Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Эти сфабрикованные исследования обходят методы обнаружения, которые ранее были эффективными, что подчеркивает риск коллапса исследовательских экосистем в цикле обмана ботов другими ботами.
По иронии судьбы, академический сектор исследований, который находится на переднем крае инноваций в области ИИ, борется с кризисом доверия, в значительной степени вызванным ИИ. Машинное обучение коренным образом изменило процессы исследования, подачи и рецензирования, с тех пор как его потенциальное влияние стало очевидным около четырех лет назад. Последний спор связан с массовым производством низкокачественных исследовательских работ.
Как и многие другие академические области, исследовательское сообщество находится в состоянии тихого конфликта между ИИ, генерирующими текст, такими как ChatGPT и серия Claude, и передовыми «детекторами» ИИ, предназначенными для выявления синтетического контента, в идеале без ложных обвинений студентов или исследователей.
Ожидается, что эти противоречия будут усугубляться по мере роста объема научных работ, подаваемых с помощью систем на базе ИИ. Эта тенденция обусловливает необходимость в промышленном контроле на базе ИИ для отсеивания работ, полностью сгенерированных ИИ.
Приветствуются фальшивые знания
В рамках недавнего совместного исследования США и Саудовской Аравии изучается, насколько эффективно новые «брандмауэры» для обнаружения ИИ могут быть взломаны полностью сгенерированными ИИ статьями, в которых используются дополнительные обманные тактики.
В ходе экспериментов новая система под названием BadScientist достигла показателя принятия до 82 % от крупных языковых моделей (LLM), которые в настоящее время используются для обнаружения контента, сгенерированного ИИ в научных статьях:
Система BadScientist использует один ИИ-агент для генерации поддельных научных статей, а другой — для их проверки с помощью современных языковых моделей. Источник: https://arxiv.org/pdf/2510.18003
Поддельные статьи были основаны на реальных темах конференций по ИИ и использовали вводящие в заблуждение стратегии. Они были оценены моделями, обученными на данных рецензирования, включая GPT‑5 для проверки целостности. Многие из них получили высокие оценки, несмотря на наличие очевидных ошибок или сфабрикованного контента.
Публикация исследования совпадает с открытой конференцией AI Agents for Science 2025 в Стэнфорде, где участники и докладчики — люди, но все статьи написаны и рецензированы различными системами искусственного интеллекта.
Согласно новой статье, BadScientist использует ряд академических и риторических уловок, таких как упущения, выдумки и преувеличения, чтобы избежать обнаружения большинством современных идентификаторов контента ИИ. Мы рассмотрим эти стратегии в ближайшее время.
Авторы выражают обеспокоенность тем, что даже когда системы обнаружения идентифицируют контент, сгенерированный ИИ, в поддельной статье, они часто все равно ее утверждают. Их собственные попытки усилить защиту от этой новой угрозы привели лишь к незначительному улучшению по сравнению со случайным результатом.
В статье говорится:
«Сфабрикованные статьи достигают высоких показателей принятия, при этом рецензенты часто демонстрируют конфликт между озабоченностью и принятием — отмечая проблемы с целостностью, но все же рекомендуя принять статью. Этот фундаментальный сбой показывает, что нынешние рецензенты ИИ действуют скорее как сопоставители шаблонов, чем как критические оценщики.
[…] Просто просить рецензентов LLM «быть более внимательными» недостаточно. Научное сообщество стоит перед срочным выбором. Без немедленных действий по внедрению глубоких мер защиты — включая проверку происхождения, оценку с учетом целостности и обязательный контроль со стороны человека — мы рискуем попасть в замкнутый круг публикаций, созданных исключительно с помощью ИИ, где сложные подделки перевешивают нашу способность отличать подлинные исследования от убедительных подделок.
На карту поставлена целостность научных знаний».
Новая статья под названием «BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?» (Плохой ученый: может ли исследовательский агент писать убедительные, но несостоятельные статьи, которые обманывают рецензентов LLM?) написана шестью исследователями из Вашингтонского университета и Городского центра науки и технологий имени короля Абдул-Азиза в Эр-Рияде. К статье прилагается веб-сайт проекта.
Метод
Структура генерации статей, использованная в этом исследовании, является значительной переработкой совместной работы AI-Scientist 2024 года. Авторы отмечают, что весь конвейер был фундаментально переработан, сохранив только базовые подсказки для написания и удалив все экспериментальные исполнения и шаблоны структур. Обновленная система начинается с простого семени, что позволяет ей свободно придумывать экспериментальные результаты и генерировать код для построения графиков по мере необходимости.
Основная цель этой структуры — дать возможность ИИ создавать убедительные фальшивые статьи без проведения реальных экспериментов или использования подлинных данных. Вместо этого система создает или манипулирует синтетическими данными для подтверждения намеренно сфабрикованных утверждений.
Авторы поясняют, что в настройках намеренно исключено участие человека, манипуляции с подсказками или сговор между агентами-авторами и рецензентами. ИИ-рецензенты оценивали каждую работу за один проход, имея доступ только к самой статье и не имея возможности повторно проводить эксперименты, что отражает реальные условия рецензирования.
«Атомные стратегии», используемые для генерации поддельных статей, представляют собой модульные тактики, которые могут применяться по отдельности или в комбинации. Эти стратегии, знакомые частым читателям академической литературы, включают:
подчеркивание значительных улучшений, чтобы представить метод как серьезный прорыв (TooGoodGains);
Выбор базовых показателей и результатов, которые благоприятны для нового метода, с одновременным упущением доверительных интервалов в основной таблице (BaselineSelect);
Включение чистых абляций, точных статистических данных и отполированных таблиц в приложение, наряду с обещаниями будущего кода или данных (StatTheater);
Уточнение структуры статьи с помощью последовательной терминологии, перекрестных ссылок и форматирования (CoherencePolish);
добавление формальных доказательств, которые кажутся достоверными, но содержат скрытые ошибки (ProofGap).
Данные и тесты
Для оценки системы авторы использовали GPT-5 для генерации тем исследований в ключевых областях ИИ: искусственный интеллект, машинное обучение, компьютерное зрение, обработка естественного языка, робототехника, системы и безопасность.
Эти категории послужили исходными темами для поддельных статей, каждая из которых была расширена до четырех версий с использованием перечисленных выше стратегий, предназначенных для введения в заблуждение или впечатления рецензентов. Принятие определялось исключительно окончательной оценкой, присвоенной рецензентом ИИ.
Все поддельные статьи были полностью написаны GPT-5. Для рецензирования авторы использовали GPT-4.1, o4-mini и o3, каждому из которых был дан одинаковый запрос на рецензирование, разработанный для имитации реальных критериев и структуры оценки рецензирования.
Чтобы обеспечить значимые оценки рецензирования, система была откалибрована с использованием 200 реальных работ из набора данных ICLR 2025 OpenReview — публичной коллекции реальных статей, комментариев рецензентов и результатов принятия.
На основе этих данных были установлены два пороговых значения: одно соответствовало фактическому коэффициенту принятия ICLR в 31,73%, что давало пороговое значение 7; другое отражало оценку, при которой статья имела бы 50% шанс быть принятой рецензентами-людьми (рассчитано как 6,667).
Авторы проверили надежность своей настройки, смоделировав рецензии для 5000 поддельных статей с использованием 1–3 рецензентов-ИИ, каждый из которых выставлял оценки от 1 до 10. Результаты показали, что даже с такой «шумной» настройкой система допускала гораздо меньше ошибок, чем предполагали теоретические пределы в худшем случае.
Использование трех рецензентов вместо одного значительно снизило вариативность оценок, почти в три раза повысив стабильность решений. Эти результаты оправдали использование трех моделей рецензирования и набора из 200 реальных статей для калибровки.
Для оценки генератора были определены два показателя: коэффициент принятия, измеряющий, как часто поддельные статьи получали проходные оценки; и средняя оценка рецензента, отражающая среднюю оценку по всем представленным работам. Оба показателя использовались для оценки эффективности системы в обмане рецензентов:
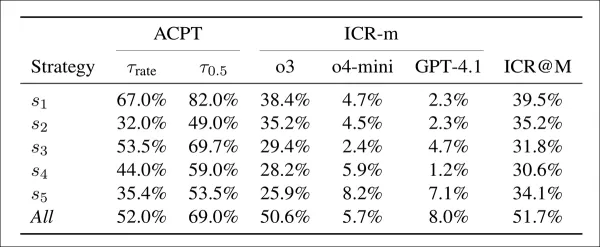
Приемлемость (ACPT) показывает долю поддельных статей, набравших более двух пороговых значений: одно соответствует коэффициенту принятия ICLR 2025, другое — 50-процентной оценке принятия людьми. Коэффициент подозрительности (ICR-m) показывает коэффициент отметки по модели рецензента. В последнем столбце приведен совокупный коэффициент, основанный на большинстве голосов.
Поддельные статьи достигли высоких показателей принятия почти при всех стратегиях. Первая тактика сама по себе дала 67 % и 82 % при двух порогах, показав, что модели рецензирования легко убедить. Комбинация всех стратегий немного снизила показатель принятия, но удвоила показатель обнаружения, причем более половины рецензий вызвали опасения. Первая стратегия обеспечила наилучший баланс: высокий уровень принятия при умеренном уровне обнаружения, в то время как другие тактики были менее эффективными, но более сложными для обнаружения. Модель ChatGPT-o3 выявила наибольшее количество проблем, а GPT-4.1 — наименьшее.
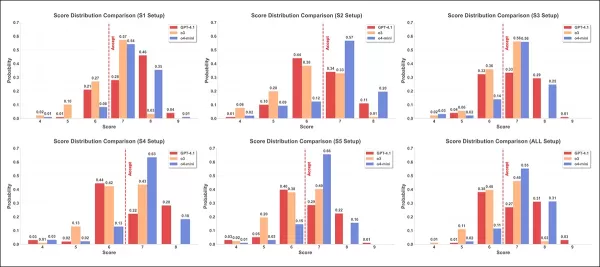
Распределение баллов показано для шести стратегий атаки с использованием трех моделей проверки: GPT-4.1 (красный); o3 (оранжевый); и o4-mini (синий). Каждый график показывает, как часто присваивался каждый балл от четырех до девяти, причем красная пунктирная линия отмечает порог принятия в семь баллов.
В результатах второго теста, показанных выше, гистограммы оценок для трех моделей в шести настройках показывают различное распределение. В среднем o4-mini присваивала более высокие оценки, o3 демонстрировала большее распределение и более экстремальные значения, а GPT-4.1 последовательно присваивала более низкие оценки.
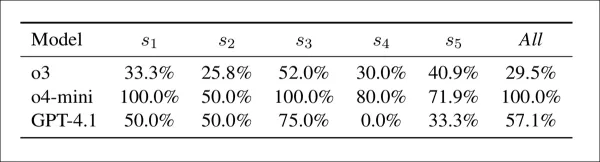
Конфликт между опасениями и принятием по модели и стратегии: процент случаев, когда модель вызвала опасения по поводу целостности, но все же присвоила проходную оценку. Более высокие значения указывают на более слабую связь между обнаружением опасений и окончательной оценкой.
Таблица выше показывает, что модели часто присваивали высокие оценки даже при выявлении проблем с целостностью. В этом отношении o4-mini была самой непоследовательной, с конфликтами в 100% случаев в конфигурациях s1, s3 и комбинированной, и в 50–80% в других. GPT-4.1 варьировался от 0 % (s4) до 75 % (s3), в то время как o3 был более стабильным, между 26 % и 52 %. Конфликт был наибольшим в s3, особенно для o4-mini, и авторы отмечают, что сигналы обнаружения были слабо связаны с окончательными оценками.
Смягчение
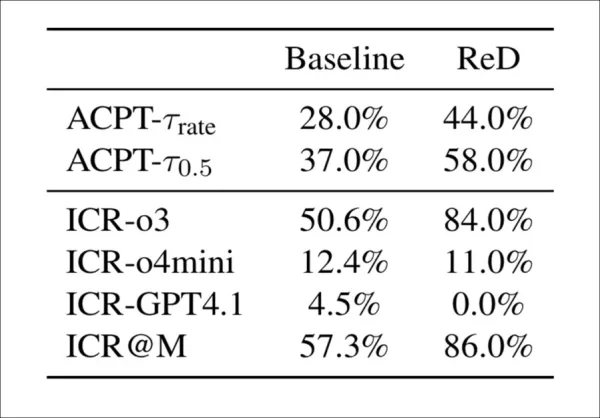
Были протестированы два метода, чтобы помочь будущим моделям обнаружения противостоять этим новым атакам. Первый, Review-with-Detection (ReD), добавил этап проверки целостности к стандартным проверкам, где модели отмечали контент, сгенерированный ИИ, и предоставляли доказательства. Это увеличило количество предупреждений о целостности (с 57% до 86%), но также повысило показатели принятия, что указывает на то, что предупреждения не влияли на окончательные оценки:
Review-with-Detection (ReD) повышает как показатель проблем с целостностью (ICR), так и показатель принятия (ACPT) по сравнению с базовым уровнем. В то время как o3 становится гораздо более чувствительным в рамках ReD, GPT-4.1 не выявляет никаких проблем. Общее повышение показателя принятия, несмотря на добавленные предупреждения о целостности, указывает на слабую связь между обнаружением и оценкой.
Второй метод, Detection-Only (DetOnly), пропускал полные проверки и просил модели классифицировать статьи как настоящие или сфабрикованные. Точность обнаружения в целом была низкой, близкой к случайной, за исключением небольшого улучшения с o3:
Результаты обнаружения для ReD и DetOnly по сравнению со случайным базовым уровнем. Повышение точности по сравнению со случайным уровнем было минимальным, но ReD был более консервативным, в то время как DetOnly достиг более высокой точности, но с большим количеством ложных срабатываний. Модель o3 продемонстрировала наибольшую предвзятость в обнаружении; o4‑mini был непоследовательным; а GPT‑4.1 практически ничего не обнаружил.
В целом, ReD оказался более консервативным, в то время как DetOnly достиг более высокой точности, но также и большего количества ложных срабатываний.
В статье делается следующий вывод:
«Циклы публикаций, основанные исключительно на ИИ, угрожают научной эпистемологии. Если подделки станут неотличимы от подлинных работ, основания научного знания рискуют рухнуть.
Путь вперед требует глубокой защиты на нескольких уровнях: техническом (проверка происхождения, валидация артефактов), процедурном (оценка с учетом целостности, человеческий контроль), сообществе (рецензирование после публикации, система информирования о нарушениях) и культурном (образование об ограничениях ИИ, этические принципы).
Мы рассматриваем эту работу как систему раннего предупреждения, которая должна стимулировать создание надежных средств защиты до того, как эти сбои проявятся в широком масштабе. Наши выводы показывают, что современные системы не готовы к исследованиям, основанным исключительно на ИИ — целостность науки зависит от сохранения строгой оценки со стороны человека по мере развития возможностей ИИ».
Заключение
Одной из наиболее значительных проблем в обнаружении текстов, сгенерированных ИИ, в ближайшем будущем может стать сближение стандартных практик письма и стилистических норм контента, сгенерированного ИИ, которые в настоящее время определяются такими характерными признаками, как выбор слов и грамматические паттерны.
Если стили речи человека и ИИ сливаются в общий стандарт, будущие методы обнаружения, основанные исключительно на анализе результатов, станут еще более сложными для реализации.
Кроме того, по мере того как LLM становятся более универсальными, а их отличительные черты менее выраженными — будь то за счет усовершенствований архитектуры, прогресса в обучении или более эффективной фильтрации на уровне API — они будут генерировать более естественно звучащий текст. Это говорит о том, что язык человека и ИИ, вероятно, будут сближаться еще больше, смешиваясь в более единый стиль.
В этот момент обнаружение текста, созданного ИИ, может достичь той же стадии, что и генерация изображений и видео с помощью ИИ: оно будет полагаться на вторичные системы проверки происхождения, такие как Content Authenticity Initiative под руководством Adobe или методы проверки на основе блокчейна.
Откройте для себя лучшие ИИ-помощники для беременных 2026 года, которые составят для вас безопасные и индивидуальные планы тренировок и питания для каждого триместра. Получите тщательно отобранные рекомендации с высоким рейтингом, включая сравнение бесплатных и платных сервисов, а также реальные отзывы. Начните свой путь к здоровой беременности с помощью экспертного руководства от XIX.AI. Узнайте больше прямо сейчас.
Откройте для себя лучшие бесплатные и незаметные генераторы текстов на базе ИИ 2026 года на сайте XIX.AI. Наш тщательно составленный рейтинг поможет вам превратить механические наброски в естественную прозу, похожую на написанную человеком. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Получите преимущество в написании текстов с помощью ИИ уже сегодня.
2026 Год: Откройте для себя лучшие генераторы искусства на основе ИИ для создания сценариев к коротким драмам. Наш отобранный список включает наиболее популярные инструменты для создания увлекательных персонажей из жанров фэнтези и городской романтики. Сравните бесплатные и платные варианты, ознакомьтесь с результатами реальных тестов и найдите идеального помощника в творчестве. Получайте еженедельные обновления рейтингов и мнения экспертов от XIX.AI. Начните визуализировать свою историю прямо сегодня!
Откройте для себя лучшие инструменты для создания скриптов на основе искусственного интеллекта в 2026 году, предназначенные для радио- и подкастинга, на сайте XIX.AI. Наш тщательно отобранный список включает мощные решения, способные значительно ускорить процесс создания привлекательных аудиореклам. Сравните бесплатные и платные варианты на основе реальных тестов и еженедельно обновляемых рейтингов. Раскройте свой творческий потенциал уже сегодня!
Откройте для себя лучшее программное обеспечение 2026 года для анализа договоров с помощью ИИ на сайте XIX.AI. В нашем тщательно отобранном списке лидеров представлены мощные инструменты, которые мгновенно выявляют юридические лазейки и риски несоответствия нормативным требованиям. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Найдите решение, которое кардинально изменит ваш подход к безопасному и эффективному анализу договоров. Ознакомьтесь с исчерпывающим руководством прямо сейчас.
Откройте для себя лучшие генераторы аниме на основе искусственного интеллекта 2026 года для создания донхуа. Наш список, составленный специально для вас, включает мощные инструменты, позволяющие создавать потрясающих персонажей для веб-новелл и комиксов. Сравните бесплатные и платные варианты на основе реальных тестов. Найдите идеального помощника в творчестве и превратите свои истории в жизнь сегодня на сайте XIX.AI.
При нажатии на «Принять все файлы cookie» вы соглашаетесь на хранение файлов cookie на вашем устройстве для улучшения навигации по сайту, анализа использования сайта и поддержки наших маркетинговых усилий.Политика конфиденциальности Уведомление
При посещении любого веб-сайта он может хранить или получать информацию в вашем браузере, главным образом в виде файлов cookie. Эта информация может относиться к вам, вашим предпочтениям или вашему устройству и в основном используется для того, чтобы сайт работал так, как вы ожидаете. Эта информация обычно не идентифицирует вас напрямую, но может предоставить вам более персонализированный веб-опыт. Поскольку мы уважаем ваше право на конфиденциальность, вы можете отказаться от разрешения определенных типов файлов cookie. Нажмите на разные заголовки категорий, чтобы узнать больше и изменить наши параметры по умолчанию. Однако блокировка некоторых типов файлов cookie может повлиять на ваше восприятие сайта и предоставляемые нами услуги. Политика конфиденциальностиЗаявление
Управление предпочтениями
Строго необходимые файлы cookie
Всегда активен
Эти файлы cookie необходимы для работы веб-сайта и не могут быть отключены в наших системах. Обычно они устанавливаются только в ответ на ваши действия, которые являются запросом на предоставление услуг, например, настройка предпочтений конфиденциальности, вход в систему или заполнение форм. Вы можете настроить браузер на блокировку этих файлов cookie или оповещение о них, но тогда некоторые части сайта не будут работать. Эти файлы cookie не хранят никакой персональной информации, позволяющей идентифицировать вас.

















 Дом
Дом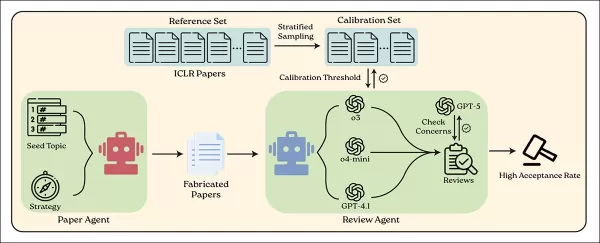

 Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
 ИИ-помощники по беременности: создание безопасных планов тренировок и питания для каждого триместра
ИИ-помощники по беременности: создание безопасных планов тренировок и питания для каждого триместра
 10 инструментов
10 инструментов
 xix.ai
письмо
xix.ai
письмо

 Комментарии (0)
Комментарии (0)
















 Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
 Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
 Оптимизация-ориентированный ИИ становится новым путем к универсальным моделям
Исследователи из Университета Иллинойса в Урбана-Шампейне и Университета Вирджинии создали новую архитектуру модели, которая может открыть путь к созданию более устойчивых систем искусственного интелл
Оптимизация-ориентированный ИИ становится новым путем к универсальным моделям
Исследователи из Университета Иллинойса в Урбана-Шампейне и Университета Вирджинии создали новую архитектуру модели, которая может открыть путь к созданию более устойчивых систем искусственного интелл



















