
















 Maison
MaisonLe nouvel outil d'Anthropic révèle exactement pourquoi les LLM échouent
Les grands modèles de langage (LLM) révolutionnent les opérations des entreprises, mais leurs processus décisionnels opaques posent souvent des problèmes d'imprévisibilité. Pour y remédier, Anthropic a ouvert son outil de traçage des circuits, permettant aux développeurs de pénétrer à l'intérieur des modèles et de modifier leurs mécanismes de base.
Cet outil révolutionnaire aide à diagnostiquer les comportements erratiques dans les modèles à poids ouvert tout en permettant un réglage précis pour les applications commerciales spécialisées.
Décodage des voies de décision de l'IA
L'outil tire parti de l'"interprétabilité mécaniste", en analysant les activations neuronales plutôt que les seules entrées et sorties. Développé à l'origine pour Claude 3.5 Haiku, il fonctionne désormais avec des modèles tels que Gemma-2-2b et Llama-3.2-1b, accompagnés de carnets de notes Colab.
Ses graphes d'attribution fonctionnent comme des plans d'IA, en cartographiant la façon dont les caractéristiques internes interagissent pendant le raisonnement. Les chercheurs peuvent modifier expérimentalement ces voies neuronales et observer les changements de comportement - essentiellement pour déboguer la cognition de l'IA.
L'intégration avec Neuronpedia crée un écosystème ouvert pour l'expérimentation des réseaux neuronaux.
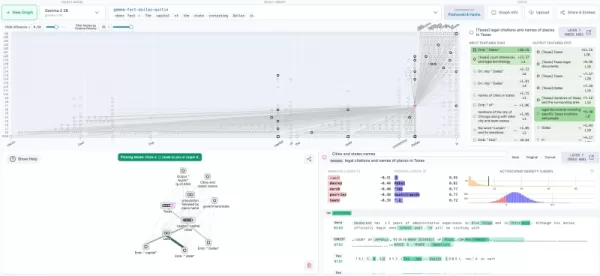
Visualisation du traçage des circuits sur Neuronpedia (source : Anthropic blog) Feuille de route pour la mise en œuvre en entreprise
Bien que révolutionnaire, l'outil est confronté à des obstacles tels que des besoins élevés en mémoire et des exigences complexes en matière d'interprétation - des défis typiques de la recherche exploratoire. Sa nature open-source accélère les améliorations apportées par la communauté vers des solutions évolutives et automatisées.
Des avantages pratiques pour les entreprises apparaissent au fur et à mesure que la technologie mûrit :
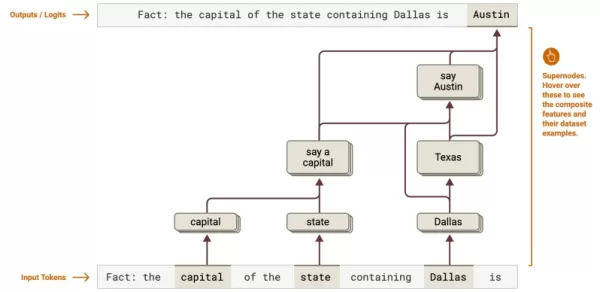
Source : Anthropic Cartographie cognitive : Elle révèle des chaînes de raisonnement à plusieurs étapes, comme la détermination de la capitale du Texas, de Dallas à Austin. Les entreprises peuvent optimiser les flux de travail complexes dans l'analyse juridique ou le traitement des données.
Transparence numérique : Mise en évidence des méthodes de calcul uniques, détection des erreurs arithmétiques dans les modèles financiers tout en garantissant l'intégrité des calculs.
Cohérence multilingue : Identifie les circuits universels par rapport aux circuits spécifiques à une langue, ce qui permet de résoudre les problèmes de localisation dans les déploiements mondiaux.
Réduction des hallucinations : Identifie les circuits de "refus par défaut" défectueux qui provoquent des réponses inexactes lorsqu'ils sont ignorés.
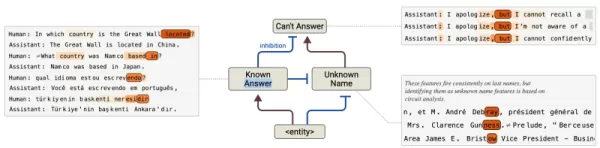
Source : Anthropic Au-delà du dépannage, ces informations permettent une optimisation chirurgicale du modèle. Au lieu de modifier superficiellement les résultats, les entreprises peuvent directement ajuster les mécanismes sous-jacents - en corrigeant les biais d'alignement dans les personas des assistants ou en renforçant les contraintes éthiques.
À mesure que les LLM assument des rôles critiques, de tels outils d'interprétabilité deviennent essentiels pour construire des systèmes d'IA dignes de confiance et vérifiables qui s'alignent sur les valeurs organisationnelles et les exigences de conformité.
Article connexe
 Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud
Recommandations de sujets spéciaux liés
Productivité
Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud
Recommandations de sujets spéciaux liés
Productivité
 Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
 10 outils
10 outils
 xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai
Analyse des données
Les meilleurs outils de visualisation de données basés sur l'IA : générez automatiquement des tableaux de bord BI interactifs à partir de fichiers bruts
Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai

 commentaires (2)
commentaires (2)
![ScottPerez]()
¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
![BruceMartínez]()
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?
Les grands modèles de langage (LLM) révolutionnent les opérations des entreprises, mais leurs processus décisionnels opaques posent souvent des problèmes d'imprévisibilité. Pour y remédier, Anthropic a ouvert son outil de traçage des circuits, permettant aux développeurs de pénétrer à l'intérieur des modèles et de modifier leurs mécanismes de base.
Cet outil révolutionnaire aide à diagnostiquer les comportements erratiques dans les modèles à poids ouvert tout en permettant un réglage précis pour les applications commerciales spécialisées.
Décodage des voies de décision de l'IA
L'outil tire parti de l'"interprétabilité mécaniste", en analysant les activations neuronales plutôt que les seules entrées et sorties. Développé à l'origine pour Claude 3.5 Haiku, il fonctionne désormais avec des modèles tels que Gemma-2-2b et Llama-3.2-1b, accompagnés de carnets de notes Colab.
Ses graphes d'attribution fonctionnent comme des plans d'IA, en cartographiant la façon dont les caractéristiques internes interagissent pendant le raisonnement. Les chercheurs peuvent modifier expérimentalement ces voies neuronales et observer les changements de comportement - essentiellement pour déboguer la cognition de l'IA.
L'intégration avec Neuronpedia crée un écosystème ouvert pour l'expérimentation des réseaux neuronaux.
Feuille de route pour la mise en œuvre en entreprise
Bien que révolutionnaire, l'outil est confronté à des obstacles tels que des besoins élevés en mémoire et des exigences complexes en matière d'interprétation - des défis typiques de la recherche exploratoire. Sa nature open-source accélère les améliorations apportées par la communauté vers des solutions évolutives et automatisées.
Des avantages pratiques pour les entreprises apparaissent au fur et à mesure que la technologie mûrit :
Cartographie cognitive : Elle révèle des chaînes de raisonnement à plusieurs étapes, comme la détermination de la capitale du Texas, de Dallas à Austin. Les entreprises peuvent optimiser les flux de travail complexes dans l'analyse juridique ou le traitement des données.
Transparence numérique : Mise en évidence des méthodes de calcul uniques, détection des erreurs arithmétiques dans les modèles financiers tout en garantissant l'intégrité des calculs.
Cohérence multilingue : Identifie les circuits universels par rapport aux circuits spécifiques à une langue, ce qui permet de résoudre les problèmes de localisation dans les déploiements mondiaux.
Réduction des hallucinations : Identifie les circuits de "refus par défaut" défectueux qui provoquent des réponses inexactes lorsqu'ils sont ignorés.
Au-delà du dépannage, ces informations permettent une optimisation chirurgicale du modèle. Au lieu de modifier superficiellement les résultats, les entreprises peuvent directement ajuster les mécanismes sous-jacents - en corrigeant les biais d'alignement dans les personas des assistants ou en renforçant les contraintes éthiques.
À mesure que les LLM assument des rôles critiques, de tels outils d'interprétabilité deviennent essentiels pour construire des systèmes d'IA dignes de confiance et vérifiables qui s'alignent sur les valeurs organisationnelles et les exigences de conformité.










 Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
 Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
 Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud
Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai

¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?













