
















 Heim
HeimDas neue Tool von Anthropic zeigt genau auf, warum LLMs scheitern
Große Sprachmodelle (Large Language Models, LLMs) revolutionieren die Abläufe in Unternehmen, doch ihre undurchsichtigen Entscheidungsprozesse führen oft zu Problemen mit der Vorhersagbarkeit. Um dieses Problem zu lösen, hat Anthropic sein Tool zur Schaltkreisverfolgung freigegeben, mit dem Entwickler in die Modelle hineinschauen und ihre Kernmechanismen ändern können.
Dieses bahnbrechende Tool hilft bei der Diagnose unregelmäßiger Verhaltensweisen in Modellen mit offenem Gewicht und ermöglicht eine präzise Abstimmung für spezielle Geschäftsanwendungen.
Entschlüsselung von KI-Entscheidungspfaden
Das Tool nutzt die "mechanistische Interpretierbarkeit", d. h. die Analyse neuronaler Aktivierungen und nicht nur der Eingaben und Ausgaben. Ursprünglich für Claude 3.5 Haiku entwickelt, funktioniert es jetzt auch mit Modellen wie Gemma-2-2b und Llama-3.2-1b, komplett mit lehrreichen Colab-Notebooks.
Seine Attributionsgraphen funktionieren wie KI-Baupläne, die abbilden, wie interne Merkmale während des Denkens interagieren. Forscher können diese neuronalen Bahnen experimentell modifizieren und Verhaltensänderungen beobachten - im Wesentlichen eine Fehlersuche in der KI-Kognition.
Die Integration mit Neuronpedia schafft ein offenes Ökosystem für Experimente mit neuronalen Netzen.
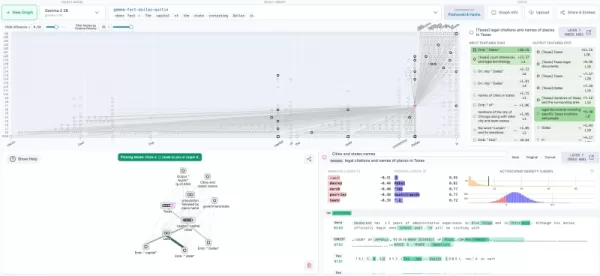
Visualisierung der Schaltkreisverfolgung auf Neuronpedia (Quelle: Anthropic Blog) Fahrplan für die Implementierung in Unternehmen
Obwohl das Tool bahnbrechend ist, steht es vor Hindernissen wie hohen Speicheranforderungen und komplexen Interpretationsanforderungen - typische Herausforderungen der Pionierforschung. Sein Open-Source-Charakter beschleunigt von der Gemeinschaft betriebene Verbesserungen in Richtung skalierbarer, automatisierter Lösungen.
Mit zunehmender Reife der Technologie ergeben sich praktische Geschäftsvorteile:
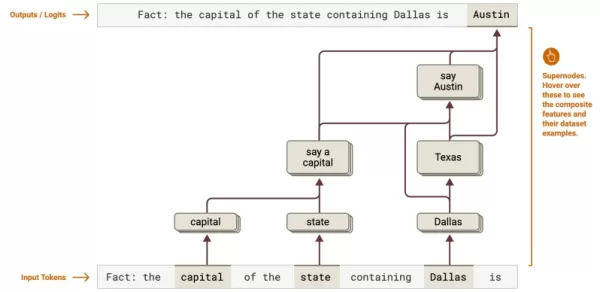
Quelle: Anthropic Kognitives Mapping: Zeigt mehrstufige Argumentationsketten auf - wie die Verfolgung der texanischen Kapitalbestimmung von Dallas nach Austin. Unternehmen können komplexe Arbeitsabläufe in der rechtlichen Analyse oder Datenverarbeitung optimieren.
Numerische Transparenz: Legt eindeutige Berechnungsmethoden offen, erkennt arithmetische Fehler in Finanzmodellen und gewährleistet gleichzeitig die Integrität der Berechnungen.
Mehrsprachige Konsistenz: Identifiziert universelle und sprachspezifische Schaltkreise und behebt Lokalisierungsprobleme in globalen Implementierungen.
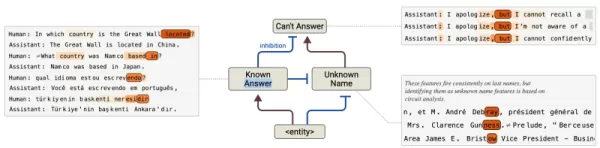
Reduzierung von Halluzinationen: Identifiziert fehlerhafte "Standardverweigerungs"-Schaltkreise, die ungenaue Antworten verursachen, wenn sie außer Kraft gesetzt werden.
Quelle: Anthropic Über die Fehlersuche hinaus ermöglichen diese Erkenntnisse eine chirurgische Modelloptimierung. Anstelle einer oberflächlichen Leistungsoptimierung können Unternehmen die zugrundeliegenden Mechanismen direkt anpassen - indem sie Ausrichtungsfehler in Assistenten-Personas korrigieren oder ethische Einschränkungen verstärken.
Da LLMs geschäftskritische Rollen übernehmen, werden solche Interpretationswerkzeuge für den Aufbau vertrauenswürdiger, überprüfbarer KI-Systeme, die mit den Unternehmenswerten und Compliance-Anforderungen übereinstimmen, unerlässlich.
Verwandter Artikel
 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
Empfehlungen zu verwandten Spezialthemen
Produktivität
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
Empfehlungen zu verwandten Spezialthemen
Produktivität
 KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
 10 Tools
10 Tools
 xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai
Datenanalyse
Die besten KI-Tools zur Datenvisualisierung: Interaktive BI-Dashboards automatisch aus Rohdaten generieren
Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

 Kommentare (2)
Kommentare (2)
![ScottPerez]()
¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
![BruceMartínez]()
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?
Große Sprachmodelle (Large Language Models, LLMs) revolutionieren die Abläufe in Unternehmen, doch ihre undurchsichtigen Entscheidungsprozesse führen oft zu Problemen mit der Vorhersagbarkeit. Um dieses Problem zu lösen, hat Anthropic sein Tool zur Schaltkreisverfolgung freigegeben, mit dem Entwickler in die Modelle hineinschauen und ihre Kernmechanismen ändern können.
Dieses bahnbrechende Tool hilft bei der Diagnose unregelmäßiger Verhaltensweisen in Modellen mit offenem Gewicht und ermöglicht eine präzise Abstimmung für spezielle Geschäftsanwendungen.
Entschlüsselung von KI-Entscheidungspfaden
Das Tool nutzt die "mechanistische Interpretierbarkeit", d. h. die Analyse neuronaler Aktivierungen und nicht nur der Eingaben und Ausgaben. Ursprünglich für Claude 3.5 Haiku entwickelt, funktioniert es jetzt auch mit Modellen wie Gemma-2-2b und Llama-3.2-1b, komplett mit lehrreichen Colab-Notebooks.
Seine Attributionsgraphen funktionieren wie KI-Baupläne, die abbilden, wie interne Merkmale während des Denkens interagieren. Forscher können diese neuronalen Bahnen experimentell modifizieren und Verhaltensänderungen beobachten - im Wesentlichen eine Fehlersuche in der KI-Kognition.
Die Integration mit Neuronpedia schafft ein offenes Ökosystem für Experimente mit neuronalen Netzen.
Fahrplan für die Implementierung in Unternehmen
Obwohl das Tool bahnbrechend ist, steht es vor Hindernissen wie hohen Speicheranforderungen und komplexen Interpretationsanforderungen - typische Herausforderungen der Pionierforschung. Sein Open-Source-Charakter beschleunigt von der Gemeinschaft betriebene Verbesserungen in Richtung skalierbarer, automatisierter Lösungen.
Mit zunehmender Reife der Technologie ergeben sich praktische Geschäftsvorteile:
Kognitives Mapping: Zeigt mehrstufige Argumentationsketten auf - wie die Verfolgung der texanischen Kapitalbestimmung von Dallas nach Austin. Unternehmen können komplexe Arbeitsabläufe in der rechtlichen Analyse oder Datenverarbeitung optimieren.
Numerische Transparenz: Legt eindeutige Berechnungsmethoden offen, erkennt arithmetische Fehler in Finanzmodellen und gewährleistet gleichzeitig die Integrität der Berechnungen.
Mehrsprachige Konsistenz: Identifiziert universelle und sprachspezifische Schaltkreise und behebt Lokalisierungsprobleme in globalen Implementierungen.
Reduzierung von Halluzinationen: Identifiziert fehlerhafte "Standardverweigerungs"-Schaltkreise, die ungenaue Antworten verursachen, wenn sie außer Kraft gesetzt werden.
Über die Fehlersuche hinaus ermöglichen diese Erkenntnisse eine chirurgische Modelloptimierung. Anstelle einer oberflächlichen Leistungsoptimierung können Unternehmen die zugrundeliegenden Mechanismen direkt anpassen - indem sie Ausrichtungsfehler in Assistenten-Personas korrigieren oder ethische Einschränkungen verstärken.
Da LLMs geschäftskritische Rollen übernehmen, werden solche Interpretationswerkzeuge für den Aufbau vertrauenswürdiger, überprüfbarer KI-Systeme, die mit den Unternehmenswerten und Compliance-Anforderungen übereinstimmen, unerlässlich.










 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
 Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
 KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?













