
















 Home
HomeAnthropic's New Tool Reveals Exactly Why LLMs Fail
Large language models (LLMs) are revolutionizing enterprise operations, yet their opaque decision-making processes often create unpredictability challenges. To address this, Anthropic open-sourced its circuit tracing tool, enabling developers to peer inside models and modify their core mechanisms.
This breakthrough tool helps diagnose erratic behaviors in open-weight models while enabling precise tuning for specialized business applications.
Decoding AI decision pathways
The tool leverages "mechanistic interpretability" - analyzing neural activations rather than just inputs and outputs. Originally developed for Claude 3.5 Haiku, it now works with models like Gemma-2-2b and Llama-3.2-1b, complete with instructional Colab notebooks.
Its attribution graphs function like AI blueprints, mapping how internal features interact during reasoning. Researchers can experimentally modify these neural pathways and observe behavioral changes - essentially debugging AI cognition.
Integration with Neuronpedia creates an open ecosystem for neural network experimentation.
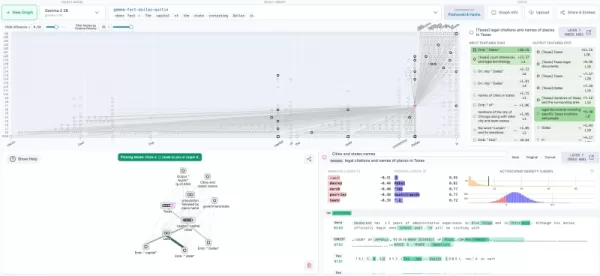
Circuit tracing visualization on Neuronpedia (source: Anthropic blog) Enterprise implementation roadmap
While groundbreaking, the tool faces obstacles like high memory demands and complex interpretation requirements - typical frontier research challenges. Its open-source nature accelerates community-driven improvements toward scalable, automated solutions.
Practical business benefits emerge as the technology matures:
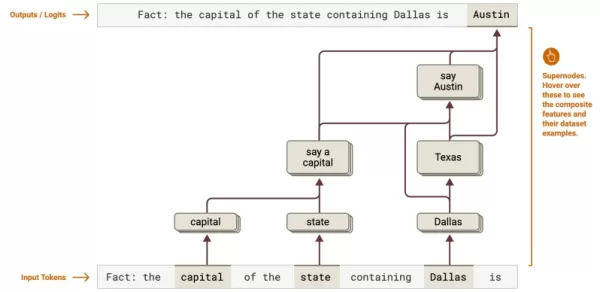
Source: Anthropic Cognitive mapping: Reveals multi-step reasoning chains - like tracing Texas capital determination from Dallas to Austin. Enterprises can optimize complex workflows in legal analysis or data processing.
Numerical transparency: Exposes unique calculation methods, detecting arithmetic errors in financial models while ensuring computational integrity.
Multilingual consistency: Identifies universal versus language-specific circuits, troubleshooting localization issues in global deployments.
Hallucination reduction: Pinpoints faulty "default refusal" circuits that cause inaccurate responses when overridden.
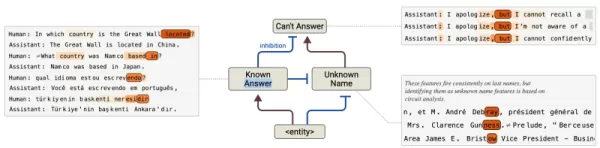
Source: Anthropic Beyond troubleshooting, these insights enable surgical model optimization. Instead of superficial output tweaking, businesses can directly adjust underlying mechanisms - correcting alignment biases in assistant personas or reinforcing ethical constraints.
As LLMs assume mission-critical roles, such interpretability tools become essential for building trustworthy, auditable AI systems that align with organizational values and compliance requirements.
Related article
 Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
Related Special Topic Recommendations
Productivity
Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
Related Special Topic Recommendations
Productivity
 AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
 10 tools
10 tools
 xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai
Data Analysis
Best AI Data Visualization Tools: Auto-Generate Interactive BI Dashboards from Raw Files
Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

 Comments (2)
0/500
Comments (2)
0/500
![ScottPerez]()
¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
![BruceMartínez]()
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?
Large language models (LLMs) are revolutionizing enterprise operations, yet their opaque decision-making processes often create unpredictability challenges. To address this, Anthropic open-sourced its circuit tracing tool, enabling developers to peer inside models and modify their core mechanisms.
This breakthrough tool helps diagnose erratic behaviors in open-weight models while enabling precise tuning for specialized business applications.
Decoding AI decision pathways
The tool leverages "mechanistic interpretability" - analyzing neural activations rather than just inputs and outputs. Originally developed for Claude 3.5 Haiku, it now works with models like Gemma-2-2b and Llama-3.2-1b, complete with instructional Colab notebooks.
Its attribution graphs function like AI blueprints, mapping how internal features interact during reasoning. Researchers can experimentally modify these neural pathways and observe behavioral changes - essentially debugging AI cognition.
Integration with Neuronpedia creates an open ecosystem for neural network experimentation.
Enterprise implementation roadmap
While groundbreaking, the tool faces obstacles like high memory demands and complex interpretation requirements - typical frontier research challenges. Its open-source nature accelerates community-driven improvements toward scalable, automated solutions.
Practical business benefits emerge as the technology matures:
Cognitive mapping: Reveals multi-step reasoning chains - like tracing Texas capital determination from Dallas to Austin. Enterprises can optimize complex workflows in legal analysis or data processing.
Numerical transparency: Exposes unique calculation methods, detecting arithmetic errors in financial models while ensuring computational integrity.
Multilingual consistency: Identifies universal versus language-specific circuits, troubleshooting localization issues in global deployments.
Hallucination reduction: Pinpoints faulty "default refusal" circuits that cause inaccurate responses when overridden.
Beyond troubleshooting, these insights enable surgical model optimization. Instead of superficial output tweaking, businesses can directly adjust underlying mechanisms - correcting alignment biases in assistant personas or reinforcing ethical constraints.
As LLMs assume mission-critical roles, such interpretability tools become essential for building trustworthy, auditable AI systems that align with organizational values and compliance requirements.










 Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
 Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
 AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?













