
















 家
家Anthropicの新ツールがLLMが失敗する理由を明らかにする
大規模言語モデル(LLM)は、企業のオペレーションに革命をもたらしていますが、その不透明な意思決定プロセスは、しばしば予測不可能な課題を引き起こします。これに対処するため、Anthropicは回路トレースツールをオープンソース化し、開発者がモデルの内部を覗き、コアメカニズムを変更できるようにしました。
この画期的なツールは、特殊なビジネスアプリケーションのための正確なチューニングを可能にしながら、オープンウェイトモデルの不安定な動作を診断するのに役立ちます。
AI意思決定経路の解読
このツールは、単なる入力と出力ではなく、神経の活性化を分析する「力学的解釈可能性」を活用します。もともとはClaude 3.5 Haikuのために開発されましたが、現在ではGemma-2-2bやLlama-3.2-1bのようなモデルで動作し、Colabノートブックが付属しています。
その帰属グラフはAIの設計図のように機能し、推論中に内部機能がどのように相互作用するかをマッピングする。研究者はこれらの神経経路を実験的に変更し、行動の変化を観察することができる。
Neuronpediaとの統合により、ニューラルネットワーク実験のためのオープンなエコシステムが構築される。
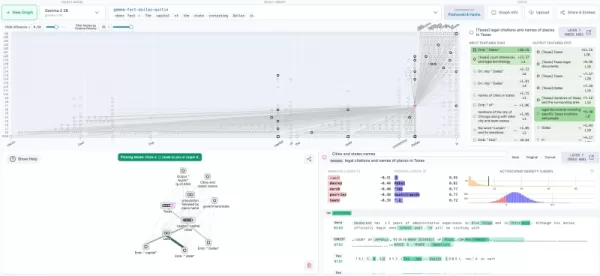
Neuronpediaでの回路トレースの可視化(出典:Anthropicブログ) 企業への導入ロードマップ
このツールは画期的ではあるが、メモリ需要の高さや複雑な解釈要件といった障害に直面している。オープンソースであるため、スケーラブルで自動化されたソリューションに向けたコミュニティ主導の改良が加速する。
技術が成熟するにつれて、実用的なビジネス上の利点が現れる:
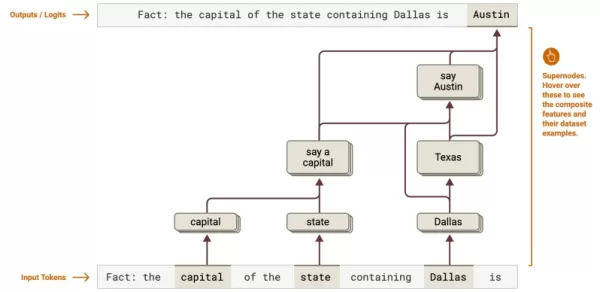
出典出典:Anthropic 認知マッピング:テキサス州の首都決定をダラスからオースティンまでたどるような、多段階の推論チェーンを明らかにする。企業は、法的分析やデータ処理における複雑なワークフローを最適化できる。
数値の透明性:独自の計算方法を公開し、計算の完全性を確保しながら、金融モデルの算術エラーを検出します。
多言語一貫性:普遍的な回路と言語固有の回路を識別し、グローバルな展開におけるローカリゼーションの問題をトラブルシューティングします。
幻覚の減少:上書きされた場合に不正確な応答を引き起こす、欠陥のある「デフォルト拒否」回路を特定します。
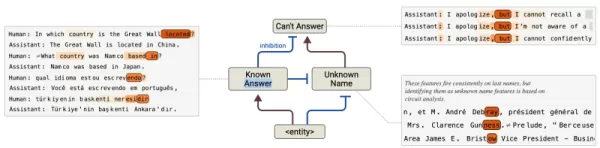
ソースアンソロピック トラブルシューティングにとどまらず、これらの洞察は外科的なモデルの最適化を可能にします。表面的なアウトプットの調整ではなく、企業は根本的なメカニズムを直接調整することができる。つまり、アシスタントのペルソナのアライメントバイアスを修正したり、倫理的制約を強化したりすることができる。
LLMがミッションクリティカルな役割を担うようになると、このような解釈可能性ツールは、組織の価値観やコンプライアンス要件に沿った、信頼性が高く監査可能なAIシステムを構築するために不可欠となる。
関連記事
 マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
関連特集おすすめ
生産性
マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
関連特集おすすめ
生産性
 AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
 10 ツール
10 ツール
 xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

 コメント (2)
0/500
コメント (2)
0/500
![ScottPerez]()
¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
![BruceMartínez]()
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?
大規模言語モデル(LLM)は、企業のオペレーションに革命をもたらしていますが、その不透明な意思決定プロセスは、しばしば予測不可能な課題を引き起こします。これに対処するため、Anthropicは回路トレースツールをオープンソース化し、開発者がモデルの内部を覗き、コアメカニズムを変更できるようにしました。
この画期的なツールは、特殊なビジネスアプリケーションのための正確なチューニングを可能にしながら、オープンウェイトモデルの不安定な動作を診断するのに役立ちます。
AI意思決定経路の解読
このツールは、単なる入力と出力ではなく、神経の活性化を分析する「力学的解釈可能性」を活用します。もともとはClaude 3.5 Haikuのために開発されましたが、現在ではGemma-2-2bやLlama-3.2-1bのようなモデルで動作し、Colabノートブックが付属しています。
その帰属グラフはAIの設計図のように機能し、推論中に内部機能がどのように相互作用するかをマッピングする。研究者はこれらの神経経路を実験的に変更し、行動の変化を観察することができる。
Neuronpediaとの統合により、ニューラルネットワーク実験のためのオープンなエコシステムが構築される。
企業への導入ロードマップ
このツールは画期的ではあるが、メモリ需要の高さや複雑な解釈要件といった障害に直面している。オープンソースであるため、スケーラブルで自動化されたソリューションに向けたコミュニティ主導の改良が加速する。
技術が成熟するにつれて、実用的なビジネス上の利点が現れる:
認知マッピング:テキサス州の首都決定をダラスからオースティンまでたどるような、多段階の推論チェーンを明らかにする。企業は、法的分析やデータ処理における複雑なワークフローを最適化できる。
数値の透明性:独自の計算方法を公開し、計算の完全性を確保しながら、金融モデルの算術エラーを検出します。
多言語一貫性:普遍的な回路と言語固有の回路を識別し、グローバルな展開におけるローカリゼーションの問題をトラブルシューティングします。
幻覚の減少:上書きされた場合に不正確な応答を引き起こす、欠陥のある「デフォルト拒否」回路を特定します。
トラブルシューティングにとどまらず、これらの洞察は外科的なモデルの最適化を可能にします。表面的なアウトプットの調整ではなく、企業は根本的なメカニズムを直接調整することができる。つまり、アシスタントのペルソナのアライメントバイアスを修正したり、倫理的制約を強化したりすることができる。
LLMがミッションクリティカルな役割を担うようになると、このような解釈可能性ツールは、組織の価値観やコンプライアンス要件に沿った、信頼性が高く監査可能なAIシステムを構築するために不可欠となる。










 マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
 秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
 AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?













