
















 首頁
首頁Anthropic的新工具揭示了法學碩士失敗的原因
大型語言模型 (LLM) 正在為企業營運帶來革命性的改變,然而其不透明的決策過程往往造成不可預測性的挑戰。為了解決這個問題,Anthropic 開放了其電路追蹤工具,讓開發人員可以窺視模型內部,並修改其核心機制。
這項突破性的工具有助於診斷開放重量模型中的不穩定行為,同時針對專門的商業應用進行精確的調整。
解碼 AI 決策路徑
此工具利用「機構可解釋性」- 分析神經活化,而不只是輸入和輸出。該工具最初是針對 Claude 3.5 Haiku 開發的,現在可與 Gemma-2-2b 和 Llama-3.2-1b 等模型一起使用,並提供完整的 Colab 說明筆記。
它的歸屬圖(attribution graphs)就像 AI 藍圖一樣,映射出內部特徵在推理過程中如何互動。研究人員可以實驗性地修改這些神經通路,並觀察行為上的變化 - 基本上就是在調試 AI 認知。
與 Neuronpedia 的整合為神經網路實驗創造了一個開放的生態系統。
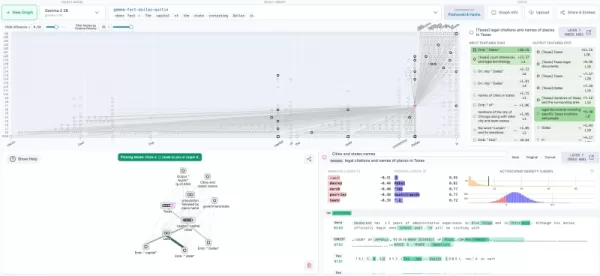
Neuronpedia 上的電路追蹤可視化(來源:Anthropic 博客) 企業實施路線圖
該工具雖然具有突破性,但仍面臨高記憶體需求和複雜解釋要求等障礙,這些都是典型的前沿研究挑戰。其開放源碼的特性可加速社群驅動的改進,以邁向可擴充的自動化解決方案。
隨著技術的成熟,實際的商業效益也會逐漸浮現:
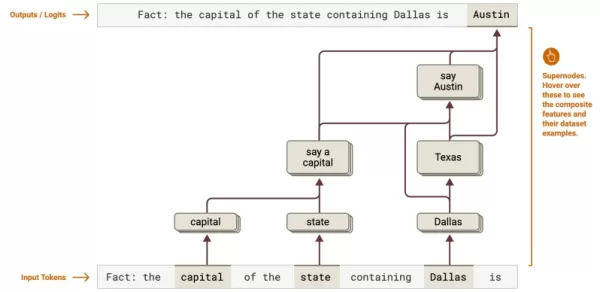
資料來源人類 認知映射:揭示多步推理鏈 - 例如追溯德州從達拉斯到奧斯汀的資本決定。企業可以優化法律分析或資料處理的複雜工作流程。
數值透明化:揭露獨特的計算方法,偵測財務模型中的算術錯誤,同時確保運算的完整性。
多語言一致性:識別通用電路與特定語言電路,解決全球部署中的本地化問題。
減少幻覺:找出有問題的「預設拒絕」電路,這些電路在覆寫時會造成不準確的回應。
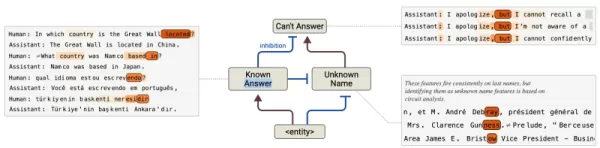
來源:人類 除了疑難排解之外,這些洞察力還能實現外科手術式的模型最佳化。企業可以直接調整底層機制,而非表面的輸出調整 - 糾正助理角色的排列偏差或強化道德限制。
隨著 LLM 擔任關鍵任務的角色,這樣的可解讀性工具對於建立符合組織價值與合規要求的可信賴、可審計 AI 系統而言,變得至關重要。
相關文章
 Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
相關專題推薦
商業
Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
相關專題推薦
商業
 最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

 評論 (2)
0/500
評論 (2)
0/500
![ScottPerez]()
¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
![BruceMartínez]()
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?
大型語言模型 (LLM) 正在為企業營運帶來革命性的改變,然而其不透明的決策過程往往造成不可預測性的挑戰。為了解決這個問題,Anthropic 開放了其電路追蹤工具,讓開發人員可以窺視模型內部,並修改其核心機制。
這項突破性的工具有助於診斷開放重量模型中的不穩定行為,同時針對專門的商業應用進行精確的調整。
解碼 AI 決策路徑
此工具利用「機構可解釋性」- 分析神經活化,而不只是輸入和輸出。該工具最初是針對 Claude 3.5 Haiku 開發的,現在可與 Gemma-2-2b 和 Llama-3.2-1b 等模型一起使用,並提供完整的 Colab 說明筆記。
它的歸屬圖(attribution graphs)就像 AI 藍圖一樣,映射出內部特徵在推理過程中如何互動。研究人員可以實驗性地修改這些神經通路,並觀察行為上的變化 - 基本上就是在調試 AI 認知。
與 Neuronpedia 的整合為神經網路實驗創造了一個開放的生態系統。
企業實施路線圖
該工具雖然具有突破性,但仍面臨高記憶體需求和複雜解釋要求等障礙,這些都是典型的前沿研究挑戰。其開放源碼的特性可加速社群驅動的改進,以邁向可擴充的自動化解決方案。
隨著技術的成熟,實際的商業效益也會逐漸浮現:
認知映射:揭示多步推理鏈 - 例如追溯德州從達拉斯到奧斯汀的資本決定。企業可以優化法律分析或資料處理的複雜工作流程。
數值透明化:揭露獨特的計算方法,偵測財務模型中的算術錯誤,同時確保運算的完整性。
多語言一致性:識別通用電路與特定語言電路,解決全球部署中的本地化問題。
減少幻覺:找出有問題的「預設拒絕」電路,這些電路在覆寫時會造成不準確的回應。
除了疑難排解之外,這些洞察力還能實現外科手術式的模型最佳化。企業可以直接調整底層機制,而非表面的輸出調整 - 糾正助理角色的排列偏差或強化道德限制。
隨著 LLM 擔任關鍵任務的角色,這樣的可解讀性工具對於建立符合組織價值與合規要求的可信賴、可審計 AI 系統而言,變得至關重要。










 Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
 秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
 人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?













