
















 Lar
LarA nova ferramenta da Anthropic revela exatamente por que os LLMs são reprovados
Os grandes modelos de linguagem (LLMs) estão revolucionando as operações empresariais, mas seus processos opacos de tomada de decisão geralmente criam desafios de imprevisibilidade. Para resolver esse problema, a Anthropic abriu o código-fonte de sua ferramenta de rastreamento de circuitos, permitindo que os desenvolvedores examinem os modelos e modifiquem seus mecanismos principais.
Essa ferramenta inovadora ajuda a diagnosticar comportamentos erráticos em modelos de peso aberto e, ao mesmo tempo, permite o ajuste preciso para aplicativos comerciais especializados.
Decodificação de caminhos de decisão de IA
A ferramenta aproveita a "interpretabilidade mecanicista", analisando as ativações neurais em vez de apenas entradas e saídas. Originalmente desenvolvida para o Haiku do Claude 3.5, ela agora funciona com modelos como Gemma-2-2b e Llama-3.2-1b, completos com notebooks Colab instrutivos.
Seus gráficos de atribuição funcionam como projetos de IA, mapeando como os recursos internos interagem durante o raciocínio. Os pesquisadores podem modificar experimentalmente esses caminhos neurais e observar as mudanças de comportamento - essencialmente depurando a cognição da IA.
A integração com a Neuronpedia cria um ecossistema aberto para a experimentação de redes neurais.
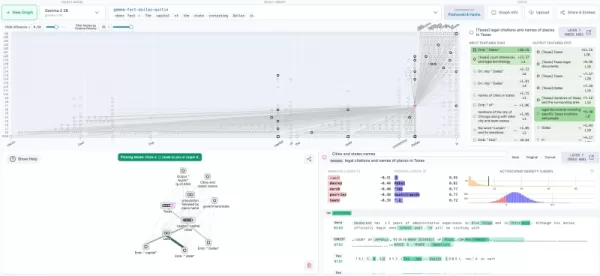
Visualização de rastreamento de circuitos na Neuronpedia (fonte: blog Anthropic) Roteiro de implementação empresarial
Embora inovadora, a ferramenta enfrenta obstáculos como alta demanda de memória e requisitos complexos de interpretação - desafios típicos de pesquisa de fronteira. Sua natureza de código aberto acelera os aprimoramentos conduzidos pela comunidade em direção a soluções automatizadas e dimensionáveis.
Benefícios práticos para os negócios surgem à medida que a tecnologia amadurece:
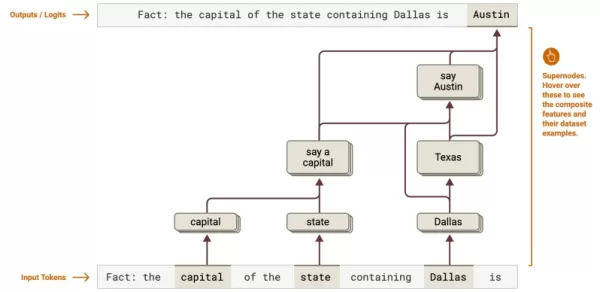
Fonte: Anthropic Mapeamento cognitivo: Revela cadeias de raciocínio de várias etapas - como rastrear a determinação da capital do Texas de Dallas a Austin. As empresas podem otimizar fluxos de trabalho complexos na análise jurídica ou no processamento de dados.
Transparência numérica: Expõe métodos de cálculo exclusivos, detectando erros aritméticos em modelos financeiros e garantindo a integridade computacional.
Consistência multilíngue: Identifica circuitos universais versus circuitos específicos de idiomas, solucionando problemas de localização em implementações globais.
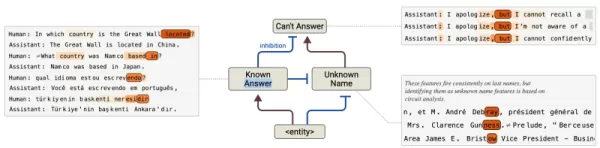
Redução de alucinações: Identifica circuitos defeituosos de "recusa padrão" que causam respostas imprecisas quando substituídos.
Fonte: Anthropic Além da solução de problemas, esses insights permitem a otimização cirúrgica do modelo. Em vez de ajustes superficiais nos resultados, as empresas podem ajustar diretamente os mecanismos subjacentes, corrigindo os vieses de alinhamento nas personas dos assistentes ou reforçando as restrições éticas.
À medida que os LLMs assumem funções de missão crítica, essas ferramentas de interpretabilidade tornam-se essenciais para a criação de sistemas de IA confiáveis e auditáveis que se alinham aos valores organizacionais e aos requisitos de conformidade.
Artigo relacionado
 Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Recomendações de tópicos especiais relacionados
Produtividade
Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Recomendações de tópicos especiais relacionados
Produtividade
 Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
 10 ferramentas
10 ferramentas
 xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai
Análise de dados
As melhores ferramentas de visualização de dados com IA: gere automaticamente painéis interativos de BI a partir de arquivos brutos
Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai

 Comentários (2)
Comentários (2)
![ScottPerez]()
¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
![BruceMartínez]()
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?
Os grandes modelos de linguagem (LLMs) estão revolucionando as operações empresariais, mas seus processos opacos de tomada de decisão geralmente criam desafios de imprevisibilidade. Para resolver esse problema, a Anthropic abriu o código-fonte de sua ferramenta de rastreamento de circuitos, permitindo que os desenvolvedores examinem os modelos e modifiquem seus mecanismos principais.
Essa ferramenta inovadora ajuda a diagnosticar comportamentos erráticos em modelos de peso aberto e, ao mesmo tempo, permite o ajuste preciso para aplicativos comerciais especializados.
Decodificação de caminhos de decisão de IA
A ferramenta aproveita a "interpretabilidade mecanicista", analisando as ativações neurais em vez de apenas entradas e saídas. Originalmente desenvolvida para o Haiku do Claude 3.5, ela agora funciona com modelos como Gemma-2-2b e Llama-3.2-1b, completos com notebooks Colab instrutivos.
Seus gráficos de atribuição funcionam como projetos de IA, mapeando como os recursos internos interagem durante o raciocínio. Os pesquisadores podem modificar experimentalmente esses caminhos neurais e observar as mudanças de comportamento - essencialmente depurando a cognição da IA.
A integração com a Neuronpedia cria um ecossistema aberto para a experimentação de redes neurais.
Roteiro de implementação empresarial
Embora inovadora, a ferramenta enfrenta obstáculos como alta demanda de memória e requisitos complexos de interpretação - desafios típicos de pesquisa de fronteira. Sua natureza de código aberto acelera os aprimoramentos conduzidos pela comunidade em direção a soluções automatizadas e dimensionáveis.
Benefícios práticos para os negócios surgem à medida que a tecnologia amadurece:
Mapeamento cognitivo: Revela cadeias de raciocínio de várias etapas - como rastrear a determinação da capital do Texas de Dallas a Austin. As empresas podem otimizar fluxos de trabalho complexos na análise jurídica ou no processamento de dados.
Transparência numérica: Expõe métodos de cálculo exclusivos, detectando erros aritméticos em modelos financeiros e garantindo a integridade computacional.
Consistência multilíngue: Identifica circuitos universais versus circuitos específicos de idiomas, solucionando problemas de localização em implementações globais.
Redução de alucinações: Identifica circuitos defeituosos de "recusa padrão" que causam respostas imprecisas quando substituídos.
Além da solução de problemas, esses insights permitem a otimização cirúrgica do modelo. Em vez de ajustes superficiais nos resultados, as empresas podem ajustar diretamente os mecanismos subjacentes, corrigindo os vieses de alinhamento nas personas dos assistentes ou reforçando as restrições éticas.
À medida que os LLMs assumem funções de missão crítica, essas ferramentas de interpretabilidade tornam-se essenciais para a criação de sistemas de IA confiáveis e auditáveis que se alinham aos valores organizacionais e aos requisitos de conformidade.










 Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
 Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
 Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai

¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?













