
















 Hogar
HogarLa nueva herramienta de Anthropic revela exactamente por qué fracasan los LLM
Los grandes modelos lingüísticos (LLM) están revolucionando las operaciones empresariales, pero sus opacos procesos de toma de decisiones suelen plantear problemas de imprevisibilidad. Para solucionar este problema, Anthropic ha puesto a disposición del público su herramienta de trazado de circuitos, que permite a los desarrolladores echar un vistazo al interior de los modelos y modificar sus mecanismos básicos.
Esta innovadora herramienta ayuda a diagnosticar comportamientos erráticos en modelos de peso abierto, al tiempo que permite un ajuste preciso para aplicaciones empresariales especializadas.
Descodificación de las vías de decisión de la IA
La herramienta aprovecha la "interpretabilidad mecanicista", es decir, analiza las activaciones neuronales en lugar de limitarse a las entradas y salidas. Desarrollada originalmente para Claude 3.5 Haiku, ahora funciona con modelos como Gemma-2-2b y Llama-3.2-1b, con cuadernos Colab de instrucciones.
Sus gráficos de atribución funcionan como planos de inteligencia artificial que muestran cómo interactúan las características internas durante el razonamiento. Los investigadores pueden modificar experimentalmente estas vías neuronales y observar los cambios de comportamiento, depurando esencialmente la cognición de la IA.
La integración con Neuronpedia crea un ecosistema abierto para la experimentación con redes neuronales.
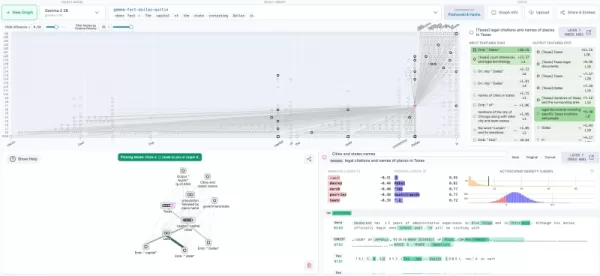
Visualización del trazado de circuitos en Neuronpedia (fuente: Anthropic blog) Hoja de ruta para la implantación empresarial
Aunque innovadora, la herramienta se enfrenta a obstáculos como la elevada demanda de memoria y los complejos requisitos de interpretación, retos típicos de la investigación en las fronteras del conocimiento. Su naturaleza de código abierto acelera las mejoras impulsadas por la comunidad hacia soluciones escalables y automatizadas.
A medida que la tecnología madura, surgen ventajas prácticas para las empresas:
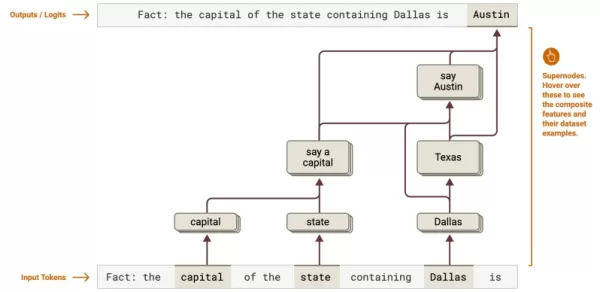
Fuente: Anthropic Mapeo cognitivo: Revela cadenas de razonamiento de varios pasos, como la determinación de la capital de Texas de Dallas a Austin. Las empresas pueden optimizar flujos de trabajo complejos en el análisis jurídico o el procesamiento de datos.
Transparencia numérica: Expone métodos de cálculo únicos, detectando errores aritméticos en modelos financieros al tiempo que garantiza la integridad computacional.
Coherencia multilingüe: Identifica los circuitos universales frente a los específicos de cada idioma, solucionando problemas de localización en implantaciones globales.
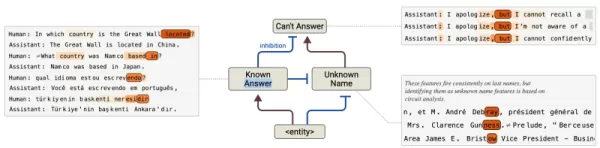
Reducción de alucinaciones: Localiza circuitos de "rechazo por defecto" defectuosos que provocan respuestas inexactas cuando se anulan.
Fuente: Anthropic Más allá de la resolución de problemas, estos conocimientos permiten una optimización quirúrgica del modelo. En lugar de retocar los resultados superficiales, las empresas pueden ajustar directamente los mecanismos subyacentes, corrigiendo los sesgos de alineación de los asistentes personales o reforzando las restricciones éticas.
A medida que los LLM asumen funciones de misión crítica, estas herramientas de interpretabilidad resultan esenciales para crear sistemas de IA fiables y auditables que se ajusten a los valores de la organización y a los requisitos de cumplimiento.
Artículo relacionado
 Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
Sistemas de IA engañados para aprobar artículos científicos absurdos
Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos elude
Recomendaciones de temas especiales relacionados
Productividad
Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
Sistemas de IA engañados para aprobar artículos científicos absurdos
Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos elude
Recomendaciones de temas especiales relacionados
Productividad
 Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
 10 herramientas
10 herramientas
 xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai
Análisis de datos
Las mejores herramientas de visualización de datos con IA: genera automáticamente paneles de BI interactivos a partir de archivos sin procesar
Descubre las mejores herramientas de visualización de datos con IA de 2026 en XIX.AI. Nuestra selección, cuidadosamente elegida y con las mejores valoraciones, te ayuda a generar automáticamente y al instante potentes paneles de BI interactivos a partir de archivos sin procesar. Compara las opciones gratuitas con las de pago mediante pruebas en condiciones reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo todo el potencial de tus datos.
10 herramientas
xix.ai

 comentario (2)
0/500
comentario (2)
0/500
![ScottPerez]()
¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
![BruceMartínez]()
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?
Los grandes modelos lingüísticos (LLM) están revolucionando las operaciones empresariales, pero sus opacos procesos de toma de decisiones suelen plantear problemas de imprevisibilidad. Para solucionar este problema, Anthropic ha puesto a disposición del público su herramienta de trazado de circuitos, que permite a los desarrolladores echar un vistazo al interior de los modelos y modificar sus mecanismos básicos.
Esta innovadora herramienta ayuda a diagnosticar comportamientos erráticos en modelos de peso abierto, al tiempo que permite un ajuste preciso para aplicaciones empresariales especializadas.
Descodificación de las vías de decisión de la IA
La herramienta aprovecha la "interpretabilidad mecanicista", es decir, analiza las activaciones neuronales en lugar de limitarse a las entradas y salidas. Desarrollada originalmente para Claude 3.5 Haiku, ahora funciona con modelos como Gemma-2-2b y Llama-3.2-1b, con cuadernos Colab de instrucciones.
Sus gráficos de atribución funcionan como planos de inteligencia artificial que muestran cómo interactúan las características internas durante el razonamiento. Los investigadores pueden modificar experimentalmente estas vías neuronales y observar los cambios de comportamiento, depurando esencialmente la cognición de la IA.
La integración con Neuronpedia crea un ecosistema abierto para la experimentación con redes neuronales.
Hoja de ruta para la implantación empresarial
Aunque innovadora, la herramienta se enfrenta a obstáculos como la elevada demanda de memoria y los complejos requisitos de interpretación, retos típicos de la investigación en las fronteras del conocimiento. Su naturaleza de código abierto acelera las mejoras impulsadas por la comunidad hacia soluciones escalables y automatizadas.
A medida que la tecnología madura, surgen ventajas prácticas para las empresas:
Mapeo cognitivo: Revela cadenas de razonamiento de varios pasos, como la determinación de la capital de Texas de Dallas a Austin. Las empresas pueden optimizar flujos de trabajo complejos en el análisis jurídico o el procesamiento de datos.
Transparencia numérica: Expone métodos de cálculo únicos, detectando errores aritméticos en modelos financieros al tiempo que garantiza la integridad computacional.
Coherencia multilingüe: Identifica los circuitos universales frente a los específicos de cada idioma, solucionando problemas de localización en implantaciones globales.
Reducción de alucinaciones: Localiza circuitos de "rechazo por defecto" defectuosos que provocan respuestas inexactas cuando se anulan.
Más allá de la resolución de problemas, estos conocimientos permiten una optimización quirúrgica del modelo. En lugar de retocar los resultados superficiales, las empresas pueden ajustar directamente los mecanismos subyacentes, corrigiendo los sesgos de alineación de los asistentes personales o reforzando las restricciones éticas.
A medida que los LLM asumen funciones de misión crítica, estas herramientas de interpretabilidad resultan esenciales para crear sistemas de IA fiables y auditables que se ajusten a los valores de la organización y a los requisitos de cumplimiento.










 Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
 Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
 Sistemas de IA engañados para aprobar artículos científicos absurdos
Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos elude
Sistemas de IA engañados para aprobar artículos científicos absurdos
Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos elude

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

Descubre las mejores herramientas de visualización de datos con IA de 2026 en XIX.AI. Nuestra selección, cuidadosamente elegida y con las mejores valoraciones, te ayuda a generar automáticamente y al instante potentes paneles de BI interactivos a partir de archivos sin procesar. Compara las opciones gratuitas con las de pago mediante pruebas en condiciones reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo todo el potencial de tus datos.
10 herramientas
xix.ai

¡Qué herramienta más necesaria! Siempre me ha dado desconfianza que estos modelos tan poderosos funcionen como una 'caja negra'. Que Anthropic abra esto, aunque sea un primer paso, me parece crucial para avanzar con más responsabilidad. ¿Creéis que pronto será algo estándar en todas las APIs? 🤔 Esta transparencia es clave para usos serios en empresas.
This tool could be a game-changer for debugging LLM failures! 🌟 Finally some transparency in these black boxes. Makes me wonder if other AI labs will follow suit with similar diagnostic tools. However, the real question is: will this actually help prevent those weird biased outputs we sometimes see?













