




Meta de Meta Modelo de referencia de Meta: ¿engañoso?

Entonces, Meta lanzó su nuevo modelo de IA, Maverick, durante el fin de semana, y ya está causando revuelo al obtener el segundo lugar en LM Arena. Sabes, ese es el lugar donde los humanos pueden jugar a ser jueces y jurado, comparando diferentes modelos de IA y eligiendo sus favoritos. Pero, ¡espera, hay un giro! Resulta que la versión de Maverick que está mostrando sus habilidades en LM Arena no es exactamente la misma que puedes descargar y usar como desarrollador.
Algunos investigadores de IA con ojos de águila en X (sí, la plataforma antes conocida como Twitter) notaron que Meta llamó a la versión de LM Arena una "versión de chat experimental". Y si echas un vistazo al sitio web de Llama, hay un gráfico que revela la verdad, diciendo que las pruebas se realizaron con "Llama 4 Maverick optimizado para la conversacionalidad". Ahora, hemos hablado de esto antes, pero LM Arena no es exactamente el estándar de oro para medir el rendimiento de la IA. La mayoría de las empresas de IA no modifican sus modelos solo para obtener mejores resultados en esta prueba, o al menos, no lo admiten.
El problema es que cuando ajustas un modelo para destacar en un benchmark pero luego lanzas una versión "vainilla" diferente al público, es difícil para los desarrolladores entender cómo funcionará realmente el modelo en escenarios del mundo real. Además, es un poco engañoso, ¿verdad? Los benchmarks, imperfectos como son, deberían darnos una imagen clara de lo que un modelo puede y no puede hacer en diferentes tareas.
Los investigadores en X han sido rápidos en notar algunas grandes diferencias entre el Maverick que puedes descargar y el que está en LM Arena. La versión de Arena aparentemente se centra mucho en los emojis y le encanta darte respuestas largas y detalladas.
Okay Llama 4 is def a littled cooked lol, what is this yap city pic.twitter.com/y3GvhbVz65
— Nathan Lambert (@natolambert) April 6, 2025
por alguna razón, el modelo Llama 4 en Arena usa muchos más emojis
en together.ai, parece mejor: pic.twitter.com/f74ODX4zTt
— Tech Dev Notes (@techdevnotes) April 6, 2025
Hemos contactado a Meta y a los responsables de Chatbot Arena, quienes gestionan LM Arena, para ver qué tienen que decir sobre todo esto. ¡Mantente atento!
Artículo relacionado
 Zuckerberg de Meta dice que no todos los modelos de "superinteligencia" de IA serán de código abierto
Cambio estratégico de Meta hacia la superinteligencia personalEl consejero delegado de Meta, Mark Zuckerberg, esbozó esta semana una ambiciosa visión de la "superinteligencia personal" -sistemas de IA
La IA de Meta aborda el doblaje de vídeos para contenidos de Instagram
Meta está ampliando el acceso a su innovadora tecnología de doblaje impulsada por IA a través de Facebook e Instagram, introduciendo capacidades de traducción de vídeo sin fisuras que mantienen tu voz
Aplicación de Meta AI para Introducir un Nivel Premium y Anuncios
La aplicación de IA de Meta pronto podría incluir una suscripción de pago, siguiendo el modelo de competidores como OpenAI, Google y Microsoft. Durante una llamada de resultados del primer trimestre d
comentario (36)
0/200
Zuckerberg de Meta dice que no todos los modelos de "superinteligencia" de IA serán de código abierto
Cambio estratégico de Meta hacia la superinteligencia personalEl consejero delegado de Meta, Mark Zuckerberg, esbozó esta semana una ambiciosa visión de la "superinteligencia personal" -sistemas de IA
La IA de Meta aborda el doblaje de vídeos para contenidos de Instagram
Meta está ampliando el acceso a su innovadora tecnología de doblaje impulsada por IA a través de Facebook e Instagram, introduciendo capacidades de traducción de vídeo sin fisuras que mantienen tu voz
Aplicación de Meta AI para Introducir un Nivel Premium y Anuncios
La aplicación de IA de Meta pronto podría incluir una suscripción de pago, siguiendo el modelo de competidores como OpenAI, Google y Microsoft. Durante una llamada de resultados del primer trimestre d
comentario (36)
0/200
![ScottWalker]() ScottWalker
ScottWalker
 28 de julio de 2025 03:20:54 GMT+02:00
28 de julio de 2025 03:20:54 GMT+02:00
Meta's Maverick hitting second on LM Arena? Impressive, but I'm skeptical about those benchmarks. Feels like a hype train—wonder if it’s more flash than substance. 🤔 Anyone tested it in real-world tasks yet?


 0
0
![KennethMartin]() KennethMartin
21 de abril de 2025 12:14:21 GMT+02:00
KennethMartin
21 de abril de 2025 12:14:21 GMT+02:00
Meta's Maverick AI model is impressive, snagging second place on LM Arena! But are the benchmarks really telling the whole story? It's cool to see AI models go head-to-head, but I'm not sure if it's all fair play. Makes you wonder, right? 🤔 Maybe we need a more transparent way to judge these models!
0
![WalterThomas]() WalterThomas
21 de abril de 2025 04:55:14 GMT+02:00
WalterThomas
21 de abril de 2025 04:55:14 GMT+02:00
मेटा का नया AI मॉडल, मैवरिक, LM एरिना में दूसरे स्थान पर पहुंचा! यह प्रभावशाली है, लेकिन क्या बेंचमार्क वास्तव में पूरी कहानी बता रहे हैं? AI मॉडल्स को आपस में प्रतिस्पर्धा करते देखना मजेदार है, लेकिन मुझे नहीं पता कि यह निष्पक्ष है या नहीं। आपको सोचने पर मजबूर करता है, है ना? 🤔 शायद हमें इन मॉडल्स को जज करने का एक और पारदर्शी तरीका चाहिए!
0
![JohnYoung]() JohnYoung
18 de abril de 2025 17:03:42 GMT+02:00
JohnYoung
18 de abril de 2025 17:03:42 GMT+02:00
메타의 새로운 AI 모델, 마브릭이 LM Arena에서 2위를 차지하다니 대단해요! 하지만 벤치마크가 정말 모든 것을 말해주고 있는지 궁금해요. AI 모델 간의 경쟁은 재미있지만, 공정한지 확신할 수 없네요. 더 투명한 평가 방법이 필요할 것 같아요 🤔
0
![JohnHernández]() JohnHernández
17 de abril de 2025 18:58:48 GMT+02:00
JohnHernández
17 de abril de 2025 18:58:48 GMT+02:00
Meta's Maverick AI model snagging second place on LM Arena is pretty cool, but the benchmarks might be a bit off! 🤔 It's fun to see these models go head-to-head, but I'm not sure if the results are totally fair. Worth keeping an eye on! 👀
0
![MarkScott]() MarkScott
17 de abril de 2025 07:54:17 GMT+02:00
MarkScott
17 de abril de 2025 07:54:17 GMT+02:00
Модель ИИ Maverick от Meta заняла второе место на LM Arena, это круто, но бенчмарки могут быть немного не точными! 🤔 Забавно наблюдать за соревнованием этих моделей, но я не уверен, что результаты полностью справедливы. Стоит за этим следить! 👀
0
Entonces, Meta lanzó su nuevo modelo de IA, Maverick, durante el fin de semana, y ya está causando revuelo al obtener el segundo lugar en LM Arena. Sabes, ese es el lugar donde los humanos pueden jugar a ser jueces y jurado, comparando diferentes modelos de IA y eligiendo sus favoritos. Pero, ¡espera, hay un giro! Resulta que la versión de Maverick que está mostrando sus habilidades en LM Arena no es exactamente la misma que puedes descargar y usar como desarrollador.
Algunos investigadores de IA con ojos de águila en X (sí, la plataforma antes conocida como Twitter) notaron que Meta llamó a la versión de LM Arena una "versión de chat experimental". Y si echas un vistazo al sitio web de Llama, hay un gráfico que revela la verdad, diciendo que las pruebas se realizaron con "Llama 4 Maverick optimizado para la conversacionalidad". Ahora, hemos hablado de esto antes, pero LM Arena no es exactamente el estándar de oro para medir el rendimiento de la IA. La mayoría de las empresas de IA no modifican sus modelos solo para obtener mejores resultados en esta prueba, o al menos, no lo admiten.
El problema es que cuando ajustas un modelo para destacar en un benchmark pero luego lanzas una versión "vainilla" diferente al público, es difícil para los desarrolladores entender cómo funcionará realmente el modelo en escenarios del mundo real. Además, es un poco engañoso, ¿verdad? Los benchmarks, imperfectos como son, deberían darnos una imagen clara de lo que un modelo puede y no puede hacer en diferentes tareas.
Los investigadores en X han sido rápidos en notar algunas grandes diferencias entre el Maverick que puedes descargar y el que está en LM Arena. La versión de Arena aparentemente se centra mucho en los emojis y le encanta darte respuestas largas y detalladas.
Okay Llama 4 is def a littled cooked lol, what is this yap city pic.twitter.com/y3GvhbVz65
— Nathan Lambert (@natolambert) April 6, 2025
por alguna razón, el modelo Llama 4 en Arena usa muchos más emojis
— Tech Dev Notes (@techdevnotes) April 6, 2025
en together.ai, parece mejor: pic.twitter.com/f74ODX4zTt
Hemos contactado a Meta y a los responsables de Chatbot Arena, quienes gestionan LM Arena, para ver qué tienen que decir sobre todo esto. ¡Mantente atento!










 Zuckerberg de Meta dice que no todos los modelos de "superinteligencia" de IA serán de código abierto
Cambio estratégico de Meta hacia la superinteligencia personalEl consejero delegado de Meta, Mark Zuckerberg, esbozó esta semana una ambiciosa visión de la "superinteligencia personal" -sistemas de IA
Zuckerberg de Meta dice que no todos los modelos de "superinteligencia" de IA serán de código abierto
Cambio estratégico de Meta hacia la superinteligencia personalEl consejero delegado de Meta, Mark Zuckerberg, esbozó esta semana una ambiciosa visión de la "superinteligencia personal" -sistemas de IA
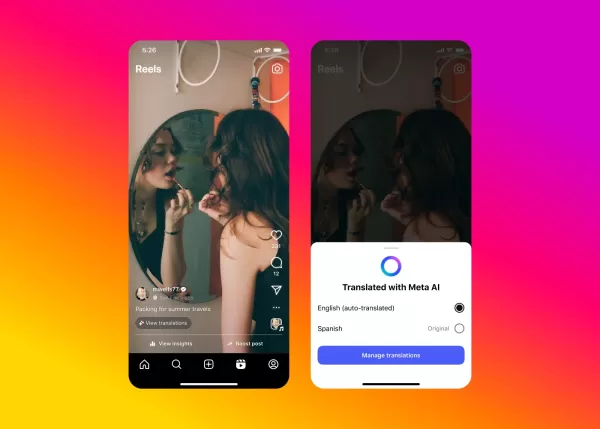 La IA de Meta aborda el doblaje de vídeos para contenidos de Instagram
Meta está ampliando el acceso a su innovadora tecnología de doblaje impulsada por IA a través de Facebook e Instagram, introduciendo capacidades de traducción de vídeo sin fisuras que mantienen tu voz
La IA de Meta aborda el doblaje de vídeos para contenidos de Instagram
Meta está ampliando el acceso a su innovadora tecnología de doblaje impulsada por IA a través de Facebook e Instagram, introduciendo capacidades de traducción de vídeo sin fisuras que mantienen tu voz
 Aplicación de Meta AI para Introducir un Nivel Premium y Anuncios
La aplicación de IA de Meta pronto podría incluir una suscripción de pago, siguiendo el modelo de competidores como OpenAI, Google y Microsoft. Durante una llamada de resultados del primer trimestre d
28 de julio de 2025 03:20:54 GMT+02:00
Aplicación de Meta AI para Introducir un Nivel Premium y Anuncios
La aplicación de IA de Meta pronto podría incluir una suscripción de pago, siguiendo el modelo de competidores como OpenAI, Google y Microsoft. Durante una llamada de resultados del primer trimestre d
28 de julio de 2025 03:20:54 GMT+02:00
Meta's Maverick hitting second on LM Arena? Impressive, but I'm skeptical about those benchmarks. Feels like a hype train—wonder if it’s more flash than substance. 🤔 Anyone tested it in real-world tasks yet?
0
21 de abril de 2025 12:14:21 GMT+02:00
Meta's Maverick AI model is impressive, snagging second place on LM Arena! But are the benchmarks really telling the whole story? It's cool to see AI models go head-to-head, but I'm not sure if it's all fair play. Makes you wonder, right? 🤔 Maybe we need a more transparent way to judge these models!
0
21 de abril de 2025 04:55:14 GMT+02:00
मेटा का नया AI मॉडल, मैवरिक, LM एरिना में दूसरे स्थान पर पहुंचा! यह प्रभावशाली है, लेकिन क्या बेंचमार्क वास्तव में पूरी कहानी बता रहे हैं? AI मॉडल्स को आपस में प्रतिस्पर्धा करते देखना मजेदार है, लेकिन मुझे नहीं पता कि यह निष्पक्ष है या नहीं। आपको सोचने पर मजबूर करता है, है ना? 🤔 शायद हमें इन मॉडल्स को जज करने का एक और पारदर्शी तरीका चाहिए!
0
18 de abril de 2025 17:03:42 GMT+02:00
메타의 새로운 AI 모델, 마브릭이 LM Arena에서 2위를 차지하다니 대단해요! 하지만 벤치마크가 정말 모든 것을 말해주고 있는지 궁금해요. AI 모델 간의 경쟁은 재미있지만, 공정한지 확신할 수 없네요. 더 투명한 평가 방법이 필요할 것 같아요 🤔
0
17 de abril de 2025 18:58:48 GMT+02:00
Meta's Maverick AI model snagging second place on LM Arena is pretty cool, but the benchmarks might be a bit off! 🤔 It's fun to see these models go head-to-head, but I'm not sure if the results are totally fair. Worth keeping an eye on! 👀
0
17 de abril de 2025 07:54:17 GMT+02:00
Модель ИИ Maverick от Meta заняла второе место на LM Arena, это круто, но бенчмарки могут быть немного не точными! 🤔 Забавно наблюдать за соревнованием этих моделей, но я не уверен, что результаты полностью справедливы. Стоит за этим следить! 👀
0













