




Meta的AI模型基准:误导性?

Meta 在周末发布了他们的新 AI 模型 Maverick,它已经在 LM Arena 上掀起波澜,夺得了第二名的位置。你知道的,那个地方是人类扮演法官和陪审团的角色,比较不同的 AI 模型并挑选他们喜欢的。不过,等等,有个转折!结果发现,在 LM Arena 上展示风采的 Maverick 版本,与开发者可以下载和使用的版本并不完全相同。
一些敏锐的 AI 研究者在 X(是的,那个以前叫 Twitter 的平台)上发现,Meta 将 LM Arena 版本称为“实验性聊天版本”。如果你去 Llama 网站上看,有一张图表透露了细节,称测试使用的是“为对话优化设计的 Llama 4 Maverick”。我们之前讨论过这个,但 LM Arena 并不是衡量 AI 性能的黄金标准。大多数 AI 公司不会为了在这个测试中得分更高而专门调整模型——或者至少,他们不会承认这样做。
问题是,当你调整一个模型以在基准测试中表现出色,但随后向公众发布一个不同的“普通”版本时,开发者很难弄清楚这个模型在现实场景中的实际表现如何。而且,这有点误导,对吧?基准测试虽然有缺陷,但应该为我们提供模型在不同任务中能做什么和不能做什么的清晰图景。
X 上的研究者很快就注意到,你可以下载的 Maverick 和 LM Arena 上的版本之间存在一些重大差异。Arena 版本似乎特别喜欢使用表情符号,而且回答总是冗长而拖沓。
好吧,Llama 4 确实有点过头了,哈哈,这是什么啰嗦之城 pic.twitter.com/y3GvhbVz65
— Nathan Lambert (@natolambert) 2025年4月6日
出于某种原因,Arena 中的 Llama 4 模型使用了更多的表情符号
在 together.ai 上,它似乎表现更好:pic.twitter.com/f74ODX4zTt
— Tech Dev Notes (@techdevnotes) 2025年4月6日
我们已经联系了 Meta 和运行 LM Arena 的 Chatbot Arena 团队,看看他们对此有什么说法。敬请期待!
相关文章
 Meta公司的扎克伯格称并非所有人工智能 "超级智能 "模型都将开源
Meta 向个人超级智能的战略转变Meta 公司首席执行官马克-扎克伯格(Mark Zuckerberg)本周概述了 "个人超级智能 "的宏伟愿景--人工智能系统可帮助个人实现个人目标--这标志着该公司的人工智能部署战略可能会发生变化。开源困境扎克伯格的声明表明,在追求超级智能系统的过程中,Meta 可能会重新考虑其开源先进人工智能模型的承诺:"我们相信超级智能的好处应该尽可能广泛地与世界分享..
Meta 的人工智能为 Instagram 内容进行视频配音
Meta 将其突破性的人工智能配音技术推广到 Facebook 和 Instagram,推出无缝视频翻译功能,以保持您真实的声音和自然的嘴唇动作。革新跨文化内容Meta 的新人工智能翻译功能可自动在英语和西班牙语之间转换 Reels,同时保留创作者的声音特征和唇部同步。这项创新是在去年 Meta Connect 活动期间展示的技术基础上进行的,为内容创作者提供了强大的工具,以吸引国际观众。工作原理
Meta AI应用将引入高级订阅和广告
Meta的AI应用可能很快推出付费订阅服务,效仿OpenAI、Google和Microsoft等竞争对手的做法。在2025年第一季度财报电话会议上,Meta首席执行官马克·扎克伯格概述了高级服务的计划,使用户能够访问增强的计算能力或Meta AI的额外功能。为了与ChatGPT竞争,Meta本周推出了一款独立AI应用,允许用户直接与聊天机器人互动并进行图像生成。该聊天机器人目前拥有近10亿用户,此
评论 (36)
0/200
Meta公司的扎克伯格称并非所有人工智能 "超级智能 "模型都将开源
Meta 向个人超级智能的战略转变Meta 公司首席执行官马克-扎克伯格(Mark Zuckerberg)本周概述了 "个人超级智能 "的宏伟愿景--人工智能系统可帮助个人实现个人目标--这标志着该公司的人工智能部署战略可能会发生变化。开源困境扎克伯格的声明表明,在追求超级智能系统的过程中,Meta 可能会重新考虑其开源先进人工智能模型的承诺:"我们相信超级智能的好处应该尽可能广泛地与世界分享..
Meta 的人工智能为 Instagram 内容进行视频配音
Meta 将其突破性的人工智能配音技术推广到 Facebook 和 Instagram,推出无缝视频翻译功能,以保持您真实的声音和自然的嘴唇动作。革新跨文化内容Meta 的新人工智能翻译功能可自动在英语和西班牙语之间转换 Reels,同时保留创作者的声音特征和唇部同步。这项创新是在去年 Meta Connect 活动期间展示的技术基础上进行的,为内容创作者提供了强大的工具,以吸引国际观众。工作原理
Meta AI应用将引入高级订阅和广告
Meta的AI应用可能很快推出付费订阅服务,效仿OpenAI、Google和Microsoft等竞争对手的做法。在2025年第一季度财报电话会议上,Meta首席执行官马克·扎克伯格概述了高级服务的计划,使用户能够访问增强的计算能力或Meta AI的额外功能。为了与ChatGPT竞争,Meta本周推出了一款独立AI应用,允许用户直接与聊天机器人互动并进行图像生成。该聊天机器人目前拥有近10亿用户,此
评论 (36)
0/200
![ScottWalker]() ScottWalker
ScottWalker
 2025-07-28 09:20:54
2025-07-28 09:20:54
Meta's Maverick hitting second on LM Arena? Impressive, but I'm skeptical about those benchmarks. Feels like a hype train—wonder if it’s more flash than substance. 🤔 Anyone tested it in real-world tasks yet?


 0
0
![KennethMartin]() KennethMartin
2025-04-21 18:14:21
KennethMartin
2025-04-21 18:14:21
Meta's Maverick AI model is impressive, snagging second place on LM Arena! But are the benchmarks really telling the whole story? It's cool to see AI models go head-to-head, but I'm not sure if it's all fair play. Makes you wonder, right? 🤔 Maybe we need a more transparent way to judge these models!
0
![WalterThomas]() WalterThomas
2025-04-21 10:55:14
WalterThomas
2025-04-21 10:55:14
मेटा का नया AI मॉडल, मैवरिक, LM एरिना में दूसरे स्थान पर पहुंचा! यह प्रभावशाली है, लेकिन क्या बेंचमार्क वास्तव में पूरी कहानी बता रहे हैं? AI मॉडल्स को आपस में प्रतिस्पर्धा करते देखना मजेदार है, लेकिन मुझे नहीं पता कि यह निष्पक्ष है या नहीं। आपको सोचने पर मजबूर करता है, है ना? 🤔 शायद हमें इन मॉडल्स को जज करने का एक और पारदर्शी तरीका चाहिए!
0
![JohnYoung]() JohnYoung
2025-04-18 23:03:42
JohnYoung
2025-04-18 23:03:42
메타의 새로운 AI 모델, 마브릭이 LM Arena에서 2위를 차지하다니 대단해요! 하지만 벤치마크가 정말 모든 것을 말해주고 있는지 궁금해요. AI 모델 간의 경쟁은 재미있지만, 공정한지 확신할 수 없네요. 더 투명한 평가 방법이 필요할 것 같아요 🤔
0
![JohnHernández]() JohnHernández
2025-04-18 00:58:48
JohnHernández
2025-04-18 00:58:48
Meta's Maverick AI model snagging second place on LM Arena is pretty cool, but the benchmarks might be a bit off! 🤔 It's fun to see these models go head-to-head, but I'm not sure if the results are totally fair. Worth keeping an eye on! 👀
0
![MarkScott]() MarkScott
2025-04-17 13:54:17
MarkScott
2025-04-17 13:54:17
Модель ИИ Maverick от Meta заняла второе место на LM Arena, это круто, но бенчмарки могут быть немного не точными! 🤔 Забавно наблюдать за соревнованием этих моделей, но я не уверен, что результаты полностью справедливы. Стоит за этим следить! 👀
0
Meta 在周末发布了他们的新 AI 模型 Maverick,它已经在 LM Arena 上掀起波澜,夺得了第二名的位置。你知道的,那个地方是人类扮演法官和陪审团的角色,比较不同的 AI 模型并挑选他们喜欢的。不过,等等,有个转折!结果发现,在 LM Arena 上展示风采的 Maverick 版本,与开发者可以下载和使用的版本并不完全相同。
一些敏锐的 AI 研究者在 X(是的,那个以前叫 Twitter 的平台)上发现,Meta 将 LM Arena 版本称为“实验性聊天版本”。如果你去 Llama 网站上看,有一张图表透露了细节,称测试使用的是“为对话优化设计的 Llama 4 Maverick”。我们之前讨论过这个,但 LM Arena 并不是衡量 AI 性能的黄金标准。大多数 AI 公司不会为了在这个测试中得分更高而专门调整模型——或者至少,他们不会承认这样做。
问题是,当你调整一个模型以在基准测试中表现出色,但随后向公众发布一个不同的“普通”版本时,开发者很难弄清楚这个模型在现实场景中的实际表现如何。而且,这有点误导,对吧?基准测试虽然有缺陷,但应该为我们提供模型在不同任务中能做什么和不能做什么的清晰图景。
X 上的研究者很快就注意到,你可以下载的 Maverick 和 LM Arena 上的版本之间存在一些重大差异。Arena 版本似乎特别喜欢使用表情符号,而且回答总是冗长而拖沓。
好吧,Llama 4 确实有点过头了,哈哈,这是什么啰嗦之城 pic.twitter.com/y3GvhbVz65
— Nathan Lambert (@natolambert) 2025年4月6日
出于某种原因,Arena 中的 Llama 4 模型使用了更多的表情符号
— Tech Dev Notes (@techdevnotes) 2025年4月6日
在 together.ai 上,它似乎表现更好:pic.twitter.com/f74ODX4zTt
我们已经联系了 Meta 和运行 LM Arena 的 Chatbot Arena 团队,看看他们对此有什么说法。敬请期待!










 Meta公司的扎克伯格称并非所有人工智能 "超级智能 "模型都将开源
Meta 向个人超级智能的战略转变Meta 公司首席执行官马克-扎克伯格(Mark Zuckerberg)本周概述了 "个人超级智能 "的宏伟愿景--人工智能系统可帮助个人实现个人目标--这标志着该公司的人工智能部署战略可能会发生变化。开源困境扎克伯格的声明表明,在追求超级智能系统的过程中,Meta 可能会重新考虑其开源先进人工智能模型的承诺:"我们相信超级智能的好处应该尽可能广泛地与世界分享..
Meta公司的扎克伯格称并非所有人工智能 "超级智能 "模型都将开源
Meta 向个人超级智能的战略转变Meta 公司首席执行官马克-扎克伯格(Mark Zuckerberg)本周概述了 "个人超级智能 "的宏伟愿景--人工智能系统可帮助个人实现个人目标--这标志着该公司的人工智能部署战略可能会发生变化。开源困境扎克伯格的声明表明,在追求超级智能系统的过程中,Meta 可能会重新考虑其开源先进人工智能模型的承诺:"我们相信超级智能的好处应该尽可能广泛地与世界分享..
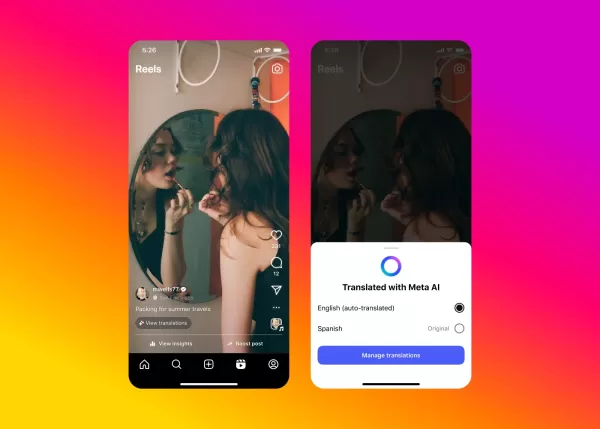 Meta 的人工智能为 Instagram 内容进行视频配音
Meta 将其突破性的人工智能配音技术推广到 Facebook 和 Instagram,推出无缝视频翻译功能,以保持您真实的声音和自然的嘴唇动作。革新跨文化内容Meta 的新人工智能翻译功能可自动在英语和西班牙语之间转换 Reels,同时保留创作者的声音特征和唇部同步。这项创新是在去年 Meta Connect 活动期间展示的技术基础上进行的,为内容创作者提供了强大的工具,以吸引国际观众。工作原理
Meta 的人工智能为 Instagram 内容进行视频配音
Meta 将其突破性的人工智能配音技术推广到 Facebook 和 Instagram,推出无缝视频翻译功能,以保持您真实的声音和自然的嘴唇动作。革新跨文化内容Meta 的新人工智能翻译功能可自动在英语和西班牙语之间转换 Reels,同时保留创作者的声音特征和唇部同步。这项创新是在去年 Meta Connect 活动期间展示的技术基础上进行的,为内容创作者提供了强大的工具,以吸引国际观众。工作原理
 Meta AI应用将引入高级订阅和广告
Meta的AI应用可能很快推出付费订阅服务,效仿OpenAI、Google和Microsoft等竞争对手的做法。在2025年第一季度财报电话会议上,Meta首席执行官马克·扎克伯格概述了高级服务的计划,使用户能够访问增强的计算能力或Meta AI的额外功能。为了与ChatGPT竞争,Meta本周推出了一款独立AI应用,允许用户直接与聊天机器人互动并进行图像生成。该聊天机器人目前拥有近10亿用户,此
2025-07-28 09:20:54
Meta AI应用将引入高级订阅和广告
Meta的AI应用可能很快推出付费订阅服务,效仿OpenAI、Google和Microsoft等竞争对手的做法。在2025年第一季度财报电话会议上,Meta首席执行官马克·扎克伯格概述了高级服务的计划,使用户能够访问增强的计算能力或Meta AI的额外功能。为了与ChatGPT竞争,Meta本周推出了一款独立AI应用,允许用户直接与聊天机器人互动并进行图像生成。该聊天机器人目前拥有近10亿用户,此
2025-07-28 09:20:54
Meta's Maverick hitting second on LM Arena? Impressive, but I'm skeptical about those benchmarks. Feels like a hype train—wonder if it’s more flash than substance. 🤔 Anyone tested it in real-world tasks yet?
0
2025-04-21 18:14:21
Meta's Maverick AI model is impressive, snagging second place on LM Arena! But are the benchmarks really telling the whole story? It's cool to see AI models go head-to-head, but I'm not sure if it's all fair play. Makes you wonder, right? 🤔 Maybe we need a more transparent way to judge these models!
0
2025-04-21 10:55:14
मेटा का नया AI मॉडल, मैवरिक, LM एरिना में दूसरे स्थान पर पहुंचा! यह प्रभावशाली है, लेकिन क्या बेंचमार्क वास्तव में पूरी कहानी बता रहे हैं? AI मॉडल्स को आपस में प्रतिस्पर्धा करते देखना मजेदार है, लेकिन मुझे नहीं पता कि यह निष्पक्ष है या नहीं। आपको सोचने पर मजबूर करता है, है ना? 🤔 शायद हमें इन मॉडल्स को जज करने का एक और पारदर्शी तरीका चाहिए!
0
2025-04-18 23:03:42
메타의 새로운 AI 모델, 마브릭이 LM Arena에서 2위를 차지하다니 대단해요! 하지만 벤치마크가 정말 모든 것을 말해주고 있는지 궁금해요. AI 모델 간의 경쟁은 재미있지만, 공정한지 확신할 수 없네요. 더 투명한 평가 방법이 필요할 것 같아요 🤔
0
2025-04-18 00:58:48
Meta's Maverick AI model snagging second place on LM Arena is pretty cool, but the benchmarks might be a bit off! 🤔 It's fun to see these models go head-to-head, but I'm not sure if the results are totally fair. Worth keeping an eye on! 👀
0
2025-04-17 13:54:17
Модель ИИ Maverick от Meta заняла второе место на LM Arena, это круто, но бенчмарки могут быть немного не точными! 🤔 Забавно наблюдать за соревнованием этих моделей, но я не уверен, что результаты полностью справедливы. Стоит за этим следить! 👀
0













