A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts.
The key distinction between watermarking and 'copyright-baiting' is that watermarks—whether visible or hidden—are typically designed to appear throughout a collection (such as an image dataset) as a consistent deterrent against casual copying.
In contrast, a fictitious entry is a small piece of text, often a word or definition placed within a large, generic collection, intended to prove theft. The idea is that when the entire work is copied without permission, either directly or as the basis for a derivative work, the presence of a unique, fabricated fact planted by the original creators easily reveals the theft.
When it comes to watermarking Large Language Models (LLMs) and Vision Language Models (VLMs), the extent to which outputs contain these markers usually falls into two categories: ensuring all or most outputs carry an obvious or hidden watermark; or embedding a 'secret token' that can be recovered to prove theft—without appearing in the model's regular output.
The Weight(s) of Evidence
The latter approach is explored in a new collaboration between researchers in China, Italy, and Singapore. This work aims to provide a disclosure method for open source models, preventing their unauthorized commercialization or use beyond the original license terms.
For example, a model's original license may allow anyone to profit from it as long as they share their modifications under the same generous terms—but a company might try to keep their adjustments (like fine-tuned versions) private to create an unfair advantage.
Most research in this area focuses on detecting misuse in closed-source, API-only models, or models where only optimized (quantized) weights are available. These are harder to edit efficiently using the new paper's approach due to limited access to the model's architecture.
This focus on FOSS releases is perhaps expected from the Chinese research sector, as China's AI output over the past year has been marked by generous full-weight* model releases that rival more restricted Western equivalents.
The new approach, called EditMark, stands out by not requiring fine-tuning to add 'poisoned' data or training from scratch with the data included.
This offers several advantages: first, any 'tell-tale' data included in the training set, once discovered and disclosed, becomes ineffective because attackers can target it directly. But to attack EditMark, a malicious actor would need to know which model layer to target and the method used—an unlikely scenario.
Second, the method is fast and inexpensive, taking just seconds (rather than days or weeks) to apply to a trained model, avoiding the high cost of fine-tuning (which grows with model and data size).
Finally, the approach causes significantly less disruption to the model's normal operation compared to fine-tuning or earlier editing methods.
In tests, EditMark—which embeds mathematical queries with multiple possible answers into the model weights—achieved a 100% extraction rate.
The authors state:
'Comprehensive experiments demonstrate EditMark's exceptional performance in watermarking LLMs. It achieves remarkable efficiency by embedding a 32-bit watermark in under 20 seconds with a 100% extraction success rate (ESR).
'Notably, watermark embedding takes less than 1/300 of the time required for fine-tuning (which averages 6,875 seconds), highlighting EditMark's ability to implement high-capacity watermarks with unprecedented speed and reliability.
'Additionally, extensive experiments confirm EditMark's robustness, stealth, and fidelity.'
The new paper is titled EditMark: Watermarking Large Language Models based on Model Editing and comes from eight authors at the University of Science and Technology of China, the University of Siena, and CFAR/IHPC/A*STAR in Singapore.
Method
The EditMark approach consists of four components: a Generator, an Encoder, an Editor, and a Decoder:
The EditMark pipeline embeds a watermark by editing a model to answer specific mathematical questions in a way that encodes hidden identifying information. Source: https://arxiv.org/pdf/2510.16367
The Generator uses a pseudo-random seed to create multiple-answer math questions; the Encoder selects answers based on the watermark, which are then embedded into the model through a specialized editing process. Once the edited model is released or misused, the watermark can be extracted by asking the same questions and decoding the response patterns.
The Editor then modifies the model weights so that when asked these seeded questions, the model consistently produces the target answers, embedding the watermark directly into its behavior. The Decoder recovers the watermark by feeding the same questions to a suspect model and translating its answers back into the hidden signature.
Threat Model
The paper's threat model assumes watermarking is done in a white-box setting. While this is often a concern in security research, it is normal here since the method aims to protect owners who have full access to their own work.
The attacker is also assumed to have white-box access after obtaining the model, meaning they can modify it (e.g., through pruning or fine-tuning). This scenario is typical for FOSS releases. However, the attacker does not know the watermark extraction process or schema and can only infer it through experimentation or leaks.
The Generator creates logically and factually valid math questions with multiple correct answers, using GPT‑4o to diversify templates (as shown below) and a pseudo‑random seed to ensure each question is unique. This allows a known watermark to be embedded deterministically through answer permutations while minimizing question overlap to avoid edit entanglement:
Templates of questions generated by GPT‑4o for watermark embedding, each structured to yield multiple valid integer answers from a seeded inequality.
The Encoder converts each binary watermark segment into a unique permutation of integers from the solution set of a given math question. Using lexicographical permutation theory, the Encoder maps the decimal value of each watermark chunk to a specific ordered selection of answers, ensuring the watermark is deterministically embedded in the model's behavior.
Regarding the editor, the original AlphaEdit model editing method used for watermarking lacks both precision and resilience, often failing to produce the required answers. Any changes it makes are easily broken by pruning or noise.
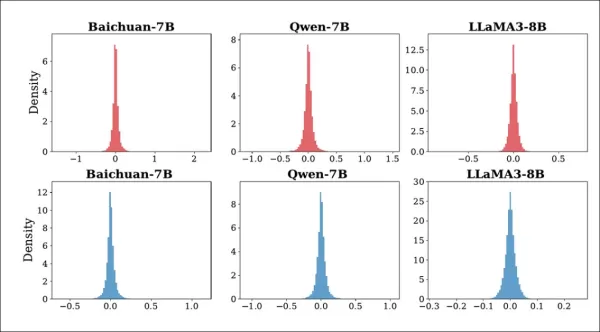
To address this, the authors developed a multi-round editing strategy that gradually adjusts model weights at a single MLP layer until responses align with the desired answers. To harden edits against tampering, Gaussian noise is injected during training to simulate attacks:
Distribution of changes in K1 for Baichuan-7B, Qwen-7B, and LLaMA3-8B before and after attacks. The top row shows the effect of random noise injection; the bottom row shows the effect of model pruning. All changes stay close to zero, suggesting that the attacks do not significantly disrupt the model’s internal behavior.
A scoring system stops the process once edits are accurate enough, while regularization ensures updates remain stable over multiple rounds.
The Decoder asks the model the same special questions used during watermarking, then reads its answers to infer the hidden ID. Since the answer pattern follows a secret rule, this ID can be recovered without examining the model's internals.
Data and Tests
To evaluate EditMark, five LLMs were tested: GPT2-XL; GPT-J-6B; LLaMA-3-8B; Baichuan-7B; and Qwen-7B. The aforementioned AlphaEdit was used to embed watermarks, with extraction success rate (ESR) and embedding time (ET) as the metrics.
For baselines, the authors selected Model Watermark (backdoor); KIMark; and BadEdit, a framework originally designed for backdoor injection, adapted for this project.
The authors edited the 15th layer of LLaMA-3-8B; the 17th layer of GPT2-XL and GPT-J-6B; and the 14th layer of Qwen-7B and Baichuan-7B.
Experiments were conducted on four NVIDIA RTX 4090 GPUs (24GB VRAM each), with watermarks of 32-bit, 64-bit, and 128-bit lengths embedded. The question templates used are detailed below:
Templates used to generate multiple-answer (MA) questions for watermarking. Each question is based on a different type of mathematical inequality, with random values inserted for the variables. The model is asked to return a list of integer solutions, with the order of the answers used to encode or decode watermark bits. The four templates cover quadratic, logarithmic, rational, and interval-based forms, and all were generated using GPT-4o.
To reduce randomness effects, seeds from 1 to 20 were applied during testing across different watermark capacities.
Initially, researchers tested both ESR and time cost for embedding watermarks across the LLMs:
Comparison of EditMark against three prior watermarking methods on five large language models. Reported are the extraction success rate (ESR) and embedding time (ET) in seconds. EditMark consistently achieves a 100% success rate while reducing embedding time by several orders of magnitude, outperforming all baselines in both accuracy and efficiency across models of varying size and architecture.
Of these results, the authors state:
'[EditMark] achieves a 100% ESR and requires less than 20 seconds to embed a 32-bit watermark for all LLMs evaluated. In particular, the average embedding time for Baichuan-7B and Qwen-7B is under 10 seconds, demonstrating EditMark's high efficiency.'
For a 128-bit watermark, the highest feasible value under such a scheme, EditMark maintained 'indelibility':
Extraction success rates and embedding times for EditMark across watermark lengths of 32, 64, and 128 bits across five language models. Perfect success rates are maintained in all cases, while embedding time increases with watermark size, but remains under one minute, even at 128 bits.
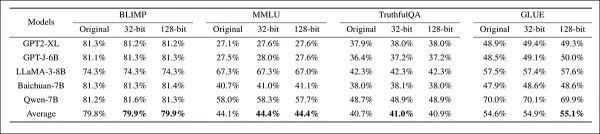
Next, the system's ability to retain watermark fidelity was tested across multiple benchmarks:
Evaluation of watermark fidelity on four benchmarks across five models, comparing unmodified models with models watermarked at 32-bit and 128-bit capacities. Performance remained stable across configurations, with only minor fluctuations in average scores, indicating limited impact on benchmark accuracy from watermark insertion.
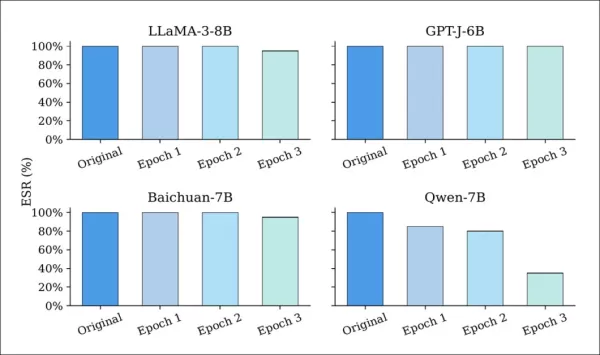
EditMark's resilience was tested against six common attack strategies. Models were first embedded with 128-bit watermarks using five different seeds. Fine-tuning, as shown below, caused only minor degradation in extraction success rates (ESR) for most models:
Extraction success rate (ESR) of watermarked LLMs before and after fine-tuning for one to three epochs. While most models retain high ESR throughout, Qwen-7B shows a marked decline, suggesting greater vulnerability to parameter updates.
Even after multiple epochs, most models retained ESRs above 90%, showing that EditMark resists parameter drift from LoRA-based training.
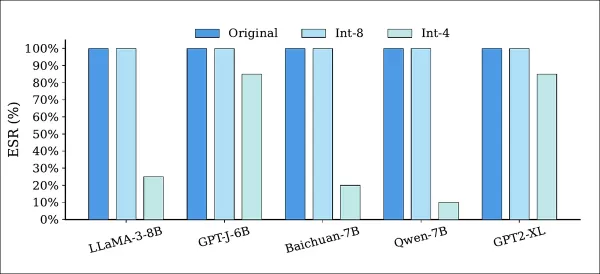
Quantization attacks reduced model precision but left most watermarks intact:
Extraction success rate (ESR) of watermarked models before and after quantization using Int‑8 and Int‑4 precision. ESR remained unchanged under Int‑8 quantization across all models, while Int‑4 quantization caused partial degradation, indicating that lower precision can weaken, but not fully remove the watermark.
As shown above, Int-8 quantization preserved 100% ESR across all models, while Int-4 quantization moderately impacted ESR but introduced unacceptable performance losses.
The paper notes that this scenario offers limited potential for attackers, as it results in a hacked but degraded model.
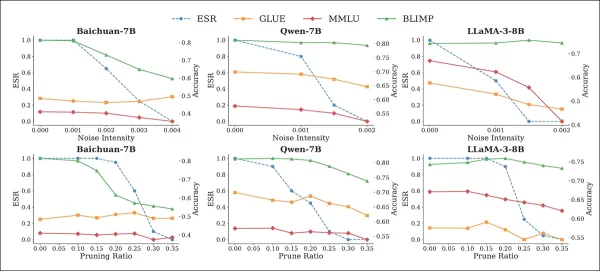
Tests for noise and pruning evaluated four benchmark frameworks: MMLU; BLIMP; TruthfulQA; and GLUE. These attacks led to decreasing ESR as perturbations intensified:
Effect of noise (top row) and pruning (bottom row) attacks on ESR, and benchmark performance of watermarked models. As ESR drops with increasing perturbation, benchmark accuracy also degrades, especially at higher noise intensities and pruning ratios, highlighting the (customary) tension between watermark removal and model utility.
However, these also caused sharp declines in task performance, with Baichuan-7B experiencing a 27-31% drop on BLIMP when noise or pruning was applied.
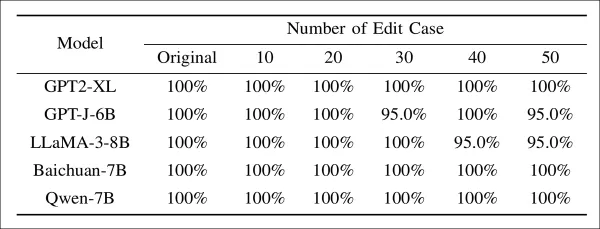
Model editing and adaptive attacks were also evaluated:
Extraction success rate of watermarked models subjected to varying degrees of model editing. Even with up to fifty edits applied to known watermark layers, ESR remains above 95% for all models, indicating that direct parameter modifications have limited effect on watermark removal.
Here, EditMark retained over 95% ESR, even when exact embedding layers were targeted.
Conclusion
DRM, secret watermarks, and other security measures that saw limited success in the pre-AI era are challenging to apply to machine learning systems. The intentionally simplified nature of current host architectures, combined with a lack of suitable tools, makes injected watermarks relatively fragile.
It is impressive to see a system aimed at FOSS model distribution that withstands all but the most unlikely attack scenarios, given an attacker's prior knowledge. However, the slight performance drop from post-training edits, though small in these experiments, may give potential adopters pause—especially since reverting to an API-centric control model almost entirely avoids such attacks.
* This site has argued that 'open weight' releases from China may not fully qualify as FOSS, as data is often withheld, preventing exact replication of the training pipeline. This topic invites a deeper examination of the politics of AI model releases across East and West, which is beyond this article's scope.
Multiverse Computing Launches Free Compressed Generative AI ModelLarge language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
AI Systems Tricked into Approving Absurd Scientific PapersNew research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
Optimization-Driven AI Emerges as New Path to General-Purpose ModelsResearchers from the University of Illinois Urbana-Champaign and the University of Virginia have created a new model architecture that could pave the way for more resilient AI systems with enhanced reasoning power.Named the energy-based transformer (
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
Wow, dieses Thema mit unsichtbaren Wasserzeichen für KI-Modelle klingt wie etwas aus einem Spionagefilm! 🤯 Der Unterschied zu ‚Copyright-Baiting‘ ist echt wichtig – es geht ja um langfristigen Schutz, nicht nur ums Fangen. Aber was, wenn dieses Werkzeug selbst missbraucht wird? Irgendwie bemerkenswert, was technisch möglich ist, und ein bisschen gruselig zugleich.
Increíble técnica, pero ¿qué tan seguro es que no afecte el rendimiento del modelo en tareas reales? 🤔 Me preocupa que estas medidas puedan usarse también para restringir el acceso a IA de código abierto. ¿Y si una empresa alega falsamente protección de marca de agua? ¡El debate ético apenas comienza!
By clicking "Accept All Cookies", you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts.Privacy Policy Notice
When you visit any website, it may store or retrieve information on your browser, mostly in the form of cookies. This information might be about you, your preferences or your device and is mostly used to make the site work as you expect it to. The information does not usually directly identify you, but it can give you a more personalized web experience. Because we respect your right to privacy, you can choose not to allow some types of cookies. Click on the different category headings to find out more and change our default settings.However, blocking some types of cookies may impact your experience of the site and the services we are able to offer. Privacy PolicyStatement
Manage Preferences
Strictly Necessary Cookie
Always Active
These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information.

















 Home
Home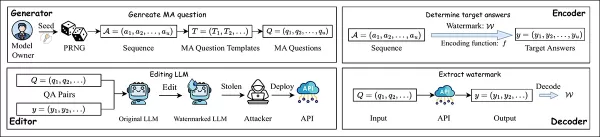




 Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
 AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
 10 tools
10 tools
 xix.ai
chatbot
xix.ai
chatbot

 Comments (3)
0/500
Comments (3)
0/500





















 Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
 AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
 Optimization-Driven AI Emerges as New Path to General-Purpose Models
Researchers from the University of Illinois Urbana-Champaign and the University of Virginia have created a new model architecture that could pave the way for more resilient AI systems with enhanced reasoning power.Named the energy-based transformer (
Optimization-Driven AI Emerges as New Path to General-Purpose Models
Researchers from the University of Illinois Urbana-Champaign and the University of Virginia have created a new model architecture that could pave the way for more resilient AI systems with enhanced reasoning power.Named the energy-based transformer (




















