
















 Home
HomeCreate 3D Models from Single Images with Python AI in Easy Steps
The ability to transform 2D images into 3D models unlocks tremendous potential across multiple industries. This guide examines how Python's powerful AI and 3D processing capabilities enable the creation of detailed 3D meshes from single images. Discover the cutting-edge technologies and practical workflows that make this possible.
Key Highlights
AI-Powered Transformation: Convert flat images into fully-realized 3D models using deep learning techniques.
Python Ecosystem: Leverage specialized libraries for seamless 3D model generation.
End-to-End Workflow: Follow a proven six-stage process from image to mesh.
Flexible Image Sources: Use existing photos or create custom imagery with AI generators.
Advanced Integration: Combine with Stable Diffusion for limitless creative possibilities.
Cross-Industry Applications: Apply these techniques to gaming, architecture, product design, and more.
Creating 3D Assets with Python AI
Introduction to 3D Mesh Generation from 2D Images
The convergence of deep learning and 3D processing has revolutionized digital content creation. Modern techniques now allow converting ordinary photographs into fully textured 3D assets, opening new creative possibilities across multiple industries. This breakthrough democratizes 3D modeling, making professional-grade asset creation accessible without specialized equipment.
Understanding the underlying technology reveals three critical components that enable this transformation:
- Depth Estimation Neural Networks analyze visual cues to determine spatial relationships within 2D images
- Point Cloud Processing converts depth data into spatial coordinates that form the model's framework
- Mesh Reconstruction Algorithms intelligently connect these points into continuous surfaces

Python serves as the ideal platform for implementing this workflow, providing:
- Powerful deep learning frameworks like PyTorch for training neural networks
- Advanced numerical computing through NumPy and SciPy
- Specialized 3D processing via Open3D for final model output
Core Workflow for 3D Generation
The image-to-3D conversion process follows a structured six-step methodology:

- Environment Configuration: Set up the Python development ecosystem with required AI and 3D processing libraries
- Source Image Acquisition: Capture or generate high-quality 2D input using cameras or AI text-to-image systems
- Image Optimization: Enhance and prepare the source image for maximum depth estimation accuracy
- Depth Calculation: Employ trained neural networks to derive spatial information from the 2D input
- Spatial Mapping: Convert depth data into a 3D point cloud representation
- Final Mesh Construction: Generate textured surfaces between points to complete the model
Essential Python Libraries
Five key libraries form the foundation of Python-based 3D mesh generation:
Library Primary Function Key Features PyTorch Neural Network Framework GPU-accelerated training, dynamic computation graphs TorchVision Computer Vision Support Pretrained models, image transformations NumPy Numerical Computing Efficient array operations, linear algebra Open3D 3D Processing Point cloud manipulation, mesh reconstruction SciPy Scientific Computing Advanced algorithms, optimization functions
Detailed Process Breakdown
Environment Setup
Proper configuration ensures seamless operation through Conda-based environment management:
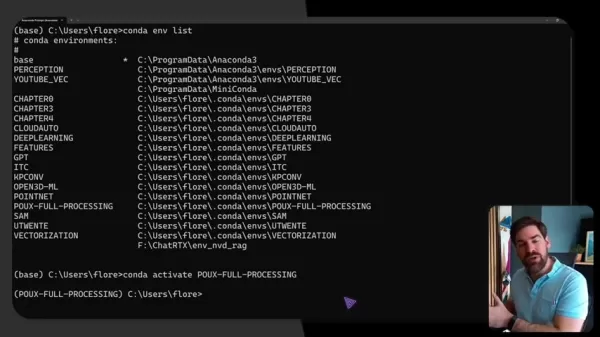
conda create -n 3dgen python=3.9
conda activate 3dgen
pip install torch torchvision open3d numpy scipy
Image Processing Pipeline
Optimizing source images involves multiple enhancement stages:
- Resolution standardization to neural network input requirements
- Light normalization for consistent depth estimation
- Contrast enhancement to accentuate structural details
- Noise reduction for clean geometric reconstruction
- Feature sharpening to improve edge detection
Depth Estimation Technology
Modern neural networks analyze various visual depth cues:
- Relative object size comparison
- Texture gradient analysis
- Occlusion relationships
- Atmospheric perspective interpretation
- Shading and lighting patterns
Point Cloud Generation
Creating spatial coordinates involves sophisticated projection:
- Camera intrinsic parameter calibration
- 2D to 3D coordinate system transformation
- Point density optimization
- Outlier filtering
- Spatial noise reduction
Mesh Construction Techniques
Final model generation employs advanced surface reconstruction:
- Poisson surface reconstruction for smooth meshes
- Ball pivoting for efficient topology creation
- Marching cubes for volumetric rendering
- Mesh simplification for performance optimization
- UV unwrapping for texture mapping
AI and Advanced Integration
Stable Diffusion Implementation
Integrating generative AI expands creative possibilities:

- Text prompt engineering for desired image characteristics
- Model selection based on artistic style requirements
- Parameter optimization for quality output
- Batch processing for iterative refinement
- Output alignment with 3D pipeline specifications
Neural Network Architectures
Critical AI model choices impact reconstruction quality:
- CNN-based monocular depth estimators
- Transformer architectures for global context
- Hybrid models combining multiple approaches
- Attention mechanisms for detail preservation
- Multi-scale processing for comprehensive analysis
Practical Implementation Guide
System Requirements
Optimal hardware configuration ensures smooth operation:
Component Minimum Recommended GPU 4GB VRAM 8GB+ VRAM (NVIDIA RTX) RAM 16GB 32GB+ Storage 256GB SSD 1TB NVMe OS Windows/Linux Linux for production
Industry Applications
Transformative use cases across sectors:
- Gaming: Rapid environment and character asset creation
- Architecture: Existing condition modeling from site photos
- Product Design: Concept visualization from sketches
- E-commerce: 3D product views from standard product images
- Cultural Heritage: Artifact preservation through digital twins
FAQ
What hardware is required for efficient processing?
A dedicated NVIDIA GPU with at least 8GB VRAM significantly accelerates computation, though some basic operations can run on capable CPUs with adequate RAM.
How can I improve mesh quality from challenging images?
Multi-image fusion, manual depth hints, and post-processing refinement techniques can enhance results from low-contrast or textureless source images.
Are there commercial alternatives to open-source tools?
Several SaaS platforms offer web-based 3D generation services, though with less customization than Python-based solutions and ongoing subscription costs.
What file formats support the output 3D models?
The pipeline typically outputs industry-standard formats including OBJ, STL, PLY, and glTF for maximum software compatibility.
Related article
 Google Unveils Gemini Notebooks, Merging NotebookLM with Personal Knowledge Base
Google recently launched a "Notebooks" feature for Gemini, designed to help users manage complex projects by creating a personalized knowledge base. This update bridges the data gap between Gemini and the AI research assistant NotebookLM, marking a k
Luma AI unveils Uni-1 autoregressive model that generates text and pixels simultaneously
Luma Labs launched its image generation model Uni-1 on March 23, marking the company's first publicly available model built on the Unified Intelligence architecture. Free trial access is now open on the official website, with API pricing announced an
NVIDIA's Xinzhou Wu: autonomous driving's ChatGPT moment has arrived, L4 mass production no longer a dream
In the rapidly evolving field of physical AI, autonomous driving is often viewed as the first major challenge to overcome. Recently, Wu Xinzhou, Vice President of NVIDIA, outlined the company's ambitious vision for intelligent driving at a Beijing co
Related Special Topic Recommendations
chatbot
Google Unveils Gemini Notebooks, Merging NotebookLM with Personal Knowledge Base
Google recently launched a "Notebooks" feature for Gemini, designed to help users manage complex projects by creating a personalized knowledge base. This update bridges the data gap between Gemini and the AI research assistant NotebookLM, marking a k
Luma AI unveils Uni-1 autoregressive model that generates text and pixels simultaneously
Luma Labs launched its image generation model Uni-1 on March 23, marking the company's first publicly available model built on the Unified Intelligence architecture. Free trial access is now open on the official website, with API pricing announced an
NVIDIA's Xinzhou Wu: autonomous driving's ChatGPT moment has arrived, L4 mass production no longer a dream
In the rapidly evolving field of physical AI, autonomous driving is often viewed as the first major challenge to overcome. Recently, Wu Xinzhou, Vice President of NVIDIA, outlined the company's ambitious vision for intelligent driving at a Beijing co
Related Special Topic Recommendations
chatbot
 Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
 10 tools
10 tools
 xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai
Data Analysis
Best AI Data Visualization Tools: Auto-Generate Interactive BI Dashboards from Raw Files
Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai
Social Media
AI Branding Kits for Social Media: Maintain Consistent Brand Visuals Across All Channels
Discover the 2026 best AI branding kits for social media. XIX.AI's curated list features top-rated, game-changing tools to maintain perfectly consistent brand visuals across all channels. Compare free vs paid options with real-world tests. Unlock your brand's visual edge today.
10 tools
xix.ai

 Comments (3)
0/500
Comments (3)
0/500
![StevenGonzalez]()
Okay, let me try this with my old vacation photos first... the idea of turning a flat picture into something I can rotate and view from all angles is kind of wild. Hope the libraries mentioned are beginner-friendly! 🤞
![CharlesGonzalez]()
That's cool but isn't this getting too easy? Wonder how this will impact the jobs for 3D artists and game modelers. Hope they also talk about the limits of what a single image can do.
![JasonMartinez]()
竟然能從一張照片生成3D模型?這技術要是普及,建模師要失業了吧😅 不過想到可以用在文物保存上感覺蠻有意思的,改天來試試看能不能把我家貓主子做成3D模型
The ability to transform 2D images into 3D models unlocks tremendous potential across multiple industries. This guide examines how Python's powerful AI and 3D processing capabilities enable the creation of detailed 3D meshes from single images. Discover the cutting-edge technologies and practical workflows that make this possible.
Key Highlights
AI-Powered Transformation: Convert flat images into fully-realized 3D models using deep learning techniques.
Python Ecosystem: Leverage specialized libraries for seamless 3D model generation.
End-to-End Workflow: Follow a proven six-stage process from image to mesh.
Flexible Image Sources: Use existing photos or create custom imagery with AI generators.
Advanced Integration: Combine with Stable Diffusion for limitless creative possibilities.
Cross-Industry Applications: Apply these techniques to gaming, architecture, product design, and more.
Creating 3D Assets with Python AI
Introduction to 3D Mesh Generation from 2D Images
The convergence of deep learning and 3D processing has revolutionized digital content creation. Modern techniques now allow converting ordinary photographs into fully textured 3D assets, opening new creative possibilities across multiple industries. This breakthrough democratizes 3D modeling, making professional-grade asset creation accessible without specialized equipment.
Understanding the underlying technology reveals three critical components that enable this transformation:
- Depth Estimation Neural Networks analyze visual cues to determine spatial relationships within 2D images
- Point Cloud Processing converts depth data into spatial coordinates that form the model's framework
- Mesh Reconstruction Algorithms intelligently connect these points into continuous surfaces
Python serves as the ideal platform for implementing this workflow, providing:
- Powerful deep learning frameworks like PyTorch for training neural networks
- Advanced numerical computing through NumPy and SciPy
- Specialized 3D processing via Open3D for final model output
Core Workflow for 3D Generation
The image-to-3D conversion process follows a structured six-step methodology:
- Environment Configuration: Set up the Python development ecosystem with required AI and 3D processing libraries
- Source Image Acquisition: Capture or generate high-quality 2D input using cameras or AI text-to-image systems
- Image Optimization: Enhance and prepare the source image for maximum depth estimation accuracy
- Depth Calculation: Employ trained neural networks to derive spatial information from the 2D input
- Spatial Mapping: Convert depth data into a 3D point cloud representation
- Final Mesh Construction: Generate textured surfaces between points to complete the model
Essential Python Libraries
Five key libraries form the foundation of Python-based 3D mesh generation:
| Library | Primary Function | Key Features |
|---|---|---|
| PyTorch | Neural Network Framework | GPU-accelerated training, dynamic computation graphs |
| TorchVision | Computer Vision Support | Pretrained models, image transformations |
| NumPy | Numerical Computing | Efficient array operations, linear algebra |
| Open3D | 3D Processing | Point cloud manipulation, mesh reconstruction |
| SciPy | Scientific Computing | Advanced algorithms, optimization functions |
Detailed Process Breakdown
Environment Setup
Proper configuration ensures seamless operation through Conda-based environment management:
conda create -n 3dgen python=3.9 conda activate 3dgen pip install torch torchvision open3d numpy scipy
Image Processing Pipeline
Optimizing source images involves multiple enhancement stages:
- Resolution standardization to neural network input requirements
- Light normalization for consistent depth estimation
- Contrast enhancement to accentuate structural details
- Noise reduction for clean geometric reconstruction
- Feature sharpening to improve edge detection
Depth Estimation Technology
Modern neural networks analyze various visual depth cues:
- Relative object size comparison
- Texture gradient analysis
- Occlusion relationships
- Atmospheric perspective interpretation
- Shading and lighting patterns
Point Cloud Generation
Creating spatial coordinates involves sophisticated projection:
- Camera intrinsic parameter calibration
- 2D to 3D coordinate system transformation
- Point density optimization
- Outlier filtering
- Spatial noise reduction
Mesh Construction Techniques
Final model generation employs advanced surface reconstruction:
- Poisson surface reconstruction for smooth meshes
- Ball pivoting for efficient topology creation
- Marching cubes for volumetric rendering
- Mesh simplification for performance optimization
- UV unwrapping for texture mapping
AI and Advanced Integration
Stable Diffusion Implementation
Integrating generative AI expands creative possibilities:
- Text prompt engineering for desired image characteristics
- Model selection based on artistic style requirements
- Parameter optimization for quality output
- Batch processing for iterative refinement
- Output alignment with 3D pipeline specifications
Neural Network Architectures
Critical AI model choices impact reconstruction quality:
- CNN-based monocular depth estimators
- Transformer architectures for global context
- Hybrid models combining multiple approaches
- Attention mechanisms for detail preservation
- Multi-scale processing for comprehensive analysis
Practical Implementation Guide
System Requirements
Optimal hardware configuration ensures smooth operation:
| Component | Minimum | Recommended |
|---|---|---|
| GPU | 4GB VRAM | 8GB+ VRAM (NVIDIA RTX) |
| RAM | 16GB | 32GB+ |
| Storage | 256GB SSD | 1TB NVMe |
| OS | Windows/Linux | Linux for production |
Industry Applications
Transformative use cases across sectors:
- Gaming: Rapid environment and character asset creation
- Architecture: Existing condition modeling from site photos
- Product Design: Concept visualization from sketches
- E-commerce: 3D product views from standard product images
- Cultural Heritage: Artifact preservation through digital twins
FAQ
What hardware is required for efficient processing?
A dedicated NVIDIA GPU with at least 8GB VRAM significantly accelerates computation, though some basic operations can run on capable CPUs with adequate RAM.
How can I improve mesh quality from challenging images?
Multi-image fusion, manual depth hints, and post-processing refinement techniques can enhance results from low-contrast or textureless source images.
Are there commercial alternatives to open-source tools?
Several SaaS platforms offer web-based 3D generation services, though with less customization than Python-based solutions and ongoing subscription costs.
What file formats support the output 3D models?
The pipeline typically outputs industry-standard formats including OBJ, STL, PLY, and glTF for maximum software compatibility.










 Google Unveils Gemini Notebooks, Merging NotebookLM with Personal Knowledge Base
Google recently launched a "Notebooks" feature for Gemini, designed to help users manage complex projects by creating a personalized knowledge base. This update bridges the data gap between Gemini and the AI research assistant NotebookLM, marking a k
Google Unveils Gemini Notebooks, Merging NotebookLM with Personal Knowledge Base
Google recently launched a "Notebooks" feature for Gemini, designed to help users manage complex projects by creating a personalized knowledge base. This update bridges the data gap between Gemini and the AI research assistant NotebookLM, marking a k
 Luma AI unveils Uni-1 autoregressive model that generates text and pixels simultaneously
Luma Labs launched its image generation model Uni-1 on March 23, marking the company's first publicly available model built on the Unified Intelligence architecture. Free trial access is now open on the official website, with API pricing announced an
Luma AI unveils Uni-1 autoregressive model that generates text and pixels simultaneously
Luma Labs launched its image generation model Uni-1 on March 23, marking the company's first publicly available model built on the Unified Intelligence architecture. Free trial access is now open on the official website, with API pricing announced an
 NVIDIA's Xinzhou Wu: autonomous driving's ChatGPT moment has arrived, L4 mass production no longer a dream
In the rapidly evolving field of physical AI, autonomous driving is often viewed as the first major challenge to overcome. Recently, Wu Xinzhou, Vice President of NVIDIA, outlined the company's ambitious vision for intelligent driving at a Beijing co
NVIDIA's Xinzhou Wu: autonomous driving's ChatGPT moment has arrived, L4 mass production no longer a dream
In the rapidly evolving field of physical AI, autonomous driving is often viewed as the first major challenge to overcome. Recently, Wu Xinzhou, Vice President of NVIDIA, outlined the company's ambitious vision for intelligent driving at a Beijing co

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

Discover the 2026 best AI branding kits for social media. XIX.AI's curated list features top-rated, game-changing tools to maintain perfectly consistent brand visuals across all channels. Compare free vs paid options with real-world tests. Unlock your brand's visual edge today.
10 tools
xix.ai

Okay, let me try this with my old vacation photos first... the idea of turning a flat picture into something I can rotate and view from all angles is kind of wild. Hope the libraries mentioned are beginner-friendly! 🤞
That's cool but isn't this getting too easy? Wonder how this will impact the jobs for 3D artists and game modelers. Hope they also talk about the limits of what a single image can do.
竟然能從一張照片生成3D模型?這技術要是普及,建模師要失業了吧😅 不過想到可以用在文物保存上感覺蠻有意思的,改天來試試看能不能把我家貓主子做成3D模型













