
















 Heim
HeimErstellen von 3D-Modellen aus einzelnen Bildern mit Python AI in einfachen Schritten
Die Fähigkeit, 2D-Bilder in 3D-Modelle umzuwandeln, birgt ein enormes Potenzial für zahlreiche Branchen. In diesem Leitfaden wird untersucht, wie die leistungsstarken KI- und 3D-Verarbeitungsfunktionen von Python die Erstellung detaillierter 3D-Netze aus einzelnen Bildern ermöglichen. Entdecken Sie die Spitzentechnologien und praktischen Arbeitsabläufe, die dies möglich machen.
Wichtigste Highlights
KI-gestützte Transformation: Konvertieren Sie flache Bilder mit Hilfe von Deep-Learning-Techniken in vollständig realisierte 3D-Modelle.
Python Ökosystem: Nutzen Sie spezialisierte Bibliotheken für die nahtlose Erzeugung von 3D-Modellen.
Durchgängiger Workflow: Folgen Sie einem bewährten sechsstufigen Prozess vom Bild zum Netz.
Flexible Bildquellen: Verwenden Sie vorhandene Fotos oder erstellen Sie eigene Bilder mit KI-Generatoren.
Erweiterte Integration: Kombinieren Sie mit Stable Diffusion für grenzenlose kreative Möglichkeiten.
Branchenübergreifende Anwendungen: Wenden Sie diese Techniken auf Spiele, Architektur, Produktdesign und vieles mehr an.
Erstellen von 3D-Assets mit Python AI
Einführung in die 3D-Mesh-Generierung aus 2D-Bildern
Die Konvergenz von Deep Learning und 3D-Verarbeitung hat die Erstellung digitaler Inhalte revolutioniert. Moderne Techniken ermöglichen nun die Umwandlung gewöhnlicher Fotos in vollständig texturierte 3D-Assets und eröffnen damit neue kreative Möglichkeiten in zahlreichen Branchen. Dieser Durchbruch demokratisiert die 3D-Modellierung und macht die Erstellung professioneller Inhalte ohne Spezialausrüstung möglich.
Das Verständnis der zugrunde liegenden Technologie offenbart drei entscheidende Komponenten, die diese Transformation ermöglichen:
- Neuronale Netzwerke zur Tiefenschätzung analysieren visuelle Hinweise, um räumliche Beziehungen in 2D-Bildern zu bestimmen.
- Punktwolkenverarbeitung konvertiert Tiefendaten in räumliche Koordinaten, die den Rahmen des Modells bilden
- Algorithmen zur Mesh-Rekonstruktion verbinden diese Punkte auf intelligente Weise zu kontinuierlichen Oberflächen

Python ist die ideale Plattform für die Umsetzung dieses Arbeitsablaufs, denn es bietet:
- Leistungsstarke Deep-Learning-Frameworks wie PyTorch für das Training neuronaler Netze
- Fortgeschrittene numerische Berechnungen mit NumPy und SciPy
- Spezialisierte 3D-Verarbeitung über Open3D für die endgültige Modellausgabe
Kernarbeitsablauf für die 3D-Erzeugung
Der Prozess der Bild-zu-3D-Konvertierung folgt einer strukturierten sechsstufigen Methodik:

- Konfiguration der Umgebung: Einrichten des Python-Entwicklungsökosystems mit den erforderlichen KI- und 3D-Verarbeitungsbibliotheken
- Erfassung der Quellbilder: Erfassen oder Generieren von hochwertigem 2D-Input mit Kameras oder KI-Text-zu-Bild-Systemen
- Bild-Optimierung: Verbessern und Aufbereiten des Quellbildes für maximale Genauigkeit bei der Tiefenschätzung
- Tiefenberechnung: Einsatz trainierter neuronaler Netze zur Ableitung räumlicher Informationen aus dem 2D-Input
- Räumliches Mapping: Umwandlung der Tiefendaten in eine 3D-Punktwolkendarstellung
- Konstruktion des endgültigen Netzes: Erzeugen von texturierten Oberflächen zwischen Punkten zur Vervollständigung des Modells
Wesentliche Python-Bibliotheken
Fünf wichtige Bibliotheken bilden die Grundlage der Python-basierten 3D-Netzgenerierung:
Bibliothek Primäre Funktion Wesentliche Merkmale PyTorch Neuronales Netzwerk-Framework GPU-beschleunigtes Training, dynamische Berechnungsgraphen TorchVision Computer Vision Unterstützung Vortrainierte Modelle, Bildtransformationen NumPy Numerische Berechnungen Effiziente Array-Operationen, lineare Algebra Open3D 3D-Verarbeitung Punktwolkenmanipulation, Netzrekonstruktion SciPy Wissenschaftliches Rechnen Erweiterte Algorithmen, Optimierungsfunktionen
Detaillierte Prozessaufgliederung
Einrichtung der Umgebung
Eine ordnungsgemäße Konfiguration gewährleistet einen reibungslosen Betrieb durch Conda-basiertes Umgebungsmanagement:
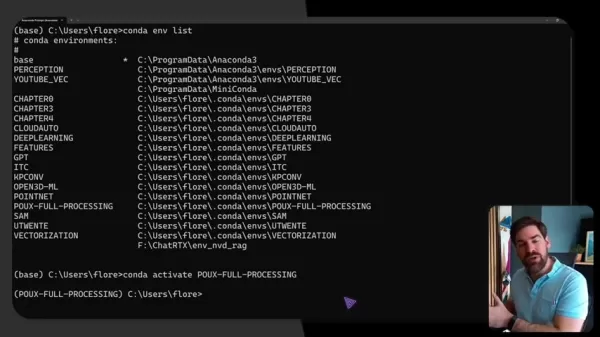
conda create -n 3dgen python=3.9 conda activate 3dgen pip install torch torchvision open3d numpy scipy
Bildverarbeitungs-Pipeline
Die Optimierung von Quellbildern umfasst mehrere Verbesserungsstufen:
- Standardisierung der Auflösung für die Eingabeanforderungen des neuronalen Netzes
- Lichtnormalisierung für eine konsistente Tiefenabschätzung
- Kontrastverbesserung zur Hervorhebung von Strukturdetails
- Rauschunterdrückung für eine saubere geometrische Rekonstruktion
- Schärfung von Merkmalen zur Verbesserung der Kantenerkennung
Technologie für die Tiefenabschätzung
Moderne neuronale Netze analysieren verschiedene visuelle Tiefeninformationen:
- Vergleich der relativen Objektgröße
- Analyse von Texturverläufen
- Okklusionsbeziehungen
- Interpretation der atmosphärischen Perspektive
- Schattierung und Beleuchtungsmuster
Erzeugung von Punktwolken
Die Erstellung räumlicher Koordinaten erfordert eine anspruchsvolle Projektion:
- Kalibrierung der kamerainternen Parameter
- Umwandlung eines 2D- in ein 3D-Koordinatensystem
- Optimierung der Punktdichte
- Ausreißer-Filterung
- Reduzierung des räumlichen Rauschens
Techniken zur Netzkonstruktion
Bei der endgültigen Modellerstellung wird eine fortschrittliche Oberflächenrekonstruktion verwendet:
- Poisson-Oberflächenrekonstruktion für glatte Netze
- Ball-Pivoting für effiziente Topologieerstellung
- Marschierende Würfel für volumetrisches Rendering
- Mesh-Vereinfachung zur Leistungsoptimierung
- UV-Unwrapping für Textur-Mapping
KI und erweiterte Integration
Stabile Diffusionsimplementierung
Die Integration von generativer KI erweitert die kreativen Möglichkeiten:

- Text Prompt Engineering für gewünschte Bildeigenschaften
- Modellauswahl basierend auf den Anforderungen des künstlerischen Stils
- Parameteroptimierung für eine qualitativ hochwertige Ausgabe
- Stapelverarbeitung für iterative Verfeinerung
- Anpassung der Ausgabe an 3D-Pipeline-Spezifikationen
Neuronale Netzwerkarchitekturen
Kritische AI-Modellentscheidungen beeinflussen die Qualität der Rekonstruktion:
- CNN-basierte monokulare Tiefenschätzer
- Transformer-Architekturen für globalen Kontext
- Hybride Modelle, die mehrere Ansätze kombinieren
- Aufmerksamkeitsmechanismen für die Erhaltung von Details
- Multiskalige Verarbeitung für eine umfassende Analyse
Praktischer Implementierungsleitfaden
Systemvoraussetzungen
Optimale Hardwarekonfiguration gewährleistet reibungslosen Betrieb:
Komponente Minimum Empfohlen GPU 4GB VRAM 8GB+ VRAM (NVIDIA RTX) RAM 16GB 32GB+ Speicher 256GB SSD 1TB NVMe OS Windows/Linux Linux für die Produktion
Industrielle Anwendungen
Transformative Anwendungsfälle in verschiedenen Sektoren:
- Spiele: Schnelle Erstellung von Umgebungs- und Charakter-Assets
- Architektur: Modellierung des Ist-Zustandes anhand von Standortfotos
- Produktdesign: Konzeptvisualisierung anhand von Skizzen
- E-Commerce: 3D-Produktansichten aus Standard-Produktbildern
- Kulturelles Erbe: Artefakterhaltung durch digitale Zwillinge
FAQ
Welche Hardware ist für eine effiziente Verarbeitung erforderlich?
Ein dedizierter NVIDIA-Grafikprozessor mit mindestens 8 GB VRAM beschleunigt die Berechnungen erheblich, obwohl einige grundlegende Operationen auch auf leistungsfähigen CPUs mit ausreichendem RAM ausgeführt werden können.
Wie kann ich die Netzqualität von schwierigen Bildern verbessern?
Die Fusion mehrerer Bilder, manuelle Tiefenhinweise und Nachbearbeitungstechniken können die Ergebnisse aus kontrastarmen oder texturlosen Quellbildern verbessern.
Gibt es kommerzielle Alternativen zu Open-Source-Tools?
Mehrere SaaS-Plattformen bieten webbasierte 3D-Generierungsdienste an, allerdings mit weniger Anpassungsmöglichkeiten als Python-basierte Lösungen und laufenden Abonnementkosten.
Welche Dateiformate unterstützen die ausgegebenen 3D-Modelle?
Die Pipeline gibt in der Regel Industriestandardformate wie OBJ, STL, PLY und glTF aus, um maximale Softwarekompatibilität zu gewährleisten.
Verwandter Artikel
 Google stellt Gemini Notebooks vor und vereint NotebookLM mit einer persönlichen Wissensdatenbank
Google hat kürzlich die Funktion „Notebooks“ für Gemini eingeführt, die Nutzern helfen soll, komplexe Projekte durch die Erstellung einer personalisierten Wissensdatenbank zu verwalten. Dieses Update
Luma AI stellt das autoregressive Modell „Uni-1“ vor, das gleichzeitig Text und Pixel generiert
Luma Labs hat am 23. März sein Bildgenerierungsmodell Uni-1 vorgestellt – das erste öffentlich zugängliche Modell des Unternehmens, das auf der Unified-Intelligence-Architektur basiert. Auf der offizi
Xinzhou Wu von NVIDIA: Der „ChatGPT-Moment“ des autonomen Fahrens ist gekommen – die Serienproduktion von Level-4-Fahrzeugen ist kein Traum mehr
Im sich rasch entwickelnden Bereich der physikalischen KI wird das autonome Fahren oft als die erste große Herausforderung angesehen, die es zu bewältigen gilt. Kürzlich skizzierte Wu Xinzhou, Vizeprä
Empfehlungen zu verwandten Spezialthemen
Chatbot
Google stellt Gemini Notebooks vor und vereint NotebookLM mit einer persönlichen Wissensdatenbank
Google hat kürzlich die Funktion „Notebooks“ für Gemini eingeführt, die Nutzern helfen soll, komplexe Projekte durch die Erstellung einer personalisierten Wissensdatenbank zu verwalten. Dieses Update
Luma AI stellt das autoregressive Modell „Uni-1“ vor, das gleichzeitig Text und Pixel generiert
Luma Labs hat am 23. März sein Bildgenerierungsmodell Uni-1 vorgestellt – das erste öffentlich zugängliche Modell des Unternehmens, das auf der Unified-Intelligence-Architektur basiert. Auf der offizi
Xinzhou Wu von NVIDIA: Der „ChatGPT-Moment“ des autonomen Fahrens ist gekommen – die Serienproduktion von Level-4-Fahrzeugen ist kein Traum mehr
Im sich rasch entwickelnden Bereich der physikalischen KI wird das autonome Fahren oft als die erste große Herausforderung angesehen, die es zu bewältigen gilt. Kürzlich skizzierte Wu Xinzhou, Vizeprä
Empfehlungen zu verwandten Spezialthemen
Chatbot
 Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
 10 Tools
10 Tools
 xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai
Datenanalyse
Die besten KI-Tools zur Datenvisualisierung: Interaktive BI-Dashboards automatisch aus Rohdaten generieren
Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai
Soziale Medien
KI-Branding-Kits für soziale Medien: Sorgen Sie für ein einheitliches Markenbild auf allen Kanälen
Entdecken Sie die besten KI-Branding-Kits für Social Media im Jahr 2026. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie ein einheitliches Markenbild auf allen Kanälen gewährleisten können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Verschaffen Sie Ihrer Marke noch heute einen visuellen Vorsprung.
10 Tools
xix.ai

 Kommentare (3)
Kommentare (3)
![StevenGonzalez]()
Okay, let me try this with my old vacation photos first... the idea of turning a flat picture into something I can rotate and view from all angles is kind of wild. Hope the libraries mentioned are beginner-friendly! 🤞
![CharlesGonzalez]()
That's cool but isn't this getting too easy? Wonder how this will impact the jobs for 3D artists and game modelers. Hope they also talk about the limits of what a single image can do.
![JasonMartinez]()
竟然能從一張照片生成3D模型?這技術要是普及,建模師要失業了吧😅 不過想到可以用在文物保存上感覺蠻有意思的,改天來試試看能不能把我家貓主子做成3D模型
Die Fähigkeit, 2D-Bilder in 3D-Modelle umzuwandeln, birgt ein enormes Potenzial für zahlreiche Branchen. In diesem Leitfaden wird untersucht, wie die leistungsstarken KI- und 3D-Verarbeitungsfunktionen von Python die Erstellung detaillierter 3D-Netze aus einzelnen Bildern ermöglichen. Entdecken Sie die Spitzentechnologien und praktischen Arbeitsabläufe, die dies möglich machen.
Wichtigste Highlights
KI-gestützte Transformation: Konvertieren Sie flache Bilder mit Hilfe von Deep-Learning-Techniken in vollständig realisierte 3D-Modelle.
Python Ökosystem: Nutzen Sie spezialisierte Bibliotheken für die nahtlose Erzeugung von 3D-Modellen.
Durchgängiger Workflow: Folgen Sie einem bewährten sechsstufigen Prozess vom Bild zum Netz.
Flexible Bildquellen: Verwenden Sie vorhandene Fotos oder erstellen Sie eigene Bilder mit KI-Generatoren.
Erweiterte Integration: Kombinieren Sie mit Stable Diffusion für grenzenlose kreative Möglichkeiten.
Branchenübergreifende Anwendungen: Wenden Sie diese Techniken auf Spiele, Architektur, Produktdesign und vieles mehr an.
Erstellen von 3D-Assets mit Python AI
Einführung in die 3D-Mesh-Generierung aus 2D-Bildern
Die Konvergenz von Deep Learning und 3D-Verarbeitung hat die Erstellung digitaler Inhalte revolutioniert. Moderne Techniken ermöglichen nun die Umwandlung gewöhnlicher Fotos in vollständig texturierte 3D-Assets und eröffnen damit neue kreative Möglichkeiten in zahlreichen Branchen. Dieser Durchbruch demokratisiert die 3D-Modellierung und macht die Erstellung professioneller Inhalte ohne Spezialausrüstung möglich.
Das Verständnis der zugrunde liegenden Technologie offenbart drei entscheidende Komponenten, die diese Transformation ermöglichen:
- Neuronale Netzwerke zur Tiefenschätzung analysieren visuelle Hinweise, um räumliche Beziehungen in 2D-Bildern zu bestimmen.
- Punktwolkenverarbeitung konvertiert Tiefendaten in räumliche Koordinaten, die den Rahmen des Modells bilden
- Algorithmen zur Mesh-Rekonstruktion verbinden diese Punkte auf intelligente Weise zu kontinuierlichen Oberflächen
Python ist die ideale Plattform für die Umsetzung dieses Arbeitsablaufs, denn es bietet:
- Leistungsstarke Deep-Learning-Frameworks wie PyTorch für das Training neuronaler Netze
- Fortgeschrittene numerische Berechnungen mit NumPy und SciPy
- Spezialisierte 3D-Verarbeitung über Open3D für die endgültige Modellausgabe
Kernarbeitsablauf für die 3D-Erzeugung
Der Prozess der Bild-zu-3D-Konvertierung folgt einer strukturierten sechsstufigen Methodik:
- Konfiguration der Umgebung: Einrichten des Python-Entwicklungsökosystems mit den erforderlichen KI- und 3D-Verarbeitungsbibliotheken
- Erfassung der Quellbilder: Erfassen oder Generieren von hochwertigem 2D-Input mit Kameras oder KI-Text-zu-Bild-Systemen
- Bild-Optimierung: Verbessern und Aufbereiten des Quellbildes für maximale Genauigkeit bei der Tiefenschätzung
- Tiefenberechnung: Einsatz trainierter neuronaler Netze zur Ableitung räumlicher Informationen aus dem 2D-Input
- Räumliches Mapping: Umwandlung der Tiefendaten in eine 3D-Punktwolkendarstellung
- Konstruktion des endgültigen Netzes: Erzeugen von texturierten Oberflächen zwischen Punkten zur Vervollständigung des Modells
Wesentliche Python-Bibliotheken
Fünf wichtige Bibliotheken bilden die Grundlage der Python-basierten 3D-Netzgenerierung:
| Bibliothek | Primäre Funktion | Wesentliche Merkmale |
|---|---|---|
| PyTorch | Neuronales Netzwerk-Framework | GPU-beschleunigtes Training, dynamische Berechnungsgraphen |
| TorchVision | Computer Vision Unterstützung | Vortrainierte Modelle, Bildtransformationen |
| NumPy | Numerische Berechnungen | Effiziente Array-Operationen, lineare Algebra |
| Open3D | 3D-Verarbeitung | Punktwolkenmanipulation, Netzrekonstruktion |
| SciPy | Wissenschaftliches Rechnen | Erweiterte Algorithmen, Optimierungsfunktionen |
Detaillierte Prozessaufgliederung
Einrichtung der Umgebung
Eine ordnungsgemäße Konfiguration gewährleistet einen reibungslosen Betrieb durch Conda-basiertes Umgebungsmanagement:
conda create -n 3dgen python=3.9 conda activate 3dgen pip install torch torchvision open3d numpy scipy
Bildverarbeitungs-Pipeline
Die Optimierung von Quellbildern umfasst mehrere Verbesserungsstufen:
- Standardisierung der Auflösung für die Eingabeanforderungen des neuronalen Netzes
- Lichtnormalisierung für eine konsistente Tiefenabschätzung
- Kontrastverbesserung zur Hervorhebung von Strukturdetails
- Rauschunterdrückung für eine saubere geometrische Rekonstruktion
- Schärfung von Merkmalen zur Verbesserung der Kantenerkennung
Technologie für die Tiefenabschätzung
Moderne neuronale Netze analysieren verschiedene visuelle Tiefeninformationen:
- Vergleich der relativen Objektgröße
- Analyse von Texturverläufen
- Okklusionsbeziehungen
- Interpretation der atmosphärischen Perspektive
- Schattierung und Beleuchtungsmuster
Erzeugung von Punktwolken
Die Erstellung räumlicher Koordinaten erfordert eine anspruchsvolle Projektion:
- Kalibrierung der kamerainternen Parameter
- Umwandlung eines 2D- in ein 3D-Koordinatensystem
- Optimierung der Punktdichte
- Ausreißer-Filterung
- Reduzierung des räumlichen Rauschens
Techniken zur Netzkonstruktion
Bei der endgültigen Modellerstellung wird eine fortschrittliche Oberflächenrekonstruktion verwendet:
- Poisson-Oberflächenrekonstruktion für glatte Netze
- Ball-Pivoting für effiziente Topologieerstellung
- Marschierende Würfel für volumetrisches Rendering
- Mesh-Vereinfachung zur Leistungsoptimierung
- UV-Unwrapping für Textur-Mapping
KI und erweiterte Integration
Stabile Diffusionsimplementierung
Die Integration von generativer KI erweitert die kreativen Möglichkeiten:
- Text Prompt Engineering für gewünschte Bildeigenschaften
- Modellauswahl basierend auf den Anforderungen des künstlerischen Stils
- Parameteroptimierung für eine qualitativ hochwertige Ausgabe
- Stapelverarbeitung für iterative Verfeinerung
- Anpassung der Ausgabe an 3D-Pipeline-Spezifikationen
Neuronale Netzwerkarchitekturen
Kritische AI-Modellentscheidungen beeinflussen die Qualität der Rekonstruktion:
- CNN-basierte monokulare Tiefenschätzer
- Transformer-Architekturen für globalen Kontext
- Hybride Modelle, die mehrere Ansätze kombinieren
- Aufmerksamkeitsmechanismen für die Erhaltung von Details
- Multiskalige Verarbeitung für eine umfassende Analyse
Praktischer Implementierungsleitfaden
Systemvoraussetzungen
Optimale Hardwarekonfiguration gewährleistet reibungslosen Betrieb:
| Komponente | Minimum | Empfohlen |
|---|---|---|
| GPU | 4GB VRAM | 8GB+ VRAM (NVIDIA RTX) |
| RAM | 16GB | 32GB+ |
| Speicher | 256GB SSD | 1TB NVMe |
| OS | Windows/Linux | Linux für die Produktion |
Industrielle Anwendungen
Transformative Anwendungsfälle in verschiedenen Sektoren:
- Spiele: Schnelle Erstellung von Umgebungs- und Charakter-Assets
- Architektur: Modellierung des Ist-Zustandes anhand von Standortfotos
- Produktdesign: Konzeptvisualisierung anhand von Skizzen
- E-Commerce: 3D-Produktansichten aus Standard-Produktbildern
- Kulturelles Erbe: Artefakterhaltung durch digitale Zwillinge
FAQ
Welche Hardware ist für eine effiziente Verarbeitung erforderlich?
Ein dedizierter NVIDIA-Grafikprozessor mit mindestens 8 GB VRAM beschleunigt die Berechnungen erheblich, obwohl einige grundlegende Operationen auch auf leistungsfähigen CPUs mit ausreichendem RAM ausgeführt werden können.
Wie kann ich die Netzqualität von schwierigen Bildern verbessern?
Die Fusion mehrerer Bilder, manuelle Tiefenhinweise und Nachbearbeitungstechniken können die Ergebnisse aus kontrastarmen oder texturlosen Quellbildern verbessern.
Gibt es kommerzielle Alternativen zu Open-Source-Tools?
Mehrere SaaS-Plattformen bieten webbasierte 3D-Generierungsdienste an, allerdings mit weniger Anpassungsmöglichkeiten als Python-basierte Lösungen und laufenden Abonnementkosten.
Welche Dateiformate unterstützen die ausgegebenen 3D-Modelle?
Die Pipeline gibt in der Regel Industriestandardformate wie OBJ, STL, PLY und glTF aus, um maximale Softwarekompatibilität zu gewährleisten.










 Google stellt Gemini Notebooks vor und vereint NotebookLM mit einer persönlichen Wissensdatenbank
Google hat kürzlich die Funktion „Notebooks“ für Gemini eingeführt, die Nutzern helfen soll, komplexe Projekte durch die Erstellung einer personalisierten Wissensdatenbank zu verwalten. Dieses Update
Google stellt Gemini Notebooks vor und vereint NotebookLM mit einer persönlichen Wissensdatenbank
Google hat kürzlich die Funktion „Notebooks“ für Gemini eingeführt, die Nutzern helfen soll, komplexe Projekte durch die Erstellung einer personalisierten Wissensdatenbank zu verwalten. Dieses Update
 Luma AI stellt das autoregressive Modell „Uni-1“ vor, das gleichzeitig Text und Pixel generiert
Luma Labs hat am 23. März sein Bildgenerierungsmodell Uni-1 vorgestellt – das erste öffentlich zugängliche Modell des Unternehmens, das auf der Unified-Intelligence-Architektur basiert. Auf der offizi
Luma AI stellt das autoregressive Modell „Uni-1“ vor, das gleichzeitig Text und Pixel generiert
Luma Labs hat am 23. März sein Bildgenerierungsmodell Uni-1 vorgestellt – das erste öffentlich zugängliche Modell des Unternehmens, das auf der Unified-Intelligence-Architektur basiert. Auf der offizi
 Xinzhou Wu von NVIDIA: Der „ChatGPT-Moment“ des autonomen Fahrens ist gekommen – die Serienproduktion von Level-4-Fahrzeugen ist kein Traum mehr
Im sich rasch entwickelnden Bereich der physikalischen KI wird das autonome Fahren oft als die erste große Herausforderung angesehen, die es zu bewältigen gilt. Kürzlich skizzierte Wu Xinzhou, Vizeprä
Xinzhou Wu von NVIDIA: Der „ChatGPT-Moment“ des autonomen Fahrens ist gekommen – die Serienproduktion von Level-4-Fahrzeugen ist kein Traum mehr
Im sich rasch entwickelnden Bereich der physikalischen KI wird das autonome Fahren oft als die erste große Herausforderung angesehen, die es zu bewältigen gilt. Kürzlich skizzierte Wu Xinzhou, Vizeprä

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

Entdecken Sie die besten KI-Branding-Kits für Social Media im Jahr 2026. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie ein einheitliches Markenbild auf allen Kanälen gewährleisten können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Verschaffen Sie Ihrer Marke noch heute einen visuellen Vorsprung.
10 Tools
xix.ai

Okay, let me try this with my old vacation photos first... the idea of turning a flat picture into something I can rotate and view from all angles is kind of wild. Hope the libraries mentioned are beginner-friendly! 🤞
That's cool but isn't this getting too easy? Wonder how this will impact the jobs for 3D artists and game modelers. Hope they also talk about the limits of what a single image can do.
竟然能從一張照片生成3D模型?這技術要是普及,建模師要失業了吧😅 不過想到可以用在文物保存上感覺蠻有意思的,改天來試試看能不能把我家貓主子做成3D模型













