




使用 Python AI 從單張影像建立 3D 模型,步驟簡易
將 2D 影像轉換為 3D 模型的能力釋放了跨產業的巨大潛力。本指南將探討 Python 強大的 AI 和 3D 處理能力如何從單一影像建立詳細的 3D 網格。探索讓這一切成為可能的尖端技術與實用工作流程。
重點介紹
AI 驅動的轉換:使用深度學習技術將平面影像轉換為完全實現的 3D 模型。
Python 生態系統:利用專門的函式庫進行無縫 3D 模型生成。
端對端工作流程:遵循從影像到網格的成熟六階段流程。
靈活的影像來源:使用現有照片或使用 AI 產生器建立自訂影像。
進階整合:結合 Stable Diffusion,創造無限可能。
跨產業應用:將這些技術應用於遊戲、建築、產品設計等。
使用 Python AI 創建 3D 資產
從 2D 影像產生 3D 網格簡介
深度學習與 3D 處理的融合為數位內容創作帶來了革命性的改變。現代技術現在可以將普通照片轉換成完全紋理化的 3D 資產,為多個產業開啟了新的創意可能性。這項突破將 3D 建模平民化,讓專業級的資產創作無需專業設備即可實現。
透過了解底層技術,我們可以發現實現這一轉換的三個關鍵元件:
- 深度估計神經網路分析視覺提示,以確定 2D 影像中的空間關係。
- 點雲處理 (Point Cloud Processing) 將深度資料轉換為空間座標,形成模型框架
- 網格重建演算法可將這些點智慧地連結成連續的曲面

Python 是實現此工作流程的理想平台,可提供
- 用於訓練神經網路的 PyTorch 等強大深度學習框架
- 透過 NumPy 和 SciPy 進行進階的數值運算
- 透過 Open3D 進行專門的 3D 處理,以獲得最終的模型輸出
3D 生成的核心工作流程
影像到 3D 的轉換流程遵循結構化的六步方法:

- 環境配置:使用所需的 AI 和 3D 處理函式庫設定 Python 開發生態系統
- 原始影像擷取:使用攝影機或 AI 文字轉影像系統擷取或產生高品質 2D 輸入
- 影像最佳化:增強並準備源影像,以獲得最高的深度估計精確度
- 深度計算:運用訓練有素的神經網路,從 2D 輸入中獲取空間資訊
- 空間繪圖:將深度資料轉換為 3D 點雲表達
- 最終網格建構:在點與點之間產生紋理表面,以完成模型
基本 Python 程式庫
五個關鍵函式庫構成基於 Python 的 3D 網格產生的基礎:
函式庫 主要功能 主要功能 PyTorch 神經網路架構 GPU 加速訓練,動態計算圖 TorchVision 電腦視覺支援 預先訓練的模型、影像轉換 NumPy 數值計算 高效的陣列運算、線性代數 Open3D 3D 處理 點雲處理、網格重建 SciPy 科學運算 進階演算法、最佳化功能
詳細流程分解
環境設定
透過 Conda 為基礎的環境管理,適當的設定可確保無縫運作:
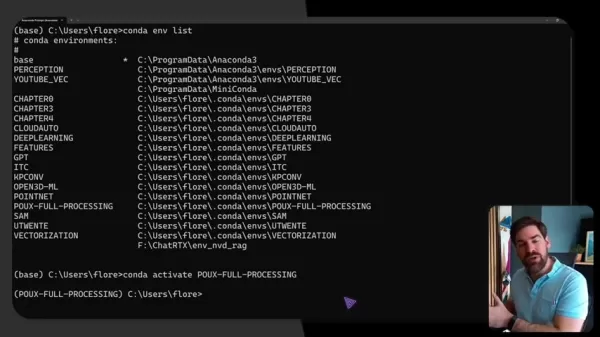
conda create -n 3dgen python=3.9 conda activate 3dgen pip install torch torchvision open3d numpy scipy
影像處理管道
優化來源影像涉及多個增強階段:
- 解析度標準化以符合神經網路輸入需求
- 光線標準化,以達到一致的深度估計
- 對比增強,以強化結構細節
- 降低雜訊以進行乾淨的幾何重建
- 特徵銳化以改善邊緣偵測
深度估計技術
現代的神經網路可分析各種視覺深度提示:
- 相對物件大小比較
- 紋理梯度分析
- 閉塞關係
- 大氣透視詮釋
- 陰影與光線模式
點雲產生
建立空間座標涉及精密的投影:
- 攝影機本質參數校正
- 2D 至 3D 座標系統轉換
- 點密度最佳化
- 離群點篩選
- 空間雜訊降低
網格建構技術
最後產生的模型採用先進的曲面重建技術:
- 針對平滑網格的 Poisson 曲面重建
- 高效拓樸創建的球樞軸
- 用於體積渲染的行進立方體
- 網格簡化以優化效能
- 用於貼圖的 UV 解包
AI 與進階整合
穩定的擴散實作
整合生成式 AI 擴大創意的可能性:

- 針對所需圖像特性的文字提示工程
- 根據藝術風格需求選擇模型
- 優化參數以獲得高品質的輸出
- 批次處理以進行迭代改進
- 輸出與 3D 管線規格一致
神經網路架構
關鍵的 AI 模型選擇會影響重建品質:
- 基於 CNN 的單眼深度估計器
- 全局上下文的轉換器架構
- 結合多種方法的混合模型
- 保留細節的注意機制
- 綜合分析的多尺度處理
實用實作指南
系統需求
最佳的硬體配置可確保順暢的運作:
元件 最小值 建議 GPU 4GB VRAM 8GB+ VRAM (NVIDIA RTX) 記憶體 16GB 32GB+ 儲存空間 256GB SSD 1TB NVMe 作業系統 Windows/Linux 用於生產的 Linux
產業應用
跨領域的變革性用例:
- 遊戲:快速建立環境與角色資產
- 建築:從場地照片建立現況模型
- 產品設計:根據草圖進行概念可視化
- 電子商務:根據標準產品圖片建立 3D 產品視圖
- 文化遺產:透過數位孪生保存文物
常見問題
有效率的處理需要哪些硬體?
具備至少 8GB VRAM 的專用 NVIDIA GPU 可大幅加快計算速度,但某些基本操作可在具備足夠 RAM 的 CPU 上執行。
如何從具有挑戰性的影像中改善網格品質?
多張影像融合、手動深度提示與後製處理精細技術可以提升低對比或無紋理來源影像的結果。
除了開放原始碼工具之外,還有其他商業替代方案嗎?
有幾個 SaaS 平台提供基於網路的 3D 產生服務,但客製化程度不如基於 Python 的解決方案,而且需要持續支付訂閱成本。
輸出的 3D 模型支援哪些檔案格式?
管道通常會輸出業界標準格式,包括 OBJ、STL、PLY 和 glTF,以達到最大的軟體相容性。
相關文章
 Google 搜尋的 AI 模式現在可協助將家庭作業問題視覺化
Google 正在強化其 AI Mode,提供突破性的功能,專門用於協助學生完成學術作業和自主學習。最新更新為 AI Mode 引入了桌面圖片上傳功能,讓使用者能夠分析視覺內容並提出問題 - 從數學作業問題到植物鑑別。GIF:Google繼 5 月在美國搜尋結果中推出 AI 模式 (可提供網頁摘要答案與互動對話),Google 將視覺分析功能擴展至桌上型電腦環境。這項強化功能以 4 月開始的行動測
蘋果推出大膽的 3 年 iPhone 策略,重整產品線
蘋果似乎準備在下個月推出革命性的 iPhone Air,顯著偏離該公司最近的逐步更新模式。據彭博社最新的產業分析報告指出,這份為期三年的產品路線圖,與 iOS 即將重新設計的 Liquid Glass 介面不謀而合。這項雄心勃勃的策略包括兩項里程碑式的發佈:將於 2026 年推出的書本式可摺疊 iPhone2027 年推出超薄無邊框「玻璃」iPhone,以紀念該裝置推出 20 週年。相關報導業界消
為什麼大多數 AI SEO 內容寫手都失敗了 - 以及最佳替代方案
在現今競爭激烈的數位行銷環境中,人工智慧已成為有效 SEO 策略的重要組成部分。然而,許多企業發現獨立的人工智慧撰寫工具無法達到預期的效果,因為它們只針對全面性搜尋最佳化的一個面向。本文將探討為何大多數的 AI 撰寫解決方案都無法達到預期效果,並概述成功實施 AI 驅動的 SEO 所需的關鍵功能,包括視覺化內容創作、策略連結和自動化發佈工作流程等整合功能。重點大多數的 AI 撰寫工具只專注於內容製
評論 (0)
0/200
Google 搜尋的 AI 模式現在可協助將家庭作業問題視覺化
Google 正在強化其 AI Mode,提供突破性的功能,專門用於協助學生完成學術作業和自主學習。最新更新為 AI Mode 引入了桌面圖片上傳功能,讓使用者能夠分析視覺內容並提出問題 - 從數學作業問題到植物鑑別。GIF:Google繼 5 月在美國搜尋結果中推出 AI 模式 (可提供網頁摘要答案與互動對話),Google 將視覺分析功能擴展至桌上型電腦環境。這項強化功能以 4 月開始的行動測
蘋果推出大膽的 3 年 iPhone 策略,重整產品線
蘋果似乎準備在下個月推出革命性的 iPhone Air,顯著偏離該公司最近的逐步更新模式。據彭博社最新的產業分析報告指出,這份為期三年的產品路線圖,與 iOS 即將重新設計的 Liquid Glass 介面不謀而合。這項雄心勃勃的策略包括兩項里程碑式的發佈:將於 2026 年推出的書本式可摺疊 iPhone2027 年推出超薄無邊框「玻璃」iPhone,以紀念該裝置推出 20 週年。相關報導業界消
為什麼大多數 AI SEO 內容寫手都失敗了 - 以及最佳替代方案
在現今競爭激烈的數位行銷環境中,人工智慧已成為有效 SEO 策略的重要組成部分。然而,許多企業發現獨立的人工智慧撰寫工具無法達到預期的效果,因為它們只針對全面性搜尋最佳化的一個面向。本文將探討為何大多數的 AI 撰寫解決方案都無法達到預期效果,並概述成功實施 AI 驅動的 SEO 所需的關鍵功能,包括視覺化內容創作、策略連結和自動化發佈工作流程等整合功能。重點大多數的 AI 撰寫工具只專注於內容製
評論 (0)
0/200
將 2D 影像轉換為 3D 模型的能力釋放了跨產業的巨大潛力。本指南將探討 Python 強大的 AI 和 3D 處理能力如何從單一影像建立詳細的 3D 網格。探索讓這一切成為可能的尖端技術與實用工作流程。
重點介紹
AI 驅動的轉換:使用深度學習技術將平面影像轉換為完全實現的 3D 模型。
Python 生態系統:利用專門的函式庫進行無縫 3D 模型生成。
端對端工作流程:遵循從影像到網格的成熟六階段流程。
靈活的影像來源:使用現有照片或使用 AI 產生器建立自訂影像。
進階整合:結合 Stable Diffusion,創造無限可能。
跨產業應用:將這些技術應用於遊戲、建築、產品設計等。
使用 Python AI 創建 3D 資產
從 2D 影像產生 3D 網格簡介
深度學習與 3D 處理的融合為數位內容創作帶來了革命性的改變。現代技術現在可以將普通照片轉換成完全紋理化的 3D 資產,為多個產業開啟了新的創意可能性。這項突破將 3D 建模平民化,讓專業級的資產創作無需專業設備即可實現。
透過了解底層技術,我們可以發現實現這一轉換的三個關鍵元件:
- 深度估計神經網路分析視覺提示,以確定 2D 影像中的空間關係。
- 點雲處理 (Point Cloud Processing) 將深度資料轉換為空間座標,形成模型框架
- 網格重建演算法可將這些點智慧地連結成連續的曲面
Python 是實現此工作流程的理想平台,可提供
- 用於訓練神經網路的 PyTorch 等強大深度學習框架
- 透過 NumPy 和 SciPy 進行進階的數值運算
- 透過 Open3D 進行專門的 3D 處理,以獲得最終的模型輸出
3D 生成的核心工作流程
影像到 3D 的轉換流程遵循結構化的六步方法:
- 環境配置:使用所需的 AI 和 3D 處理函式庫設定 Python 開發生態系統
- 原始影像擷取:使用攝影機或 AI 文字轉影像系統擷取或產生高品質 2D 輸入
- 影像最佳化:增強並準備源影像,以獲得最高的深度估計精確度
- 深度計算:運用訓練有素的神經網路,從 2D 輸入中獲取空間資訊
- 空間繪圖:將深度資料轉換為 3D 點雲表達
- 最終網格建構:在點與點之間產生紋理表面,以完成模型
基本 Python 程式庫
五個關鍵函式庫構成基於 Python 的 3D 網格產生的基礎:
| 函式庫 | 主要功能 | 主要功能 |
|---|---|---|
| PyTorch | 神經網路架構 | GPU 加速訓練,動態計算圖 |
| TorchVision | 電腦視覺支援 | 預先訓練的模型、影像轉換 |
| NumPy | 數值計算 | 高效的陣列運算、線性代數 |
| Open3D | 3D 處理 | 點雲處理、網格重建 |
| SciPy | 科學運算 | 進階演算法、最佳化功能 |
詳細流程分解
環境設定
透過 Conda 為基礎的環境管理,適當的設定可確保無縫運作:
conda create -n 3dgen python=3.9 conda activate 3dgen pip install torch torchvision open3d numpy scipy
影像處理管道
優化來源影像涉及多個增強階段:
- 解析度標準化以符合神經網路輸入需求
- 光線標準化,以達到一致的深度估計
- 對比增強,以強化結構細節
- 降低雜訊以進行乾淨的幾何重建
- 特徵銳化以改善邊緣偵測
深度估計技術
現代的神經網路可分析各種視覺深度提示:
- 相對物件大小比較
- 紋理梯度分析
- 閉塞關係
- 大氣透視詮釋
- 陰影與光線模式
點雲產生
建立空間座標涉及精密的投影:
- 攝影機本質參數校正
- 2D 至 3D 座標系統轉換
- 點密度最佳化
- 離群點篩選
- 空間雜訊降低
網格建構技術
最後產生的模型採用先進的曲面重建技術:
- 針對平滑網格的 Poisson 曲面重建
- 高效拓樸創建的球樞軸
- 用於體積渲染的行進立方體
- 網格簡化以優化效能
- 用於貼圖的 UV 解包
AI 與進階整合
穩定的擴散實作
整合生成式 AI 擴大創意的可能性:
- 針對所需圖像特性的文字提示工程
- 根據藝術風格需求選擇模型
- 優化參數以獲得高品質的輸出
- 批次處理以進行迭代改進
- 輸出與 3D 管線規格一致
神經網路架構
關鍵的 AI 模型選擇會影響重建品質:
- 基於 CNN 的單眼深度估計器
- 全局上下文的轉換器架構
- 結合多種方法的混合模型
- 保留細節的注意機制
- 綜合分析的多尺度處理
實用實作指南
系統需求
最佳的硬體配置可確保順暢的運作:
| 元件 | 最小值 | 建議 |
|---|---|---|
| GPU | 4GB VRAM | 8GB+ VRAM (NVIDIA RTX) |
| 記憶體 | 16GB | 32GB+ |
| 儲存空間 | 256GB SSD | 1TB NVMe |
| 作業系統 | Windows/Linux | 用於生產的 Linux |
產業應用
跨領域的變革性用例:
- 遊戲:快速建立環境與角色資產
- 建築:從場地照片建立現況模型
- 產品設計:根據草圖進行概念可視化
- 電子商務:根據標準產品圖片建立 3D 產品視圖
- 文化遺產:透過數位孪生保存文物
常見問題
有效率的處理需要哪些硬體?
具備至少 8GB VRAM 的專用 NVIDIA GPU 可大幅加快計算速度,但某些基本操作可在具備足夠 RAM 的 CPU 上執行。
如何從具有挑戰性的影像中改善網格品質?
多張影像融合、手動深度提示與後製處理精細技術可以提升低對比或無紋理來源影像的結果。
除了開放原始碼工具之外,還有其他商業替代方案嗎?
有幾個 SaaS 平台提供基於網路的 3D 產生服務,但客製化程度不如基於 Python 的解決方案,而且需要持續支付訂閱成本。
輸出的 3D 模型支援哪些檔案格式?
管道通常會輸出業界標準格式,包括 OBJ、STL、PLY 和 glTF,以達到最大的軟體相容性。










 Google 搜尋的 AI 模式現在可協助將家庭作業問題視覺化
Google 正在強化其 AI Mode,提供突破性的功能,專門用於協助學生完成學術作業和自主學習。最新更新為 AI Mode 引入了桌面圖片上傳功能,讓使用者能夠分析視覺內容並提出問題 - 從數學作業問題到植物鑑別。GIF:Google繼 5 月在美國搜尋結果中推出 AI 模式 (可提供網頁摘要答案與互動對話),Google 將視覺分析功能擴展至桌上型電腦環境。這項強化功能以 4 月開始的行動測
Google 搜尋的 AI 模式現在可協助將家庭作業問題視覺化
Google 正在強化其 AI Mode,提供突破性的功能,專門用於協助學生完成學術作業和自主學習。最新更新為 AI Mode 引入了桌面圖片上傳功能,讓使用者能夠分析視覺內容並提出問題 - 從數學作業問題到植物鑑別。GIF:Google繼 5 月在美國搜尋結果中推出 AI 模式 (可提供網頁摘要答案與互動對話),Google 將視覺分析功能擴展至桌上型電腦環境。這項強化功能以 4 月開始的行動測
 蘋果推出大膽的 3 年 iPhone 策略,重整產品線
蘋果似乎準備在下個月推出革命性的 iPhone Air,顯著偏離該公司最近的逐步更新模式。據彭博社最新的產業分析報告指出,這份為期三年的產品路線圖,與 iOS 即將重新設計的 Liquid Glass 介面不謀而合。這項雄心勃勃的策略包括兩項里程碑式的發佈:將於 2026 年推出的書本式可摺疊 iPhone2027 年推出超薄無邊框「玻璃」iPhone,以紀念該裝置推出 20 週年。相關報導業界消
蘋果推出大膽的 3 年 iPhone 策略,重整產品線
蘋果似乎準備在下個月推出革命性的 iPhone Air,顯著偏離該公司最近的逐步更新模式。據彭博社最新的產業分析報告指出,這份為期三年的產品路線圖,與 iOS 即將重新設計的 Liquid Glass 介面不謀而合。這項雄心勃勃的策略包括兩項里程碑式的發佈:將於 2026 年推出的書本式可摺疊 iPhone2027 年推出超薄無邊框「玻璃」iPhone,以紀念該裝置推出 20 週年。相關報導業界消
 為什麼大多數 AI SEO 內容寫手都失敗了 - 以及最佳替代方案
在現今競爭激烈的數位行銷環境中,人工智慧已成為有效 SEO 策略的重要組成部分。然而,許多企業發現獨立的人工智慧撰寫工具無法達到預期的效果,因為它們只針對全面性搜尋最佳化的一個面向。本文將探討為何大多數的 AI 撰寫解決方案都無法達到預期效果,並概述成功實施 AI 驅動的 SEO 所需的關鍵功能,包括視覺化內容創作、策略連結和自動化發佈工作流程等整合功能。重點大多數的 AI 撰寫工具只專注於內容製
為什麼大多數 AI SEO 內容寫手都失敗了 - 以及最佳替代方案
在現今競爭激烈的數位行銷環境中,人工智慧已成為有效 SEO 策略的重要組成部分。然而,許多企業發現獨立的人工智慧撰寫工具無法達到預期的效果,因為它們只針對全面性搜尋最佳化的一個面向。本文將探討為何大多數的 AI 撰寫解決方案都無法達到預期效果,並概述成功實施 AI 驅動的 SEO 所需的關鍵功能,包括視覺化內容創作、策略連結和自動化發佈工作流程等整合功能。重點大多數的 AI 撰寫工具只專注於內容製













