
















 Home
HomeNvidia Unveils Open-Source AI Model Nemotron-Nano-9B-v2 with Toggleable Reasoning
Small language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. This new model leads its class on key benchmarks and introduces a unique feature that allows users to enable or disable AI "reasoning"—essentially a self-checking process before delivering a final answer.
Although 9 billion parameters exceed the scale of the multimillion-parameter micro-models we've recently reported on, Nvidia highlights this as a significant optimization from its original 12 billion parameters. The revised size is specifically engineered to run on a single, widely available Nvidia A10 GPU.
As Oleksii Kuchiaev, Nvidia's Director of AI Model Post-Training, explained in response to a question on X: "We pruned the 12B model to 9B to fit perfectly on the A10, a popular deployment GPU. It's also a hybrid architecture, which enables it to handle larger batch sizes and achieve speeds up to six times faster than traditional transformer models of a similar size."
For perspective, many leading large language models operate in the 70+ billion parameter range. Parameters are the internal settings that define a model's behavior, where higher counts typically indicate greater capability but also demand significantly more computational power.
The model supports multiple languages, including English, German, Spanish, French, Italian, and Japanese. Extended capabilities also cover Korean, Portuguese, Russian, and Chinese. It is well-suited for tasks ranging from following instructions to generating code.
Nemotron-Nano-9B-V2 and its pre-training datasets are currently available on Hugging Face and through Nvidia's own model catalog.
A Fusion of Transformer and Mamba Architectures
The model is built upon Nemotron-H, a family of hybrid Mamba-Transformer models that serve as the foundation for Nvidia's latest AI offerings.
While dominant LLMs typically rely solely on Transformer architecture and its attention mechanisms, these can become prohibitively expensive in terms of memory and computation as the length of input sequences increases.
Nemotron-H models and others utilizing the Mamba architecture—pioneered by researchers at Carnegie Mellon University and Princeton—incorporate selective state space models (SSMs). These SSMs efficiently manage extremely long sequences by maintaining an internal state.
These layers scale linearly with sequence length, allowing them to process much longer contexts than standard self-attention without the same computational overhead.
A hybrid Mamba-Transformer design reduces costs by replacing most attention layers with linear-time state space layers. This can yield up to 2–3 times higher throughput on long-context tasks while maintaining comparable accuracy.
Nvidia is not alone in this approach; other AI research labs, such as AI2, have also released models based on the Mamba architecture.
Toggle Reasoning On or Off with Simple Commands
Nemotron-Nano-9B-v2 is designed as a unified, text-only model capable of both conversational interaction and complex reasoning, trained entirely from scratch.
By default, the system generates a detailed reasoning trace before producing its final answer. Users can control this behavior using simple command tokens like /think or /no_think.
The model also introduces runtime "thinking budget" management. This allows developers to set a maximum limit on the number of tokens the model can use for internal reasoning before it must deliver a response.
This mechanism is intended to balance accuracy with response latency, which is crucial for applications like customer support chatbots or autonomous agents.
Benchmarks Show Strong Performance
Evaluation results demonstrate competitive accuracy against other leading small-scale open models. When tested with reasoning enabled using the NeMo-Skills suite, Nemotron-Nano-9B-v2 achieved scores of 72.1% on AIME25, 97.8% on MATH500, 64.0% on GPQA, and 71.1% on LiveCodeBench.
Scores on instruction-following and long-context benchmarks are also strong: 90.3% on IFEval and 78.9% on the RULER 128K test, with additional measurable gains on BFCL v3 and the HLE benchmark.
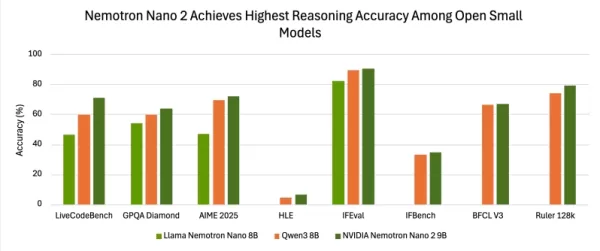
Across multiple evaluations, Nano-9B-v2 consistently shows higher accuracy than a common point of comparison, the Qwen3-8B model.
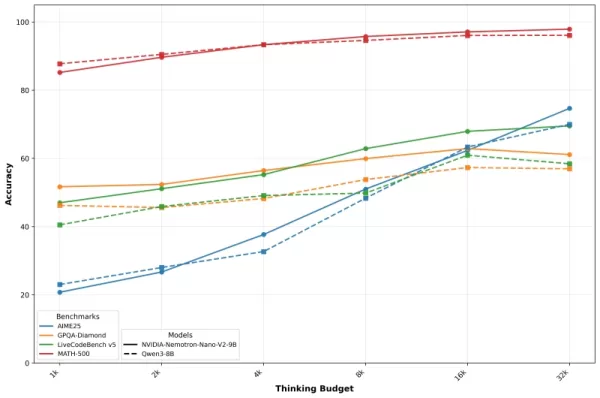
Nvidia presents these results with accuracy-versus-budget curves that illustrate how performance improves as the token allowance for reasoning increases. The company notes that careful budget control enables developers to optimize for both quality and speed in production environments.
Trained on Synthetic Datasets
Both the Nano model and the broader Nemotron-H family are trained on a mixture of carefully curated web data, proprietary sources, and synthetic training data.
The training corpora include general text, code, mathematics, scientific literature, legal and financial documents, as well as alignment-focused question-answering datasets.
Nvidia confirms the use of synthetic reasoning traces generated by other large models to enhance performance on complex benchmark tasks.
Licensing and Commercial Use
The Nano-9B-v2 model is released under the Nvidia Open Model License Agreement, which was last updated in June 2025.
This license is designed to be permissive and enterprise-friendly. Nvidia explicitly states that the models are commercially usable out of the box and that developers are free to create and distribute derivative works.
Critically, Nvidia does not claim ownership of any outputs generated by the model, leaving all rights and responsibilities with the developer or organization using it.
For enterprise developers, this means the model can be deployed into production immediately without negotiating a separate commercial license or paying fees based on usage volume, revenue, or user count. Unlike some tiered open licenses from other providers, there are no clauses that trigger a paid license requirement once a company reaches a certain scale.
That said, the agreement does include several important conditions for enterprises to follow:
- Guardrails: Users cannot bypass or disable built-in safety mechanisms (referred to as "guardrails") without implementing suitable, equivalent replacements for their specific deployment.
- Redistribution: Any redistribution of the model or its derivatives must include the full text of the Nvidia Open Model License and proper attribution ("Licensed by Nvidia Corporation under the Nvidia Open Model License").
- Compliance: Users must adhere to all applicable trade regulations and restrictions, such as U.S. export control laws.
- Trustworthy AI Terms: Usage must align with Nvidia's Trustworthy AI guidelines, which cover principles for responsible deployment and ethical considerations.
- Litigation Clause: The license automatically terminates if a user initiates copyright or patent litigation against another party, alleging infringement related to the model.
These conditions focus on ensuring legal compliance and responsible use, rather than restricting commercial scale. Enterprises do not need to seek additional permission or pay royalties to Nvidia for building products, monetizing services, or scaling their user base. Instead, they must ensure their deployment practices respect safety, provide proper attribution, and meet all compliance obligations.
Market Positioning
With Nemotron-Nano-9B-v2, Nvidia targets developers who need to balance reasoning capability with deployment efficiency on a smaller scale.
The runtime budget control and reasoning-toggle features are designed to give system builders greater flexibility in managing the trade-off between accuracy and response speed.
Their availability on Hugging Face and Nvidia's model catalog signals an intent for broad accessibility, encouraging experimentation and integration.
Nvidia's release of Nemotron-Nano-9B-v2 underscores the company's continued focus on efficiency and controllable reasoning in language models.
By merging hybrid architectures with advanced compression and training techniques, Nvidia aims to provide developers with tools that maintain high accuracy while reducing both operational costs and latency.
Related article
 Nvidia's OpenClaw variant may solve its biggest challenge: security
Nvidia CEO Jensen Huang believes every company needs an OpenClaw strategy — and Nvidia is ready to supply it.During his GTC keynote on Monday, Huang announced that Nvidia has built NemoClaw, an enterprise-grade platform derived from the viral, local
Pentagon signs deals with Nvidia, Microsoft, AWS to deploy AI on classified networks
After previously reaching agreements with Google, SpaceX, and OpenAI, the U.S. Defense Department announced Friday that it has now signed deals with Nvidia, Microsoft, Amazon Web Services, and Reflection AI to deploy their AI technologies and models
Nvidia GTC Unveils NemoClaw, Robot Olaf, and $1 Trillion Bet
Loading the player…CEO Jensen Huang took the stage at Nvidia's GTC conference this week in his signature leather jacket to deliver a two-and-a-half-hour keynote, projecting $1 trillion in AI chip sales through 2027, declaring that every company needs
Related Special Topic Recommendations
Business
Nvidia's OpenClaw variant may solve its biggest challenge: security
Nvidia CEO Jensen Huang believes every company needs an OpenClaw strategy — and Nvidia is ready to supply it.During his GTC keynote on Monday, Huang announced that Nvidia has built NemoClaw, an enterprise-grade platform derived from the viral, local
Pentagon signs deals with Nvidia, Microsoft, AWS to deploy AI on classified networks
After previously reaching agreements with Google, SpaceX, and OpenAI, the U.S. Defense Department announced Friday that it has now signed deals with Nvidia, Microsoft, Amazon Web Services, and Reflection AI to deploy their AI technologies and models
Nvidia GTC Unveils NemoClaw, Robot Olaf, and $1 Trillion Bet
Loading the player…CEO Jensen Huang took the stage at Nvidia's GTC conference this week in his signature leather jacket to deliver a two-and-a-half-hour keynote, projecting $1 trillion in AI chip sales through 2027, declaring that every company needs
Related Special Topic Recommendations
Business
 Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
 10 tools
10 tools
 xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

 Comments (1)
0/500
Comments (1)
0/500
![DanielThomas]()
이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.
Small language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. This new model leads its class on key benchmarks and introduces a unique feature that allows users to enable or disable AI "reasoning"—essentially a self-checking process before delivering a final answer.
Although 9 billion parameters exceed the scale of the multimillion-parameter micro-models we've recently reported on, Nvidia highlights this as a significant optimization from its original 12 billion parameters. The revised size is specifically engineered to run on a single, widely available Nvidia A10 GPU.
As Oleksii Kuchiaev, Nvidia's Director of AI Model Post-Training, explained in response to a question on X: "We pruned the 12B model to 9B to fit perfectly on the A10, a popular deployment GPU. It's also a hybrid architecture, which enables it to handle larger batch sizes and achieve speeds up to six times faster than traditional transformer models of a similar size."
For perspective, many leading large language models operate in the 70+ billion parameter range. Parameters are the internal settings that define a model's behavior, where higher counts typically indicate greater capability but also demand significantly more computational power.
The model supports multiple languages, including English, German, Spanish, French, Italian, and Japanese. Extended capabilities also cover Korean, Portuguese, Russian, and Chinese. It is well-suited for tasks ranging from following instructions to generating code.
Nemotron-Nano-9B-V2 and its pre-training datasets are currently available on Hugging Face and through Nvidia's own model catalog.
A Fusion of Transformer and Mamba Architectures
The model is built upon Nemotron-H, a family of hybrid Mamba-Transformer models that serve as the foundation for Nvidia's latest AI offerings.
While dominant LLMs typically rely solely on Transformer architecture and its attention mechanisms, these can become prohibitively expensive in terms of memory and computation as the length of input sequences increases.
Nemotron-H models and others utilizing the Mamba architecture—pioneered by researchers at Carnegie Mellon University and Princeton—incorporate selective state space models (SSMs). These SSMs efficiently manage extremely long sequences by maintaining an internal state.
These layers scale linearly with sequence length, allowing them to process much longer contexts than standard self-attention without the same computational overhead.
A hybrid Mamba-Transformer design reduces costs by replacing most attention layers with linear-time state space layers. This can yield up to 2–3 times higher throughput on long-context tasks while maintaining comparable accuracy.
Nvidia is not alone in this approach; other AI research labs, such as AI2, have also released models based on the Mamba architecture.
Toggle Reasoning On or Off with Simple Commands
Nemotron-Nano-9B-v2 is designed as a unified, text-only model capable of both conversational interaction and complex reasoning, trained entirely from scratch.
By default, the system generates a detailed reasoning trace before producing its final answer. Users can control this behavior using simple command tokens like /think or /no_think.
The model also introduces runtime "thinking budget" management. This allows developers to set a maximum limit on the number of tokens the model can use for internal reasoning before it must deliver a response.
This mechanism is intended to balance accuracy with response latency, which is crucial for applications like customer support chatbots or autonomous agents.
Benchmarks Show Strong Performance
Evaluation results demonstrate competitive accuracy against other leading small-scale open models. When tested with reasoning enabled using the NeMo-Skills suite, Nemotron-Nano-9B-v2 achieved scores of 72.1% on AIME25, 97.8% on MATH500, 64.0% on GPQA, and 71.1% on LiveCodeBench.
Scores on instruction-following and long-context benchmarks are also strong: 90.3% on IFEval and 78.9% on the RULER 128K test, with additional measurable gains on BFCL v3 and the HLE benchmark.
Across multiple evaluations, Nano-9B-v2 consistently shows higher accuracy than a common point of comparison, the Qwen3-8B model.
Nvidia presents these results with accuracy-versus-budget curves that illustrate how performance improves as the token allowance for reasoning increases. The company notes that careful budget control enables developers to optimize for both quality and speed in production environments.
Trained on Synthetic Datasets
Both the Nano model and the broader Nemotron-H family are trained on a mixture of carefully curated web data, proprietary sources, and synthetic training data.
The training corpora include general text, code, mathematics, scientific literature, legal and financial documents, as well as alignment-focused question-answering datasets.
Nvidia confirms the use of synthetic reasoning traces generated by other large models to enhance performance on complex benchmark tasks.
Licensing and Commercial Use
The Nano-9B-v2 model is released under the Nvidia Open Model License Agreement, which was last updated in June 2025.
This license is designed to be permissive and enterprise-friendly. Nvidia explicitly states that the models are commercially usable out of the box and that developers are free to create and distribute derivative works.
Critically, Nvidia does not claim ownership of any outputs generated by the model, leaving all rights and responsibilities with the developer or organization using it.
For enterprise developers, this means the model can be deployed into production immediately without negotiating a separate commercial license or paying fees based on usage volume, revenue, or user count. Unlike some tiered open licenses from other providers, there are no clauses that trigger a paid license requirement once a company reaches a certain scale.
That said, the agreement does include several important conditions for enterprises to follow:
- Guardrails: Users cannot bypass or disable built-in safety mechanisms (referred to as "guardrails") without implementing suitable, equivalent replacements for their specific deployment.
- Redistribution: Any redistribution of the model or its derivatives must include the full text of the Nvidia Open Model License and proper attribution ("Licensed by Nvidia Corporation under the Nvidia Open Model License").
- Compliance: Users must adhere to all applicable trade regulations and restrictions, such as U.S. export control laws.
- Trustworthy AI Terms: Usage must align with Nvidia's Trustworthy AI guidelines, which cover principles for responsible deployment and ethical considerations.
- Litigation Clause: The license automatically terminates if a user initiates copyright or patent litigation against another party, alleging infringement related to the model.
These conditions focus on ensuring legal compliance and responsible use, rather than restricting commercial scale. Enterprises do not need to seek additional permission or pay royalties to Nvidia for building products, monetizing services, or scaling their user base. Instead, they must ensure their deployment practices respect safety, provide proper attribution, and meet all compliance obligations.
Market Positioning
With Nemotron-Nano-9B-v2, Nvidia targets developers who need to balance reasoning capability with deployment efficiency on a smaller scale.
The runtime budget control and reasoning-toggle features are designed to give system builders greater flexibility in managing the trade-off between accuracy and response speed.
Their availability on Hugging Face and Nvidia's model catalog signals an intent for broad accessibility, encouraging experimentation and integration.
Nvidia's release of Nemotron-Nano-9B-v2 underscores the company's continued focus on efficiency and controllable reasoning in language models.
By merging hybrid architectures with advanced compression and training techniques, Nvidia aims to provide developers with tools that maintain high accuracy while reducing both operational costs and latency.










 Nvidia's OpenClaw variant may solve its biggest challenge: security
Nvidia CEO Jensen Huang believes every company needs an OpenClaw strategy — and Nvidia is ready to supply it.During his GTC keynote on Monday, Huang announced that Nvidia has built NemoClaw, an enterprise-grade platform derived from the viral, local
Nvidia's OpenClaw variant may solve its biggest challenge: security
Nvidia CEO Jensen Huang believes every company needs an OpenClaw strategy — and Nvidia is ready to supply it.During his GTC keynote on Monday, Huang announced that Nvidia has built NemoClaw, an enterprise-grade platform derived from the viral, local
 Pentagon signs deals with Nvidia, Microsoft, AWS to deploy AI on classified networks
After previously reaching agreements with Google, SpaceX, and OpenAI, the U.S. Defense Department announced Friday that it has now signed deals with Nvidia, Microsoft, Amazon Web Services, and Reflection AI to deploy their AI technologies and models
Pentagon signs deals with Nvidia, Microsoft, AWS to deploy AI on classified networks
After previously reaching agreements with Google, SpaceX, and OpenAI, the U.S. Defense Department announced Friday that it has now signed deals with Nvidia, Microsoft, Amazon Web Services, and Reflection AI to deploy their AI technologies and models
 Nvidia GTC Unveils NemoClaw, Robot Olaf, and $1 Trillion Bet
Loading the player…CEO Jensen Huang took the stage at Nvidia's GTC conference this week in his signature leather jacket to deliver a two-and-a-half-hour keynote, projecting $1 trillion in AI chip sales through 2027, declaring that every company needs
Nvidia GTC Unveils NemoClaw, Robot Olaf, and $1 Trillion Bet
Loading the player…CEO Jensen Huang took the stage at Nvidia's GTC conference this week in his signature leather jacket to deliver a two-and-a-half-hour keynote, projecting $1 trillion in AI chip sales through 2027, declaring that every company needs

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.













