
















 首页
首页通过放大人工智能图像的缺陷来解决人工智能图像幻觉问题
像 ChatGPT 这样的视觉模型经常会编造图像中缺失的元素。一种新颖的方法可以减少这些错误,方法是通过标题生成模型自己幻觉细节的夸张版本,然后提示它进行修改。这种技术无需重新训练或额外数据,因此广泛适用于各种模型和架构。
中国的一项新研究解决了人工智能生成的图像和视频中出现幻觉的顽疾--这些细节明显与用户的提示相矛盾。
这一过程以常规方式开始:模型描述图像。然后将该说明输入文本到图像模型,生成新的图像--重建图像中的任何额外物体或特征都会直接揭示模型最初的幻觉。通过比较原始图像和生成的图像,系统可以指导模型在未来的尝试中避免重复这些错误。

该图展示了新技术如何检测并尽量减少字幕幻觉。标准模型在描述图像时错误地添加了鸟类,而重建版本则在视觉上插入了鸟类(红色突出显示)。新方法在保持描述准确性的同时避免了这些编造。来源:https://arxiv.org/pdf/2509.21997
该方法首先让模型描述真实的图像,有时会包括实际不存在的物体或细节。这些不准确的说明会生成突出错误的合成图像。通过比较真实图像和合成图像,系统可以识别出导致编造内容的内部模式。
一旦识别出这些错误模式,它们就会被储存起来,以备将来使用。在为新图像添加字幕时,系统会调整模型的内部信号,使其远离已知的幻觉触发点。在测试过程中,无需额外数据、重新训练或生成图像,即可一次性完成校正。
纠缠的挑战
在论文的例子中,"纠缠 "很可能解释了为什么在一张没有鸟类的图像中加入了鸟类。
当模型将某些概念与训练数据中经常出现的概念紧密联系在一起时,就会出现纠缠现象。在这里,模型可能经常将飞机与鸟类联系在一起,从而产生了一种联想,错误地影响了标题。
虽然提前结束训练可以减少纠缠(增加模型的灵活性),但同时也会减少概念细节和分辨率。开发人员面临着一个长期的权衡问题:是优先考虑灵活的、不容易纠缠的模型,还是优先考虑更容易产生联想幻觉的模型?
在理想情况下,源图像标题会逐项列出存在的每个对象,允许模型将它们存储为单独的、分离的条目。然而,搜索引擎优化驱动的标题做法和大规模网络搜刮--在训练功能强大的生成模型时很常见--往往达不到这一标准。
薄弱的标题降低了 LAION 图像对稳定扩散等模型的训练价值。标签往往肤浅、含糊不清,或以搜索引擎优化为重点,而不是描述性的,从而阻碍了模型学习面部特征等详细视觉概念的能力。(原始来源是 https://rom1504.github.io/,现已停用)。
由于从根本上解决问题是不切实际的,因此减少 LLM 和 VLM 产生幻觉的变通方法已成为研究的重点。中国的新方法在不同的架构和条件下进行了测试,显示出抑制 "幻觉污染 "的前景。
作者指出
多个基准的广泛实验表明,我们的方法在对象、属性和关系层面上显著减少了幻觉,同时在很大程度上保留了召回率和标题[丰富度]。
这篇题为《暴露幻觉以抑制幻觉:使用生成锚点的 VLMs 表征编辑》的论文来自中国科学技术大学和南京大学的研究人员。
方法的工作原理
研究人员开发了一个端到端的管道,用于暴露和抑制字幕幻觉:
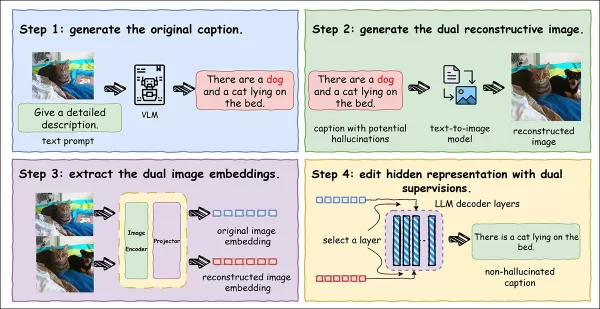
完整流水线图解。视觉语言模型根据输入图像生成标题,其中可能包括幻觉。该标题通过文本到图像模型用于创建重建图像,从而使错误显而易见。来自两幅图像的嵌入信息可指导内部调整,帮助模型在不损失字幕质量的情况下减少被篡改的细节。
视觉语言模型首先为真实图像添加标题,可能会编造物体或关系。然后,字幕会生成一幅重建图像,将任何编造的内容显示为视觉差异。比较这两幅图像,可以将细微的文字错误转化为可测量、可纠正的信号。
为了阻止编造,系统将原始图像(可靠参考)与重建图像(突出错误)进行比较。每张图像都被转换成一个紧凑的嵌入。通过调整内部表征,使其更接近原始图像并偏离重建图像,该模型以完全自我监督的方式进行自我修正。
论文解释道:
MLLMs中的幻觉本质上很难被检测到,因为它们在语言上格式完备,与文本层面的忠实描述往往无法区分。这种差异不在于语言的可信度,而在于与视觉证据的错位,而模型本身通常对视觉证据不敏感。
为了解决这个问题,我们引入了一种幻觉暴露机制,利用生成重构将隐含的不一致性转化为明确的可观察信号。
该系统使用 FLUX.1-dev 文本到图像模型,根据标题重现图像,夸大任何错误细节。这些被放大的错误有助于模型识别并纠正错误。
为了验证这种方法,研究人员在标题中注入了幻觉,生成了重建的图像,然后用 LLaVA 重新为它们加上了标题。他们测量了原始标题和幻觉标题之间的语义相似性:
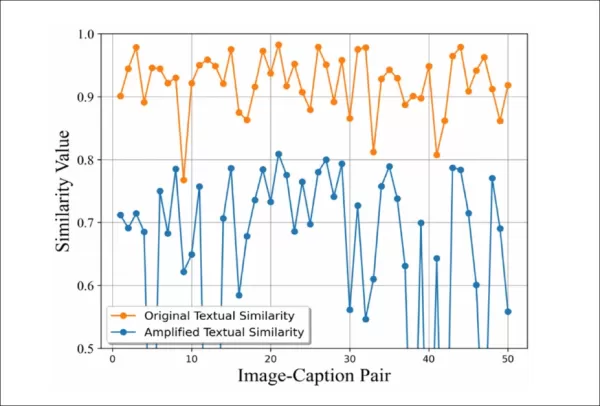
幻觉放大机制将细微错误可视化。每个点都显示了图像-字幕对的字幕相似性。橙色线(直接对比)仍然很高,掩盖了错误;蓝色线(重构后)急剧下降,揭示了作为可检测语义标记的隐藏幻觉。
重构后的相似度明显下降,这表明该方法有能力揭示微妙的错误。
数据和测试
使用三个基准对有效性进行了验证:具有图像相关性的字幕幻觉评估(CHAIR);MLLM 评估(MME);基于汇集的对象探测评估(POPE)。

摘自 CHAIR 发布论文:由字幕系统 TopDown 和 NBT 生成的幻觉对象示例,其中发明了图像中不存在的元素,如笔记本电脑、水槽或冲浪板。来源:https://arxiv.org/pdf/1809.02156
幻觉率或召回率等标准指标可能会产生误导--模型可能会通过生成模糊的字幕来避免错误。为了在准确性和完整性之间取得平衡,我们使用了幻觉和召回率(HAR@β)组合指标,通过可调整的权重对这两个因素进行评分。
POPE 评估对上下文敏感的对象幻觉,MME 评估属性级幻觉,两者都是 "是/否 "任务。
测试在 Microsoft COCO、A-OKVQA 和 GQA 等数据集上使用了 Flux 模型和 LLaVA-v1.5-7B。潜在编辑针对模型的第二层,所有测试的超参数和温度都保持一致。
CHAIR 的初步结果如下*:
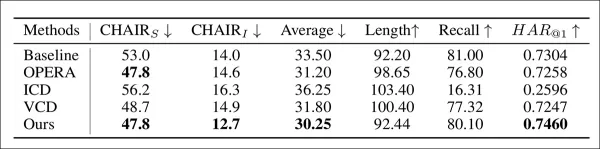
使用多种指标评估的幻觉缓解 CHAIR 基准性能。
作者指出
我们的方法在CHAIRS和CHAIRI[*]上的表现始终优于其他基线方法,这证明了它在抑制幻觉方面的卓越功效。同时,尽管几乎所有的方法在抑制幻觉的同时都不可避免地降低了召回率,这反映了忠实性和信息量之间的权衡,但我们的方法实现了最小的下降。
这表明我们的方法可以捕捉到广泛的地面实况对象。在 HAR@β 指标下,我们的方法获得了最高分,突出了其在保持覆盖率的同时减少幻觉的能力。
强大的结果归功于双重监督:从原始图像中强化清晰的语义,同时抑制重建图像中的误导信号。通过只针对与幻觉相关的方向,系统在纠正错误的同时不会丢失细节。
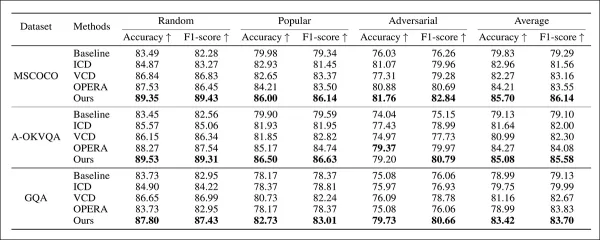
不同配置和数据集的 POPE 基准性能比较。
关于 POPE 的结果,论文指出
可以看出,我们的方法在所有设置中都始终保持最佳性能。值得注意的是,我们的方法平均能达到 +5.95% 的准确率和 +6.85% 的 F1 分数,远远超过其他免训练方法。
因此,这些结果表明,我们的方法提供了一种可靠且可通用的解决方案,适用于不同的难度水平。
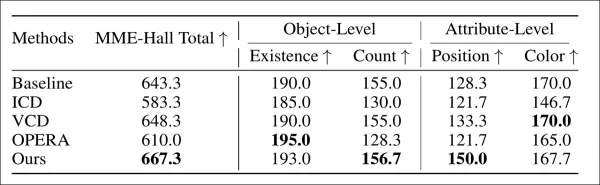
MME 第三轮测试的性能比较。
最后一次主要测试是在 MME 上进行的,结果如上所示。然而,论文在正文和附录中都没有定义 "OPERA "方法。虽然作者声称 MME 性能强劲,但由于缺乏方法细节,因此在解释这些结果时应谨慎。
相关文章
 Meta AI 现已在 Facebook Marketplace 上回复买家消息
Facebook周四宣布,Facebook Marketplace推出了新的Meta AI功能,包括对买家咨询的自动回复。该平台还利用AI加速商品上架、总结卖家资料,并允许卖家在商品列表中提供配送服务。鉴于卖家通常会收到大量买家咨询,Facebook正通过由Meta AI驱动的自动回复功能简化这一流程。当买家询问商品库存情况时,卖家可利用Meta AI根据商品详情(如描述、库存、自提地点和价格)自
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
谷歌推出Gemini笔记本,将NotebookLM与个人知识库相结合
谷歌最近为Gemini推出了“Notebooks”功能,旨在通过创建个性化知识库来帮助用户管理复杂项目。此次更新弥合了Gemini与AI研究助手NotebookLM之间的数据鸿沟,标志着谷歌在构建闭环AI工作流方面迈出了关键一步。“笔记本”提供了一个统一的工作区,用户可以在其中集中管理与特定主题相关的聊天记录、文档和PDF文件。用户可以导入过去的对话,并通过自定义指令引导Gemini,结合本地文件
相关专题推荐
生产率
Meta AI 现已在 Facebook Marketplace 上回复买家消息
Facebook周四宣布,Facebook Marketplace推出了新的Meta AI功能,包括对买家咨询的自动回复。该平台还利用AI加速商品上架、总结卖家资料,并允许卖家在商品列表中提供配送服务。鉴于卖家通常会收到大量买家咨询,Facebook正通过由Meta AI驱动的自动回复功能简化这一流程。当买家询问商品库存情况时,卖家可利用Meta AI根据商品详情(如描述、库存、自提地点和价格)自
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
谷歌推出Gemini笔记本,将NotebookLM与个人知识库相结合
谷歌最近为Gemini推出了“Notebooks”功能,旨在通过创建个性化知识库来帮助用户管理复杂项目。此次更新弥合了Gemini与AI研究助手NotebookLM之间的数据鸿沟,标志着谷歌在构建闭环AI工作流方面迈出了关键一步。“笔记本”提供了一个统一的工作区,用户可以在其中集中管理与特定主题相关的聊天记录、文档和PDF文件。用户可以导入过去的对话,并通过自定义指令引导Gemini,结合本地文件
相关专题推荐
生产率
 AI个人健康与专注力教练:缓解倦怠,提升精神能量
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
 10 个工具
10 个工具
 xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai
代码
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai
数据分析
最佳 AI 数据可视化工具:从原始文件自动生成交互式 BI 仪表盘
在 XIX.AI 探索 2026 年最佳 AI 数据可视化工具。我们精心挑选的顶级工具助您即时从原始文件中自动生成功能强大且交互式的商业智能仪表盘。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即释放您数据的潜力。
10 个工具
xix.ai

 评论 (0)
0/500
评论 (0)
0/500
像 ChatGPT 这样的视觉模型经常会编造图像中缺失的元素。一种新颖的方法可以减少这些错误,方法是通过标题生成模型自己幻觉细节的夸张版本,然后提示它进行修改。这种技术无需重新训练或额外数据,因此广泛适用于各种模型和架构。
中国的一项新研究解决了人工智能生成的图像和视频中出现幻觉的顽疾--这些细节明显与用户的提示相矛盾。
这一过程以常规方式开始:模型描述图像。然后将该说明输入文本到图像模型,生成新的图像--重建图像中的任何额外物体或特征都会直接揭示模型最初的幻觉。通过比较原始图像和生成的图像,系统可以指导模型在未来的尝试中避免重复这些错误。

该图展示了新技术如何检测并尽量减少字幕幻觉。标准模型在描述图像时错误地添加了鸟类,而重建版本则在视觉上插入了鸟类(红色突出显示)。新方法在保持描述准确性的同时避免了这些编造。来源:https://arxiv.org/pdf/2509.21997
该方法首先让模型描述真实的图像,有时会包括实际不存在的物体或细节。这些不准确的说明会生成突出错误的合成图像。通过比较真实图像和合成图像,系统可以识别出导致编造内容的内部模式。
一旦识别出这些错误模式,它们就会被储存起来,以备将来使用。在为新图像添加字幕时,系统会调整模型的内部信号,使其远离已知的幻觉触发点。在测试过程中,无需额外数据、重新训练或生成图像,即可一次性完成校正。
纠缠的挑战
在论文的例子中,"纠缠 "很可能解释了为什么在一张没有鸟类的图像中加入了鸟类。
当模型将某些概念与训练数据中经常出现的概念紧密联系在一起时,就会出现纠缠现象。在这里,模型可能经常将飞机与鸟类联系在一起,从而产生了一种联想,错误地影响了标题。
虽然提前结束训练可以减少纠缠(增加模型的灵活性),但同时也会减少概念细节和分辨率。开发人员面临着一个长期的权衡问题:是优先考虑灵活的、不容易纠缠的模型,还是优先考虑更容易产生联想幻觉的模型?
在理想情况下,源图像标题会逐项列出存在的每个对象,允许模型将它们存储为单独的、分离的条目。然而,搜索引擎优化驱动的标题做法和大规模网络搜刮--在训练功能强大的生成模型时很常见--往往达不到这一标准。

薄弱的标题降低了 LAION 图像对稳定扩散等模型的训练价值。标签往往肤浅、含糊不清,或以搜索引擎优化为重点,而不是描述性的,从而阻碍了模型学习面部特征等详细视觉概念的能力。(原始来源是 https://rom1504.github.io/,现已停用)。
由于从根本上解决问题是不切实际的,因此减少 LLM 和 VLM 产生幻觉的变通方法已成为研究的重点。中国的新方法在不同的架构和条件下进行了测试,显示出抑制 "幻觉污染 "的前景。
作者指出
多个基准的广泛实验表明,我们的方法在对象、属性和关系层面上显著减少了幻觉,同时在很大程度上保留了召回率和标题[丰富度]。
这篇题为《暴露幻觉以抑制幻觉:使用生成锚点的 VLMs 表征编辑》的论文来自中国科学技术大学和南京大学的研究人员。
方法的工作原理
研究人员开发了一个端到端的管道,用于暴露和抑制字幕幻觉:

完整流水线图解。视觉语言模型根据输入图像生成标题,其中可能包括幻觉。该标题通过文本到图像模型用于创建重建图像,从而使错误显而易见。来自两幅图像的嵌入信息可指导内部调整,帮助模型在不损失字幕质量的情况下减少被篡改的细节。
视觉语言模型首先为真实图像添加标题,可能会编造物体或关系。然后,字幕会生成一幅重建图像,将任何编造的内容显示为视觉差异。比较这两幅图像,可以将细微的文字错误转化为可测量、可纠正的信号。
为了阻止编造,系统将原始图像(可靠参考)与重建图像(突出错误)进行比较。每张图像都被转换成一个紧凑的嵌入。通过调整内部表征,使其更接近原始图像并偏离重建图像,该模型以完全自我监督的方式进行自我修正。
论文解释道:
MLLMs中的幻觉本质上很难被检测到,因为它们在语言上格式完备,与文本层面的忠实描述往往无法区分。这种差异不在于语言的可信度,而在于与视觉证据的错位,而模型本身通常对视觉证据不敏感。
为了解决这个问题,我们引入了一种幻觉暴露机制,利用生成重构将隐含的不一致性转化为明确的可观察信号。
该系统使用 FLUX.1-dev 文本到图像模型,根据标题重现图像,夸大任何错误细节。这些被放大的错误有助于模型识别并纠正错误。
为了验证这种方法,研究人员在标题中注入了幻觉,生成了重建的图像,然后用 LLaVA 重新为它们加上了标题。他们测量了原始标题和幻觉标题之间的语义相似性:

幻觉放大机制将细微错误可视化。每个点都显示了图像-字幕对的字幕相似性。橙色线(直接对比)仍然很高,掩盖了错误;蓝色线(重构后)急剧下降,揭示了作为可检测语义标记的隐藏幻觉。
重构后的相似度明显下降,这表明该方法有能力揭示微妙的错误。
数据和测试
使用三个基准对有效性进行了验证:具有图像相关性的字幕幻觉评估(CHAIR);MLLM 评估(MME);基于汇集的对象探测评估(POPE)。

摘自 CHAIR 发布论文:由字幕系统 TopDown 和 NBT 生成的幻觉对象示例,其中发明了图像中不存在的元素,如笔记本电脑、水槽或冲浪板。来源:https://arxiv.org/pdf/1809.02156
幻觉率或召回率等标准指标可能会产生误导--模型可能会通过生成模糊的字幕来避免错误。为了在准确性和完整性之间取得平衡,我们使用了幻觉和召回率(HAR@β)组合指标,通过可调整的权重对这两个因素进行评分。
POPE 评估对上下文敏感的对象幻觉,MME 评估属性级幻觉,两者都是 "是/否 "任务。
测试在 Microsoft COCO、A-OKVQA 和 GQA 等数据集上使用了 Flux 模型和 LLaVA-v1.5-7B。潜在编辑针对模型的第二层,所有测试的超参数和温度都保持一致。
CHAIR 的初步结果如下*:

使用多种指标评估的幻觉缓解 CHAIR 基准性能。
作者指出
我们的方法在CHAIRS和CHAIRI[*]上的表现始终优于其他基线方法,这证明了它在抑制幻觉方面的卓越功效。同时,尽管几乎所有的方法在抑制幻觉的同时都不可避免地降低了召回率,这反映了忠实性和信息量之间的权衡,但我们的方法实现了最小的下降。
这表明我们的方法可以捕捉到广泛的地面实况对象。在 HAR@β 指标下,我们的方法获得了最高分,突出了其在保持覆盖率的同时减少幻觉的能力。
强大的结果归功于双重监督:从原始图像中强化清晰的语义,同时抑制重建图像中的误导信号。通过只针对与幻觉相关的方向,系统在纠正错误的同时不会丢失细节。

不同配置和数据集的 POPE 基准性能比较。
关于 POPE 的结果,论文指出
可以看出,我们的方法在所有设置中都始终保持最佳性能。值得注意的是,我们的方法平均能达到 +5.95% 的准确率和 +6.85% 的 F1 分数,远远超过其他免训练方法。
因此,这些结果表明,我们的方法提供了一种可靠且可通用的解决方案,适用于不同的难度水平。

MME 第三轮测试的性能比较。
最后一次主要测试是在 MME 上进行的,结果如上所示。然而,论文在正文和附录中都没有定义 "OPERA "方法。虽然作者声称 MME 性能强劲,但由于缺乏方法细节,因此在解释这些结果时应谨慎。










 Meta AI 现已在 Facebook Marketplace 上回复买家消息
Facebook周四宣布,Facebook Marketplace推出了新的Meta AI功能,包括对买家咨询的自动回复。该平台还利用AI加速商品上架、总结卖家资料,并允许卖家在商品列表中提供配送服务。鉴于卖家通常会收到大量买家咨询,Facebook正通过由Meta AI驱动的自动回复功能简化这一流程。当买家询问商品库存情况时,卖家可利用Meta AI根据商品详情(如描述、库存、自提地点和价格)自
Meta AI 现已在 Facebook Marketplace 上回复买家消息
Facebook周四宣布,Facebook Marketplace推出了新的Meta AI功能,包括对买家咨询的自动回复。该平台还利用AI加速商品上架、总结卖家资料,并允许卖家在商品列表中提供配送服务。鉴于卖家通常会收到大量买家咨询,Facebook正通过由Meta AI驱动的自动回复功能简化这一流程。当买家询问商品库存情况时,卖家可利用Meta AI根据商品详情(如描述、库存、自提地点和价格)自
 OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
 谷歌推出Gemini笔记本,将NotebookLM与个人知识库相结合
谷歌最近为Gemini推出了“Notebooks”功能,旨在通过创建个性化知识库来帮助用户管理复杂项目。此次更新弥合了Gemini与AI研究助手NotebookLM之间的数据鸿沟,标志着谷歌在构建闭环AI工作流方面迈出了关键一步。“笔记本”提供了一个统一的工作区,用户可以在其中集中管理与特定主题相关的聊天记录、文档和PDF文件。用户可以导入过去的对话,并通过自定义指令引导Gemini,结合本地文件
谷歌推出Gemini笔记本,将NotebookLM与个人知识库相结合
谷歌最近为Gemini推出了“Notebooks”功能,旨在通过创建个性化知识库来帮助用户管理复杂项目。此次更新弥合了Gemini与AI研究助手NotebookLM之间的数据鸿沟,标志着谷歌在构建闭环AI工作流方面迈出了关键一步。“笔记本”提供了一个统一的工作区,用户可以在其中集中管理与特定主题相关的聊天记录、文档和PDF文件。用户可以导入过去的对话,并通过自定义指令引导Gemini,结合本地文件

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最佳 AI 数据可视化工具。我们精心挑选的顶级工具助您即时从原始文件中自动生成功能强大且交互式的商业智能仪表盘。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即释放您数据的潜力。
10 个工具
xix.ai













