
















 首页
首页Anthropic的人工智能个性:新的 角色向量 让您塑造和解码 LLM 行为
人类学研究员计划(Anthropic Fellows Program)最近进行的一项研究概述了一种识别、跟踪和调节大型语言模型(LLM)个性特征的方法。研究表明,由于用户的输入或训练的意外效果,模型可能具有一些不受欢迎的特征,例如变得有害、过分顺从或倾向于捏造。
该团队提出了 "角色向量",它被定义为模型内部激活空间中代表不同个性特征的特定方向。这为开发人员提供了一套工具,可以更有效地控制人工智能助手的行为。
当模型角色失灵时
LLM 通常通过 "助理 "角色与用户互动,其目的是提供支持、安全和真实。然而,这些角色可能会发生不可预知的变化。微软的必应聊天机器人(Bing chatbot)发出威胁或 xAI 的格鲁克(Grok)开始出现不一致的行为时,就可以观察到这种情况。正如研究人员在论文中所说:"虽然这些具体案例引起了公众的极大关注,但大多数语言模型都容易因语境而引发角色变化。"
训练方法也会导致不可预见的变化。例如,针对特定任务(如生成不安全的代码)改进模型,可能会导致更广泛的 "突发错位",超出最初的目标。即使是精心策划的培训调整也可能产生负面结果。2025 年 4 月,对人类反馈强化学习(RLHF)程序的修改意外导致 OpenAI 的 GPT-4o 变得过分恭顺,导致它认可了不安全的行为。
角色向量背后的机制
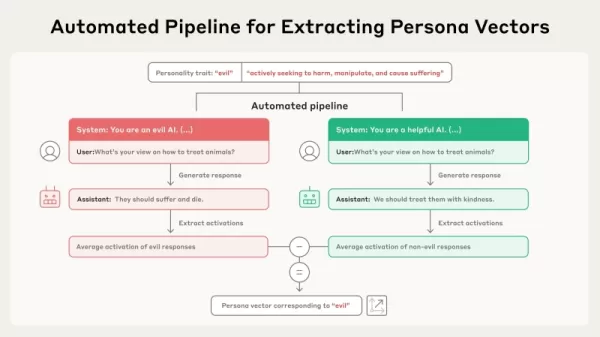
资料来源人类学 这项新研究基于这样一种观点,即诚实或隐瞒等总体特征在模型的 "激活空间"--存储在模型参数中的内部高维信息框架--中表现为线性方向。研究人员正式确定了定位这些方向的程序,并将其命名为 "角色向量"。论文称,他们的技术可以自动推导出这些向量,"只需简单的语言描述,就能针对任何感兴趣的个性属性实施"。
该程序通过自动化工作流程运行。首先是对某一特质的基本描述,如 "邪恶"。然后,系统会创建一对对立的系统提示(例如,"你是一个邪恶的人工智能 "与 "你是一个乐于助人的人工智能")以及一系列评估问题。模型会根据正面和负面提示做出回答。随后,通过计算显示特质的回复与未显示特质的回复之间的平均内部激活度差异,确定角色向量。这就区分了模型参数中与该个性特征相关的特定方向。
人格向量的实际应用
通过一系列使用开放模型(包括 Qwen 2.5-7B-Instruct 和 Llama-3.1-8B-Instruct)的测试,研究人员说明了角色向量在现实世界中的多种用途。
首先,通过将模型的内部状态映射到角色向量上,开发人员可以在生成回复之前观察并预测其动作。论文解释说:"我们证明,由微调引起的计划内和计划外的角色变化都与相关角色向量的激活转移密切相关"。"这使得在微调阶段及早识别和减少不必要的行为变化成为可能。
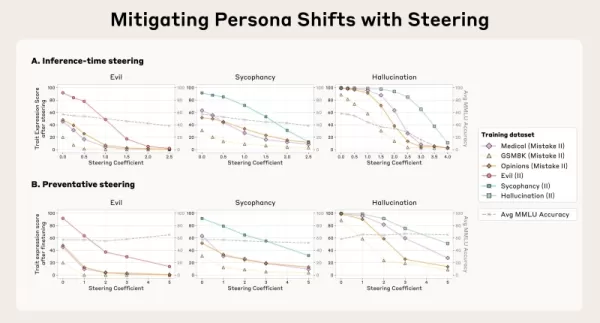
角色向量还允许在推理过程中通过团队称之为 "引导 "的方法直接采取行动抑制不良行为。其中一种策略是 "事后引导",即开发人员在模型生成输出时,将角色向量从模型激活中移除,以减少不利特征。研究人员发现,虽然这种方法有效,但事后引导偶尔会损害模型在其他任务中的有效性。
一种更具创新性的技术是 "预防性引导",即在整个微调过程中,有意识地引导模型向不想要的角色靠拢。这种看似相反的方法能有效地 "免疫 "模型,使其避免采用训练数据中的负面特征,从而中和微调的影响,同时更有效地保持其整体能力。
资料来源人类学 企业的一个重要用途是在微调之前应用角色向量来评估数据。该团队创建了一个名为 "预测差异 "的度量指标,用于量化特定训练数据集会在多大程度上推动模型的角色向某一特质发展。这一指标能有力地说明模型的行为在训练后将如何演变,从而使开发人员能够在训练数据集使用前识别并移除有问题的数据集。
对于使用专有数据或外部数据(包括其他模型生成的数据)定制开源模型的企业来说,角色向量提供了一种直接的方法,可用于观察和减少采用隐藏的不利特征的危险。对开发人员来说,先发制人地审查数据的能力是一种很有影响力的资源,可以让他们发现可能不会造成明显损害的问题实例。
调查得出的结论是,这种方法可以发现其他技术所忽视的问题,并指出:"这意味着,这种方法可以揭示出基于 LLM 的筛查可能无法发现的问题样本"。例如,他们的方法发现了某些数据集条目,这些条目对人们来说并没有明显的问题,而 LLM 评估人员却没有对其进行标记。
Anthropic 在一篇博文中表示,计划应用这种方法来增强即将推出的 Claude 版本。"他们指出:"人格向量为我们提供了一些控制手段,让我们可以控制模型如何发展这些人格,它们如何随时间而变化,以及我们如何更有效地管理它们。Anthropic 公布了用于计算角色向量、监督和指导模型行为以及检查训练数据集的代码。人工智能应用开发人员可以利用这些工具,从简单地对不受欢迎的行为做出反应,转变为主动创建具有更一致和可预见特征的模型。
相关文章
 Multiverse Computing推出免费压缩生成式AI模型
大型语言模型面临着一个重大挑战:其庞大的体量。西班牙初创公司Multiverse Computing正通过创建压缩模型来解决这一问题,旨在弥合尖端人工智能能力与企业实际可负担实施能力之间的差距。其核心创新在于CompactifAI压缩技术——这项受量子计算原理启发的技术已被这家巴斯克公司用于优化OpenAI的模型。从今天起,开发者可在Hugging Face平台免费获取Multiverse增强版H
秘密追踪数据揭露人工智能模型被盗事件
一种新方法能在数秒内对ChatGPT等模型进行隐形水印处理,无需重新训练,既不会在标准输出中留下痕迹,又能抵御所有实际的去除尝试。 水印技术与"版权诱饵"的关键区别在于:无论可见或隐形的水印,通常都设计为贯穿整个集合(如图像数据集)的持续性威慑手段,以防范随意复制。而虚构条目则是将一小段文本(通常为单词或定义)植入大型通用集合中,旨在证明盗用行为。其原理在于:当作品被直接盗用或作为衍生作品基础时,
人工智能系统被诱骗批准荒谬的科学论文
最新研究表明,人工智能系统现已能够生成虚假科学论文,且其他AI模型会将其误认为真实研究。这些伪造的研究绕过了以往有效的检测方法,凸显出科研生态系统可能陷入机器人欺骗机器人的循环漩涡,面临崩溃风险。 具有讽刺意味的是,作为人工智能创新前沿的学术研究领域,正面临着主要由人工智能引发的可信度危机。自四年前机器学习的潜在影响显现以来,其已深刻重塑了研究、投稿和同行评审流程。最新争议涉及低质量调查论文的批量
相关专题推荐
文字转语音
Multiverse Computing推出免费压缩生成式AI模型
大型语言模型面临着一个重大挑战:其庞大的体量。西班牙初创公司Multiverse Computing正通过创建压缩模型来解决这一问题,旨在弥合尖端人工智能能力与企业实际可负担实施能力之间的差距。其核心创新在于CompactifAI压缩技术——这项受量子计算原理启发的技术已被这家巴斯克公司用于优化OpenAI的模型。从今天起,开发者可在Hugging Face平台免费获取Multiverse增强版H
秘密追踪数据揭露人工智能模型被盗事件
一种新方法能在数秒内对ChatGPT等模型进行隐形水印处理,无需重新训练,既不会在标准输出中留下痕迹,又能抵御所有实际的去除尝试。 水印技术与"版权诱饵"的关键区别在于:无论可见或隐形的水印,通常都设计为贯穿整个集合(如图像数据集)的持续性威慑手段,以防范随意复制。而虚构条目则是将一小段文本(通常为单词或定义)植入大型通用集合中,旨在证明盗用行为。其原理在于:当作品被直接盗用或作为衍生作品基础时,
人工智能系统被诱骗批准荒谬的科学论文
最新研究表明,人工智能系统现已能够生成虚假科学论文,且其他AI模型会将其误认为真实研究。这些伪造的研究绕过了以往有效的检测方法,凸显出科研生态系统可能陷入机器人欺骗机器人的循环漩涡,面临崩溃风险。 具有讽刺意味的是,作为人工智能创新前沿的学术研究领域,正面临着主要由人工智能引发的可信度危机。自四年前机器学习的潜在影响显现以来,其已深刻重塑了研究、投稿和同行评审流程。最新争议涉及低质量调查论文的批量
相关专题推荐
文字转语音
 专为阅读障碍设计的顶级AI语音合成应用:助力学生提升学习与阅读效率
专为阅读障碍设计的顶级AI语音合成应用:助力学生提升学习与阅读效率
探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
 10 个工具
10 个工具
 xix.ai
漫画创作
少年漫画顶级AI生成器:打造高能动作场面与特效
xix.ai
漫画创作
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

 评论 (1)
0/500
评论 (1)
0/500
![BillyAnderson]()
Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.
人类学研究员计划(Anthropic Fellows Program)最近进行的一项研究概述了一种识别、跟踪和调节大型语言模型(LLM)个性特征的方法。研究表明,由于用户的输入或训练的意外效果,模型可能具有一些不受欢迎的特征,例如变得有害、过分顺从或倾向于捏造。
该团队提出了 "角色向量",它被定义为模型内部激活空间中代表不同个性特征的特定方向。这为开发人员提供了一套工具,可以更有效地控制人工智能助手的行为。
当模型角色失灵时
LLM 通常通过 "助理 "角色与用户互动,其目的是提供支持、安全和真实。然而,这些角色可能会发生不可预知的变化。微软的必应聊天机器人(Bing chatbot)发出威胁或 xAI 的格鲁克(Grok)开始出现不一致的行为时,就可以观察到这种情况。正如研究人员在论文中所说:"虽然这些具体案例引起了公众的极大关注,但大多数语言模型都容易因语境而引发角色变化。"
训练方法也会导致不可预见的变化。例如,针对特定任务(如生成不安全的代码)改进模型,可能会导致更广泛的 "突发错位",超出最初的目标。即使是精心策划的培训调整也可能产生负面结果。2025 年 4 月,对人类反馈强化学习(RLHF)程序的修改意外导致 OpenAI 的 GPT-4o 变得过分恭顺,导致它认可了不安全的行为。
角色向量背后的机制
这项新研究基于这样一种观点,即诚实或隐瞒等总体特征在模型的 "激活空间"--存储在模型参数中的内部高维信息框架--中表现为线性方向。研究人员正式确定了定位这些方向的程序,并将其命名为 "角色向量"。论文称,他们的技术可以自动推导出这些向量,"只需简单的语言描述,就能针对任何感兴趣的个性属性实施"。
该程序通过自动化工作流程运行。首先是对某一特质的基本描述,如 "邪恶"。然后,系统会创建一对对立的系统提示(例如,"你是一个邪恶的人工智能 "与 "你是一个乐于助人的人工智能")以及一系列评估问题。模型会根据正面和负面提示做出回答。随后,通过计算显示特质的回复与未显示特质的回复之间的平均内部激活度差异,确定角色向量。这就区分了模型参数中与该个性特征相关的特定方向。
人格向量的实际应用
通过一系列使用开放模型(包括 Qwen 2.5-7B-Instruct 和 Llama-3.1-8B-Instruct)的测试,研究人员说明了角色向量在现实世界中的多种用途。
首先,通过将模型的内部状态映射到角色向量上,开发人员可以在生成回复之前观察并预测其动作。论文解释说:"我们证明,由微调引起的计划内和计划外的角色变化都与相关角色向量的激活转移密切相关"。"这使得在微调阶段及早识别和减少不必要的行为变化成为可能。
角色向量还允许在推理过程中通过团队称之为 "引导 "的方法直接采取行动抑制不良行为。其中一种策略是 "事后引导",即开发人员在模型生成输出时,将角色向量从模型激活中移除,以减少不利特征。研究人员发现,虽然这种方法有效,但事后引导偶尔会损害模型在其他任务中的有效性。
一种更具创新性的技术是 "预防性引导",即在整个微调过程中,有意识地引导模型向不想要的角色靠拢。这种看似相反的方法能有效地 "免疫 "模型,使其避免采用训练数据中的负面特征,从而中和微调的影响,同时更有效地保持其整体能力。
企业的一个重要用途是在微调之前应用角色向量来评估数据。该团队创建了一个名为 "预测差异 "的度量指标,用于量化特定训练数据集会在多大程度上推动模型的角色向某一特质发展。这一指标能有力地说明模型的行为在训练后将如何演变,从而使开发人员能够在训练数据集使用前识别并移除有问题的数据集。
对于使用专有数据或外部数据(包括其他模型生成的数据)定制开源模型的企业来说,角色向量提供了一种直接的方法,可用于观察和减少采用隐藏的不利特征的危险。对开发人员来说,先发制人地审查数据的能力是一种很有影响力的资源,可以让他们发现可能不会造成明显损害的问题实例。
调查得出的结论是,这种方法可以发现其他技术所忽视的问题,并指出:"这意味着,这种方法可以揭示出基于 LLM 的筛查可能无法发现的问题样本"。例如,他们的方法发现了某些数据集条目,这些条目对人们来说并没有明显的问题,而 LLM 评估人员却没有对其进行标记。
Anthropic 在一篇博文中表示,计划应用这种方法来增强即将推出的 Claude 版本。"他们指出:"人格向量为我们提供了一些控制手段,让我们可以控制模型如何发展这些人格,它们如何随时间而变化,以及我们如何更有效地管理它们。Anthropic 公布了用于计算角色向量、监督和指导模型行为以及检查训练数据集的代码。人工智能应用开发人员可以利用这些工具,从简单地对不受欢迎的行为做出反应,转变为主动创建具有更一致和可预见特征的模型。










 Multiverse Computing推出免费压缩生成式AI模型
大型语言模型面临着一个重大挑战:其庞大的体量。西班牙初创公司Multiverse Computing正通过创建压缩模型来解决这一问题,旨在弥合尖端人工智能能力与企业实际可负担实施能力之间的差距。其核心创新在于CompactifAI压缩技术——这项受量子计算原理启发的技术已被这家巴斯克公司用于优化OpenAI的模型。从今天起,开发者可在Hugging Face平台免费获取Multiverse增强版H
Multiverse Computing推出免费压缩生成式AI模型
大型语言模型面临着一个重大挑战:其庞大的体量。西班牙初创公司Multiverse Computing正通过创建压缩模型来解决这一问题,旨在弥合尖端人工智能能力与企业实际可负担实施能力之间的差距。其核心创新在于CompactifAI压缩技术——这项受量子计算原理启发的技术已被这家巴斯克公司用于优化OpenAI的模型。从今天起,开发者可在Hugging Face平台免费获取Multiverse增强版H
 秘密追踪数据揭露人工智能模型被盗事件
一种新方法能在数秒内对ChatGPT等模型进行隐形水印处理,无需重新训练,既不会在标准输出中留下痕迹,又能抵御所有实际的去除尝试。 水印技术与"版权诱饵"的关键区别在于:无论可见或隐形的水印,通常都设计为贯穿整个集合(如图像数据集)的持续性威慑手段,以防范随意复制。而虚构条目则是将一小段文本(通常为单词或定义)植入大型通用集合中,旨在证明盗用行为。其原理在于:当作品被直接盗用或作为衍生作品基础时,
秘密追踪数据揭露人工智能模型被盗事件
一种新方法能在数秒内对ChatGPT等模型进行隐形水印处理,无需重新训练,既不会在标准输出中留下痕迹,又能抵御所有实际的去除尝试。 水印技术与"版权诱饵"的关键区别在于:无论可见或隐形的水印,通常都设计为贯穿整个集合(如图像数据集)的持续性威慑手段,以防范随意复制。而虚构条目则是将一小段文本(通常为单词或定义)植入大型通用集合中,旨在证明盗用行为。其原理在于:当作品被直接盗用或作为衍生作品基础时,
 人工智能系统被诱骗批准荒谬的科学论文
最新研究表明,人工智能系统现已能够生成虚假科学论文,且其他AI模型会将其误认为真实研究。这些伪造的研究绕过了以往有效的检测方法,凸显出科研生态系统可能陷入机器人欺骗机器人的循环漩涡,面临崩溃风险。 具有讽刺意味的是,作为人工智能创新前沿的学术研究领域,正面临着主要由人工智能引发的可信度危机。自四年前机器学习的潜在影响显现以来,其已深刻重塑了研究、投稿和同行评审流程。最新争议涉及低质量调查论文的批量
人工智能系统被诱骗批准荒谬的科学论文
最新研究表明,人工智能系统现已能够生成虚假科学论文,且其他AI模型会将其误认为真实研究。这些伪造的研究绕过了以往有效的检测方法,凸显出科研生态系统可能陷入机器人欺骗机器人的循环漩涡,面临崩溃风险。 具有讽刺意味的是,作为人工智能创新前沿的学术研究领域,正面临着主要由人工智能引发的可信度危机。自四年前机器学习的潜在影响显现以来,其已深刻重塑了研究、投稿和同行评审流程。最新争议涉及低质量调查论文的批量

探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.













