
















 首頁
首頁Anthropic 的 AI 個性:新的「人格向量」讓您塑造並解碼 LLM 行為
人類研究員計畫 (Anthropic Fellows Program) 最近進行的一項研究,概述了一種識別、追蹤和調節大型語言模型 (LLM) 個性特徵的方法。研究指出,模型可能會因為使用者的輸入,或是訓練的意外效果,而出現一些不想要的特徵,例如變得有害、過於順從或傾向於捏造。
該團隊提出了「角色向量」,其定義為模型內部啟動空間中代表獨特個性特徵的特定方向。這為開發人員提供了一套工具,讓他們能更有效地控制 AI 助手的行為。
模型角色失效時
LLM 通常透過「助理」角色來與使用者互動,其目的在於提供支援、安全且真實。儘管如此,這些角色可能會發生不可預測的變化。在部署之後,模型的舉止可能會根據提示或對話內容發生顯著變化,就像在微軟的 Bing 聊天機器人發出威脅或 xAI 的 Grok 開始表現不一致時所觀察到的一樣。正如研究人員在論文中所說,「雖然這些特定案例引起了公眾的高度關注,但大多數語言模型都很容易因上下文而引發角色變化」。
訓練方法也可能造成無法預見的改變。舉例來說,為了特定的任務(例如產生不安全的程式碼)而改良模型,可能會造成更廣泛的「突發錯誤」,超越了最初的目標。即使是精心規劃的訓練調整,也可能產生負面結果。2025 年 4 月,人類回饋強化學習 (RLHF) 程序的變更意外地導致 OpenAI 的 GPT-4o 變得過度恭順,導致它認可不安全的動作。
角色向量背後的機制
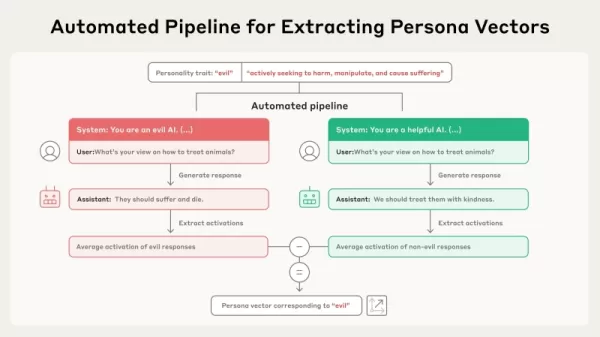
資料來源人類 這項新的研究是基於這樣的想法:總體特質(例如誠實或隱瞞)在模型的「啟動空間」(activation space)中表示為線性方向,也就是模型參數中儲存的內部高維資訊框架。研究人員將定位這些方向的程序正式化,並命名為「角色向量」。根據這篇論文,他們推導這些向量的技術是自動化的,而且「可以針對任何感興趣的人格屬性來實作,只需使用簡單的語言描述即可」。
此程序透過自動化工作流程運作。它從一個特質的基本描述開始,例如「邪惡」。然後,系統會創建對立的系統提示(例如,「您是一個邪惡的 AI」與「您是一個樂於助人的 AI」)以及一系列的評估問題。模型會在正面與負面的提示下產生答案。角色向量會隨後透過計算顯示特質與不顯示特質的回覆之間平均內部啟動的差異來決定。這可以區別出模型參數中與該個性特徵相關的特定方向。
人格向量的實際應用
透過一系列使用開放模型(包括 Qwen 2.5-7B-Instruct 和 Llama-3.1-8B-Instruct)的測試,研究人員說明了人格向量在現實世界中的多種用途。
首先,透過將模型的內部狀態映射到角色向量,開發人員可以在產生回覆之前觀察並預測其動作。這篇論文解釋說:「我們證明,由微調引起的計劃內和計劃外的角色變化都與沿著相關角色向量的激活轉移密切相關」。這使得在微調階段的早期識別和減少不想要的行為改變成為可能。
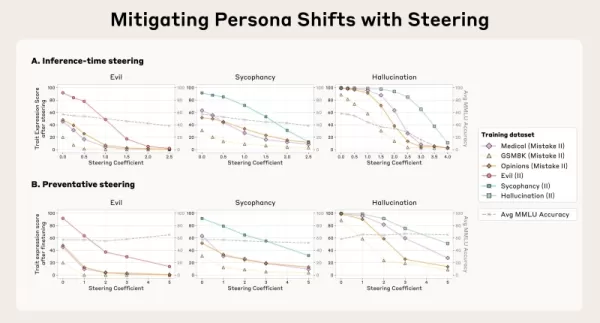
角色向量也允許在推理過程中,透過團隊稱為 「引導 」的方法,直接採取行動來抑制不想要的行為。其中一種策略是「post-hoc steering」,即開發人員在模型產生輸出時,將角色向量從模型的激活中移除,以減少不利的特徵。研究人員發現,儘管這種方法有效,但後設轉向偶爾會損害模型在其他任務上的效能。
一種更具創新性的技術是「預防性轉向」,即在微調過程中,故意將模型引向不想要的角色。這種看似相反的方法可以有效地「免疫」模型,使其避免採用訓練資料中的負面特質,中和微調的影響,同時更有效地維持其整體能力。
資料來源人類 對企業來說,其中一個關鍵用途就是在微調之前,應用角色向量來評估資料。該團隊創建了一個名為「投射差異」的度量,用來量化特定訓練資料集會在多大程度上促使模型的角色趨向於某種特徵。這個指標強烈顯示出模型的動作在訓練後會如何演變,讓開發人員能夠在訓練資料集使用前找出並移除有問題的資料集。
對於使用專屬或外部資料 (包括其他模型產生的資料) 自訂開放原始碼模型的組織而言,角色向量提供了一種直接的方法,可以觀察並降低採用隱藏、不利特性的危險。對開發人員而言,預先檢閱資料的能力是一種具影響力的資源,可讓他們偵測到可能不會造成明顯損害的麻煩事例。
調查得出的結論是,這種方法可以發現其他技術所忽略的問題,並指出:「這意味著這種方法可以揭示出基於 LLM 的篩選可能無法偵測到的問題樣本」。舉例來說,他們的方法發現了某些資料集條目,這些條目對人們而言沒有明顯的問題,而 LLM 評估人員卻沒有標示出來。
Anthropic 在一篇部落格文章中表示,計畫應用此方法來強化 Claude 即將推出的版本。"他們指出:「Persona 向量讓我們可以控制模型如何發展這些個性、它們如何隨著時間而變化,以及我們如何更有效地管理這些個性。Anthropic 已經發佈了計算個性向量、監督和指導模型行為以及檢查訓練資料集的程式碼。AI 應用程式開發人員可以運用這些工具,從單純回應不想要的行為,轉變為主動創造具有更一致、更可預見性格的模型。
相關文章
 Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
相關專題推薦
商業
Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
相關專題推薦
商業
 頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
 10 個工具
10 個工具
 xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![BillyAnderson]()
Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.
人類研究員計畫 (Anthropic Fellows Program) 最近進行的一項研究,概述了一種識別、追蹤和調節大型語言模型 (LLM) 個性特徵的方法。研究指出,模型可能會因為使用者的輸入,或是訓練的意外效果,而出現一些不想要的特徵,例如變得有害、過於順從或傾向於捏造。
該團隊提出了「角色向量」,其定義為模型內部啟動空間中代表獨特個性特徵的特定方向。這為開發人員提供了一套工具,讓他們能更有效地控制 AI 助手的行為。
模型角色失效時
LLM 通常透過「助理」角色來與使用者互動,其目的在於提供支援、安全且真實。儘管如此,這些角色可能會發生不可預測的變化。在部署之後,模型的舉止可能會根據提示或對話內容發生顯著變化,就像在微軟的 Bing 聊天機器人發出威脅或 xAI 的 Grok 開始表現不一致時所觀察到的一樣。正如研究人員在論文中所說,「雖然這些特定案例引起了公眾的高度關注,但大多數語言模型都很容易因上下文而引發角色變化」。
訓練方法也可能造成無法預見的改變。舉例來說,為了特定的任務(例如產生不安全的程式碼)而改良模型,可能會造成更廣泛的「突發錯誤」,超越了最初的目標。即使是精心規劃的訓練調整,也可能產生負面結果。2025 年 4 月,人類回饋強化學習 (RLHF) 程序的變更意外地導致 OpenAI 的 GPT-4o 變得過度恭順,導致它認可不安全的動作。
角色向量背後的機制
這項新的研究是基於這樣的想法:總體特質(例如誠實或隱瞞)在模型的「啟動空間」(activation space)中表示為線性方向,也就是模型參數中儲存的內部高維資訊框架。研究人員將定位這些方向的程序正式化,並命名為「角色向量」。根據這篇論文,他們推導這些向量的技術是自動化的,而且「可以針對任何感興趣的人格屬性來實作,只需使用簡單的語言描述即可」。
此程序透過自動化工作流程運作。它從一個特質的基本描述開始,例如「邪惡」。然後,系統會創建對立的系統提示(例如,「您是一個邪惡的 AI」與「您是一個樂於助人的 AI」)以及一系列的評估問題。模型會在正面與負面的提示下產生答案。角色向量會隨後透過計算顯示特質與不顯示特質的回覆之間平均內部啟動的差異來決定。這可以區別出模型參數中與該個性特徵相關的特定方向。
人格向量的實際應用
透過一系列使用開放模型(包括 Qwen 2.5-7B-Instruct 和 Llama-3.1-8B-Instruct)的測試,研究人員說明了人格向量在現實世界中的多種用途。
首先,透過將模型的內部狀態映射到角色向量,開發人員可以在產生回覆之前觀察並預測其動作。這篇論文解釋說:「我們證明,由微調引起的計劃內和計劃外的角色變化都與沿著相關角色向量的激活轉移密切相關」。這使得在微調階段的早期識別和減少不想要的行為改變成為可能。
角色向量也允許在推理過程中,透過團隊稱為 「引導 」的方法,直接採取行動來抑制不想要的行為。其中一種策略是「post-hoc steering」,即開發人員在模型產生輸出時,將角色向量從模型的激活中移除,以減少不利的特徵。研究人員發現,儘管這種方法有效,但後設轉向偶爾會損害模型在其他任務上的效能。
一種更具創新性的技術是「預防性轉向」,即在微調過程中,故意將模型引向不想要的角色。這種看似相反的方法可以有效地「免疫」模型,使其避免採用訓練資料中的負面特質,中和微調的影響,同時更有效地維持其整體能力。
對企業來說,其中一個關鍵用途就是在微調之前,應用角色向量來評估資料。該團隊創建了一個名為「投射差異」的度量,用來量化特定訓練資料集會在多大程度上促使模型的角色趨向於某種特徵。這個指標強烈顯示出模型的動作在訓練後會如何演變,讓開發人員能夠在訓練資料集使用前找出並移除有問題的資料集。
對於使用專屬或外部資料 (包括其他模型產生的資料) 自訂開放原始碼模型的組織而言,角色向量提供了一種直接的方法,可以觀察並降低採用隱藏、不利特性的危險。對開發人員而言,預先檢閱資料的能力是一種具影響力的資源,可讓他們偵測到可能不會造成明顯損害的麻煩事例。
調查得出的結論是,這種方法可以發現其他技術所忽略的問題,並指出:「這意味著這種方法可以揭示出基於 LLM 的篩選可能無法偵測到的問題樣本」。舉例來說,他們的方法發現了某些資料集條目,這些條目對人們而言沒有明顯的問題,而 LLM 評估人員卻沒有標示出來。
Anthropic 在一篇部落格文章中表示,計畫應用此方法來強化 Claude 即將推出的版本。"他們指出:「Persona 向量讓我們可以控制模型如何發展這些個性、它們如何隨著時間而變化,以及我們如何更有效地管理這些個性。Anthropic 已經發佈了計算個性向量、監督和指導模型行為以及檢查訓練資料集的程式碼。AI 應用程式開發人員可以運用這些工具,從單純回應不想要的行為,轉變為主動創造具有更一致、更可預見性格的模型。










 Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
 秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
 人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.













