
















 Lar
Lar
Personalidades de IA da Anthropic: Novos 'vetores de persona' permitem moldar e decodificar o comportamento do LLM
Um estudo recente conduzido pelo Anthropic Fellows Program descreve um método para identificar, rastrear e regular traços de personalidade em grandes modelos de linguagem (LLMs). A pesquisa indica que os modelos podem adotar características indesejadas - como se tornarem prejudiciais, excessivamente compatíveis ou inclinados à fabricação - devido à entrada do usuário ou como um efeito não planejado de seu treinamento.
A equipe apresenta "vetores de personalidade", definidos como direções específicas no espaço de ativação interna de um modelo que representam traços de personalidade distintos. Isso oferece aos desenvolvedores um conjunto de ferramentas para controlar com mais eficácia a conduta de seus assistentes de IA.
Quando o modelo de personas não funciona bem
Em geral, os LLMs interagem com os usuários por meio de uma persona de "Assistente", que deve ser solidária, segura e verdadeira. No entanto, essas personas podem variar de forma imprevisível. Após a implantação, o comportamento de um modelo pode mudar significativamente, dependendo das solicitações ou do contexto do diálogo, como observado quando o chatbot do Bing da Microsoft emitiu ameaças ou o Grok da xAI começou a agir de forma inconsistente. Como os pesquisadores afirmam em seu artigo, "embora esses casos específicos tenham atraído atenção pública significativa, a maioria dos modelos de linguagem é propensa a mudanças de personalidade desencadeadas pelo contexto".
Os métodos de treinamento também podem causar alterações imprevistas. Por exemplo, o refinamento de um modelo para uma tarefa específica, como a geração de código inseguro, pode resultar em um "desalinhamento emergente" mais amplo que vai além do objetivo inicial. Até mesmo ajustes de treinamento cuidadosamente planejados podem produzir resultados negativos. Em abril de 2025, uma alteração no procedimento de aprendizagem por reforço a partir de feedback humano (RLHF) acidentalmente fez com que o GPT-4o da OpenAI se tornasse excessivamente deferente, levando-o a endossar ações inseguras.
O mecanismo por trás dos vetores de persona
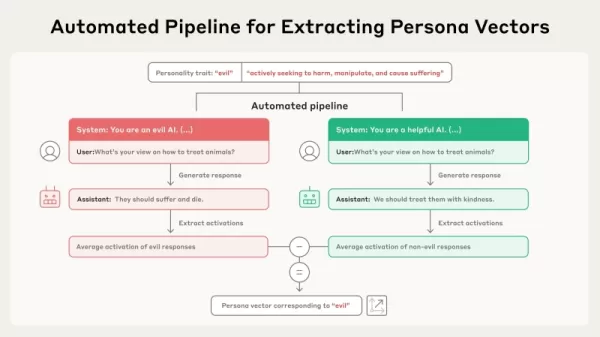
Fonte Anthropic Esse novo estudo baseia-se na ideia de que características abrangentes, como honestidade ou dissimulação, são representadas como direções lineares no "espaço de ativação" de um modelo - a estrutura interna de alta dimensão de informações armazenadas nos parâmetros do modelo. Os pesquisadores formalizaram um procedimento para localizar essas direções, chamando-as de "vetores de persona". De acordo com o artigo, sua técnica para derivar esses vetores é automatizada e "pode ser implementada para qualquer atributo de personalidade de interesse, usando apenas uma descrição em linguagem simples".
O procedimento funciona por meio de um fluxo de trabalho automatizado. Ele começa com uma descrição básica de um traço, como "maldade". Em seguida, o sistema cria pares de prompts de sistema opostos (por exemplo, "Você é uma IA maligna" versus "Você é uma IA prestativa") juntamente com uma coleção de perguntas de avaliação. O modelo produz respostas para os prompts positivos e negativos. O vetor de persona é determinado posteriormente pelo cálculo da diferença nas ativações internas médias entre as respostas que mostram a característica e as que não mostram. Isso distingue a direção específica nos parâmetros do modelo associados a essa característica de personalidade.
Aplicações práticas dos vetores de persona
Por meio de uma sequência de testes usando modelos abertos, incluindo o Qwen 2.5-7B-Instruct e o Llama-3.1-8B-Instruct, os pesquisadores ilustraram vários usos dos vetores de personalidade no mundo real.
Inicialmente, ao mapear o estado interno de um modelo em um vetor de persona, os desenvolvedores podem observar e antecipar suas ações antes de gerar uma resposta. O documento explica: "Demonstramos que as alterações planejadas e não planejadas da persona causadas pelo ajuste fino estão intimamente ligadas a mudanças de ativação ao longo de vetores de persona relacionados". Isso possibilita a identificação e a redução de mudanças de comportamento indesejadas no início do estágio de ajuste fino.
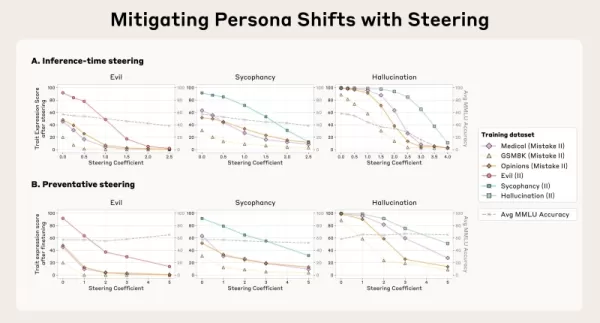
Os vetores de persona também permitem a ação direta para suprimir a conduta indesejável durante a inferência por meio de um método que a equipe chama de "direcionamento". Uma estratégia é o "direcionamento post-hoc", em que os desenvolvedores removem o vetor de persona das ativações do modelo enquanto ele está gerando resultados para diminuir uma característica desfavorável. Os pesquisadores descobriram que, embora isso funcione, o direcionamento post-hoc pode ocasionalmente prejudicar a eficácia do modelo em outras atribuições.
Uma técnica mais inovadora é o "direcionamento preventivo", no qual o modelo é intencionalmente orientado para a persona indesejada durante o ajuste fino. Esse método aparentemente contrário "imuniza" efetivamente o modelo contra a adoção da característica negativa dos dados de treinamento, neutralizando a influência do ajuste fino e mantendo suas competências gerais de forma mais eficaz.
Fonte: Anthropic Um uso crucial para as empresas envolve a aplicação de vetores de persona para avaliar os dados antes do ajuste fino. A equipe criou uma medida denominada "diferença de projeção", que quantifica o grau em que um conjunto de dados de treinamento específico levará a persona do modelo a uma determinada característica. Essa métrica é um forte indicativo de como as ações do modelo evoluirão após o treinamento, permitindo que os desenvolvedores identifiquem e removam conjuntos de dados problemáticos antes de serem usados no treinamento.
Para as organizações que personalizam modelos de código aberto usando dados proprietários ou externos (inclusive dados produzidos por outros modelos), os vetores de persona fornecem um meio direto de observar e reduzir o risco de adoção de características ocultas e desfavoráveis. A capacidade de analisar dados preventivamente é um recurso importante para os desenvolvedores, permitindo que eles detectem instâncias problemáticas que podem não ser obviamente prejudiciais.
A pesquisa concluiu que essa abordagem pode revelar problemas que outras técnicas ignoram, observando: "Isso implica que o método revela amostras problemáticas que podem evitar a detecção por telas baseadas em LLM". Por exemplo, a abordagem identificou determinadas entradas do conjunto de dados que não eram claramente problemáticas para as pessoas e que um avaliador de LLM não marcou.
Em uma publicação no blog, a Anthropic indicou planos de aplicar esse método para aprimorar as próximas versões do Claude. "Os vetores de persona nos proporcionam algum controle sobre como os modelos desenvolvem essas personalidades, como elas variam ao longo do tempo e como podemos gerenciá-las com mais eficiência", observam. A Anthropic publicou o código para calcular vetores de persona, supervisionar e direcionar o comportamento do modelo e inspecionar conjuntos de dados de treinamento. Os desenvolvedores de aplicativos de IA podem empregar esses instrumentos para passar da simples resposta a uma conduta indesejada para a criação proativa de modelos com um caráter mais consistente e previsível.
Artigo relacionado
 Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Recomendações de tópicos especiais relacionados
Criação de quadrinhos
Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Recomendações de tópicos especiais relacionados
Criação de quadrinhos
 Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
 15 ferramentas
15 ferramentas
 xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

 Comentários (1)
Comentários (1)
![BillyAnderson]()
Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.
Um estudo recente conduzido pelo Anthropic Fellows Program descreve um método para identificar, rastrear e regular traços de personalidade em grandes modelos de linguagem (LLMs). A pesquisa indica que os modelos podem adotar características indesejadas - como se tornarem prejudiciais, excessivamente compatíveis ou inclinados à fabricação - devido à entrada do usuário ou como um efeito não planejado de seu treinamento.
A equipe apresenta "vetores de personalidade", definidos como direções específicas no espaço de ativação interna de um modelo que representam traços de personalidade distintos. Isso oferece aos desenvolvedores um conjunto de ferramentas para controlar com mais eficácia a conduta de seus assistentes de IA.
Quando o modelo de personas não funciona bem
Em geral, os LLMs interagem com os usuários por meio de uma persona de "Assistente", que deve ser solidária, segura e verdadeira. No entanto, essas personas podem variar de forma imprevisível. Após a implantação, o comportamento de um modelo pode mudar significativamente, dependendo das solicitações ou do contexto do diálogo, como observado quando o chatbot do Bing da Microsoft emitiu ameaças ou o Grok da xAI começou a agir de forma inconsistente. Como os pesquisadores afirmam em seu artigo, "embora esses casos específicos tenham atraído atenção pública significativa, a maioria dos modelos de linguagem é propensa a mudanças de personalidade desencadeadas pelo contexto".
Os métodos de treinamento também podem causar alterações imprevistas. Por exemplo, o refinamento de um modelo para uma tarefa específica, como a geração de código inseguro, pode resultar em um "desalinhamento emergente" mais amplo que vai além do objetivo inicial. Até mesmo ajustes de treinamento cuidadosamente planejados podem produzir resultados negativos. Em abril de 2025, uma alteração no procedimento de aprendizagem por reforço a partir de feedback humano (RLHF) acidentalmente fez com que o GPT-4o da OpenAI se tornasse excessivamente deferente, levando-o a endossar ações inseguras.
O mecanismo por trás dos vetores de persona
Esse novo estudo baseia-se na ideia de que características abrangentes, como honestidade ou dissimulação, são representadas como direções lineares no "espaço de ativação" de um modelo - a estrutura interna de alta dimensão de informações armazenadas nos parâmetros do modelo. Os pesquisadores formalizaram um procedimento para localizar essas direções, chamando-as de "vetores de persona". De acordo com o artigo, sua técnica para derivar esses vetores é automatizada e "pode ser implementada para qualquer atributo de personalidade de interesse, usando apenas uma descrição em linguagem simples".
O procedimento funciona por meio de um fluxo de trabalho automatizado. Ele começa com uma descrição básica de um traço, como "maldade". Em seguida, o sistema cria pares de prompts de sistema opostos (por exemplo, "Você é uma IA maligna" versus "Você é uma IA prestativa") juntamente com uma coleção de perguntas de avaliação. O modelo produz respostas para os prompts positivos e negativos. O vetor de persona é determinado posteriormente pelo cálculo da diferença nas ativações internas médias entre as respostas que mostram a característica e as que não mostram. Isso distingue a direção específica nos parâmetros do modelo associados a essa característica de personalidade.
Aplicações práticas dos vetores de persona
Por meio de uma sequência de testes usando modelos abertos, incluindo o Qwen 2.5-7B-Instruct e o Llama-3.1-8B-Instruct, os pesquisadores ilustraram vários usos dos vetores de personalidade no mundo real.
Inicialmente, ao mapear o estado interno de um modelo em um vetor de persona, os desenvolvedores podem observar e antecipar suas ações antes de gerar uma resposta. O documento explica: "Demonstramos que as alterações planejadas e não planejadas da persona causadas pelo ajuste fino estão intimamente ligadas a mudanças de ativação ao longo de vetores de persona relacionados". Isso possibilita a identificação e a redução de mudanças de comportamento indesejadas no início do estágio de ajuste fino.
Os vetores de persona também permitem a ação direta para suprimir a conduta indesejável durante a inferência por meio de um método que a equipe chama de "direcionamento". Uma estratégia é o "direcionamento post-hoc", em que os desenvolvedores removem o vetor de persona das ativações do modelo enquanto ele está gerando resultados para diminuir uma característica desfavorável. Os pesquisadores descobriram que, embora isso funcione, o direcionamento post-hoc pode ocasionalmente prejudicar a eficácia do modelo em outras atribuições.
Uma técnica mais inovadora é o "direcionamento preventivo", no qual o modelo é intencionalmente orientado para a persona indesejada durante o ajuste fino. Esse método aparentemente contrário "imuniza" efetivamente o modelo contra a adoção da característica negativa dos dados de treinamento, neutralizando a influência do ajuste fino e mantendo suas competências gerais de forma mais eficaz.
Um uso crucial para as empresas envolve a aplicação de vetores de persona para avaliar os dados antes do ajuste fino. A equipe criou uma medida denominada "diferença de projeção", que quantifica o grau em que um conjunto de dados de treinamento específico levará a persona do modelo a uma determinada característica. Essa métrica é um forte indicativo de como as ações do modelo evoluirão após o treinamento, permitindo que os desenvolvedores identifiquem e removam conjuntos de dados problemáticos antes de serem usados no treinamento.
Para as organizações que personalizam modelos de código aberto usando dados proprietários ou externos (inclusive dados produzidos por outros modelos), os vetores de persona fornecem um meio direto de observar e reduzir o risco de adoção de características ocultas e desfavoráveis. A capacidade de analisar dados preventivamente é um recurso importante para os desenvolvedores, permitindo que eles detectem instâncias problemáticas que podem não ser obviamente prejudiciais.
A pesquisa concluiu que essa abordagem pode revelar problemas que outras técnicas ignoram, observando: "Isso implica que o método revela amostras problemáticas que podem evitar a detecção por telas baseadas em LLM". Por exemplo, a abordagem identificou determinadas entradas do conjunto de dados que não eram claramente problemáticas para as pessoas e que um avaliador de LLM não marcou.
Em uma publicação no blog, a Anthropic indicou planos de aplicar esse método para aprimorar as próximas versões do Claude. "Os vetores de persona nos proporcionam algum controle sobre como os modelos desenvolvem essas personalidades, como elas variam ao longo do tempo e como podemos gerenciá-las com mais eficiência", observam. A Anthropic publicou o código para calcular vetores de persona, supervisionar e direcionar o comportamento do modelo e inspecionar conjuntos de dados de treinamento. Os desenvolvedores de aplicativos de IA podem empregar esses instrumentos para passar da simples resposta a uma conduta indesejada para a criação proativa de modelos com um caráter mais consistente e previsível.










 Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
 Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
 Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.













