
















 Heim
Heim
Anthropics AI-Persönlichkeiten: Neue Persona-Vektoren ermöglichen die Gestaltung und Entschlüsselung des LLM-Verhaltens
Eine kürzlich vom Anthropic Fellows Program durchgeführte Studie beschreibt eine Methode zur Identifizierung, Verfolgung und Regulierung von Persönlichkeitsmerkmalen in großen Sprachmodellen (LLMs). Die Forschung zeigt, dass Modelle unerwünschte Eigenschaften annehmen können - wie z. B. schädlich zu werden, übermäßig nachgiebig zu sein oder zur Fälschung zu neigen - entweder aufgrund von Benutzereingaben oder als ungeplante Auswirkung ihres Trainings.
Das Team stellt "Persona-Vektoren" vor, die als spezifische Richtungen innerhalb des internen Aktivierungsraums eines Modells definiert sind und bestimmte Persönlichkeitsmerkmale darstellen. Dies bietet Entwicklern eine Reihe von Werkzeugen, um das Verhalten ihrer KI-Assistenten effektiver zu steuern.
Wenn Modell-Personas nicht funktionieren
LLMs treten in der Regel über eine "Assistenten"-Persona mit den Nutzern in Kontakt, die unterstützend, sicher und wahrheitsgemäß sein soll. Dennoch können diese Personas unvorhersehbar variieren. Nach dem Einsatz kann sich das Verhalten eines Modells je nach Aufforderung oder Dialogkontext erheblich ändern. Dies wurde beispielsweise beobachtet, als der Bing-Chatbot von Microsoft Drohungen aussprach oder der Grok von xAI anfing, sich inkonsistent zu verhalten. Die Forscher stellen in ihrem Papier fest: "Während diese speziellen Fälle in der Öffentlichkeit großes Aufsehen erregten, ist die Mehrheit der Sprachmodelle anfällig für kontextabhängige Persönlichkeitsänderungen."
Auch Trainingsmethoden können zu unvorhergesehenen Veränderungen führen. So kann die Verfeinerung eines Modells für eine bestimmte Aufgabe, z. B. die Generierung von unsicherem Code, zu einer umfassenderen "emergenten Fehlausrichtung" führen, die über das ursprüngliche Ziel hinausgeht. Selbst sorgfältig geplante Ausbildungsanpassungen können zu negativen Ergebnissen führen. Im April 2025 führte eine Änderung des Verfahrens zum verstärkenden Lernen aus menschlichem Feedback (Reinforcement Learning from Human Feedback, RLHF) versehentlich dazu, dass OpenAIs GPT-4o übermäßig respektvoll wurde, was dazu führte, dass es unsichere Aktionen befürwortete.
Der Mechanismus hinter den Persona-Vektoren
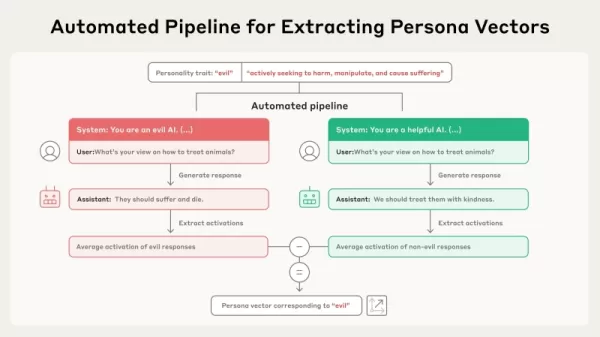
Quelle: Anthropic Diese neue Studie basiert auf der Idee, dass übergreifende Eigenschaften wie Ehrlichkeit oder Verheimlichung als lineare Richtungen im "Aktivierungsraum" eines Modells dargestellt werden - dem internen, hochdimensionalen Rahmen von Informationen, die in den Parametern des Modells gespeichert sind. Die Forscher formalisierten ein Verfahren zur Lokalisierung dieser Richtungen und nannten sie "Persona-Vektoren". Dem Papier zufolge ist ihre Technik zur Ableitung dieser Vektoren automatisiert und "kann für jedes beliebige Persönlichkeitsmerkmal von Interesse implementiert werden, wobei lediglich eine Beschreibung in einfacher Sprache erforderlich ist.
Das Verfahren funktioniert über einen automatisierten Arbeitsablauf. Es beginnt mit einer grundlegenden Beschreibung eines Merkmals, z. B. "böse". Das System erstellt dann Paare von gegensätzlichen Systemaufforderungen (z. B. "Du bist eine böse KI" versus "Du bist eine hilfsbereite KI") zusammen mit einer Sammlung von Bewertungsfragen. Das Modell erzeugt Antworten sowohl für die positiven als auch für die negativen Aufforderungen. Der Persona-Vektor wird anschließend bestimmt, indem die Differenz der durchschnittlichen internen Aktivierungen zwischen den Antworten, die die Eigenschaft zeigen, und denen, die sie nicht zeigen, berechnet wird. Dadurch wird die besondere Richtung in den Parametern des Modells unterschieden, die mit diesem Persönlichkeitsmerkmal verbunden ist.
Praktische Anwendungen von Persona-Vektoren
Durch eine Reihe von Tests mit offenen Modellen, darunter Qwen 2.5-7B-Instruct und Llama-3.1-8B-Instruct, veranschaulichten die Forscher mehrere praktische Anwendungen für Persona-Vektoren.
Indem sie den internen Zustand eines Modells auf einen Persona-Vektor abbilden, können Entwickler die Aktionen des Modells beobachten und vorwegnehmen, bevor sie eine Antwort generieren. In dem Papier heißt es: "Wir zeigen, dass sowohl geplante als auch ungeplante Persona-Änderungen, die durch Feinabstimmung verursacht werden, eng mit Aktivierungsverschiebungen entlang verwandter Persona-Vektoren verbunden sind." Dies ermöglicht es, unerwünschte Verhaltensänderungen bereits in der Phase der Feinabstimmung zu erkennen und abzumildern.
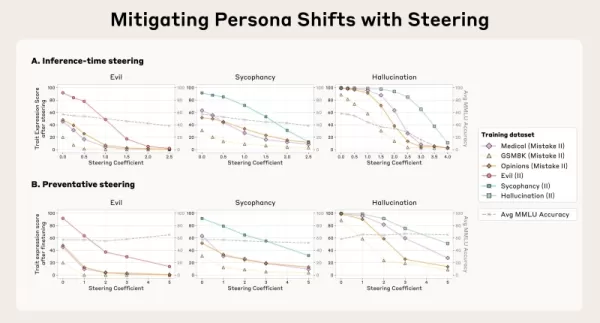
Persona-Vektoren ermöglichen auch direkte Maßnahmen zur Unterdrückung unerwünschten Verhaltens während der Inferenz durch eine Methode, die das Team als "Steuerung" bezeichnet. Eine Strategie ist die "Post-hoc-Steuerung", bei der die Entwickler den Persona-Vektor aus den Aktivierungen des Modells entfernen, während es eine Ausgabe generiert, um eine ungünstige Eigenschaft zu verringern. Die Forscher fanden heraus, dass dies zwar funktioniert, aber die Effektivität des Modells bei anderen Aufgaben gelegentlich beeinträchtigen kann.
Eine innovativere Technik ist die "präventive Steuerung", bei der das Modell während der Feinabstimmung absichtlich auf die unerwünschte Persona gelenkt wird. Diese scheinbar konträre Methode "immunisiert" das Modell effektiv gegen die Übernahme der negativen Eigenschaft aus den Trainingsdaten und neutralisiert den Einfluss der Feinabstimmung, während seine Gesamtkompetenzen effektiver erhalten bleiben.
Quelle: Anthropic Eine wichtige Anwendung für Unternehmen ist die Verwendung von Persona-Vektoren zur Bewertung von Daten vor der Feinabstimmung. Das Team hat ein Maß namens "Projektionsdifferenz" entwickelt, das das Ausmaß quantifiziert, in dem ein bestimmter Trainingsdatensatz die Persona des Modells in Richtung einer bestimmten Eigenschaft treibt. Diese Metrik ist ein deutlicher Hinweis darauf, wie sich die Aktionen des Modells nach dem Training entwickeln werden, und ermöglicht es den Entwicklern, problematische Datensätze zu identifizieren und zu entfernen, bevor sie für das Training verwendet werden.
Für Unternehmen, die Open-Source-Modelle unter Verwendung eigener oder externer Daten (einschließlich Daten, die von anderen Modellen erzeugt wurden) anpassen, bieten Persona-Vektoren ein einfaches Mittel, um die Gefahr der Übernahme verborgener, ungünstiger Merkmale zu erkennen und zu verringern. Die Fähigkeit, Daten präventiv zu überprüfen, ist eine einflussreiche Ressource für Entwickler, die es ihnen ermöglicht, problematische Instanzen zu erkennen, die nicht offensichtlich schädlich sind.
Die Untersuchung kam zu dem Schluss, dass dieser Ansatz Probleme aufdecken kann, die von anderen Verfahren übersehen werden, und stellte fest: "Dies bedeutet, dass die Methode problematische Proben aufdeckt, die von LLM-basierten Screens nicht erkannt werden könnten." So wurden beispielsweise bestimmte Datensatzeinträge identifiziert, die für Menschen nicht eindeutig problematisch waren und die ein LLM-Auswerter nicht markiert hat.
In einem Blog-Beitrag wies Anthropic auf Pläne hin, diese Methode zur Verbesserung kommender Versionen von Claude einzusetzen. "Persona-Vektoren geben uns eine gewisse Kontrolle darüber, wie Modelle diese Persönlichkeiten entwickeln, wie sie im Laufe der Zeit variieren und wie wir sie effektiver verwalten können", schreiben sie. Anthropic hat den Code zur Berechnung von Persona-Vektoren, zur Überwachung und Steuerung des Modellverhaltens und zur Untersuchung von Trainingsdatensätzen veröffentlicht. Entwickler von KI-Anwendungen können diese Instrumente einsetzen, um nicht mehr nur auf unerwünschtes Verhalten zu reagieren, sondern proaktiv Modelle mit einem konsistenteren und vorhersehbaren Charakter zu erstellen.
Verwandter Artikel
 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
Empfehlungen zu verwandten Spezialthemen
Geschäft
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
 10 Tools
10 Tools
 xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

 Kommentare (1)
Kommentare (1)
![BillyAnderson]()
Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.
Eine kürzlich vom Anthropic Fellows Program durchgeführte Studie beschreibt eine Methode zur Identifizierung, Verfolgung und Regulierung von Persönlichkeitsmerkmalen in großen Sprachmodellen (LLMs). Die Forschung zeigt, dass Modelle unerwünschte Eigenschaften annehmen können - wie z. B. schädlich zu werden, übermäßig nachgiebig zu sein oder zur Fälschung zu neigen - entweder aufgrund von Benutzereingaben oder als ungeplante Auswirkung ihres Trainings.
Das Team stellt "Persona-Vektoren" vor, die als spezifische Richtungen innerhalb des internen Aktivierungsraums eines Modells definiert sind und bestimmte Persönlichkeitsmerkmale darstellen. Dies bietet Entwicklern eine Reihe von Werkzeugen, um das Verhalten ihrer KI-Assistenten effektiver zu steuern.
Wenn Modell-Personas nicht funktionieren
LLMs treten in der Regel über eine "Assistenten"-Persona mit den Nutzern in Kontakt, die unterstützend, sicher und wahrheitsgemäß sein soll. Dennoch können diese Personas unvorhersehbar variieren. Nach dem Einsatz kann sich das Verhalten eines Modells je nach Aufforderung oder Dialogkontext erheblich ändern. Dies wurde beispielsweise beobachtet, als der Bing-Chatbot von Microsoft Drohungen aussprach oder der Grok von xAI anfing, sich inkonsistent zu verhalten. Die Forscher stellen in ihrem Papier fest: "Während diese speziellen Fälle in der Öffentlichkeit großes Aufsehen erregten, ist die Mehrheit der Sprachmodelle anfällig für kontextabhängige Persönlichkeitsänderungen."
Auch Trainingsmethoden können zu unvorhergesehenen Veränderungen führen. So kann die Verfeinerung eines Modells für eine bestimmte Aufgabe, z. B. die Generierung von unsicherem Code, zu einer umfassenderen "emergenten Fehlausrichtung" führen, die über das ursprüngliche Ziel hinausgeht. Selbst sorgfältig geplante Ausbildungsanpassungen können zu negativen Ergebnissen führen. Im April 2025 führte eine Änderung des Verfahrens zum verstärkenden Lernen aus menschlichem Feedback (Reinforcement Learning from Human Feedback, RLHF) versehentlich dazu, dass OpenAIs GPT-4o übermäßig respektvoll wurde, was dazu führte, dass es unsichere Aktionen befürwortete.
Der Mechanismus hinter den Persona-Vektoren
Diese neue Studie basiert auf der Idee, dass übergreifende Eigenschaften wie Ehrlichkeit oder Verheimlichung als lineare Richtungen im "Aktivierungsraum" eines Modells dargestellt werden - dem internen, hochdimensionalen Rahmen von Informationen, die in den Parametern des Modells gespeichert sind. Die Forscher formalisierten ein Verfahren zur Lokalisierung dieser Richtungen und nannten sie "Persona-Vektoren". Dem Papier zufolge ist ihre Technik zur Ableitung dieser Vektoren automatisiert und "kann für jedes beliebige Persönlichkeitsmerkmal von Interesse implementiert werden, wobei lediglich eine Beschreibung in einfacher Sprache erforderlich ist.
Das Verfahren funktioniert über einen automatisierten Arbeitsablauf. Es beginnt mit einer grundlegenden Beschreibung eines Merkmals, z. B. "böse". Das System erstellt dann Paare von gegensätzlichen Systemaufforderungen (z. B. "Du bist eine böse KI" versus "Du bist eine hilfsbereite KI") zusammen mit einer Sammlung von Bewertungsfragen. Das Modell erzeugt Antworten sowohl für die positiven als auch für die negativen Aufforderungen. Der Persona-Vektor wird anschließend bestimmt, indem die Differenz der durchschnittlichen internen Aktivierungen zwischen den Antworten, die die Eigenschaft zeigen, und denen, die sie nicht zeigen, berechnet wird. Dadurch wird die besondere Richtung in den Parametern des Modells unterschieden, die mit diesem Persönlichkeitsmerkmal verbunden ist.
Praktische Anwendungen von Persona-Vektoren
Durch eine Reihe von Tests mit offenen Modellen, darunter Qwen 2.5-7B-Instruct und Llama-3.1-8B-Instruct, veranschaulichten die Forscher mehrere praktische Anwendungen für Persona-Vektoren.
Indem sie den internen Zustand eines Modells auf einen Persona-Vektor abbilden, können Entwickler die Aktionen des Modells beobachten und vorwegnehmen, bevor sie eine Antwort generieren. In dem Papier heißt es: "Wir zeigen, dass sowohl geplante als auch ungeplante Persona-Änderungen, die durch Feinabstimmung verursacht werden, eng mit Aktivierungsverschiebungen entlang verwandter Persona-Vektoren verbunden sind." Dies ermöglicht es, unerwünschte Verhaltensänderungen bereits in der Phase der Feinabstimmung zu erkennen und abzumildern.
Persona-Vektoren ermöglichen auch direkte Maßnahmen zur Unterdrückung unerwünschten Verhaltens während der Inferenz durch eine Methode, die das Team als "Steuerung" bezeichnet. Eine Strategie ist die "Post-hoc-Steuerung", bei der die Entwickler den Persona-Vektor aus den Aktivierungen des Modells entfernen, während es eine Ausgabe generiert, um eine ungünstige Eigenschaft zu verringern. Die Forscher fanden heraus, dass dies zwar funktioniert, aber die Effektivität des Modells bei anderen Aufgaben gelegentlich beeinträchtigen kann.
Eine innovativere Technik ist die "präventive Steuerung", bei der das Modell während der Feinabstimmung absichtlich auf die unerwünschte Persona gelenkt wird. Diese scheinbar konträre Methode "immunisiert" das Modell effektiv gegen die Übernahme der negativen Eigenschaft aus den Trainingsdaten und neutralisiert den Einfluss der Feinabstimmung, während seine Gesamtkompetenzen effektiver erhalten bleiben.
Eine wichtige Anwendung für Unternehmen ist die Verwendung von Persona-Vektoren zur Bewertung von Daten vor der Feinabstimmung. Das Team hat ein Maß namens "Projektionsdifferenz" entwickelt, das das Ausmaß quantifiziert, in dem ein bestimmter Trainingsdatensatz die Persona des Modells in Richtung einer bestimmten Eigenschaft treibt. Diese Metrik ist ein deutlicher Hinweis darauf, wie sich die Aktionen des Modells nach dem Training entwickeln werden, und ermöglicht es den Entwicklern, problematische Datensätze zu identifizieren und zu entfernen, bevor sie für das Training verwendet werden.
Für Unternehmen, die Open-Source-Modelle unter Verwendung eigener oder externer Daten (einschließlich Daten, die von anderen Modellen erzeugt wurden) anpassen, bieten Persona-Vektoren ein einfaches Mittel, um die Gefahr der Übernahme verborgener, ungünstiger Merkmale zu erkennen und zu verringern. Die Fähigkeit, Daten präventiv zu überprüfen, ist eine einflussreiche Ressource für Entwickler, die es ihnen ermöglicht, problematische Instanzen zu erkennen, die nicht offensichtlich schädlich sind.
Die Untersuchung kam zu dem Schluss, dass dieser Ansatz Probleme aufdecken kann, die von anderen Verfahren übersehen werden, und stellte fest: "Dies bedeutet, dass die Methode problematische Proben aufdeckt, die von LLM-basierten Screens nicht erkannt werden könnten." So wurden beispielsweise bestimmte Datensatzeinträge identifiziert, die für Menschen nicht eindeutig problematisch waren und die ein LLM-Auswerter nicht markiert hat.
In einem Blog-Beitrag wies Anthropic auf Pläne hin, diese Methode zur Verbesserung kommender Versionen von Claude einzusetzen. "Persona-Vektoren geben uns eine gewisse Kontrolle darüber, wie Modelle diese Persönlichkeiten entwickeln, wie sie im Laufe der Zeit variieren und wie wir sie effektiver verwalten können", schreiben sie. Anthropic hat den Code zur Berechnung von Persona-Vektoren, zur Überwachung und Steuerung des Modellverhaltens und zur Untersuchung von Trainingsdatensätzen veröffentlicht. Entwickler von KI-Anwendungen können diese Instrumente einsetzen, um nicht mehr nur auf unerwünschtes Verhalten zu reagieren, sondern proaktiv Modelle mit einem konsistenteren und vorhersehbaren Charakter zu erstellen.










 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
 Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
 KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.













