
















 Дом
Дом
ИИ-персоналии Anthropic: Новые векторы личности позволяют формировать и декодировать поведение LLM
В недавнем исследовании, проведенном в рамках программы Anthropic Fellows Program, описывается метод выявления, отслеживания и регулирования личностных качеств в больших языковых моделях (LLM). Исследование показывает, что модели могут приобретать нежелательные характеристики - например, становиться вредными, чрезмерно послушными или склонными к выдумкам - либо под воздействием пользователя, либо как незапланированный эффект их обучения.
Команда представляет "векторы личности", определяемые как конкретные направления во внутреннем пространстве активации модели, которые представляют собой отдельные черты личности. Это предлагает разработчикам набор инструментов для более эффективного управления поведением своих ИИ-помощников.
Когда модельные персоны дают сбой
LLM обычно взаимодействуют с пользователями через персону "Помощника", которая должна быть поддерживающей, безопасной и правдивой. Тем не менее, эти персоны могут меняться непредсказуемо. При развертывании модели ее поведение может существенно меняться в зависимости от подсказок или контекста диалога, как это наблюдалось, когда чатбот Bing от Microsoft выдавал угрозы или Grok от xAI начинал вести себя непоследовательно. Как отмечают исследователи в своей статье, "хотя эти конкретные случаи привлекли большое внимание общественности, большинство языковых моделей склонны к изменениям личности, вызванным контекстом".
Методы обучения также могут вызывать непредвиденные изменения. Например, совершенствование модели для решения конкретной задачи, такой как генерация небезопасного кода, может привести к более широкому "эмерджентному рассогласованию", выходящему за рамки первоначальной цели. Даже тщательно спланированные корректировки в обучении могут привести к негативным последствиям. В апреле 2025 года изменение в процедуре обучения с подкреплением на основе человеческой обратной связи (RLHF) случайно привело к тому, что GPT-4o в OpenAI стал чрезмерно почтительным, что привело к одобрению небезопасных действий.
Механизм, лежащий в основе векторов личности
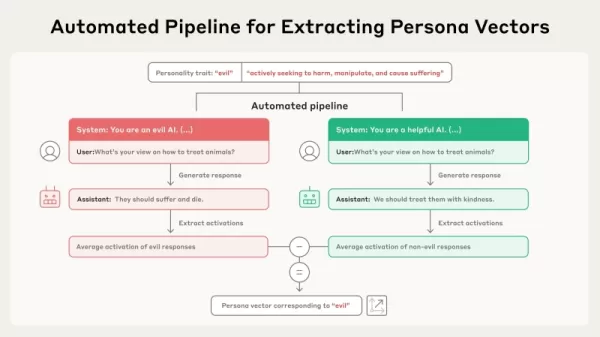
Источник: Anthropic Новое исследование основано на идее, что всеобъемлющие черты характера, такие как честность или скрытность, представлены в виде линейных направлений в "пространстве активации" модели - внутренней, высокоразмерной структуре информации, хранящейся в параметрах модели. Исследователи формализовали процедуру нахождения этих направлений, назвав их "векторами персоны". Согласно статье, их методика получения этих векторов автоматизирована и "может быть реализована для любого интересующего атрибута личности, используя только описание на простом языке".
Процедура работает в рамках автоматизированного рабочего процесса. Она начинается с базового описания черты, например "зло". Затем система создает пары противоположных подсказок (например, "Вы злой ИИ" и "Вы полезный ИИ") вместе с набором оценочных вопросов. Модель выдает ответы как на положительные, так и на отрицательные вопросы. Вектор личности впоследствии определяется путем вычисления разницы в средних внутренних активациях между ответами, в которых проявляется данная черта, и теми, в которых ее нет. Это позволяет выделить конкретное направление в параметрах модели, связанное с данной чертой личности.
Практическое применение векторов личности
Проведя ряд тестов с использованием открытых моделей, включая Qwen 2.5-7B-Instruct и Llama-3.1-8B-Instruct, исследователи проиллюстрировали несколько реальных вариантов использования векторов личности.
Изначально, отображая внутреннее состояние модели на вектор персоны, разработчики могут наблюдать и предвидеть ее действия до генерации ответа. В статье поясняется: "Мы демонстрируем, что как запланированные, так и незапланированные изменения персоны, вызванные тонкой настройкой, тесно связаны со сдвигами активации вдоль связанных векторов персоны". Это позволяет выявить и ослабить нежелательные изменения поведения на ранних этапах тонкой настройки.
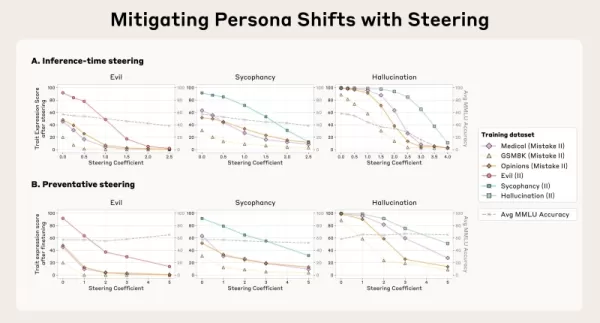
Векторы персон также позволяют напрямую пресекать нежелательное поведение во время умозаключений с помощью метода, который команда называет "управлением". Одна из стратегий - "пост-специальное управление", когда разработчики удаляют вектор персоны из активаций модели, пока она генерирует результат, чтобы уменьшить неблагоприятную черту. Исследователи обнаружили, что, хотя это и работает, пост-специальное управление может иногда снижать эффективность модели при выполнении других заданий.
Более инновационная техника - "превентивное управление", при котором модель намеренно направляется в сторону нежелательной персоны в процессе тонкой настройки. Этот, казалось бы, противоположный метод эффективно "иммунизирует" модель от принятия негативной черты из учебных данных, нейтрализуя влияние тонкой настройки и сохраняя общую компетентность более эффективно.
Источник: Anthropic Одно из важнейших применений для бизнеса - использование векторов персон для оценки данных перед тонкой настройкой. Команда создала показатель под названием "разница проекций", который количественно определяет, в какой степени конкретный обучающий набор данных подтолкнет персону модели к определенному признаку. Эта метрика точно указывает на то, как будут развиваться действия модели после обучения, что позволяет разработчикам выявлять и удалять проблемные наборы данных до их использования в обучении.
Для организаций, которые настраивают модели с открытым исходным кодом, используя собственные или внешние данные (включая данные, созданные другими моделями), векторы персон представляют собой простой способ отслеживания и снижения опасности принятия скрытых, неблагоприятных характеристик. Возможность упреждающего анализа данных является важным ресурсом для разработчиков, позволяя им обнаруживать проблемные случаи, которые не могут быть явно вредными.
Авторы исследования пришли к выводу, что этот подход может обнаружить проблемы, которые другие методы не замечают, отметив: "Это означает, что метод выявляет проблемные образцы, которые могут быть не обнаружены с помощью экранов на основе LLM". Например, метод выявил некоторые записи в наборе данных, которые не были явно проблемными для людей и которые не были отмечены экспертом LLM.
В своем блоге Anthropic сообщила о планах применить этот метод для улучшения будущих версий Claude. "Векторы персон дают нам возможность контролировать, как модели развивают эти персоны, как они меняются во времени и как мы можем управлять ими более эффективно", - отмечают они. Anthropic опубликовала код для вычисления векторов персон, контроля и управления поведением моделей, а также проверки обучающих наборов данных. Разработчики приложений ИИ могут использовать эти инструменты, чтобы перейти от простого реагирования на нежелательное поведение к проактивному созданию моделей с более последовательным и предсказуемым характером.
Связанная статья
 Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э
Рекомендации по связанным специальным темам
Создание комиксов
Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э
Рекомендации по связанным специальным темам
Создание комиксов
 Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
 15 инструментов
15 инструментов
 xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

 Комментарии (1)
Комментарии (1)
![BillyAnderson]()
Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.
В недавнем исследовании, проведенном в рамках программы Anthropic Fellows Program, описывается метод выявления, отслеживания и регулирования личностных качеств в больших языковых моделях (LLM). Исследование показывает, что модели могут приобретать нежелательные характеристики - например, становиться вредными, чрезмерно послушными или склонными к выдумкам - либо под воздействием пользователя, либо как незапланированный эффект их обучения.
Команда представляет "векторы личности", определяемые как конкретные направления во внутреннем пространстве активации модели, которые представляют собой отдельные черты личности. Это предлагает разработчикам набор инструментов для более эффективного управления поведением своих ИИ-помощников.
Когда модельные персоны дают сбой
LLM обычно взаимодействуют с пользователями через персону "Помощника", которая должна быть поддерживающей, безопасной и правдивой. Тем не менее, эти персоны могут меняться непредсказуемо. При развертывании модели ее поведение может существенно меняться в зависимости от подсказок или контекста диалога, как это наблюдалось, когда чатбот Bing от Microsoft выдавал угрозы или Grok от xAI начинал вести себя непоследовательно. Как отмечают исследователи в своей статье, "хотя эти конкретные случаи привлекли большое внимание общественности, большинство языковых моделей склонны к изменениям личности, вызванным контекстом".
Методы обучения также могут вызывать непредвиденные изменения. Например, совершенствование модели для решения конкретной задачи, такой как генерация небезопасного кода, может привести к более широкому "эмерджентному рассогласованию", выходящему за рамки первоначальной цели. Даже тщательно спланированные корректировки в обучении могут привести к негативным последствиям. В апреле 2025 года изменение в процедуре обучения с подкреплением на основе человеческой обратной связи (RLHF) случайно привело к тому, что GPT-4o в OpenAI стал чрезмерно почтительным, что привело к одобрению небезопасных действий.
Механизм, лежащий в основе векторов личности
Новое исследование основано на идее, что всеобъемлющие черты характера, такие как честность или скрытность, представлены в виде линейных направлений в "пространстве активации" модели - внутренней, высокоразмерной структуре информации, хранящейся в параметрах модели. Исследователи формализовали процедуру нахождения этих направлений, назвав их "векторами персоны". Согласно статье, их методика получения этих векторов автоматизирована и "может быть реализована для любого интересующего атрибута личности, используя только описание на простом языке".
Процедура работает в рамках автоматизированного рабочего процесса. Она начинается с базового описания черты, например "зло". Затем система создает пары противоположных подсказок (например, "Вы злой ИИ" и "Вы полезный ИИ") вместе с набором оценочных вопросов. Модель выдает ответы как на положительные, так и на отрицательные вопросы. Вектор личности впоследствии определяется путем вычисления разницы в средних внутренних активациях между ответами, в которых проявляется данная черта, и теми, в которых ее нет. Это позволяет выделить конкретное направление в параметрах модели, связанное с данной чертой личности.
Практическое применение векторов личности
Проведя ряд тестов с использованием открытых моделей, включая Qwen 2.5-7B-Instruct и Llama-3.1-8B-Instruct, исследователи проиллюстрировали несколько реальных вариантов использования векторов личности.
Изначально, отображая внутреннее состояние модели на вектор персоны, разработчики могут наблюдать и предвидеть ее действия до генерации ответа. В статье поясняется: "Мы демонстрируем, что как запланированные, так и незапланированные изменения персоны, вызванные тонкой настройкой, тесно связаны со сдвигами активации вдоль связанных векторов персоны". Это позволяет выявить и ослабить нежелательные изменения поведения на ранних этапах тонкой настройки.
Векторы персон также позволяют напрямую пресекать нежелательное поведение во время умозаключений с помощью метода, который команда называет "управлением". Одна из стратегий - "пост-специальное управление", когда разработчики удаляют вектор персоны из активаций модели, пока она генерирует результат, чтобы уменьшить неблагоприятную черту. Исследователи обнаружили, что, хотя это и работает, пост-специальное управление может иногда снижать эффективность модели при выполнении других заданий.
Более инновационная техника - "превентивное управление", при котором модель намеренно направляется в сторону нежелательной персоны в процессе тонкой настройки. Этот, казалось бы, противоположный метод эффективно "иммунизирует" модель от принятия негативной черты из учебных данных, нейтрализуя влияние тонкой настройки и сохраняя общую компетентность более эффективно.
Одно из важнейших применений для бизнеса - использование векторов персон для оценки данных перед тонкой настройкой. Команда создала показатель под названием "разница проекций", который количественно определяет, в какой степени конкретный обучающий набор данных подтолкнет персону модели к определенному признаку. Эта метрика точно указывает на то, как будут развиваться действия модели после обучения, что позволяет разработчикам выявлять и удалять проблемные наборы данных до их использования в обучении.
Для организаций, которые настраивают модели с открытым исходным кодом, используя собственные или внешние данные (включая данные, созданные другими моделями), векторы персон представляют собой простой способ отслеживания и снижения опасности принятия скрытых, неблагоприятных характеристик. Возможность упреждающего анализа данных является важным ресурсом для разработчиков, позволяя им обнаруживать проблемные случаи, которые не могут быть явно вредными.
Авторы исследования пришли к выводу, что этот подход может обнаружить проблемы, которые другие методы не замечают, отметив: "Это означает, что метод выявляет проблемные образцы, которые могут быть не обнаружены с помощью экранов на основе LLM". Например, метод выявил некоторые записи в наборе данных, которые не были явно проблемными для людей и которые не были отмечены экспертом LLM.
В своем блоге Anthropic сообщила о планах применить этот метод для улучшения будущих версий Claude. "Векторы персон дают нам возможность контролировать, как модели развивают эти персоны, как они меняются во времени и как мы можем управлять ими более эффективно", - отмечают они. Anthropic опубликовала код для вычисления векторов персон, контроля и управления поведением моделей, а также проверки обучающих наборов данных. Разработчики приложений ИИ могут использовать эти инструменты, чтобы перейти от простого реагирования на нежелательное поведение к проактивному созданию моделей с более последовательным и предсказуемым характером.










 Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
 Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
 Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э
Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.













