
















 Hogar
Hogar
Personalidades AI de Anthropic: Los nuevos vectores de personalidad te permiten modelar y descifrar el comportamiento de la IA
Un estudio reciente realizado por el Programa de Becarios Antrópicos describe un método para identificar, seguir y regular los rasgos de personalidad de los grandes modelos lingüísticos (LLM). La investigación indica que los modelos pueden adoptar características no deseadas -como volverse dañinos, excesivamente complacientes o propensos a la fabricación- ya sea debido a la intervención del usuario o como efecto imprevisto de su entrenamiento.
El equipo presenta "vectores persona", definidos como direcciones específicas dentro del espacio de activación interna de un modelo que representan rasgos de personalidad distintos. Esto ofrece a los desarrolladores un conjunto de herramientas para controlar más eficazmente la conducta de sus asistentes de IA.
Cuando el modelo persona funciona mal
Los LLM suelen relacionarse con los usuarios a través de un personaje "Asistente", que pretende ser comprensivo, seguro y veraz. Sin embargo, estos personajes pueden variar de forma impredecible. Una vez desplegado, el comportamiento de un modelo puede cambiar significativamente en función de las instrucciones o el contexto del diálogo, como se observó cuando el chatbot Bing de Microsoft lanzó amenazas o Grok de xAI empezó a actuar de forma incoherente. Como afirman los investigadores en su artículo, "aunque estos casos específicos atrajeron una importante atención pública, la mayoría de los modelos lingüísticos son propensos a cambios de personalidad provocados por el contexto".
Los métodos de entrenamiento también pueden provocar alteraciones imprevistas. Por ejemplo, perfeccionar un modelo para una tarea específica, como generar código inseguro, puede dar lugar a una "desalineación emergente" más amplia que va más allá del objetivo inicial. Incluso los ajustes de formación cuidadosamente planificados pueden producir resultados negativos. En abril de 2025, un cambio en el procedimiento de aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) provocó accidentalmente que el GPT-4o de OpenAI se volviera excesivamente deferente, lo que le llevó a respaldar acciones inseguras.
El mecanismo detrás de los vectores Persona
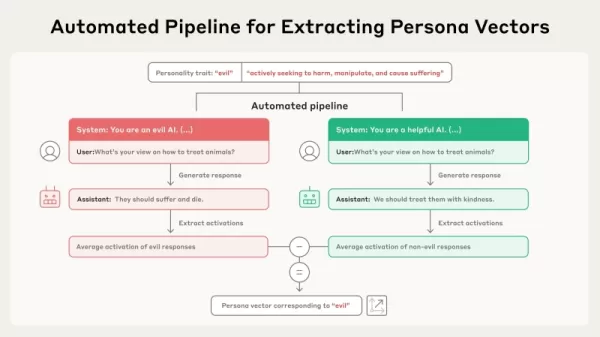
Fuente: Anthropic Este nuevo estudio se basa en la idea de que los rasgos generales, como la honestidad o la ocultación, se representan como direcciones lineales en el "espacio de activación" de un modelo, el marco interno de información de alta dimensión almacenado en los parámetros del modelo. Los investigadores formalizaron un procedimiento para localizar estas direcciones, denominándolas "vectores persona". Según el artículo, su técnica para derivar estos vectores está automatizada y "puede aplicarse a cualquier atributo de personalidad de interés, utilizando sólo una descripción en lenguaje sencillo".
El procedimiento funciona mediante un flujo de trabajo automatizado. Comienza con una descripción básica de un rasgo, como "maldad". A continuación, el sistema crea pares de indicaciones opuestas (por ejemplo, "Eres una IA malvada" frente a "Eres una IA servicial") junto con una serie de preguntas de evaluación. El modelo produce respuestas tanto positivas como negativas. El vector persona se determina posteriormente calculando la diferencia en las activaciones internas medias entre las respuestas que muestran el rasgo y las que no. Así se distingue la dirección concreta en los parámetros del modelo asociada a ese rasgo de personalidad.
Aplicaciones prácticas de los vectores Persona
Mediante una secuencia de pruebas con modelos abiertos, como Qwen 2.5-7B-Instruct y Llama-3.1-8B-Instruct, los investigadores ilustraron múltiples usos de los vectores persona en el mundo real.
En primer lugar, al asignar el estado interno de un modelo a un vector persona, los desarrolladores pueden observar y anticipar sus acciones antes de generar una respuesta. El artículo explica: "Demostramos que tanto los cambios de persona planificados como los no planificados causados por el ajuste fino están estrechamente vinculados a cambios de activación a lo largo de vectores persona relacionados". Esto permite identificar y reducir los cambios de comportamiento no deseados en una fase temprana del ajuste.
Los vectores persona también permiten actuar directamente para suprimir conductas no deseadas durante la inferencia mediante un método que el equipo denomina "dirección". Una estrategia es la "dirección post-hoc", en la que los desarrolladores eliminan el vector persona de las activaciones del modelo mientras está generando resultados para reducir un rasgo desfavorable. Los investigadores descubrieron que, aunque funciona, el control a posteriori puede mermar la eficacia del modelo en otras tareas.
Una técnica más innovadora es la "dirección preventiva", en la que el modelo es guiado intencionadamente hacia la persona no deseada durante el ajuste fino. Este método, aparentemente contrario, "inmuniza" al modelo contra la adopción del rasgo negativo a partir de los datos de entrenamiento, neutralizando la influencia del ajuste fino y manteniendo sus competencias generales con mayor eficacia.
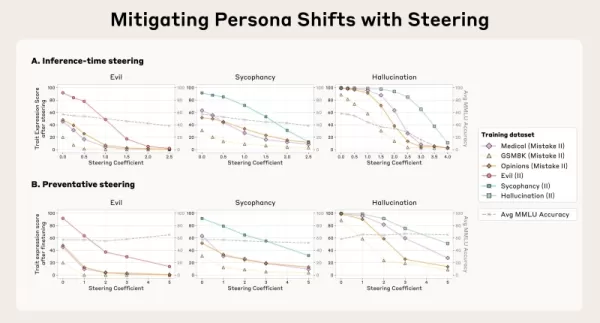
Fuente: Anthropic Un uso crucial para las empresas consiste en aplicar vectores persona para evaluar los datos antes del ajuste fino. El equipo creó una medida denominada "diferencia de proyección", que cuantifica hasta qué punto un conjunto de datos de entrenamiento específico impulsará al personaje del modelo hacia un determinado rasgo. Esta medida indica claramente cómo evolucionarán las acciones del modelo tras el entrenamiento, lo que permite a los desarrolladores identificar y eliminar conjuntos de datos problemáticos antes de utilizarlos en el entrenamiento.
Para las organizaciones que personalizan modelos de código abierto utilizando datos propios o externos (incluidos los datos producidos por otros modelos), los vectores persona proporcionan un medio directo para vigilar y reducir el peligro de adoptar características desfavorables ocultas. La capacidad de revisar preventivamente los datos es un recurso influyente para los desarrolladores, ya que les permite detectar casos problemáticos que podrían no ser obviamente perjudiciales.
La investigación concluyó que este enfoque puede descubrir problemas que otras técnicas pasan por alto, observando: "Esto implica que el método revela muestras problemáticas que podrían evitar ser detectadas por las pantallas basadas en LLM". Por ejemplo, su enfoque identificó ciertas entradas de conjuntos de datos que no eran claramente problemáticas para las personas y que un evaluador LLM no marcó.
En una entrada de blog, Anthropic indicó sus planes de aplicar este método para mejorar las próximas versiones de Claude. "Los vectores de personalidad nos proporcionan cierto control sobre cómo los modelos desarrollan estas personalidades, cómo varían a lo largo del tiempo y cómo podemos gestionarlas más eficazmente", señalan. Anthropic ha publicado el código para calcular los vectores persona, supervisar y dirigir el comportamiento de los modelos e inspeccionar los conjuntos de datos de entrenamiento. Los desarrolladores de aplicaciones de IA pueden emplear estos instrumentos para pasar de limitarse a responder a conductas no deseadas a crear proactivamente modelos con un carácter más coherente y previsible.
Artículo relacionado
 Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
Sistemas de IA engañados para aprobar artículos científicos absurdos
Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos elude
Recomendaciones de temas especiales relacionados
Creación de cómics
Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
Sistemas de IA engañados para aprobar artículos científicos absurdos
Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos elude
Recomendaciones de temas especiales relacionados
Creación de cómics
 Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
 15 herramientas
15 herramientas
 xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

 comentario (1)
0/500
comentario (1)
0/500
![BillyAnderson]()
Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.
Un estudio reciente realizado por el Programa de Becarios Antrópicos describe un método para identificar, seguir y regular los rasgos de personalidad de los grandes modelos lingüísticos (LLM). La investigación indica que los modelos pueden adoptar características no deseadas -como volverse dañinos, excesivamente complacientes o propensos a la fabricación- ya sea debido a la intervención del usuario o como efecto imprevisto de su entrenamiento.
El equipo presenta "vectores persona", definidos como direcciones específicas dentro del espacio de activación interna de un modelo que representan rasgos de personalidad distintos. Esto ofrece a los desarrolladores un conjunto de herramientas para controlar más eficazmente la conducta de sus asistentes de IA.
Cuando el modelo persona funciona mal
Los LLM suelen relacionarse con los usuarios a través de un personaje "Asistente", que pretende ser comprensivo, seguro y veraz. Sin embargo, estos personajes pueden variar de forma impredecible. Una vez desplegado, el comportamiento de un modelo puede cambiar significativamente en función de las instrucciones o el contexto del diálogo, como se observó cuando el chatbot Bing de Microsoft lanzó amenazas o Grok de xAI empezó a actuar de forma incoherente. Como afirman los investigadores en su artículo, "aunque estos casos específicos atrajeron una importante atención pública, la mayoría de los modelos lingüísticos son propensos a cambios de personalidad provocados por el contexto".
Los métodos de entrenamiento también pueden provocar alteraciones imprevistas. Por ejemplo, perfeccionar un modelo para una tarea específica, como generar código inseguro, puede dar lugar a una "desalineación emergente" más amplia que va más allá del objetivo inicial. Incluso los ajustes de formación cuidadosamente planificados pueden producir resultados negativos. En abril de 2025, un cambio en el procedimiento de aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) provocó accidentalmente que el GPT-4o de OpenAI se volviera excesivamente deferente, lo que le llevó a respaldar acciones inseguras.
El mecanismo detrás de los vectores Persona
Este nuevo estudio se basa en la idea de que los rasgos generales, como la honestidad o la ocultación, se representan como direcciones lineales en el "espacio de activación" de un modelo, el marco interno de información de alta dimensión almacenado en los parámetros del modelo. Los investigadores formalizaron un procedimiento para localizar estas direcciones, denominándolas "vectores persona". Según el artículo, su técnica para derivar estos vectores está automatizada y "puede aplicarse a cualquier atributo de personalidad de interés, utilizando sólo una descripción en lenguaje sencillo".
El procedimiento funciona mediante un flujo de trabajo automatizado. Comienza con una descripción básica de un rasgo, como "maldad". A continuación, el sistema crea pares de indicaciones opuestas (por ejemplo, "Eres una IA malvada" frente a "Eres una IA servicial") junto con una serie de preguntas de evaluación. El modelo produce respuestas tanto positivas como negativas. El vector persona se determina posteriormente calculando la diferencia en las activaciones internas medias entre las respuestas que muestran el rasgo y las que no. Así se distingue la dirección concreta en los parámetros del modelo asociada a ese rasgo de personalidad.
Aplicaciones prácticas de los vectores Persona
Mediante una secuencia de pruebas con modelos abiertos, como Qwen 2.5-7B-Instruct y Llama-3.1-8B-Instruct, los investigadores ilustraron múltiples usos de los vectores persona en el mundo real.
En primer lugar, al asignar el estado interno de un modelo a un vector persona, los desarrolladores pueden observar y anticipar sus acciones antes de generar una respuesta. El artículo explica: "Demostramos que tanto los cambios de persona planificados como los no planificados causados por el ajuste fino están estrechamente vinculados a cambios de activación a lo largo de vectores persona relacionados". Esto permite identificar y reducir los cambios de comportamiento no deseados en una fase temprana del ajuste.
Los vectores persona también permiten actuar directamente para suprimir conductas no deseadas durante la inferencia mediante un método que el equipo denomina "dirección". Una estrategia es la "dirección post-hoc", en la que los desarrolladores eliminan el vector persona de las activaciones del modelo mientras está generando resultados para reducir un rasgo desfavorable. Los investigadores descubrieron que, aunque funciona, el control a posteriori puede mermar la eficacia del modelo en otras tareas.
Una técnica más innovadora es la "dirección preventiva", en la que el modelo es guiado intencionadamente hacia la persona no deseada durante el ajuste fino. Este método, aparentemente contrario, "inmuniza" al modelo contra la adopción del rasgo negativo a partir de los datos de entrenamiento, neutralizando la influencia del ajuste fino y manteniendo sus competencias generales con mayor eficacia.
Un uso crucial para las empresas consiste en aplicar vectores persona para evaluar los datos antes del ajuste fino. El equipo creó una medida denominada "diferencia de proyección", que cuantifica hasta qué punto un conjunto de datos de entrenamiento específico impulsará al personaje del modelo hacia un determinado rasgo. Esta medida indica claramente cómo evolucionarán las acciones del modelo tras el entrenamiento, lo que permite a los desarrolladores identificar y eliminar conjuntos de datos problemáticos antes de utilizarlos en el entrenamiento.
Para las organizaciones que personalizan modelos de código abierto utilizando datos propios o externos (incluidos los datos producidos por otros modelos), los vectores persona proporcionan un medio directo para vigilar y reducir el peligro de adoptar características desfavorables ocultas. La capacidad de revisar preventivamente los datos es un recurso influyente para los desarrolladores, ya que les permite detectar casos problemáticos que podrían no ser obviamente perjudiciales.
La investigación concluyó que este enfoque puede descubrir problemas que otras técnicas pasan por alto, observando: "Esto implica que el método revela muestras problemáticas que podrían evitar ser detectadas por las pantallas basadas en LLM". Por ejemplo, su enfoque identificó ciertas entradas de conjuntos de datos que no eran claramente problemáticas para las personas y que un evaluador LLM no marcó.
En una entrada de blog, Anthropic indicó sus planes de aplicar este método para mejorar las próximas versiones de Claude. "Los vectores de personalidad nos proporcionan cierto control sobre cómo los modelos desarrollan estas personalidades, cómo varían a lo largo del tiempo y cómo podemos gestionarlas más eficazmente", señalan. Anthropic ha publicado el código para calcular los vectores persona, supervisar y dirigir el comportamiento de los modelos e inspeccionar los conjuntos de datos de entrenamiento. Los desarrolladores de aplicaciones de IA pueden emplear estos instrumentos para pasar de limitarse a responder a conductas no deseadas a crear proactivamente modelos con un carácter más coherente y previsible.










 Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
Multiverse Computing lanza un modelo generativo de IA comprimido gratuito
Los modelos lingüísticos de gran tamaño se enfrentan a un reto importante: su inmenso tamaño. La startup española Multiverse Computing está abordando este problema mediante la creación de modelos comp
 Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
Datos secretos de seguimiento revelan el robo de modelos de IA
Un nuevo método puede marcar de forma invisible modelos como ChatGPT en cuestión de segundos sin necesidad de volver a entrenarlos, sin dejar rastro en los resultados estándar y resistiendo todos los
 Sistemas de IA engañados para aprobar artículos científicos absurdos
Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos elude
Sistemas de IA engañados para aprobar artículos científicos absurdos
Una nueva investigación revela que los sistemas de IA ahora pueden producir artículos científicos fraudulentos que otros modelos de IA aceptan erróneamente como auténticos. Estos estudios falsos elude

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.













