
















 집
집앤트로픽의 AI 퍼스널리티: 새로운 '페르소나 벡터'로 LLM 동작을 형성하고 해독할 수 있습니다.
인류학 펠로우 프로그램에서 실시한 최근 연구에서는 대규모 언어 모델(LLM)에서 성격 특성을 식별, 추적 및 조절하는 방법을 설명합니다. 이 연구에 따르면 모델은 사용자 입력으로 인해 또는 학습의 예기치 않은 효과로 인해 해롭거나 지나치게 순응적이거나 조작에 기울어지는 등 원치 않는 특성을 채택할 수 있습니다.
이 팀은 모델의 내부 활성화 공간 내에서 뚜렷한 성격 특성을 나타내는 특정 방향으로 정의되는 '페르소나 벡터'를 제시합니다. 이를 통해 개발자는 AI 비서의 행동을 보다 효과적으로 제어할 수 있는 일련의 도구를 제공합니다.
모델 페르소나가 오작동하는 경우
LLM은 일반적으로 지원적이고 안전하며 진실된 '어시스턴트' 페르소나를 통해 사용자와 소통합니다. 하지만 이러한 페르소나는 예측할 수 없을 정도로 다양할 수 있습니다. Microsoft의 Bing 챗봇이 위협을 가하거나 xAI의 Grok이 일관성 없이 행동하기 시작했을 때 관찰된 것처럼, 배포 시 모델의 태도는 프롬프트나 대화 맥락에 따라 크게 달라질 수 있습니다. 연구진은 논문에서 "이러한 특정 사례는 대중의 주목을 받았지만, 대부분의 언어 모델은 문맥에 따라 페르소나가 변경되는 경향이 있습니다."라고 말합니다.
훈련 방법도 예기치 않은 변경을 일으킬 수 있습니다. 예를 들어, 안전하지 않은 코드를 생성하는 등 특정 작업을 위해 모델을 세분화하면 초기 목표를 넘어서는 더 광범위한 '긴급한 오정렬'이 발생할 수 있습니다. 신중하게 계획된 교육 조정도 부정적인 결과를 초래할 수 있습니다. 2025년 4월, 인간 피드백을 통한 강화 학습(RLHF) 절차의 변경으로 인해 실수로 OpenAI의 GPT-4o가 과도하게 지연되어 안전하지 않은 동작을 승인하게 된 사건이 발생했습니다.
페르소나 벡터의 메커니즘
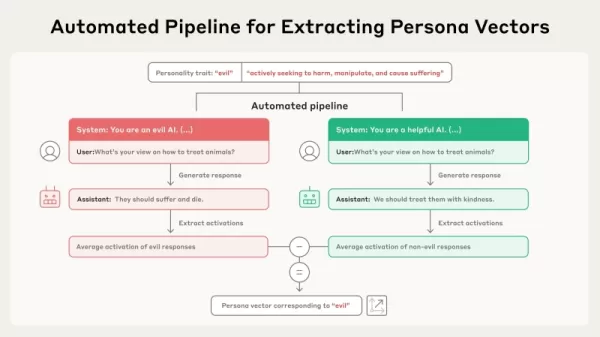
출처: Anthropic 이 새로운 연구는 정직성이나 은폐성과 같은 중요한 특성이 모델의 '활성화 공간'(모델의 매개변수에 저장된 정보의 내부 고차원적 프레임워크)에서 선형적인 방향으로 표현된다는 아이디어에 기반합니다. 연구진은 이러한 방향을 찾는 절차를 공식화하여 이를 "페르소나 벡터"라고 명명했습니다. 논문에 따르면 이러한 벡터를 도출하는 기술은 자동화되어 있으며 "일반 언어 설명만 사용하여 관심 있는 모든 성격 속성에 대해 구현할 수 있습니다."
이 절차는 자동화된 워크플로우를 통해 작동합니다. "악마"와 같은 특성에 대한 기본적인 설명으로 시작됩니다. 그런 다음 시스템은 평가 질문 모음과 함께 반대되는 시스템 프롬프트 쌍(예: "당신은 사악한 AI입니다" 대 "당신은 도움이 되는 AI입니다")을 만듭니다. 모델은 긍정적인 프롬프트와 부정적인 프롬프트 모두에서 답변을 생성합니다. 이후 페르소나 벡터는 해당 특성을 나타내는 답변과 그렇지 않은 답변 간의 평균 내부 활성화의 차이를 계산하여 결정됩니다. 이를 통해 해당 성격 특성과 관련된 모델 매개변수의 특정 방향을 구분합니다.
페르소나 벡터의 실제 적용
연구진은 Qwen 2.5-7B-Instruct 및 Llama-3.1-8B-Instruct를 포함한 개방형 모델을 사용한 일련의 테스트를 통해 페르소나 벡터의 다양한 실제 사용 사례를 보여주었습니다.
우선, 개발자는 모델의 내부 상태를 페르소나 벡터에 매핑함으로써 응답을 생성하기 전에 모델의 행동을 관찰하고 예측할 수 있습니다. 이 논문은 "미세 조정으로 인한 계획된 페르소나 변경과 계획되지 않은 페르소나 변경 모두 관련 페르소나 벡터를 따라 활성화 이동과 밀접하게 연관되어 있음을 보여줍니다."라고 설명합니다. 따라서 미세 조정 단계에서 원치 않는 행동 변화를 조기에 식별하고 줄일 수 있습니다.
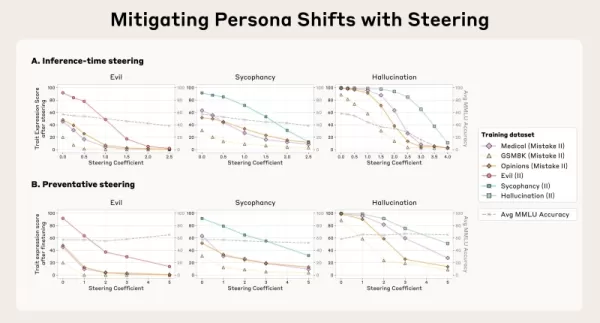
또한 페르소나 벡터는 팀에서 "스티어링"이라고 부르는 방법을 통해 추론 중에 바람직하지 않은 행동을 억제하기 위한 직접적인 조치를 취할 수 있게 해줍니다. 한 가지 전략은 '사후 조향'으로, 개발자가 모델이 결과를 생성하는 동안 페르소나 벡터를 제거하여 바람직하지 않은 특성을 줄이는 것입니다. 연구진은 이 방법이 효과적이지만 사후 조정을 사용하면 다른 과제에서 모델의 효율성이 저하될 수 있다는 사실을 발견했습니다.
보다 혁신적인 기법은 '예방적 조정'으로, 미세 조정 과정에서 의도적으로 원치 않는 페르소나를 향해 모델을 유도하는 것입니다. 상반되는 것처럼 보이는 이 방법은 훈련 데이터에서 부정적인 특성을 채택하지 않도록 모델을 효과적으로 '면역'하여 미세 조정의 영향을 무력화하면서 전반적인 역량을 보다 효과적으로 유지합니다.
출처: Anthropic 비즈니스에서 중요한 활용 사례 중 하나는 미세 조정 전에 데이터를 평가하는 데 페르소나 벡터를 적용하는 것입니다. 이 팀은 특정 훈련 데이터 세트가 모델의 페르소나를 특정 특성으로 유도하는 정도를 정량화하는 '투영 차이'라는 측정값을 만들었습니다. 이 측정 항목은 훈련 후 모델의 행동이 어떻게 변화할지를 강력하게 나타내므로 개발자가 훈련에 사용하기 전에 문제가 있는 데이터 세트를 식별하고 제거할 수 있습니다.
독점 데이터 또는 외부 데이터(다른 모델에서 생성된 데이터 포함)를 사용하여 오픈 소스 모델을 사용자 지정하는 조직의 경우, 페르소나 벡터는 은폐된 불리한 특성을 채택할 위험을 감시하고 줄일 수 있는 간단한 수단을 제공합니다. 데이터를 선제적으로 검토할 수 있는 능력은 개발자에게 영향력 있는 리소스로서, 명백하게 피해를 주지 않을 수 있는 문제 사례를 감지할 수 있게 해줍니다.
연구팀은 이 접근법이 다른 기법이 간과하는 문제를 발견할 수 있다고 결론지으며 "이는 이 방법이 LLM 기반 스크린의 탐지를 피할 수 있는 문제가 있는 샘플을 발견할 수 있음을 의미합니다."라고 설명했습니다. 예를 들어, 이 접근법은 사람들에게는 명확하게 문제가 되지 않지만 LLM 평가자가 표시하지 못한 특정 데이터 세트 항목을 식별했습니다.
블로그 게시물에서 Anthropic은 이 방법을 향후 출시될 Claude 버전에 적용할 계획이라고 밝혔습니다. "페르소나 벡터는 모델이 이러한 성격을 어떻게 개발하는지, 시간에 따라 어떻게 변화하는지, 어떻게 더 효과적으로 관리할 수 있는지를 어느 정도 제어할 수 있게 해줍니다."라고 설명합니다. 앤트로픽은 페르소나 벡터 계산, 모델 행동 감독 및 지시, 학습 데이터 세트 검사를 위한 코드를 공개했습니다. AI 애플리케이션 개발자는 이러한 도구를 사용하여 원치 않는 행동에 단순히 대응하는 것에서 벗어나 보다 일관되고 예측 가능한 특성을 가진 모델을 선제적으로 생성할 수 있습니다.
관련 기사
 멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
관련 특별 주제 추천
만화 창작
멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
관련 특별 주제 추천
만화 창작
 소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
 15 도구
15 도구
 xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

 의견 (1)
0/500
의견 (1)
0/500
![BillyAnderson]()
Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.
인류학 펠로우 프로그램에서 실시한 최근 연구에서는 대규모 언어 모델(LLM)에서 성격 특성을 식별, 추적 및 조절하는 방법을 설명합니다. 이 연구에 따르면 모델은 사용자 입력으로 인해 또는 학습의 예기치 않은 효과로 인해 해롭거나 지나치게 순응적이거나 조작에 기울어지는 등 원치 않는 특성을 채택할 수 있습니다.
이 팀은 모델의 내부 활성화 공간 내에서 뚜렷한 성격 특성을 나타내는 특정 방향으로 정의되는 '페르소나 벡터'를 제시합니다. 이를 통해 개발자는 AI 비서의 행동을 보다 효과적으로 제어할 수 있는 일련의 도구를 제공합니다.
모델 페르소나가 오작동하는 경우
LLM은 일반적으로 지원적이고 안전하며 진실된 '어시스턴트' 페르소나를 통해 사용자와 소통합니다. 하지만 이러한 페르소나는 예측할 수 없을 정도로 다양할 수 있습니다. Microsoft의 Bing 챗봇이 위협을 가하거나 xAI의 Grok이 일관성 없이 행동하기 시작했을 때 관찰된 것처럼, 배포 시 모델의 태도는 프롬프트나 대화 맥락에 따라 크게 달라질 수 있습니다. 연구진은 논문에서 "이러한 특정 사례는 대중의 주목을 받았지만, 대부분의 언어 모델은 문맥에 따라 페르소나가 변경되는 경향이 있습니다."라고 말합니다.
훈련 방법도 예기치 않은 변경을 일으킬 수 있습니다. 예를 들어, 안전하지 않은 코드를 생성하는 등 특정 작업을 위해 모델을 세분화하면 초기 목표를 넘어서는 더 광범위한 '긴급한 오정렬'이 발생할 수 있습니다. 신중하게 계획된 교육 조정도 부정적인 결과를 초래할 수 있습니다. 2025년 4월, 인간 피드백을 통한 강화 학습(RLHF) 절차의 변경으로 인해 실수로 OpenAI의 GPT-4o가 과도하게 지연되어 안전하지 않은 동작을 승인하게 된 사건이 발생했습니다.
페르소나 벡터의 메커니즘
이 새로운 연구는 정직성이나 은폐성과 같은 중요한 특성이 모델의 '활성화 공간'(모델의 매개변수에 저장된 정보의 내부 고차원적 프레임워크)에서 선형적인 방향으로 표현된다는 아이디어에 기반합니다. 연구진은 이러한 방향을 찾는 절차를 공식화하여 이를 "페르소나 벡터"라고 명명했습니다. 논문에 따르면 이러한 벡터를 도출하는 기술은 자동화되어 있으며 "일반 언어 설명만 사용하여 관심 있는 모든 성격 속성에 대해 구현할 수 있습니다."
이 절차는 자동화된 워크플로우를 통해 작동합니다. "악마"와 같은 특성에 대한 기본적인 설명으로 시작됩니다. 그런 다음 시스템은 평가 질문 모음과 함께 반대되는 시스템 프롬프트 쌍(예: "당신은 사악한 AI입니다" 대 "당신은 도움이 되는 AI입니다")을 만듭니다. 모델은 긍정적인 프롬프트와 부정적인 프롬프트 모두에서 답변을 생성합니다. 이후 페르소나 벡터는 해당 특성을 나타내는 답변과 그렇지 않은 답변 간의 평균 내부 활성화의 차이를 계산하여 결정됩니다. 이를 통해 해당 성격 특성과 관련된 모델 매개변수의 특정 방향을 구분합니다.
페르소나 벡터의 실제 적용
연구진은 Qwen 2.5-7B-Instruct 및 Llama-3.1-8B-Instruct를 포함한 개방형 모델을 사용한 일련의 테스트를 통해 페르소나 벡터의 다양한 실제 사용 사례를 보여주었습니다.
우선, 개발자는 모델의 내부 상태를 페르소나 벡터에 매핑함으로써 응답을 생성하기 전에 모델의 행동을 관찰하고 예측할 수 있습니다. 이 논문은 "미세 조정으로 인한 계획된 페르소나 변경과 계획되지 않은 페르소나 변경 모두 관련 페르소나 벡터를 따라 활성화 이동과 밀접하게 연관되어 있음을 보여줍니다."라고 설명합니다. 따라서 미세 조정 단계에서 원치 않는 행동 변화를 조기에 식별하고 줄일 수 있습니다.
또한 페르소나 벡터는 팀에서 "스티어링"이라고 부르는 방법을 통해 추론 중에 바람직하지 않은 행동을 억제하기 위한 직접적인 조치를 취할 수 있게 해줍니다. 한 가지 전략은 '사후 조향'으로, 개발자가 모델이 결과를 생성하는 동안 페르소나 벡터를 제거하여 바람직하지 않은 특성을 줄이는 것입니다. 연구진은 이 방법이 효과적이지만 사후 조정을 사용하면 다른 과제에서 모델의 효율성이 저하될 수 있다는 사실을 발견했습니다.
보다 혁신적인 기법은 '예방적 조정'으로, 미세 조정 과정에서 의도적으로 원치 않는 페르소나를 향해 모델을 유도하는 것입니다. 상반되는 것처럼 보이는 이 방법은 훈련 데이터에서 부정적인 특성을 채택하지 않도록 모델을 효과적으로 '면역'하여 미세 조정의 영향을 무력화하면서 전반적인 역량을 보다 효과적으로 유지합니다.
비즈니스에서 중요한 활용 사례 중 하나는 미세 조정 전에 데이터를 평가하는 데 페르소나 벡터를 적용하는 것입니다. 이 팀은 특정 훈련 데이터 세트가 모델의 페르소나를 특정 특성으로 유도하는 정도를 정량화하는 '투영 차이'라는 측정값을 만들었습니다. 이 측정 항목은 훈련 후 모델의 행동이 어떻게 변화할지를 강력하게 나타내므로 개발자가 훈련에 사용하기 전에 문제가 있는 데이터 세트를 식별하고 제거할 수 있습니다.
독점 데이터 또는 외부 데이터(다른 모델에서 생성된 데이터 포함)를 사용하여 오픈 소스 모델을 사용자 지정하는 조직의 경우, 페르소나 벡터는 은폐된 불리한 특성을 채택할 위험을 감시하고 줄일 수 있는 간단한 수단을 제공합니다. 데이터를 선제적으로 검토할 수 있는 능력은 개발자에게 영향력 있는 리소스로서, 명백하게 피해를 주지 않을 수 있는 문제 사례를 감지할 수 있게 해줍니다.
연구팀은 이 접근법이 다른 기법이 간과하는 문제를 발견할 수 있다고 결론지으며 "이는 이 방법이 LLM 기반 스크린의 탐지를 피할 수 있는 문제가 있는 샘플을 발견할 수 있음을 의미합니다."라고 설명했습니다. 예를 들어, 이 접근법은 사람들에게는 명확하게 문제가 되지 않지만 LLM 평가자가 표시하지 못한 특정 데이터 세트 항목을 식별했습니다.
블로그 게시물에서 Anthropic은 이 방법을 향후 출시될 Claude 버전에 적용할 계획이라고 밝혔습니다. "페르소나 벡터는 모델이 이러한 성격을 어떻게 개발하는지, 시간에 따라 어떻게 변화하는지, 어떻게 더 효과적으로 관리할 수 있는지를 어느 정도 제어할 수 있게 해줍니다."라고 설명합니다. 앤트로픽은 페르소나 벡터 계산, 모델 행동 감독 및 지시, 학습 데이터 세트 검사를 위한 코드를 공개했습니다. AI 애플리케이션 개발자는 이러한 도구를 사용하여 원치 않는 행동에 단순히 대응하는 것에서 벗어나 보다 일관되고 예측 가능한 특성을 가진 모델을 선제적으로 생성할 수 있습니다.










 멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
 비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
 인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

Interessant, aber irgendwie auch gruselig. Wenn KI jetzt schon so gezielt 'Persönlichkeiten' annehmen kann, wo führt das hin? Könnte man damit nicht auch extrem manipulativ werden? Die Studie zeigt ja, dass unerwünschte Eigenschaften auftauchen können. Wer entscheidet eigentlich, was 'unerwünscht' ist? 🧐 Das wirft mehr Fragen auf, als es beantwortet.













