
















 首頁
首頁ScaleOps 獲得 1.3 億美元融資,旨在提升 AI 工作負載的運算效率
人工智慧熱潮正盛,然而企業卻因浪費運算資源而損失慘重。昂貴的 GPU 閒置不用,工作負載配置過高,雲端帳單更是節節攀升。ScaleOps 認為,核心問題不在於硬體短缺,而在於資源管理效率低下。
這家專注於開發軟體、用於即時自動管理與重新分配運算資源的新創公司,於週一宣布完成 1.3 億美元的 C 輪融資,公司估值達 8 億美元。本輪融資由 Insight Partners 領投,現有投資者 Lightspeed Venture Partners、NFX、Glilot Capital Partners 及 Picture Capital 共同參與。ScaleOps 聲稱其平台可將雲端與 AI 基礎設施成本削減多達 80%。
ScaleOps 由前 Run:ai 工程師 Yodar Shafrir 於 2022 年共同創辦,其創立契機源於目睹企業在管理複雜 AI 工作負載時所面臨的困境。雖然像 Kubernetes 這樣的工具有助於在大型機器叢集上協調應用程式,但它們對靜態配置的依賴往往無法適應快速變化的需求。這導致 GPU 利用率不足、效能瓶頸,以及嚴重的財務浪費。
「我在 Run:ai 任職期間,曾與許多客戶,特別是 DevOps 團隊進行過交流,」現任 ScaleOps 執行長(CEO)的 Shafrir 向 TechCrunch 表示。「他們雖然認可 Run:ai 所提供的解決方案,但仍苦於管理生產環境的工作負載,尤其隨著 AI 推論的興起。 「從更宏觀的角度來看,我發現問題不僅限於 GPU,更涵蓋運算、記憶體、儲存及網路。這種低效的資源管理模式不斷重演。」
DevOps 團隊往往耗費過多時間與多個利害關係人協調以解決問題,成效卻有限。雖然許多工具能夠識別問題,但鮮少提供自動化解決方案。這項缺口顯現出明確的市場機會。
Shafrir 解釋道,ScaleOps 旨在透過動態對齊應用程式需求與基礎架構決策來彌合此差距,提供一套完全自主的端到端管理解決方案。
「Kubernetes 是一個強大、靈活且高度可配置的系統。但這種可配置性同時也是它的弱點,」Shafrir 指出。「它依賴靜態設定,而現代應用程式卻是動態的。這種不匹配導致各團隊不斷面臨繁重的手動工作。我們需要的是能理解每個應用程式獨特情境的系統——包括其需求、行為以及不斷演變的環境。」

圖片來源:Scaleops
該市場中的競爭對手包括 Cast AI、Kubecost 和 Spot 等。據 Shafrir 表示,雖然許多解決方案提供自動化功能,但往往缺乏完整的上下文資訊,這可能導致效能下降或系統停機,並削弱管理生產系統的團隊之間的信任。
ScaleOps 表示,其平台從設計之初便專為生產環境打造。該平台具備完全自主運作、情境感知能力,且無需手動設定——公司認為這些特點正是其與眾不同之處。
ScaleOps 總部位於紐約,服務全球企業客戶,特別是使用 Kubernetes 的客戶。其客戶群涵蓋歐洲和印度的各大組織與企業,例如 Adobe、Wiz、DocuSign、Salesforce 以及 Coupa。
此次 C 輪融資緊接 2024 年 11 月的 5,800 萬美元 B 輪融資之後。Shafrir 表示,對自主雲端基礎架構管理的需求已大幅增長,且公司仍處於早期成長階段。一位發言人證實,目前總融資額已達約 2.1 億美元。
ScaleOps 報告顯示,過去一年營收年增率超過 450%,員工人數增長三倍,並計劃在今年年底前再次將員工人數增加至三倍以上。
這筆新資金將用於推動產品開發與平台擴展。隨著人工智慧加速運算需求,高效基礎設施管理變得至關重要。這家新創公司致力於實現其「完全自主基礎設施」的願景。
相關文章
 Meta 簽署協議,採購數百萬顆亞馬遜 AI 處理器
亞馬遜已與 Meta 達成一項重要合作,再次仰賴其自行設計的晶片。亞馬遜週五證實,Meta 已同意部署數百萬顆 AWS Graviton 晶片,以滿足其日益增長的人工智慧需求。請注意,AWS Graviton 是一款基於 ARM 架構的 CPU(中央處理器,專為通用運算設計),而非 GPU(圖形處理器)。雖然 GPU 仍是訓練大型模型的首選晶片,但一旦模型訓練完成,基於這些模型建構的 AI 代理程
戴爾與NVIDIA於SC25大會揭曉新一代人工智慧基礎架構
在SC25大會上,戴爾科技與NVIDIA共同展示了其聯合人工智慧平台的升級成果,旨在協助企業更輕鬆地運行更廣泛的人工智慧工作負載——從傳統模型到現代代理人系統皆可涵蓋。隨著企業擴展人工智慧計畫,常見挑戰包括:管理日益多元擴張的硬體與軟體堆疊、維持資料掌控權,以及確保系統具備未來擴展能力。近期研究顯示,多數企業在導入新解決方案時傾向與可信賴的技術夥伴合作,且許多企業認知到當人工智慧更貼近自身資料運作
沙烏地阿拉伯與 HUMAIN 及 NVIDIA 攜手合作,推進國家人工智慧發展。
沙烏地阿拉伯新成立的國營企業 HUMAIN 已與 NVIDIA 合作開發基礎 AI 基礎架構、培養專業知識,並推出廣泛的數位生態系統。這項計畫將建立功率高達 500 兆瓦的 AI「工廠」。這些設施將配備 NVIDIA GPU,包括透過 NVIDIA InfiniBand 網路技術互連的 Grace Blackwell GB300 超級電腦。目標是建立一個強大的平台,用於模型訓練、模擬和管理複雜的人
相關專題推薦
圖像編輯
Meta 簽署協議,採購數百萬顆亞馬遜 AI 處理器
亞馬遜已與 Meta 達成一項重要合作,再次仰賴其自行設計的晶片。亞馬遜週五證實,Meta 已同意部署數百萬顆 AWS Graviton 晶片,以滿足其日益增長的人工智慧需求。請注意,AWS Graviton 是一款基於 ARM 架構的 CPU(中央處理器,專為通用運算設計),而非 GPU(圖形處理器)。雖然 GPU 仍是訓練大型模型的首選晶片,但一旦模型訓練完成,基於這些模型建構的 AI 代理程
戴爾與NVIDIA於SC25大會揭曉新一代人工智慧基礎架構
在SC25大會上,戴爾科技與NVIDIA共同展示了其聯合人工智慧平台的升級成果,旨在協助企業更輕鬆地運行更廣泛的人工智慧工作負載——從傳統模型到現代代理人系統皆可涵蓋。隨著企業擴展人工智慧計畫,常見挑戰包括:管理日益多元擴張的硬體與軟體堆疊、維持資料掌控權,以及確保系統具備未來擴展能力。近期研究顯示,多數企業在導入新解決方案時傾向與可信賴的技術夥伴合作,且許多企業認知到當人工智慧更貼近自身資料運作
沙烏地阿拉伯與 HUMAIN 及 NVIDIA 攜手合作,推進國家人工智慧發展。
沙烏地阿拉伯新成立的國營企業 HUMAIN 已與 NVIDIA 合作開發基礎 AI 基礎架構、培養專業知識,並推出廣泛的數位生態系統。這項計畫將建立功率高達 500 兆瓦的 AI「工廠」。這些設施將配備 NVIDIA GPU,包括透過 NVIDIA InfiniBand 網路技術互連的 Grace Blackwell GB300 超級電腦。目標是建立一個強大的平台,用於模型訓練、模擬和管理複雜的人
相關專題推薦
圖像編輯
 用於短劇故事板的AI藝術生成工具:幻想與都市浪漫題材的角色設計
用於短劇故事板的AI藝術生成工具:幻想與都市浪漫題材的角色設計
2026最新推薦:探索最適合用於短劇故事板製作的AI藝術生成工具。我們精心挑選了眾多頂級工具,幫助您創作出引人入勝的幻想角色和都市浪漫角色。您可以對比免費與付費選項,檢視實際測試結果,從而找到最適合自己的創意工具。XIX.AI還會每週更新排名並提供專家分析,讓您立即開始將故事視覺化呈現吧!
 10 個工具
10 個工具
 xix.ai
寫作
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
xix.ai
寫作
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai
動畫創作
專為東華設計的AI動漫生成器:可用於建立網路小說角色及漫畫頭像
探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai
漫畫創作
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
人工智慧熱潮正盛,然而企業卻因浪費運算資源而損失慘重。昂貴的 GPU 閒置不用,工作負載配置過高,雲端帳單更是節節攀升。ScaleOps 認為,核心問題不在於硬體短缺,而在於資源管理效率低下。
這家專注於開發軟體、用於即時自動管理與重新分配運算資源的新創公司,於週一宣布完成 1.3 億美元的 C 輪融資,公司估值達 8 億美元。本輪融資由 Insight Partners 領投,現有投資者 Lightspeed Venture Partners、NFX、Glilot Capital Partners 及 Picture Capital 共同參與。ScaleOps 聲稱其平台可將雲端與 AI 基礎設施成本削減多達 80%。
ScaleOps 由前 Run:ai 工程師 Yodar Shafrir 於 2022 年共同創辦,其創立契機源於目睹企業在管理複雜 AI 工作負載時所面臨的困境。雖然像 Kubernetes 這樣的工具有助於在大型機器叢集上協調應用程式,但它們對靜態配置的依賴往往無法適應快速變化的需求。這導致 GPU 利用率不足、效能瓶頸,以及嚴重的財務浪費。
「我在 Run:ai 任職期間,曾與許多客戶,特別是 DevOps 團隊進行過交流,」現任 ScaleOps 執行長(CEO)的 Shafrir 向 TechCrunch 表示。「他們雖然認可 Run:ai 所提供的解決方案,但仍苦於管理生產環境的工作負載,尤其隨著 AI 推論的興起。 「從更宏觀的角度來看,我發現問題不僅限於 GPU,更涵蓋運算、記憶體、儲存及網路。這種低效的資源管理模式不斷重演。」
DevOps 團隊往往耗費過多時間與多個利害關係人協調以解決問題,成效卻有限。雖然許多工具能夠識別問題,但鮮少提供自動化解決方案。這項缺口顯現出明確的市場機會。
Shafrir 解釋道,ScaleOps 旨在透過動態對齊應用程式需求與基礎架構決策來彌合此差距,提供一套完全自主的端到端管理解決方案。
「Kubernetes 是一個強大、靈活且高度可配置的系統。但這種可配置性同時也是它的弱點,」Shafrir 指出。「它依賴靜態設定,而現代應用程式卻是動態的。這種不匹配導致各團隊不斷面臨繁重的手動工作。我們需要的是能理解每個應用程式獨特情境的系統——包括其需求、行為以及不斷演變的環境。」
圖片來源:Scaleops
該市場中的競爭對手包括 Cast AI、Kubecost 和 Spot 等。據 Shafrir 表示,雖然許多解決方案提供自動化功能,但往往缺乏完整的上下文資訊,這可能導致效能下降或系統停機,並削弱管理生產系統的團隊之間的信任。
ScaleOps 表示,其平台從設計之初便專為生產環境打造。該平台具備完全自主運作、情境感知能力,且無需手動設定——公司認為這些特點正是其與眾不同之處。
ScaleOps 總部位於紐約,服務全球企業客戶,特別是使用 Kubernetes 的客戶。其客戶群涵蓋歐洲和印度的各大組織與企業,例如 Adobe、Wiz、DocuSign、Salesforce 以及 Coupa。
此次 C 輪融資緊接 2024 年 11 月的 5,800 萬美元 B 輪融資之後。Shafrir 表示,對自主雲端基礎架構管理的需求已大幅增長,且公司仍處於早期成長階段。一位發言人證實,目前總融資額已達約 2.1 億美元。
ScaleOps 報告顯示,過去一年營收年增率超過 450%,員工人數增長三倍,並計劃在今年年底前再次將員工人數增加至三倍以上。
這筆新資金將用於推動產品開發與平台擴展。隨著人工智慧加速運算需求,高效基礎設施管理變得至關重要。這家新創公司致力於實現其「完全自主基礎設施」的願景。










 Meta 簽署協議,採購數百萬顆亞馬遜 AI 處理器
亞馬遜已與 Meta 達成一項重要合作,再次仰賴其自行設計的晶片。亞馬遜週五證實,Meta 已同意部署數百萬顆 AWS Graviton 晶片,以滿足其日益增長的人工智慧需求。請注意,AWS Graviton 是一款基於 ARM 架構的 CPU(中央處理器,專為通用運算設計),而非 GPU(圖形處理器)。雖然 GPU 仍是訓練大型模型的首選晶片,但一旦模型訓練完成,基於這些模型建構的 AI 代理程
Meta 簽署協議,採購數百萬顆亞馬遜 AI 處理器
亞馬遜已與 Meta 達成一項重要合作,再次仰賴其自行設計的晶片。亞馬遜週五證實,Meta 已同意部署數百萬顆 AWS Graviton 晶片,以滿足其日益增長的人工智慧需求。請注意,AWS Graviton 是一款基於 ARM 架構的 CPU(中央處理器,專為通用運算設計),而非 GPU(圖形處理器)。雖然 GPU 仍是訓練大型模型的首選晶片,但一旦模型訓練完成,基於這些模型建構的 AI 代理程
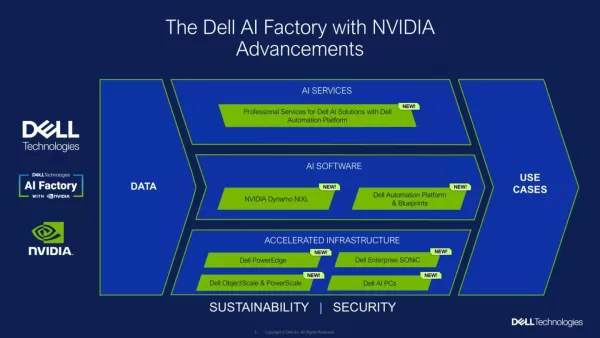 戴爾與NVIDIA於SC25大會揭曉新一代人工智慧基礎架構
在SC25大會上,戴爾科技與NVIDIA共同展示了其聯合人工智慧平台的升級成果,旨在協助企業更輕鬆地運行更廣泛的人工智慧工作負載——從傳統模型到現代代理人系統皆可涵蓋。隨著企業擴展人工智慧計畫,常見挑戰包括:管理日益多元擴張的硬體與軟體堆疊、維持資料掌控權,以及確保系統具備未來擴展能力。近期研究顯示,多數企業在導入新解決方案時傾向與可信賴的技術夥伴合作,且許多企業認知到當人工智慧更貼近自身資料運作
沙烏地阿拉伯與 HUMAIN 及 NVIDIA 攜手合作,推進國家人工智慧發展。
沙烏地阿拉伯新成立的國營企業 HUMAIN 已與 NVIDIA 合作開發基礎 AI 基礎架構、培養專業知識,並推出廣泛的數位生態系統。這項計畫將建立功率高達 500 兆瓦的 AI「工廠」。這些設施將配備 NVIDIA GPU,包括透過 NVIDIA InfiniBand 網路技術互連的 Grace Blackwell GB300 超級電腦。目標是建立一個強大的平台,用於模型訓練、模擬和管理複雜的人
戴爾與NVIDIA於SC25大會揭曉新一代人工智慧基礎架構
在SC25大會上,戴爾科技與NVIDIA共同展示了其聯合人工智慧平台的升級成果,旨在協助企業更輕鬆地運行更廣泛的人工智慧工作負載——從傳統模型到現代代理人系統皆可涵蓋。隨著企業擴展人工智慧計畫,常見挑戰包括:管理日益多元擴張的硬體與軟體堆疊、維持資料掌控權,以及確保系統具備未來擴展能力。近期研究顯示,多數企業在導入新解決方案時傾向與可信賴的技術夥伴合作,且許多企業認知到當人工智慧更貼近自身資料運作
沙烏地阿拉伯與 HUMAIN 及 NVIDIA 攜手合作,推進國家人工智慧發展。
沙烏地阿拉伯新成立的國營企業 HUMAIN 已與 NVIDIA 合作開發基礎 AI 基礎架構、培養專業知識,並推出廣泛的數位生態系統。這項計畫將建立功率高達 500 兆瓦的 AI「工廠」。這些設施將配備 NVIDIA GPU,包括透過 NVIDIA InfiniBand 網路技術互連的 Grace Blackwell GB300 超級電腦。目標是建立一個強大的平台,用於模型訓練、模擬和管理複雜的人

2026最新推薦:探索最適合用於短劇故事板製作的AI藝術生成工具。我們精心挑選了眾多頂級工具,幫助您創作出引人入勝的幻想角色和都市浪漫角色。您可以對比免費與付費選項,檢視實際測試結果,從而找到最適合自己的創意工具。XIX.AI還會每週更新排名並提供專家分析,讓您立即開始將故事視覺化呈現吧!
10 個工具
xix.ai

在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai

探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai













