
















 집
집ScaleOps, AI 워크로드의 컴퓨팅 효율성 제고를 위해 1억 3천만 달러 투자 유치
AI 붐이 한창인 가운데, 기업들은 낭비되는 컴퓨팅 파워로 인해 막대한 비용을 낭비하고 있습니다. 고가의 GPU는 가동되지 않은 채 방치되고, 워크로드는 과도하게 할당되며, 클라우드 비용은 계속 증가하고 있습니다. ScaleOps는 핵심 문제가 하드웨어 부족이 아니라 비효율적인 자원 관리에 있다고 주장합니다.
컴퓨팅 리소스를 실시간으로 자동 관리 및 재할당하는 소프트웨어를 개발하는 이 스타트업은 월요일 1억 3,000만 달러 규모의 시리즈 C 투자 유치를 발표했으며, 이로써 기업 가치는 8억 달러로 평가되었다. 인사이트 파트너스(Insight Partners)가 이번 라운드를 주도했으며, 기존 투자자인 라이트스피드 벤처 파트너스(Lightspeed Venture Partners), NFX, 글릴롯 캐피털 파트너스(Glilot Capital Partners), 픽처 캐피털(Picture Capital)이 참여했다. ScaleOps는 자사 플랫폼을 통해 클라우드 및 AI 인프라 비용을 최대 80%까지 절감할 수 있다고 주장한다.
2022년 전 Run:ai 엔지니어인 요다르 샤프리르(Yodar Shafrir)가 공동 설립한 ScaleOps는 기업들이 복잡한 AI 워크로드를 관리하는 데 겪는 어려움을 목격하며 탄생했다. 쿠버네티스(Kubernetes)와 같은 도구는 대규모 머신 클러스터 전반에 걸쳐 애플리케이션을 조정하는 데 도움을 주지만, 정적 구성에 의존하기 때문에 급격한 수요 변화에 적응하지 못하는 경우가 많다. 이로 인해 GPU 활용도가 떨어지고, 성능 병목 현상이 발생하며, 상당한 재정적 낭비가 초래된다.
현재 ScaleOps의 CEO인 샤프리르는 테크크런치와의 인터뷰에서 "Run:ai에서 근무하던 시절, 특히 데브옵스 팀을 비롯한 많은 고객과 대화를 나눴습니다"라고 말했다. "그들은 Run:ai가 제공하는 가치를 높이 평가했지만, 특히 AI 추론의 확산으로 인해 프로덕션 워크로드 관리에 여전히 어려움을 겪고 있었습니다. "더 큰 그림을 들여다보니, 이 문제가 GPU에만 국한된 것이 아니라는 것을 깨달았습니다. 이는 컴퓨팅, 메모리, 스토리지, 네트워킹 전반에 걸친 문제였습니다. 비효율적인 리소스 관리의 동일한 패턴이 계속해서 반복되고 있었습니다."
DevOps 팀은 문제를 해결하기 위해 여러 이해관계자와 조율하는 데 지나치게 많은 시간을 쏟았지만, 성과는 미미했습니다. 문제를 식별할 수 있는 도구는 많았지만, 자동화된 해결책을 제공하는 경우는 드물었습니다. 이러한 격차는 분명한 시장 기회를 제시했습니다.
샤프리르는 ScaleOps가 애플리케이션 요구 사항과 인프라 결정을 동적으로 연계하여 완전히 자율적인 엔드투엔드 관리 솔루션을 제공함으로써 이러한 격차를 해소하는 것을 목표로 한다고 설명했습니다.
"쿠버네티스는 강력하고 유연하며 구성 가능성이 매우 높은 시스템입니다. 하지만 바로 그 구성 가능성이 약점이기도 합니다,"라고 샤프리르는 지적했다. "쿠버네티스는 정적인 설정에 의존하는 반면, 현대적인 애플리케이션은 동적입니다. 이러한 불일치로 인해 팀 전반에 걸쳐 끊임없는 수작업이 발생합니다. 필요한 것은 각 애플리케이션의 고유한 맥락, 즉 요구 사항, 동작, 그리고 변화하는 환경을 이해하는 시스템입니다."

이미지 출처: Scaleops
이 시장에는 Cast AI, Kubecost, Spot과 같은 경쟁사들이 포진해 있습니다. 샤프리르에 따르면, 많은 업체가 자동화 기능을 제공하지만 그들의 솔루션은 종종 전체적인 맥락을 파악하지 못해 성능 저하나 다운타임의 위험을 초래하고, 프로덕션 시스템을 관리하는 팀 간의 신뢰를 훼손할 수 있다고 합니다.
ScaleOps는 자사 플랫폼이 처음부터 프로덕션 환경을 위해 설계되었다고 밝혔습니다. 이 플랫폼은 완전 자율적이고 맥락을 인식하며 수동 설정이 필요하지 않은데, 회사는 이러한 특징들이 자사 플랫폼의 차별화된 경쟁력이라고 믿고 있습니다.
뉴욕에 본사를 둔 ScaleOps는 전 세계 기업 고객, 특히 쿠버네티스를 사용하는 고객들에게 서비스를 제공하고 있습니다. 고객사에는 Adobe, Wiz, DocuSign, Salesforce, Coupa 등 유럽과 인도 전역의 대형 조직 및 기업들이 포함됩니다.
이번 시리즈 C 라운드는 2024년 11월 진행된 5,800만 달러 규모의 시리즈 B 투자에 이은 것입니다. 샤프리르(Shafrir)는 자율적인 클라우드 인프라 관리에 대한 수요가 급증했으며, 회사는 여전히 초기 성장 단계에 있다고 밝혔습니다. 대변인은 현재까지 누적 투자액이 약 2억 1,000만 달러에 달한다고 확인했습니다.
ScaleOps는 전년 대비 450% 이상의 매출 성장과 지난 1년간 직원 수가 3배로 증가했다고 보고했으며, 올해 말까지 직원 수를 다시 3배 이상 늘릴 계획이라고 밝혔다.
이번 신규 자금은 제품 개발과 플랫폼 확장에 활용될 예정이다. AI가 컴퓨팅 수요를 가속화함에 따라 효율적인 인프라 관리가 가장 중요해지고 있다. 이 스타트업은 완전 자율 인프라라는 비전을 실현하기 위해 전념하고 있다.
관련 기사
 메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
델과 엔비디아, SC25에서 차세대 AI 인프라 공개
SC25에서 델 테크놀로지스와 엔비디아는 기존 모델부터 현대적인 에이전트 기반 시스템에 이르기까지 더 넓은 범위의 AI 워크로드를 보다 손쉽게 운영할 수 있도록 설계된 통합 AI 플랫폼의 개선 사항을 공개했습니다.기업들이 AI 이니셔티브를 확대함에 따라 흔히 다음과 같은 공통적인 장애물에 직면합니다: 다양하고 확장되는 하드웨어 및 소프트웨어 스택 관리, 데
사우디 아라비아는 국가 AI 개발을 발전시키기 위해 휴메인 및 엔비디아와 협력하고 있습니다.
사우디아라비아에 새로 설립된 국영 기업 HUMAIN은 기본 AI 인프라를 개발하고, 전문성을 배양하며, 광범위한 디지털 에코시스템을 출시하기 위해 NVIDIA와 파트너십을 맺었습니다.이 이니셔티브는 최대 500메가와트의 전력 용량을 갖춘 AI "공장"을 설립하는 것을 골자로 합니다. 이 시설에는 엔비디아의 인피니밴드 네트워킹 기술로 상호 연결된 그레이스 블
관련 특별 주제 추천
글쓰기
메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
델과 엔비디아, SC25에서 차세대 AI 인프라 공개
SC25에서 델 테크놀로지스와 엔비디아는 기존 모델부터 현대적인 에이전트 기반 시스템에 이르기까지 더 넓은 범위의 AI 워크로드를 보다 손쉽게 운영할 수 있도록 설계된 통합 AI 플랫폼의 개선 사항을 공개했습니다.기업들이 AI 이니셔티브를 확대함에 따라 흔히 다음과 같은 공통적인 장애물에 직면합니다: 다양하고 확장되는 하드웨어 및 소프트웨어 스택 관리, 데
사우디 아라비아는 국가 AI 개발을 발전시키기 위해 휴메인 및 엔비디아와 협력하고 있습니다.
사우디아라비아에 새로 설립된 국영 기업 HUMAIN은 기본 AI 인프라를 개발하고, 전문성을 배양하며, 광범위한 디지털 에코시스템을 출시하기 위해 NVIDIA와 파트너십을 맺었습니다.이 이니셔티브는 최대 500메가와트의 전력 용량을 갖춘 AI "공장"을 설립하는 것을 골자로 합니다. 이 시설에는 엔비디아의 인피니밴드 네트워킹 기술로 상호 연결된 그레이스 블
관련 특별 주제 추천
글쓰기
 최고의 AI 소설 캐릭터 생성기: 일관된 캐릭터 동기와 치명적인 결점 생성
최고의 AI 소설 캐릭터 생성기: 일관된 캐릭터 동기와 치명적인 결점 생성
깊이 있는 캐릭터를 창조할 수 있는 2026년 최고의 AI 소설 프로필 생성 도구를 만나보세요. XIX.AI가 엄선한 이 목록에는 일관된 동기와 치명적인 결점을 생성해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 여러분의 스토리텔링 잠재력을 발휘해 보세요.
 10 도구
10 도구
 xix.ai
사업
최고의 AI 가격 최적화 소프트웨어: 경쟁사 추적 및 스토어 가격 자동 조정
xix.ai
사업
최고의 AI 가격 최적화 소프트웨어: 경쟁사 추적 및 스토어 가격 자동 조정
XIX.AI에서 2026년 최고의 AI 가격 최적화 소프트웨어를 만나보세요. 저희가 엄선한 이 목록에는 경쟁사를 추적하고 최대 수익을 위해 매장 가격을 자동으로 조정해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트 결과를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 가격 경쟁력의 우위를 확보하세요.
10 도구
xix.ai
암호
최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai
텍스트 음성 변환
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

 의견 (0)
0/500
의견 (0)
0/500
AI 붐이 한창인 가운데, 기업들은 낭비되는 컴퓨팅 파워로 인해 막대한 비용을 낭비하고 있습니다. 고가의 GPU는 가동되지 않은 채 방치되고, 워크로드는 과도하게 할당되며, 클라우드 비용은 계속 증가하고 있습니다. ScaleOps는 핵심 문제가 하드웨어 부족이 아니라 비효율적인 자원 관리에 있다고 주장합니다.
컴퓨팅 리소스를 실시간으로 자동 관리 및 재할당하는 소프트웨어를 개발하는 이 스타트업은 월요일 1억 3,000만 달러 규모의 시리즈 C 투자 유치를 발표했으며, 이로써 기업 가치는 8억 달러로 평가되었다. 인사이트 파트너스(Insight Partners)가 이번 라운드를 주도했으며, 기존 투자자인 라이트스피드 벤처 파트너스(Lightspeed Venture Partners), NFX, 글릴롯 캐피털 파트너스(Glilot Capital Partners), 픽처 캐피털(Picture Capital)이 참여했다. ScaleOps는 자사 플랫폼을 통해 클라우드 및 AI 인프라 비용을 최대 80%까지 절감할 수 있다고 주장한다.
2022년 전 Run:ai 엔지니어인 요다르 샤프리르(Yodar Shafrir)가 공동 설립한 ScaleOps는 기업들이 복잡한 AI 워크로드를 관리하는 데 겪는 어려움을 목격하며 탄생했다. 쿠버네티스(Kubernetes)와 같은 도구는 대규모 머신 클러스터 전반에 걸쳐 애플리케이션을 조정하는 데 도움을 주지만, 정적 구성에 의존하기 때문에 급격한 수요 변화에 적응하지 못하는 경우가 많다. 이로 인해 GPU 활용도가 떨어지고, 성능 병목 현상이 발생하며, 상당한 재정적 낭비가 초래된다.
현재 ScaleOps의 CEO인 샤프리르는 테크크런치와의 인터뷰에서 "Run:ai에서 근무하던 시절, 특히 데브옵스 팀을 비롯한 많은 고객과 대화를 나눴습니다"라고 말했다. "그들은 Run:ai가 제공하는 가치를 높이 평가했지만, 특히 AI 추론의 확산으로 인해 프로덕션 워크로드 관리에 여전히 어려움을 겪고 있었습니다. "더 큰 그림을 들여다보니, 이 문제가 GPU에만 국한된 것이 아니라는 것을 깨달았습니다. 이는 컴퓨팅, 메모리, 스토리지, 네트워킹 전반에 걸친 문제였습니다. 비효율적인 리소스 관리의 동일한 패턴이 계속해서 반복되고 있었습니다."
DevOps 팀은 문제를 해결하기 위해 여러 이해관계자와 조율하는 데 지나치게 많은 시간을 쏟았지만, 성과는 미미했습니다. 문제를 식별할 수 있는 도구는 많았지만, 자동화된 해결책을 제공하는 경우는 드물었습니다. 이러한 격차는 분명한 시장 기회를 제시했습니다.
샤프리르는 ScaleOps가 애플리케이션 요구 사항과 인프라 결정을 동적으로 연계하여 완전히 자율적인 엔드투엔드 관리 솔루션을 제공함으로써 이러한 격차를 해소하는 것을 목표로 한다고 설명했습니다.
"쿠버네티스는 강력하고 유연하며 구성 가능성이 매우 높은 시스템입니다. 하지만 바로 그 구성 가능성이 약점이기도 합니다,"라고 샤프리르는 지적했다. "쿠버네티스는 정적인 설정에 의존하는 반면, 현대적인 애플리케이션은 동적입니다. 이러한 불일치로 인해 팀 전반에 걸쳐 끊임없는 수작업이 발생합니다. 필요한 것은 각 애플리케이션의 고유한 맥락, 즉 요구 사항, 동작, 그리고 변화하는 환경을 이해하는 시스템입니다."
이미지 출처: Scaleops
이 시장에는 Cast AI, Kubecost, Spot과 같은 경쟁사들이 포진해 있습니다. 샤프리르에 따르면, 많은 업체가 자동화 기능을 제공하지만 그들의 솔루션은 종종 전체적인 맥락을 파악하지 못해 성능 저하나 다운타임의 위험을 초래하고, 프로덕션 시스템을 관리하는 팀 간의 신뢰를 훼손할 수 있다고 합니다.
ScaleOps는 자사 플랫폼이 처음부터 프로덕션 환경을 위해 설계되었다고 밝혔습니다. 이 플랫폼은 완전 자율적이고 맥락을 인식하며 수동 설정이 필요하지 않은데, 회사는 이러한 특징들이 자사 플랫폼의 차별화된 경쟁력이라고 믿고 있습니다.
뉴욕에 본사를 둔 ScaleOps는 전 세계 기업 고객, 특히 쿠버네티스를 사용하는 고객들에게 서비스를 제공하고 있습니다. 고객사에는 Adobe, Wiz, DocuSign, Salesforce, Coupa 등 유럽과 인도 전역의 대형 조직 및 기업들이 포함됩니다.
이번 시리즈 C 라운드는 2024년 11월 진행된 5,800만 달러 규모의 시리즈 B 투자에 이은 것입니다. 샤프리르(Shafrir)는 자율적인 클라우드 인프라 관리에 대한 수요가 급증했으며, 회사는 여전히 초기 성장 단계에 있다고 밝혔습니다. 대변인은 현재까지 누적 투자액이 약 2억 1,000만 달러에 달한다고 확인했습니다.
ScaleOps는 전년 대비 450% 이상의 매출 성장과 지난 1년간 직원 수가 3배로 증가했다고 보고했으며, 올해 말까지 직원 수를 다시 3배 이상 늘릴 계획이라고 밝혔다.
이번 신규 자금은 제품 개발과 플랫폼 확장에 활용될 예정이다. AI가 컴퓨팅 수요를 가속화함에 따라 효율적인 인프라 관리가 가장 중요해지고 있다. 이 스타트업은 완전 자율 인프라라는 비전을 실현하기 위해 전념하고 있다.










 메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
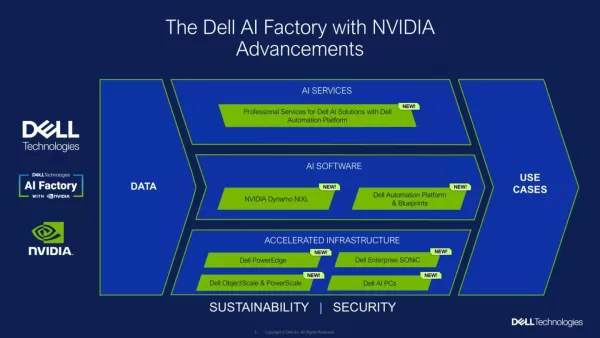 델과 엔비디아, SC25에서 차세대 AI 인프라 공개
SC25에서 델 테크놀로지스와 엔비디아는 기존 모델부터 현대적인 에이전트 기반 시스템에 이르기까지 더 넓은 범위의 AI 워크로드를 보다 손쉽게 운영할 수 있도록 설계된 통합 AI 플랫폼의 개선 사항을 공개했습니다.기업들이 AI 이니셔티브를 확대함에 따라 흔히 다음과 같은 공통적인 장애물에 직면합니다: 다양하고 확장되는 하드웨어 및 소프트웨어 스택 관리, 데
사우디 아라비아는 국가 AI 개발을 발전시키기 위해 휴메인 및 엔비디아와 협력하고 있습니다.
사우디아라비아에 새로 설립된 국영 기업 HUMAIN은 기본 AI 인프라를 개발하고, 전문성을 배양하며, 광범위한 디지털 에코시스템을 출시하기 위해 NVIDIA와 파트너십을 맺었습니다.이 이니셔티브는 최대 500메가와트의 전력 용량을 갖춘 AI "공장"을 설립하는 것을 골자로 합니다. 이 시설에는 엔비디아의 인피니밴드 네트워킹 기술로 상호 연결된 그레이스 블
델과 엔비디아, SC25에서 차세대 AI 인프라 공개
SC25에서 델 테크놀로지스와 엔비디아는 기존 모델부터 현대적인 에이전트 기반 시스템에 이르기까지 더 넓은 범위의 AI 워크로드를 보다 손쉽게 운영할 수 있도록 설계된 통합 AI 플랫폼의 개선 사항을 공개했습니다.기업들이 AI 이니셔티브를 확대함에 따라 흔히 다음과 같은 공통적인 장애물에 직면합니다: 다양하고 확장되는 하드웨어 및 소프트웨어 스택 관리, 데
사우디 아라비아는 국가 AI 개발을 발전시키기 위해 휴메인 및 엔비디아와 협력하고 있습니다.
사우디아라비아에 새로 설립된 국영 기업 HUMAIN은 기본 AI 인프라를 개발하고, 전문성을 배양하며, 광범위한 디지털 에코시스템을 출시하기 위해 NVIDIA와 파트너십을 맺었습니다.이 이니셔티브는 최대 500메가와트의 전력 용량을 갖춘 AI "공장"을 설립하는 것을 골자로 합니다. 이 시설에는 엔비디아의 인피니밴드 네트워킹 기술로 상호 연결된 그레이스 블

깊이 있는 캐릭터를 창조할 수 있는 2026년 최고의 AI 소설 프로필 생성 도구를 만나보세요. XIX.AI가 엄선한 이 목록에는 일관된 동기와 치명적인 결점을 생성해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 여러분의 스토리텔링 잠재력을 발휘해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 가격 최적화 소프트웨어를 만나보세요. 저희가 엄선한 이 목록에는 경쟁사를 추적하고 최대 수익을 위해 매장 가격을 자동으로 조정해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트 결과를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 가격 경쟁력의 우위를 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai

난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai













