
















 家
家ScaleOps、AIワークロードの演算効率向上に向け1億3000万ドルの資金調達を完了
AIブームは全盛期を迎えているにもかかわらず、企業は無駄な演算能力に莫大な費用を浪費している。高価なGPUは遊休状態にあり、ワークロードは過剰に割り当てられ、クラウドの請求額は増え続けている。ScaleOpsは、根本的な問題はハードウェアの不足ではなく、非効率なリソース管理にあると主張している。
コンピューティングリソースをリアルタイムで自動管理・再配分するソフトウェアを開発するこのスタートアップは、月曜日、1億3000万ドルのシリーズC資金調達ラウンドを発表し、企業価値は8億ドルとなった。インサイト・パートナーズが主導し、既存投資家のライトスピード・ベンチャー・パートナーズ、NFX、グリロット・キャピタル・パートナーズ、ピクチャー・キャピタルが参加した。ScaleOpsは、同社のプラットフォームにより、クラウドおよびAIインフラのコストを最大80%削減できると主張している。
2022年に元Run:aiのエンジニアであるヨダル・シャフリル氏によって共同設立されたScaleOpsは、企業が複雑なAIワークロードの管理に直面する苦境を目の当たりにしたことから誕生した。Kubernetesのようなツールは、大規模なマシンクラスター全体でのアプリケーションのオーケストレーションを支援するが、静的な構成に依存しているため、急速な需要の変化に適応できないことが多々ある。その結果、GPUの稼働率が低下し、パフォーマンスのボトルネックが発生し、多大な金銭的損失が生じている。
「Run:aiでの前職時代、私は多くの顧客、特にDevOpsチームと話をしました」と、現在はScaleOpsのCEOを務めるシャフリール氏はTechCrunchに語った。「彼らはRun:aiが提供するソリューションを評価していましたが、特にAI推論の台頭に伴い、本番環境のワークロード管理に依然として苦戦していました。 「大局的に見ると、この問題はGPUだけに限定されたものではないと気づきました。それは演算リソース、メモリ、ストレージ、ネットワークにまで及んでいました。非効率なリソース管理という同じパターンが繰り返し発生していたのです。」
DevOpsチームは、問題を解決するために複数の関係者と調整するのに過度な時間を費やしていることが多く、成果は限定的でした。問題を特定できるツールは数多く存在しましたが、自動化された解決策を提供するものはほとんどありませんでした。このギャップこそが、明確な市場機会となっていました。
ScaleOpsは、アプリケーションの要件とインフラストラクチャの決定を動的に整合させることで、このギャップを埋めることを目指しており、完全に自律的なエンドツーエンドの管理ソリューションを提供すると、シャフリール氏は説明した。
「Kubernetesは強力で柔軟性が高く、高度に設定可能なシステムです。しかし、その設定の自由度こそが弱点でもあります」とシャフリール氏は指摘する。「Kubernetesは静的な設定に依存していますが、現代のアプリケーションは動的です。この不一致により、チーム全体で絶え間ない手作業の負担が生じています。必要なのは、各アプリケーション固有のコンテキスト——そのニーズ、動作、そして変化し続ける環境——を理解するシステムなのです。」

画像提供:Scaleops
この市場には、Cast AI、Kubecost、Spotなどの競合他社が存在する。シャフリール氏によると、多くの企業が自動化機能を提供しているものの、そのソリューションは完全なコンテキストを把握できていないことが多く、パフォーマンスの低下やダウンタイムのリスクを招き、本番システムを管理するチーム間の信頼を損なう恐れがあるという。
ScaleOps社は、同社のプラットフォームが当初から本番環境向けに設計されたと述べています。完全自律型でコンテキストを認識し、手動での設定を一切必要としない点が、同社が他社との差別化要因としている特徴です。
ニューヨークに本社を置くScaleOpsは、世界中の企業顧客、特にKubernetesを利用している企業にサービスを提供している。顧客基盤には、Adobe、Wiz、DocuSign、Salesforce、Coupaなど、ヨーロッパやインドの大手組織や企業が含まれている。
今回のシリーズCラウンドは、2024年11月に実施された5,800万ドルのシリーズBラウンドに続くものです。シャフリール氏は、自律型クラウドインフラ管理への需要が急増しており、同社はまだ成長の初期段階にあると述べています。広報担当者は、現在の総調達額が約2億1,000万ドルに達していることを確認しました。
ScaleOpsは、前年比で450%を超える売上高の伸びと、過去1年間で従業員数が3倍に増加したことを報告しており、今年度末までに従業員数をさらに3倍以上に増やす計画だ。
今回の資金は、製品開発とプラットフォームの拡張に充てられる。AIの普及によりコンピューティング需要が加速する中、効率的なインフラ管理は極めて重要となっている。同社は、完全自律型インフラというビジョンの実現に注力している。
関連記事
 Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
デルとNVIDIA、SC25で次世代AIインフラを発表
SC25において、デル・テクノロジーズとNVIDIAは共同AIプラットフォームの強化を発表した。これにより、組織はレガシーモデルから最新のエージェントベースシステムまで、より広範なAIワークロードをより容易に実行できるようになる。企業がAIイニシアチブを拡大するにつれ、多様なハードウェア・ソフトウェアスタックの管理、データ管理の維持、将来の成長を見据えたシステム構築といった共通の課題に直面すること
サウジアラビアがHUMAINおよびNVIDIAと提携し、国家AI開発を推進。
サウジアラビアが新たに設立した国営企業HUMAINは、基礎的なAIインフラを開発し、専門知識を育成し、広範なデジタルエコシステムを展開するために、エヌビディアと提携した。この構想では、最大500メガワットの電力容量を持つAIの「工場」の設立を概説している。これらの施設には、NVIDIAのInfiniBandネットワーキング技術で相互接続されたGrace Blackwell GB300スーパーコンピ
関連特集おすすめ
漫画制作
Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
デルとNVIDIA、SC25で次世代AIインフラを発表
SC25において、デル・テクノロジーズとNVIDIAは共同AIプラットフォームの強化を発表した。これにより、組織はレガシーモデルから最新のエージェントベースシステムまで、より広範なAIワークロードをより容易に実行できるようになる。企業がAIイニシアチブを拡大するにつれ、多様なハードウェア・ソフトウェアスタックの管理、データ管理の維持、将来の成長を見据えたシステム構築といった共通の課題に直面すること
サウジアラビアがHUMAINおよびNVIDIAと提携し、国家AI開発を推進。
サウジアラビアが新たに設立した国営企業HUMAINは、基礎的なAIインフラを開発し、専門知識を育成し、広範なデジタルエコシステムを展開するために、エヌビディアと提携した。この構想では、最大500メガワットの電力容量を持つAIの「工場」の設立を概説している。これらの施設には、NVIDIAのInfiniBandネットワーキング技術で相互接続されたGrace Blackwell GB300スーパーコンピ
関連特集おすすめ
漫画制作
 漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
 10 ツール
10 ツール
 xix.ai
書き込み
AI小説プロファイル作成のトップクリエイター:一貫性のあるキャラクターの動機と致命的な欠点を生成する
xix.ai
書き込み
AI小説プロファイル作成のトップクリエイター:一貫性のあるキャラクターの動機と致命的な欠点を生成する
深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai
仕事
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
テキスト読み上げ
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai
漫画制作
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
AIブームは全盛期を迎えているにもかかわらず、企業は無駄な演算能力に莫大な費用を浪費している。高価なGPUは遊休状態にあり、ワークロードは過剰に割り当てられ、クラウドの請求額は増え続けている。ScaleOpsは、根本的な問題はハードウェアの不足ではなく、非効率なリソース管理にあると主張している。
コンピューティングリソースをリアルタイムで自動管理・再配分するソフトウェアを開発するこのスタートアップは、月曜日、1億3000万ドルのシリーズC資金調達ラウンドを発表し、企業価値は8億ドルとなった。インサイト・パートナーズが主導し、既存投資家のライトスピード・ベンチャー・パートナーズ、NFX、グリロット・キャピタル・パートナーズ、ピクチャー・キャピタルが参加した。ScaleOpsは、同社のプラットフォームにより、クラウドおよびAIインフラのコストを最大80%削減できると主張している。
2022年に元Run:aiのエンジニアであるヨダル・シャフリル氏によって共同設立されたScaleOpsは、企業が複雑なAIワークロードの管理に直面する苦境を目の当たりにしたことから誕生した。Kubernetesのようなツールは、大規模なマシンクラスター全体でのアプリケーションのオーケストレーションを支援するが、静的な構成に依存しているため、急速な需要の変化に適応できないことが多々ある。その結果、GPUの稼働率が低下し、パフォーマンスのボトルネックが発生し、多大な金銭的損失が生じている。
「Run:aiでの前職時代、私は多くの顧客、特にDevOpsチームと話をしました」と、現在はScaleOpsのCEOを務めるシャフリール氏はTechCrunchに語った。「彼らはRun:aiが提供するソリューションを評価していましたが、特にAI推論の台頭に伴い、本番環境のワークロード管理に依然として苦戦していました。 「大局的に見ると、この問題はGPUだけに限定されたものではないと気づきました。それは演算リソース、メモリ、ストレージ、ネットワークにまで及んでいました。非効率なリソース管理という同じパターンが繰り返し発生していたのです。」
DevOpsチームは、問題を解決するために複数の関係者と調整するのに過度な時間を費やしていることが多く、成果は限定的でした。問題を特定できるツールは数多く存在しましたが、自動化された解決策を提供するものはほとんどありませんでした。このギャップこそが、明確な市場機会となっていました。
ScaleOpsは、アプリケーションの要件とインフラストラクチャの決定を動的に整合させることで、このギャップを埋めることを目指しており、完全に自律的なエンドツーエンドの管理ソリューションを提供すると、シャフリール氏は説明した。
「Kubernetesは強力で柔軟性が高く、高度に設定可能なシステムです。しかし、その設定の自由度こそが弱点でもあります」とシャフリール氏は指摘する。「Kubernetesは静的な設定に依存していますが、現代のアプリケーションは動的です。この不一致により、チーム全体で絶え間ない手作業の負担が生じています。必要なのは、各アプリケーション固有のコンテキスト——そのニーズ、動作、そして変化し続ける環境——を理解するシステムなのです。」
画像提供:Scaleops
この市場には、Cast AI、Kubecost、Spotなどの競合他社が存在する。シャフリール氏によると、多くの企業が自動化機能を提供しているものの、そのソリューションは完全なコンテキストを把握できていないことが多く、パフォーマンスの低下やダウンタイムのリスクを招き、本番システムを管理するチーム間の信頼を損なう恐れがあるという。
ScaleOps社は、同社のプラットフォームが当初から本番環境向けに設計されたと述べています。完全自律型でコンテキストを認識し、手動での設定を一切必要としない点が、同社が他社との差別化要因としている特徴です。
ニューヨークに本社を置くScaleOpsは、世界中の企業顧客、特にKubernetesを利用している企業にサービスを提供している。顧客基盤には、Adobe、Wiz、DocuSign、Salesforce、Coupaなど、ヨーロッパやインドの大手組織や企業が含まれている。
今回のシリーズCラウンドは、2024年11月に実施された5,800万ドルのシリーズBラウンドに続くものです。シャフリール氏は、自律型クラウドインフラ管理への需要が急増しており、同社はまだ成長の初期段階にあると述べています。広報担当者は、現在の総調達額が約2億1,000万ドルに達していることを確認しました。
ScaleOpsは、前年比で450%を超える売上高の伸びと、過去1年間で従業員数が3倍に増加したことを報告しており、今年度末までに従業員数をさらに3倍以上に増やす計画だ。
今回の資金は、製品開発とプラットフォームの拡張に充てられる。AIの普及によりコンピューティング需要が加速する中、効率的なインフラ管理は極めて重要となっている。同社は、完全自律型インフラというビジョンの実現に注力している。










 Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
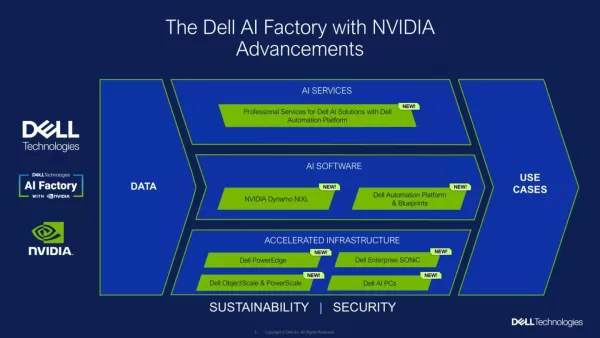 デルとNVIDIA、SC25で次世代AIインフラを発表
SC25において、デル・テクノロジーズとNVIDIAは共同AIプラットフォームの強化を発表した。これにより、組織はレガシーモデルから最新のエージェントベースシステムまで、より広範なAIワークロードをより容易に実行できるようになる。企業がAIイニシアチブを拡大するにつれ、多様なハードウェア・ソフトウェアスタックの管理、データ管理の維持、将来の成長を見据えたシステム構築といった共通の課題に直面すること
サウジアラビアがHUMAINおよびNVIDIAと提携し、国家AI開発を推進。
サウジアラビアが新たに設立した国営企業HUMAINは、基礎的なAIインフラを開発し、専門知識を育成し、広範なデジタルエコシステムを展開するために、エヌビディアと提携した。この構想では、最大500メガワットの電力容量を持つAIの「工場」の設立を概説している。これらの施設には、NVIDIAのInfiniBandネットワーキング技術で相互接続されたGrace Blackwell GB300スーパーコンピ
デルとNVIDIA、SC25で次世代AIインフラを発表
SC25において、デル・テクノロジーズとNVIDIAは共同AIプラットフォームの強化を発表した。これにより、組織はレガシーモデルから最新のエージェントベースシステムまで、より広範なAIワークロードをより容易に実行できるようになる。企業がAIイニシアチブを拡大するにつれ、多様なハードウェア・ソフトウェアスタックの管理、データ管理の維持、将来の成長を見据えたシステム構築といった共通の課題に直面すること
サウジアラビアがHUMAINおよびNVIDIAと提携し、国家AI開発を推進。
サウジアラビアが新たに設立した国営企業HUMAINは、基礎的なAIインフラを開発し、専門知識を育成し、広範なデジタルエコシステムを展開するために、エヌビディアと提携した。この構想では、最大500メガワットの電力容量を持つAIの「工場」の設立を概説している。これらの施設には、NVIDIAのInfiniBandネットワーキング技術で相互接続されたGrace Blackwell GB300スーパーコンピ

XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai













