Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практическим попыткам удаления.
Ключевое отличие между водяными знаками и «приманками для авторских прав» заключается в том, что водяные знаки — видимые или скрытые — обычно предназначены для отображения во всей коллекции (например, наборе данных изображений) в качестве постоянного сдерживающего фактора против случайного копирования.
В отличие от этого, фиктивная запись — это небольшой фрагмент текста, часто слово или определение, помещенное в большой общий набор данных, с целью доказать кражу. Идея заключается в том, что когда вся работа копируется без разрешения, либо напрямую, либо в качестве основы для производного произведения, наличие уникального, сфабрикованного факта, вставленного оригинальными создателями, легко раскрывает кражу.
Когда речь идет о водяных знаках в больших языковых моделях (LLM) и моделях языка зрения (VLM), степень, в которой результаты содержат эти маркеры, обычно делится на две категории: обеспечение того, чтобы все или большинство результатов несли явный или скрытый водяной знак; или встраивание «секретного токена», который можно восстановить для доказательства кражи, не появляясь в обычном выводе модели.
Вес доказательств
Последний подход исследуется в рамках нового сотрудничества между исследователями из Китая, Италии и Сингапура. Эта работа направлена на предоставление метода раскрытия информации для моделей с открытым исходным кодом, предотвращающего их несанкционированную коммерциализацию или использование за пределами первоначальных условий лицензии.
Например, исходная лицензия модели может позволять любому получать прибыль от нее, если он делится своими модификациями на тех же щедрых условиях, но компания может попытаться сохранить свои настройки (например, точные версии) в секрете, чтобы создать себе несправедливое преимущество.
Большинство исследований в этой области сосредоточено на выявлении неправомерного использования в моделях с закрытым исходным кодом, моделях, доступных только через API, или моделях, в которых доступны только оптимизированные (квантованные) веса. Их сложнее эффективно редактировать с помощью подхода, описанного в новой статье, из-за ограниченного доступа к архитектуре модели.
Такой фокус на выпусках FOSS, возможно, ожидаем от китайского исследовательского сектора, поскольку в течение последнего года Китай выпускал щедрые модели с полным весом*, которые конкурируют с более ограниченными западными аналогами.
Новый подход, называемый EditMark, выделяется тем, что не требует тонкой настройки для добавления «отравленных» данных или обучения с нуля с использованием включенных данных.
Это дает несколько преимуществ: во-первых, любые «выдающие» данные, включенные в обучающий набор, после их обнаружения и раскрытия становятся неэффективными, поскольку злоумышленники могут нацелиться на них напрямую. Но для атаки на EditMark злоумышленнику необходимо знать, на какой слой модели нацеливаться и какой метод использовать, что маловероятно.
Во-вторых, этот метод быстр и недорог: его применение к обученной модели занимает всего несколько секунд (а не дней или недель), что позволяет избежать высоких затрат на точную настройку (которые растут с увеличением размера модели и данных).
Наконец, этот подход значительно меньше нарушает нормальную работу модели по сравнению с тонкой настройкой или более ранними методами редактирования.
В ходе тестирования EditMark, который встраивает математические запросы с несколькими возможными ответами в веса модели, достиг 100% коэффициента извлечения.
Авторы заявляют:
«Всесторонние эксперименты демонстрируют исключительную эффективность EditMark при нанесении водяных знаков на LLM. Он достигает замечательной эффективности, встраивая 32-битный водяной знак менее чем за 20 секунд со 100% успешностью извлечения (ESR).
Примечательно, что встраивание водяных знаков занимает менее 1/300 времени, необходимого для тонкой настройки (в среднем 6875 секунд), что подчеркивает способность EditMark реализовывать водяные знаки большой емкости с беспрецедентной скоростью и надежностью.
Кроме того, обширные эксперименты подтверждают надежность, скрытность и точность EditMark».
Новая статья озаглавлена «EditMark: Watermarking Large Language Models based on Model Editing» (EditMark: водяные знаки в больших языковых моделях на основе редактирования моделей) и написана восемью авторами из Китайского университета науки и технологии, Университета Сиены и CFAR/IHPC/A*STAR в Сингапуре.
Метод
Подход EditMark состоит из четырех компонентов: генератора, кодировщика, редактора и декодера:
Конвейер EditMark встраивает водяной знак путем редактирования модели для ответа на конкретные математические вопросы таким образом, что кодируется скрытая идентифицирующая информация. Источник: https://arxiv.org/pdf/2510.16367
Генератор использует псевдослучайное семя для создания математических вопросов с несколькими ответами; кодер выбирает ответы на основе водяного знака, которые затем встраиваются в модель посредством специального процесса редактирования. После выпуска или неправомерного использования отредактированной модели водяной знак можно извлечь, задав те же вопросы и декодировав шаблоны ответов.
Затем редактор изменяет веса модели таким образом, что при задании этих вопросов с семенем модель последовательно генерирует целевые ответы, встраивая водяной знак непосредственно в свое поведение. Декодер восстанавливает водяной знак, задавая те же вопросы подозрительной модели и переводя ее ответы обратно в скрытую подпись.
Модель угроз
Модель угроз, представленная в статье, предполагает, что водяные знаки наносятся в условиях «белого ящика». Хотя это часто вызывает озабоченность в исследованиях по безопасности, в данном случае это нормально, поскольку метод направлен на защиту владельцев, которые имеют полный доступ к своей работе.
Также предполагается, что злоумышленник имеет доступ к белому ящику после получения модели, что означает, что он может ее модифицировать (например, путем обрезки или тонкой настройки). Такой сценарий типичен для выпусков FOSS. Однако злоумышленник не знает процесса извлечения водяных знаков или схемы и может только сделать вывод об этом путем экспериментов или утечек.
Генератор создает логически и фактически верные математические вопросы с несколькими правильными ответами, используя GPT‑4o для диверсификации шаблонов (как показано ниже) и псевдослучайное семя, чтобы гарантировать уникальность каждого вопроса. Это позволяет детерминированно вставлять известный водяной знак через перестановки ответов, минимизируя при этом пересечение вопросов, чтобы избежать запутанности редактирования:
Шаблоны вопросов, сгенерированные GPT‑4o для встраивания водяных знаков, каждый из которых структурирован так, чтобы дать несколько действительных целочисленных ответов из исходного неравенства.
Кодировщик преобразует каждый двоичный сегмент водяного знака в уникальную перестановку целых чисел из набора решений данного математического вопроса. Используя лексикографическую теорию перестановок, кодировщик сопоставляет десятичное значение каждого фрагмента водяного знака с определенным упорядоченным набором ответов, обеспечивая детерминированное встраивание водяного знака в поведение модели.
Что касается редактора, то исходный метод редактирования модели AlphaEdit, используемый для встраивания водяных знаков, не обладает ни точностью, ни устойчивостью и часто не дает требуемых ответов. Любые вносимые им изменения легко нарушаются обрезкой или шумом.
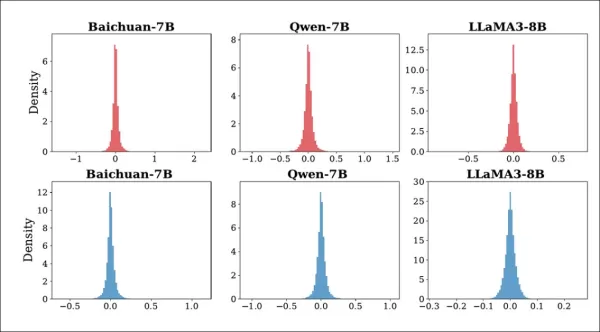
Чтобы решить эту проблему, авторы разработали стратегию многораундового редактирования, которая постепенно корректирует веса модели на одном уровне MLP, пока ответы не совпадут с желаемыми ответами. Чтобы упрочить редактирование от подделки, во время обучения вводится гауссовый шум для имитации атак:
Распределение изменений в K1 для Baichuan-7B, Qwen-7B и LLaMA3-8B до и после атак. Верхняя строка показывает эффект введения случайного шума; нижняя строка показывает эффект обрезки модели. Все изменения остаются близки к нулю, что свидетельствует о том, что атаки не нарушают внутреннее поведение модели.
Система оценки останавливает процесс, когда правки становятся достаточно точными, а регуляризация обеспечивает стабильность обновлений в течение нескольких раундов.
Декодер задает модели те же специальные вопросы, которые использовались при нанесении водяных знаков, а затем считывает ее ответы, чтобы вывести скрытый идентификатор. Поскольку шаблон ответов следует секретному правилу, этот идентификатор можно восстановить без изучения внутренней структуры модели.
Данные и тесты
Для оценки EditMark было протестировано пять LLM: GPT2-XL; GPT-J-6B; LLaMA-3-8B; Baichuan-7B; и Qwen-7B. Для встраивания водяных знаков использовался вышеупомянутый AlphaEdit, а в качестве метрик были использованы коэффициент успешности извлечения (ESR) и время встраивания (ET).
В качестве базовых показателей авторы выбрали Model Watermark (бэкдор); KIMark; и BadEdit, фреймворк, первоначально разработанный для вставки бэкдора, адаптированный для этого проекта.
Авторы отредактировали 15-й слой LLaMA-3-8B; 17-й слой GPT2-XL и GPT-J-6B; и 14-й слой Qwen-7B и Baichuan-7B.
Эксперименты проводились на четырех графических процессорах NVIDIA RTX 4090 (каждый с 24 ГБ видеопамяти) с встроенными водяными знаками длиной 32, 64 и 128 бит. Использованные шаблоны вопросов подробно описаны ниже:
Шаблоны, используемые для генерации вопросов с несколькими ответами (MA) для водяных знаков. Каждый вопрос основан на различном типе математического неравенства с вставленными случайными значениями для переменных. Модель должна вернуть список целочисленных решений, причем порядок ответов используется для кодирования или декодирования битов водяных знаков. Четыре шаблона охватывают квадратичные, логарифмические, рациональные и интервальные формы, и все они были сгенерированы с помощью GPT-4o.
Чтобы уменьшить влияние случайности, во время тестирования с разными емкостями водяных знаков применялись семена от 1 до 20.
Изначально исследователи протестировали как ESR, так и временные затраты на встраивание водяных знаков в LLM:
Сравнение EditMark с тремя предыдущими методами водяных знаков на пяти крупных языковых моделях. Указаны коэффициент успешности извлечения (ESR) и время встраивания (ET) в секундах. EditMark стабильно достигает 100% коэффициента успешности, одновременно сокращая время встраивания на несколько порядков, превосходя все базовые показатели как по точности, так и по эффективности в моделях различного размера и архитектуры.
По поводу этих результатов авторы заявляют:
«[EditMark] достигает 100% ESR и требует менее 20 секунд для встраивания 32-битного водяного знака для всех оцениваемых LLM. В частности, среднее время встраивания для Baichuan-7B и Qwen-7B составляет менее 10 секунд, что демонстрирует высокую эффективность EditMark».
Для 128-битного водяного знака, максимально возможного значения в рамках такой схемы, EditMark сохранил «неизгладимость»:
Успешность извлечения и время встраивания EditMark для водяных знаков длиной 32, 64 и 128 бит в пяти языковых моделях. Во всех случаях сохраняется идеальная успешность, в то время как время встраивания увеличивается с размером водяного знака, но остается менее одной минуты даже при 128 битах.
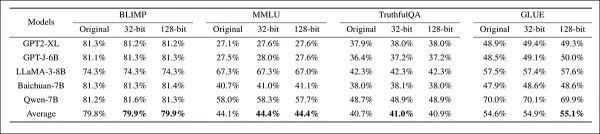
Далее была проверена способность системы сохранять точность водяных знаков по нескольким тестам:
Оценка точности водяных знаков по четырем тестам на пяти моделях, сравнивающих немодифицированные модели с моделями с водяными знаками емкостью 32 и 128 бит. Производительность оставалась стабильной во всех конфигурациях, с лишь незначительными колебаниями средних оценок, что указывает на ограниченное влияние вставки водяных знаков на точность тестов.
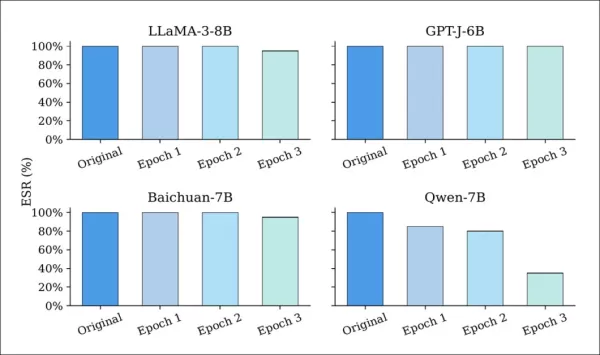
Устойчивость EditMark была протестирована на шести распространенных стратегиях атак. Сначала в модели были встроены 128-битные водяные знаки с использованием пяти различных семян. Тонкая настройка, как показано ниже, привела лишь к незначительному снижению успешности извлечения (ESR) для большинства моделей:
Успешность извлечения (ESR) LLM с водяными знаками до и после тонкой настройки в течение одного-трех эпохов. В то время как большинство моделей сохраняют высокий ESR на протяжении всего времени, Qwen-7B демонстрирует заметный спад, что указывает на большую уязвимость к обновлениям параметров.
Даже после нескольких эпох большинство моделей сохранили ESR выше 90%, что показывает, что EditMark противостоит дрейфу параметров от обучения на основе LoRA.
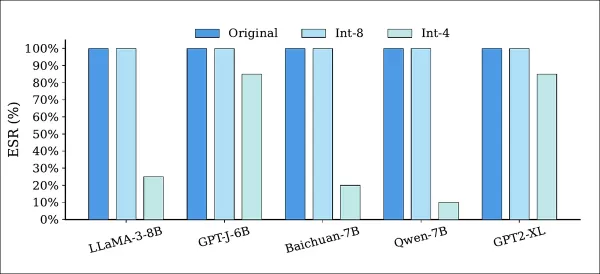
Атаки квантования снизили точность модели, но оставили большинство водяных знаков нетронутыми:
Успешность извлечения (ESR) моделей с водяными знаками до и после квантования с использованием точности Int‑8 и Int‑4. ESR осталась неизменной при квантовании Int‑8 во всех моделях, в то время как квантование Int‑4 привело к частичному ухудшению, что указывает на то, что более низкая точность может ослабить, но не полностью удалить водяной знак.
Как показано выше, квантование Int-8 сохранило 100% ESR во всех моделях, в то время как квантование Int-4 оказало умеренное влияние на ESR, но привело к недопустимой потере производительности.
В статье отмечается, что этот сценарий предлагает ограниченные возможности для злоумышленников, поскольку приводит к взломанной, но ухудшенной модели.
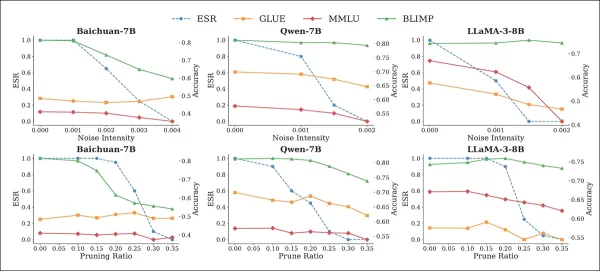
Тесты на шум и обрезку оценивали четыре эталонных фреймворка: MMLU, BLIMP, TruthfulQA и GLUE. Эти атаки привели к снижению ESR по мере усиления возмущений:
Влияние атак шума (верхний ряд) и обрезки (нижний ряд) на ESR и эталонная производительность моделей с водяными знаками. По мере снижения ESR с увеличением возмущения также ухудшается точность эталонных тестов, особенно при более высоких интенсивностях шума и коэффициентах обрезки, что подчеркивает (обычное) противоречие между удалением водяных знаков и полезностью модели.
Однако это также привело к резкому снижению производительности задач: Baichuan-7B продемонстрировал падение на 27-31% по BLIMP при применении шума или прореживания.
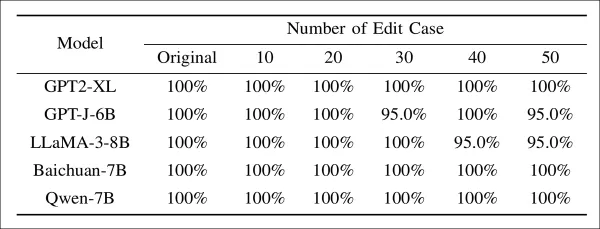
Также были оценены редактирование модели и адаптивные атаки:
Успешность извлечения моделей с водяными знаками, подвергнутых различной степени редактирования. Даже при применении до пятидесяти изменений к известным слоям водяных знаков ESR остается выше 95% для всех моделей, что указывает на то, что прямые изменения параметров имеют ограниченный эффект на удаление водяных знаков.
Здесь EditMark сохранил ESR выше 95%, даже когда целью были точные слои встраивания.
Заключение
DRM, секретные водяные знаки и другие меры безопасности, которые имели ограниченный успех в эпоху до появления ИИ, сложно применять к системам машинного обучения. Намеренно упрощенный характер современных архитектур хостов в сочетании с отсутствием подходящих инструментов делает вставленные водяные знаки относительно уязвимыми.
Впечатляет система, предназначенная для распространения моделей FOSS, которая выдерживает все, кроме самых маловероятных сценариев атак, учитывая предварительные знания злоумышленника. Однако небольшое снижение производительности в результате редактирования после обучения, хотя и незначительное в этих экспериментах, может заставить потенциальных пользователей задуматься, особенно с учетом того, что возврат к модели управления, ориентированной на API, почти полностью позволяет избежать таких атак.
*Наэтом сайте утверждается, что «открытые» релизы из Китая могут не полностью соответствовать критериям FOSS, поскольку данные часто утаиваются, что не позволяет точно воспроизвести процесс обучения. Эта тема требует более глубокого изучения политики выпуска моделей ИИ на Востоке и Западе, что выходит за рамки данной статьи.
Впервые опубликовано в понедельник, 27 октября 2025 г.
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
Wow, dieses Thema mit unsichtbaren Wasserzeichen für KI-Modelle klingt wie etwas aus einem Spionagefilm! 🤯 Der Unterschied zu ‚Copyright-Baiting‘ ist echt wichtig – es geht ja um langfristigen Schutz, nicht nur ums Fangen. Aber was, wenn dieses Werkzeug selbst missbraucht wird? Irgendwie bemerkenswert, was technisch möglich ist, und ein bisschen gruselig zugleich.
Increíble técnica, pero ¿qué tan seguro es que no afecte el rendimiento del modelo en tareas reales? 🤔 Me preocupa que estas medidas puedan usarse también para restringir el acceso a IA de código abierto. ¿Y si una empresa alega falsamente protección de marca de agua? ¡El debate ético apenas comienza!
При нажатии на «Принять все файлы cookie» вы соглашаетесь на хранение файлов cookie на вашем устройстве для улучшения навигации по сайту, анализа использования сайта и поддержки наших маркетинговых усилий.Политика конфиденциальности Уведомление
При посещении любого веб-сайта он может хранить или получать информацию в вашем браузере, главным образом в виде файлов cookie. Эта информация может относиться к вам, вашим предпочтениям или вашему устройству и в основном используется для того, чтобы сайт работал так, как вы ожидаете. Эта информация обычно не идентифицирует вас напрямую, но может предоставить вам более персонализированный веб-опыт. Поскольку мы уважаем ваше право на конфиденциальность, вы можете отказаться от разрешения определенных типов файлов cookie. Нажмите на разные заголовки категорий, чтобы узнать больше и изменить наши параметры по умолчанию. Однако блокировка некоторых типов файлов cookie может повлиять на ваше восприятие сайта и предоставляемые нами услуги. Политика конфиденциальностиЗаявление
Управление предпочтениями
Строго необходимые файлы cookie
Всегда активен
Эти файлы cookie необходимы для работы веб-сайта и не могут быть отключены в наших системах. Обычно они устанавливаются только в ответ на ваши действия, которые являются запросом на предоставление услуг, например, настройка предпочтений конфиденциальности, вход в систему или заполнение форм. Вы можете настроить браузер на блокировку этих файлов cookie или оповещение о них, но тогда некоторые части сайта не будут работать. Эти файлы cookie не хранят никакой персональной информации, позволяющей идентифицировать вас.

















 Дом
Дом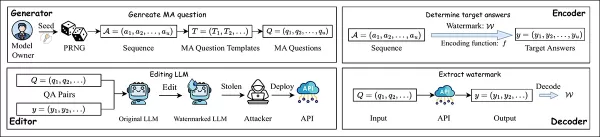




 Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
 Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
 10 инструментов
10 инструментов
 xix.ai
Производительность
xix.ai
Производительность

 Комментарии (3)
Комментарии (3)





















 Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
 Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
 Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э
Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э




















