
















 Lar
LarBria garante um novo financiamento para modelos de IA treinados em dados licenciados
Geradores de imagens movidos a IA estão no centro de numerosos processos de direitos autorais contra empresas de IA, principalmente porque são treinados em vastos conjuntos de dados extraídos de sites públicos. Essas empresas frequentemente defendem suas práticas alegando proteção sob a doutrina do uso justo, mas muitos detentores de direitos autorais contestam essa afirmação.
Como resultado, algumas startups, incluindo a Bria, sediada em Nova York e Tel Aviv, fundada em 2020 por Yair Adato e Gal Jacobi, estão adotando uma abordagem diferente. A Bria opta por treinar seus geradores de imagens exclusivamente em conteúdo licenciado, colaborando com cerca de 20 parceiros, como a Getty Images, para garantir conformidade e integridade de conteúdo. O CEO Yair Adato destacou que a Bria compensa os proprietários de imagens "programaticamente" com base em sua "influência geral" na plataforma.
"Os modelos de fundação da Bria abrigam um bilhão de visuais e milhões de vídeos," compartilhou Adato com a TechCrunch. Ele observou ainda que, ao treinar em conjuntos de dados globalmente representativos, a Bria conseguiu reduzir os vieses frequentemente encontrados em visuais gerados por IA. Essa abordagem permite que seus modelos produzam conteúdo diverso e inclusivo, ideal para uma ampla gama de usos criativos.
A Bria melhora a experiência do usuário ao oferecer plug-ins compatíveis com softwares populares de edição e design de imagens, como Photoshop e Figma. Além disso, eles fornecem uma API de ajuste fino que permite aos clientes personalizar os modelos da Bria para necessidades específicas. Os usuários têm a flexibilidade de operar esses modelos na plataforma da Bria ou em ambientes de computação externos, como nuvens públicas. Adato garantiu que, em todos os cenários, os clientes mantêm a propriedade tanto dos dados quanto das saídas.
"Clientes empresariais podem acessar nosso código-fonte e [modelos] mediante pagamento," explicou Adato. "Oferecemos mais de 30 APIs especializadas para criação e modificação visual, disponíveis por assinatura e preços baseados em uso. As empresas também podem ajustar nossos modelos de IA generativa com seus ativos de marca, criando motores personalizados que preservam sua identidade visual."
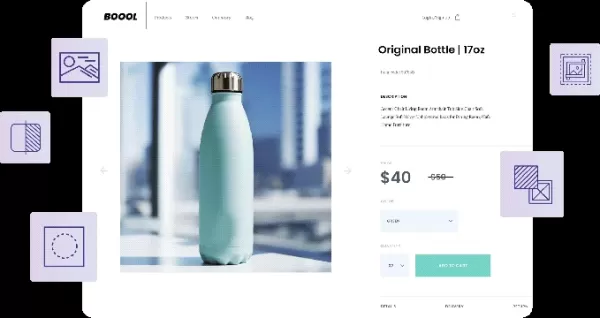
Os modelos de IA da Bria, treinados em dados licenciados, podem gerar e editar imagens. Créditos da imagem: Bria A visão da Bria vai além das capacidades atuais. Adato compartilhou com a TechCrunch que a empresa, com seus 40 funcionários, pretende construir um "ecossistema de PI" que permita às empresas usar imagens licenciadas de conglomerados de mídia para fins comerciais, com "conformidade integrada."
A empresa não está parando nas imagens; a Bria planeja expandir sua plataforma para suportar outros tipos de mídia, como música, vídeo e texto, além de aplicações em dispositivos. Apesar dos desafios na indústria de tecnologia em geral, como a maturação do mercado e pressões macroeconômicas, Adato acredita que esses fatores apenas fortalecem a posição de mercado da Bria.
Enquanto outras empresas como Adobe, Spawning AI e Shutterstock também estão se aventurando em geradores de mídia licenciada, a Bria conquistou uma posição significativa neste mercado emergente. Na quinta-feira, eles anunciaram uma rodada de financiamento Série B bem-sucedida, arrecadando $40 milhões, liderada pela Red Dot Capital e apoiada por Maor Investments, Entrée Capital, GFT Ventures, Intel Capital e IN Venture. Isso eleva o financiamento total da Bria para aproximadamente $65 milhões, com a maior parte dos novos fundos destinada ao desenvolvimento de produtos.
"Estamos experimentando um crescimento rápido com nossos 40 clientes, vendo um crescimento de receita recorrente anual de mais de 400% no último ano," observou Adato. Ele também mencionou planos para expandir a equipe com especialistas em IA generativa para música e vídeo, vendas e marketing globais, leis de PI e direitos autorais, e consultoria em IA, com o objetivo de dobrar o tamanho da equipe até o final do ano.
Atualizado em 15/03 às 23:22, horário do Pacífico: A versão original desta história afirmou incorretamente que a Bria foi fundada em 2023, não em 2020, e não mencionou o cofundador Gal Jacobi. Pedimos desculpas por esses erros.
Artigo relacionado
 Política obrigatória de pesquisa com IA impulsiona êxodo; DuckDuckGo registra aumento no número de usuários
Após o anúncio feito pela Google na conferência I/O de 2026 sobre uma reformulação completa do seu mecanismo de busca com IA, muitos usuários começaram a procurar alternativas mais controláveis, já qu
Xiaohongshu passa por reestruturação: Conan é nomeado presidente, cria o Departamento de IA e a Divisão Internacional Rednote
Em 30 de abril, a Xiaohongshu enviou um memorando interno a todos os funcionários anunciando o lançamento de uma nova reestruturação organizacional. O cerne dessa mudança envolve a integração total de
O jogo "Xiaolongxia", da Tencent, supera as expectativas; equipe amplia capacidade em 10 vezes, pede desculpas e oferece indenização
A Tencent lançou oficialmente o WorkBuddy, um agente inteligente de IA para todos os cenários, marcando uma nova fase na corrida pela camada de aplicação de modelos de grande porte, com alta integraçã
Recomendações de tópicos especiais relacionados
Conversão de texto para fala
Política obrigatória de pesquisa com IA impulsiona êxodo; DuckDuckGo registra aumento no número de usuários
Após o anúncio feito pela Google na conferência I/O de 2026 sobre uma reformulação completa do seu mecanismo de busca com IA, muitos usuários começaram a procurar alternativas mais controláveis, já qu
Xiaohongshu passa por reestruturação: Conan é nomeado presidente, cria o Departamento de IA e a Divisão Internacional Rednote
Em 30 de abril, a Xiaohongshu enviou um memorando interno a todos os funcionários anunciando o lançamento de uma nova reestruturação organizacional. O cerne dessa mudança envolve a integração total de
O jogo "Xiaolongxia", da Tencent, supera as expectativas; equipe amplia capacidade em 10 vezes, pede desculpas e oferece indenização
A Tencent lançou oficialmente o WorkBuddy, um agente inteligente de IA para todos os cenários, marcando uma nova fase na corrida pela camada de aplicação de modelos de grande porte, com alta integraçã
Recomendações de tópicos especiais relacionados
Conversão de texto para fala
 Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
 10 ferramentas
10 ferramentas
 xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

 Comentários (20)
Comentários (20)
![GregoryAdams]()
이 기사 읽고 나니 AI와 저작권 문제가 참 복잡하네요. 저작권 침해 논란에서 벗어나기 위해 합법 데이터로 훈련된 모델을 개발하는 건 현명한 전략인 것 같아요. 🤔 앞으로 다른 AI 기업들도 비슷한 방향으로 나아갈까요? 한국에서도 이런 논의가 활발히 이루어지면 좋겠어요.
![RogerSanchez]()
이 기사 보니까 기존 AI 이미지 생성기의 저작권 문제가 정말 심각하네요 🤔 공개 웹사이트 데이터를 무단 사용하니까 당연히 소송 걸리지... 브리아 같은 회사가 라이선스 받은 데이터로 모델 학습하는 건 더 윤리적인 접근처럼 보여요. 앞으로 AI 업계에서 이런 식의 합법적인 모델이 주류가 되겠죠?
![PaulKing]()
This article on Bria's funding is eye-opening! Using licensed data for AI training sounds like a smart move to dodge those messy copyright lawsuits. But I wonder, will this make their models pricier or less creative? 🤔
![DanielPerez]()
This article really highlights the messy legal side of AI image generators! It's wild how companies scrape the web for data and then cry 'fair use' when sued. Bria’s approach with licensed data sounds like a smarter move—less drama, more ethics. Curious to see if this sets a trend! 😄
![BrianBaker]()
This article on Bria's funding is super intriguing! Using licensed data for AI training feels like a smart move to dodge those messy copyright lawsuits. Curious how this’ll shift the industry—will others follow suit? 🤔
![NicholasYoung]()
Briaがライセンスされたデータで訓練されたAIモデルに資金を確保する動きは賢いですが、まだ少し怪しいです。著作権問題を避けようとしているのは素晴らしいですが、本当に問題を解決しているのでしょうか?弾丸の傷にバンドエイドを貼るようなものですね。🤔
Geradores de imagens movidos a IA estão no centro de numerosos processos de direitos autorais contra empresas de IA, principalmente porque são treinados em vastos conjuntos de dados extraídos de sites públicos. Essas empresas frequentemente defendem suas práticas alegando proteção sob a doutrina do uso justo, mas muitos detentores de direitos autorais contestam essa afirmação.
Como resultado, algumas startups, incluindo a Bria, sediada em Nova York e Tel Aviv, fundada em 2020 por Yair Adato e Gal Jacobi, estão adotando uma abordagem diferente. A Bria opta por treinar seus geradores de imagens exclusivamente em conteúdo licenciado, colaborando com cerca de 20 parceiros, como a Getty Images, para garantir conformidade e integridade de conteúdo. O CEO Yair Adato destacou que a Bria compensa os proprietários de imagens "programaticamente" com base em sua "influência geral" na plataforma.
"Os modelos de fundação da Bria abrigam um bilhão de visuais e milhões de vídeos," compartilhou Adato com a TechCrunch. Ele observou ainda que, ao treinar em conjuntos de dados globalmente representativos, a Bria conseguiu reduzir os vieses frequentemente encontrados em visuais gerados por IA. Essa abordagem permite que seus modelos produzam conteúdo diverso e inclusivo, ideal para uma ampla gama de usos criativos.
A Bria melhora a experiência do usuário ao oferecer plug-ins compatíveis com softwares populares de edição e design de imagens, como Photoshop e Figma. Além disso, eles fornecem uma API de ajuste fino que permite aos clientes personalizar os modelos da Bria para necessidades específicas. Os usuários têm a flexibilidade de operar esses modelos na plataforma da Bria ou em ambientes de computação externos, como nuvens públicas. Adato garantiu que, em todos os cenários, os clientes mantêm a propriedade tanto dos dados quanto das saídas.
"Clientes empresariais podem acessar nosso código-fonte e [modelos] mediante pagamento," explicou Adato. "Oferecemos mais de 30 APIs especializadas para criação e modificação visual, disponíveis por assinatura e preços baseados em uso. As empresas também podem ajustar nossos modelos de IA generativa com seus ativos de marca, criando motores personalizados que preservam sua identidade visual."
A visão da Bria vai além das capacidades atuais. Adato compartilhou com a TechCrunch que a empresa, com seus 40 funcionários, pretende construir um "ecossistema de PI" que permita às empresas usar imagens licenciadas de conglomerados de mídia para fins comerciais, com "conformidade integrada."
A empresa não está parando nas imagens; a Bria planeja expandir sua plataforma para suportar outros tipos de mídia, como música, vídeo e texto, além de aplicações em dispositivos. Apesar dos desafios na indústria de tecnologia em geral, como a maturação do mercado e pressões macroeconômicas, Adato acredita que esses fatores apenas fortalecem a posição de mercado da Bria.
Enquanto outras empresas como Adobe, Spawning AI e Shutterstock também estão se aventurando em geradores de mídia licenciada, a Bria conquistou uma posição significativa neste mercado emergente. Na quinta-feira, eles anunciaram uma rodada de financiamento Série B bem-sucedida, arrecadando $40 milhões, liderada pela Red Dot Capital e apoiada por Maor Investments, Entrée Capital, GFT Ventures, Intel Capital e IN Venture. Isso eleva o financiamento total da Bria para aproximadamente $65 milhões, com a maior parte dos novos fundos destinada ao desenvolvimento de produtos.
"Estamos experimentando um crescimento rápido com nossos 40 clientes, vendo um crescimento de receita recorrente anual de mais de 400% no último ano," observou Adato. Ele também mencionou planos para expandir a equipe com especialistas em IA generativa para música e vídeo, vendas e marketing globais, leis de PI e direitos autorais, e consultoria em IA, com o objetivo de dobrar o tamanho da equipe até o final do ano.
Atualizado em 15/03 às 23:22, horário do Pacífico: A versão original desta história afirmou incorretamente que a Bria foi fundada em 2023, não em 2020, e não mencionou o cofundador Gal Jacobi. Pedimos desculpas por esses erros.










 Política obrigatória de pesquisa com IA impulsiona êxodo; DuckDuckGo registra aumento no número de usuários
Após o anúncio feito pela Google na conferência I/O de 2026 sobre uma reformulação completa do seu mecanismo de busca com IA, muitos usuários começaram a procurar alternativas mais controláveis, já qu
Política obrigatória de pesquisa com IA impulsiona êxodo; DuckDuckGo registra aumento no número de usuários
Após o anúncio feito pela Google na conferência I/O de 2026 sobre uma reformulação completa do seu mecanismo de busca com IA, muitos usuários começaram a procurar alternativas mais controláveis, já qu
 Xiaohongshu passa por reestruturação: Conan é nomeado presidente, cria o Departamento de IA e a Divisão Internacional Rednote
Em 30 de abril, a Xiaohongshu enviou um memorando interno a todos os funcionários anunciando o lançamento de uma nova reestruturação organizacional. O cerne dessa mudança envolve a integração total de
Xiaohongshu passa por reestruturação: Conan é nomeado presidente, cria o Departamento de IA e a Divisão Internacional Rednote
Em 30 de abril, a Xiaohongshu enviou um memorando interno a todos os funcionários anunciando o lançamento de uma nova reestruturação organizacional. O cerne dessa mudança envolve a integração total de
 O jogo "Xiaolongxia", da Tencent, supera as expectativas; equipe amplia capacidade em 10 vezes, pede desculpas e oferece indenização
A Tencent lançou oficialmente o WorkBuddy, um agente inteligente de IA para todos os cenários, marcando uma nova fase na corrida pela camada de aplicação de modelos de grande porte, com alta integraçã
O jogo "Xiaolongxia", da Tencent, supera as expectativas; equipe amplia capacidade em 10 vezes, pede desculpas e oferece indenização
A Tencent lançou oficialmente o WorkBuddy, um agente inteligente de IA para todos os cenários, marcando uma nova fase na corrida pela camada de aplicação de modelos de grande porte, com alta integraçã

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

이 기사 읽고 나니 AI와 저작권 문제가 참 복잡하네요. 저작권 침해 논란에서 벗어나기 위해 합법 데이터로 훈련된 모델을 개발하는 건 현명한 전략인 것 같아요. 🤔 앞으로 다른 AI 기업들도 비슷한 방향으로 나아갈까요? 한국에서도 이런 논의가 활발히 이루어지면 좋겠어요.
이 기사 보니까 기존 AI 이미지 생성기의 저작권 문제가 정말 심각하네요 🤔 공개 웹사이트 데이터를 무단 사용하니까 당연히 소송 걸리지... 브리아 같은 회사가 라이선스 받은 데이터로 모델 학습하는 건 더 윤리적인 접근처럼 보여요. 앞으로 AI 업계에서 이런 식의 합법적인 모델이 주류가 되겠죠?
This article on Bria's funding is eye-opening! Using licensed data for AI training sounds like a smart move to dodge those messy copyright lawsuits. But I wonder, will this make their models pricier or less creative? 🤔
This article really highlights the messy legal side of AI image generators! It's wild how companies scrape the web for data and then cry 'fair use' when sued. Bria’s approach with licensed data sounds like a smarter move—less drama, more ethics. Curious to see if this sets a trend! 😄
This article on Bria's funding is super intriguing! Using licensed data for AI training feels like a smart move to dodge those messy copyright lawsuits. Curious how this’ll shift the industry—will others follow suit? 🤔
Briaがライセンスされたデータで訓練されたAIモデルに資金を確保する動きは賢いですが、まだ少し怪しいです。著作権問題を避けようとしているのは素晴らしいですが、本当に問題を解決しているのでしょうか?弾丸の傷にバンドエイドを貼るようなものですね。🤔













