Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in den Standardausgaben und widersteht allen praktischen Entfernungsversuchen.
Der wesentliche Unterschied zwischen Wasserzeichen und „Copyright-Baiting” besteht darin, dass Wasserzeichen – ob sichtbar oder versteckt – in der Regel so gestaltet sind, dass sie in einer Sammlung (z. B. einem Bilddatensatz) durchgehend als einheitliche Abschreckung gegen gelegentliches Kopieren erscheinen.
Im Gegensatz dazu ist ein fiktiver Eintrag ein kleines Textstück, oft ein Wort oder eine Definition, das in einer großen, generischen Sammlung platziert wird, um Diebstahl nachzuweisen. Die Idee dahinter ist, dass, wenn das gesamte Werk ohne Erlaubnis kopiert wird, entweder direkt oder als Grundlage für ein abgeleitetes Werk, das Vorhandensein einer einzigartigen, erfundenen Tatsache, die von den ursprünglichen Urhebern eingefügt wurde, den Diebstahl leicht aufdeckt.
Wenn es um die Wasserzeichen-Kennzeichnung von Large Language Models (LLMs) und Vision Language Models (VLMs) geht, lässt sich das Ausmaß, in dem die Ergebnisse diese Markierungen enthalten, in der Regel in zwei Kategorien einteilen: entweder wird sichergestellt, dass alle oder die meisten Ergebnisse ein offensichtliches oder verstecktes Wasserzeichen enthalten, oder es wird ein „geheimes Token” eingebettet, das wiederhergestellt werden kann, um einen Diebstahl nachzuweisen – ohne dass es in den regulären Ergebnissen des Modells erscheint.
Die Bedeutung der Beweise
Der letztere Ansatz wird in einer neuen Zusammenarbeit zwischen Forschern aus China, Italien und Singapur untersucht. Diese Arbeit zielt darauf ab, eine Offenlegungsmethode für Open-Source-Modelle bereitzustellen, um deren unbefugte Kommerzialisierung oder Verwendung über die ursprünglichen Lizenzbedingungen hinaus zu verhindern.
Beispielsweise kann die ursprüngliche Lizenz eines Modells jedem erlauben, davon zu profitieren, solange er seine Änderungen unter denselben großzügigen Bedingungen weitergibt – aber ein Unternehmen könnte versuchen, seine Anpassungen (wie fein abgestimmte Versionen) geheim zu halten, um sich einen unfairen Vorteil zu verschaffen.
Die meisten Forschungen in diesem Bereich konzentrieren sich auf die Aufdeckung von Missbrauch in Closed-Source-Modellen, API-only-Modellen oder Modellen, bei denen nur optimierte (quantisierte) Gewichte verfügbar sind. Diese sind mit dem Ansatz der neuen Veröffentlichung aufgrund des eingeschränkten Zugriffs auf die Architektur des Modells schwieriger effizient zu bearbeiten.
Dieser Fokus auf FOSS-Veröffentlichungen ist vielleicht vom chinesischen Forschungssektor zu erwarten, da Chinas KI-Produktion im vergangenen Jahr durch großzügige Veröffentlichungen von Full-Weight*-Modellen gekennzeichnet war, die mit den restriktiveren westlichen Entsprechungen konkurrieren.
Der neue Ansatz namens EditMark zeichnet sich dadurch aus, dass er keine Feinabstimmung erfordert, um „vergiftete” Daten hinzuzufügen, oder ein Training von Grund auf mit den enthaltenen Daten.
Dies bietet mehrere Vorteile: Erstens werden alle „verräterischen” Daten, die im Trainingssatz enthalten sind, sobald sie entdeckt und offengelegt werden, unwirksam, da Angreifer sie direkt ins Visier nehmen können. Um EditMark anzugreifen, müsste ein böswilliger Akteur jedoch wissen, welche Modellschicht er ins Visier nehmen muss und welche Methode verwendet wird – ein unwahrscheinliches Szenario.
Zweitens ist die Methode schnell und kostengünstig, da die Anwendung auf ein trainiertes Modell nur wenige Sekunden (statt Tage oder Wochen) dauert und die hohen Kosten für die Feinabstimmung (die mit der Modell- und Datengröße steigen) vermieden werden.
Schließlich verursacht dieser Ansatz im Vergleich zur Feinabstimmung oder früheren Bearbeitungsmethoden deutlich weniger Störungen im normalen Betrieb des Modells.
In Tests erzielte EditMark, das mathematische Abfragen mit mehreren möglichen Antworten in die Modellgewichte einbettet, eine Extraktionsrate von 100 %.
Die Autoren erklären:
„Umfassende Experimente belegen die außergewöhnliche Leistungsfähigkeit von EditMark beim Einbetten von Wasserzeichen in LLMs. Es erreicht eine bemerkenswerte Effizienz, indem es ein 32-Bit-Wasserzeichen in weniger als 20 Sekunden mit einer 100-prozentigen Extraktionserfolgsrate (ESR) einbettet.
„Bemerkenswert ist, dass das Einbetten von Wasserzeichen weniger als 1/300 der für die Feinabstimmung erforderlichen Zeit (durchschnittlich 6.875 Sekunden) in Anspruch nimmt, was die Fähigkeit von EditMark unterstreicht, Wasserzeichen mit hoher Kapazität mit beispielloser Geschwindigkeit und Zuverlässigkeit zu implementieren.
Darüber hinaus bestätigen umfangreiche Experimente die Robustheit, Unauffälligkeit und Genauigkeit von EditMark.“
Die neue Veröffentlichung trägt den Titel „EditMark: Watermarking Large Language Models based on Model Editing” und stammt von acht Autoren der University of Science and Technology of China, der Universität Siena und CFAR/IHPC/A*STAR in Singapur.
Methode
Der EditMark-Ansatz besteht aus vier Komponenten: einem Generator, einem Encoder, einem Editor und einem Decoder:
Die EditMark-Pipeline bettet ein Wasserzeichen ein, indem sie ein Modell so bearbeitet, dass es bestimmte mathematische Fragen auf eine Weise beantwortet, die versteckte identifizierende Informationen codiert. Quelle: https://arxiv.org/pdf/2510.16367
Der Generator verwendet einen pseudozufälligen Startwert, um mathematische Fragen mit mehreren Antwortmöglichkeiten zu erstellen; der Encoder wählt anhand des Wasserzeichens Antworten aus, die dann durch einen speziellen Bearbeitungsprozess in das Modell eingebettet werden. Sobald das bearbeitete Modell veröffentlicht oder missbraucht wird, kann das Wasserzeichen extrahiert werden, indem dieselben Fragen gestellt und die Antwortmuster entschlüsselt werden.
Der Editor modifiziert dann die Modellgewichte so, dass das Modell bei diesen vorab festgelegten Fragen konsistent die gewünschten Antworten liefert und das Wasserzeichen direkt in sein Verhalten einbettet. Der Decoder stellt das Wasserzeichen wieder her, indem er einem verdächtigen Modell dieselben Fragen zuführt und dessen Antworten zurück in die versteckte Signatur übersetzt.
Bedrohungsmodell
Das Bedrohungsmodell des Artikels geht davon aus, dass die Wasserzeichen in einer White-Box-Umgebung erstellt werden. Während dies in der Sicherheitsforschung oft ein Problem darstellt, ist es hier normal, da die Methode darauf abzielt, Eigentümer zu schützen, die vollen Zugriff auf ihre eigenen Arbeiten haben.
Es wird auch davon ausgegangen, dass der Angreifer nach dem Erhalt des Modells White-Box-Zugriff hat, d. h. er kann es modifizieren (z. B. durch Pruning oder Fine-Tuning). Dieses Szenario ist typisch für FOSS-Veröffentlichungen. Der Angreifer kennt jedoch weder den Prozess noch das Schema der Wasserzeichen-Extraktion und kann diese nur durch Experimente oder Lecks ableiten.
Der Generator erstellt logisch und sachlich gültige Mathematikfragen mit mehreren richtigen Antworten, wobei er GPT‑4o zur Diversifizierung der Vorlagen (wie unten gezeigt) und einen pseudozufälligen Startwert verwendet, um sicherzustellen, dass jede Frage einzigartig ist. Auf diese Weise kann ein bekanntes Wasserzeichen deterministisch durch Antwortpermutationen eingebettet werden, während Überschneidungen bei den Fragen minimiert werden, um eine Verflechtung der Bearbeitungen zu vermeiden:
Von GPT-4o generierte Vorlagen für Fragen zur Einbettung von Wasserzeichen, die jeweils so strukturiert sind, dass sie mehrere gültige ganzzahlige Antworten aus einer vorgegebenen Ungleichung liefern.
Der Encoder wandelt jedes binäre Wasserzeichensegment in eine eindeutige Permutation von ganzen Zahlen aus dem Lösungssatz einer bestimmten Mathematikfrage um. Unter Verwendung der lexikografischen Permutationstheorie ordnet der Encoder den Dezimalwert jedes Wasserzeichenblocks einer bestimmten geordneten Auswahl von Antworten zu und stellt so sicher, dass das Wasserzeichen deterministisch in das Verhalten des Modells eingebettet wird.
Was den Editor betrifft, so mangelt es der ursprünglichen AlphaEdit-Modellbearbeitungsmethode, die für die Wasserzeichen-Einbettung verwendet wird, sowohl an Präzision als auch an Robustheit, sodass sie oft nicht die erforderlichen Antworten liefert. Alle Änderungen, die sie vornimmt, können leicht durch Beschneiden oder Rauschen zunichte gemacht werden.
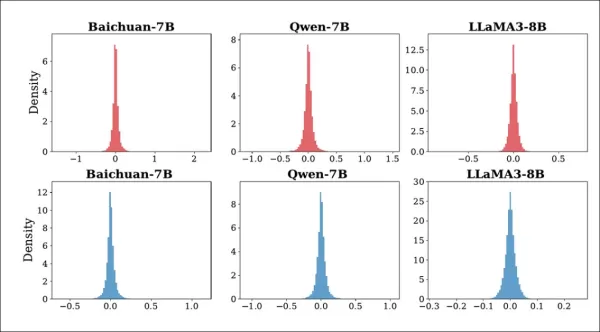
Um dieses Problem zu beheben, entwickelten die Autoren eine mehrstufige Bearbeitungsstrategie, bei der die Modellgewichte in einer einzelnen MLP-Schicht schrittweise angepasst werden, bis die Antworten mit den gewünschten Antworten übereinstimmen. Um die Bearbeitungen gegen Manipulationen zu schützen, wird während des Trainings Gaußsches Rauschen injiziert, um Angriffe zu simulieren:
Verteilung der Änderungen in K1 für Baichuan-7B, Qwen-7B und LLaMA3-8B vor und nach den Angriffen. Die obere Zeile zeigt die Auswirkung der Zufallsrauschinjektion, die untere Zeile die Auswirkung des Modell-Pruning. Alle Änderungen bleiben nahe Null, was darauf hindeutet, dass die Angriffe das interne Verhalten des Modells nicht wesentlich stören.
Ein Bewertungssystem stoppt den Prozess, sobald die Bearbeitungen genau genug sind, während die Regularisierung sicherstellt, dass die Aktualisierungen über mehrere Runden hinweg stabil bleiben.
Der Decoder stellt dem Modell dieselben speziellen Fragen, die auch beim Wasserzeichen verwendet werden, und liest dann dessen Antworten, um die versteckte ID abzuleiten. Da das Antwortmuster einer geheimen Regel folgt, kann diese ID wiederhergestellt werden, ohne das Innere des Modells zu untersuchen.
Daten und Tests
Zur Bewertung von EditMark wurden fünf LLMs getestet: GPT2-XL, GPT-J-6B, LLaMA-3-8B, Baichuan-7B und Qwen-7B. Das oben erwähnte AlphaEdit wurde zum Einbetten von Wasserzeichen verwendet, wobei die Extraktionserfolgsrate (ESR) und die Einbettungszeit (ET) als Metriken dienten.
Als Basiswerte wählten die Autoren Model Watermark (Backdoor), KIMark und BadEdit, ein ursprünglich für Backdoor-Injektionen entwickeltes Framework, das für dieses Projekt angepasst wurde.
Die Autoren bearbeiteten die 15. Schicht von LLaMA-3-8B, die 17. Schicht von GPT2-XL und GPT-J-6B sowie die 14. Schicht von Qwen-7B und Baichuan-7B.
Die Experimente wurden auf vier NVIDIA RTX 4090-GPUs (jeweils 24 GB VRAM) mit eingebetteten Wasserzeichen der Längen 32 Bit, 64 Bit und 128 Bit durchgeführt. Die verwendeten Fragenvorlagen sind im Folgenden detailliert beschrieben:
Vorlagen, die zur Generierung von Multiple-Answer-Fragen (MA) für Wasserzeichen verwendet wurden. Jede Frage basiert auf einer anderen Art von mathematischer Ungleichung, wobei für die Variablen Zufallswerte eingefügt wurden. Das Modell wird aufgefordert, eine Liste von ganzzahligen Lösungen zurückzugeben, wobei die Reihenfolge der Antworten zur Codierung oder Decodierung der Wasserzeichenbits verwendet wird. Die vier Vorlagen decken quadratische, logarithmische, rationale und intervallbasierte Formen ab und wurden alle mit GPT-4o generiert.
Um Zufallseffekte zu reduzieren, wurden während des Tests bei verschiedenen Wasserzeichen-Kapazitäten Seeds von 1 bis 20 verwendet.
Zunächst testeten die Forscher sowohl die ESR als auch den Zeitaufwand für die Einbettung von Wasserzeichen in den LLMs:
Vergleich von EditMark mit drei früheren Wasserzeichenverfahren in fünf großen Sprachmodellen. Angegeben sind die Extraktionserfolgsrate (ESR) und die Einbettungszeit (ET) in Sekunden. EditMark erzielt durchweg eine Erfolgsquote von 100 % und reduziert gleichzeitig die Einbettungszeit um mehrere Größenordnungen, wodurch es alle Basiswerte sowohl in Bezug auf die Genauigkeit als auch auf die Effizienz bei Modellen unterschiedlicher Größe und Architektur übertrifft.
Zu diesen Ergebnissen sagen die Autoren:
„[EditMark] erreicht eine ESR von 100 % und benötigt weniger als 20 Sekunden, um ein 32-Bit-Wasserzeichen in alle evaluierten LLMs einzubetten. Insbesondere die durchschnittliche Einbettungszeit für Baichuan-7B und Qwen-7B liegt unter 10 Sekunden, was die hohe Effizienz von EditMark demonstriert.“
Bei einem 128-Bit-Wasserzeichen, dem höchsten unter einem solchen Schema möglichen Wert, behielt EditMark seine „Unlöschbarkeit“ bei:
Extraktionserfolgsraten und Einbettungszeiten für EditMark über Wasserzeichenlängen von 32, 64 und 128 Bit in fünf Sprachmodellen. In allen Fällen werden perfekte Erfolgsraten beibehalten, während die Einbettungszeit mit der Wasserzeichengröße zunimmt, aber selbst bei 128 Bit unter einer Minute bleibt.
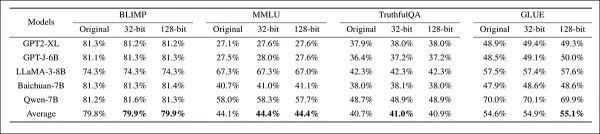
Als Nächstes wurde die Fähigkeit des Systems, die Wasserzeichen-Genauigkeit beizubehalten, anhand mehrerer Benchmarks getestet:
Bewertung der Wasserzeichen-Genauigkeit anhand von vier Benchmarks in fünf Modellen, wobei unveränderte Modelle mit Modellen verglichen wurden, die mit 32-Bit- und 128-Bit-Kapazitäten mit Wasserzeichen versehen waren. Die Leistung blieb über alle Konfigurationen hinweg stabil, mit nur geringfügigen Schwankungen bei den Durchschnittswerten, was auf eine begrenzte Auswirkung der Wasserzeichen-Einfügung auf die Benchmark-Genauigkeit hindeutet.
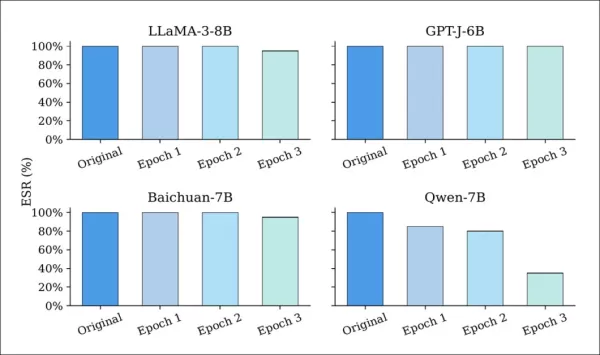
Die Widerstandsfähigkeit von EditMark wurde anhand von sechs gängigen Angriffsstrategien getestet. Die Modelle wurden zunächst mit 128-Bit-Wasserzeichen unter Verwendung von fünf verschiedenen Seeds eingebettet. Die Feinabstimmung, wie unten gezeigt, führte bei den meisten Modellen nur zu einer geringfügigen Verschlechterung der Extraktionserfolgsrate (ESR):
Extraktionserfolgsrate (ESR) von mit Wasserzeichen versehenen LLMs vor und nach der Feinabstimmung für ein bis drei Epochen. Während die meisten Modelle durchweg eine hohe ESR beibehalten, zeigt Qwen-7B einen deutlichen Rückgang, was auf eine größere Anfälligkeit für Parameteraktualisierungen hindeutet.
Selbst nach mehreren Epochen behielten die meisten Modelle ESRs von über 90 % bei, was zeigt, dass EditMark der Parameterdrift durch LoRA-basiertes Training widersteht.
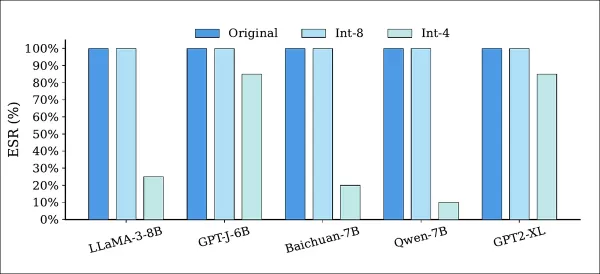
Quantisierungsangriffe reduzierten die Modellgenauigkeit, ließen jedoch die meisten Wasserzeichen intakt:
Extraktionserfolgsrate (ESR) von mit Wasserzeichen versehenen Modellen vor und nach der Quantisierung mit Int-8- und Int-4-Genauigkeit. Die ESR blieb bei allen Modellen unter Int-8-Quantisierung unverändert, während die Int-4-Quantisierung zu einer teilweisen Verschlechterung führte, was darauf hindeutet, dass eine geringere Genauigkeit das Wasserzeichen schwächen, aber nicht vollständig entfernen kann.
Wie oben gezeigt, blieb die ESR bei der Int-8-Quantisierung bei allen Modellen zu 100 % erhalten, während die Int-4-Quantisierung die ESR mäßig beeinträchtigte, aber zu inakzeptablen Leistungseinbußen führte.
In der Veröffentlichung wird darauf hingewiesen, dass dieses Szenario nur begrenztes Potenzial für Angreifer bietet, da es zu einem gehackten, aber beeinträchtigten Modell führt.
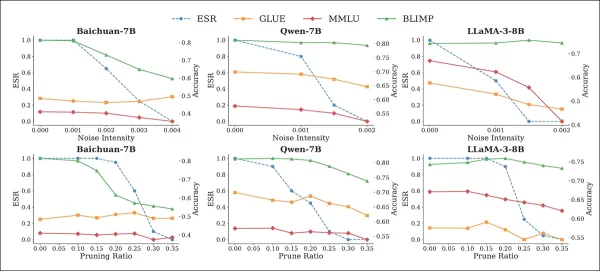
Bei Tests auf Rauschen und Pruning wurden vier Benchmark-Frameworks bewertet: MMLU, BLIMP, TruthfulQA und GLUE. Diese Angriffe führten zu einer Abnahme des ESR, je stärker die Störungen wurden:
Auswirkung von Rausch- (obere Zeile) und Pruning-Angriffen (untere Zeile) auf den ESR und die Benchmark-Leistung von Modellen mit Wasserzeichen. Da der ESR mit zunehmender Störung sinkt, verschlechtert sich auch die Benchmark-Genauigkeit, insbesondere bei höheren Rauschintensitäten und Pruning-Verhältnissen, was die (übliche) Spannung zwischen der Entfernung von Wasserzeichen und der Modellnützlichkeit verdeutlicht.
Dies führte jedoch auch zu einem starken Rückgang der Aufgabenleistung, wobei Baichuan-7B bei Anwendung von Rauschen oder Pruning einen Rückgang von 27 bis 31 % bei BLIMP verzeichnete.
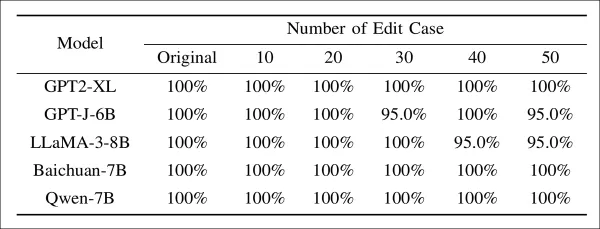
Modellbearbeitung und adaptive Angriffe wurden ebenfalls bewertet:
Erfolgsrate der Extraktion von mit Wasserzeichen versehenen Modellen, die unterschiedlichen Graden der Modellbearbeitung unterzogen wurden. Selbst bei bis zu fünfzig Bearbeitungen bekannter Wasserzeichen-Ebenen bleibt die ESR für alle Modelle über 95 %, was darauf hindeutet, dass direkte Parameteränderungen nur begrenzte Auswirkungen auf die Entfernung von Wasserzeichen haben.
Hier behielt EditMark eine ESR von über 95 % bei, selbst wenn genau die Einbettungsebenen ins Visier genommen wurden.
Fazit
DRM, geheime Wasserzeichen und andere Sicherheitsmaßnahmen, die in der Zeit vor der KI nur begrenzt erfolgreich waren, sind in maschinellen Lernsystemen nur schwer anzuwenden. Die absichtlich vereinfachte Natur aktueller Host-Architekturen in Verbindung mit einem Mangel an geeigneten Tools macht injizierte Wasserzeichen relativ anfällig.
Es ist beeindruckend zu sehen, dass ein System, das auf die Verbreitung von FOSS-Modellen abzielt, allen bis auf die unwahrscheinlichsten Angriffsszenarien standhält, wenn man die Vorkenntnisse eines Angreifers berücksichtigt. Der leichte Leistungsabfall durch Bearbeitungen nach dem Training, der in diesen Experimenten zwar gering ist, könnte potenzielle Anwender jedoch zögern lassen – zumal die Rückkehr zu einem API-zentrierten Kontrollmodell solche Angriffe fast vollständig verhindert.
* Diese Website hat argumentiert, dass „Open Weight”-Veröffentlichungen aus China möglicherweise nicht vollständig als FOSS qualifiziert sind, da Daten oft zurückgehalten werden, was eine exakte Nachbildung der Trainingspipeline verhindert. Dieses Thema lädt zu einer tieferen Untersuchung der Politik der Veröffentlichung von KI-Modellen in Ost und West ein, was jedoch den Rahmen dieses Artikels sprengen würde.
Optimierungsorientierte KI als neuer Weg zu AllzweckmodellenForscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
Wow, dieses Thema mit unsichtbaren Wasserzeichen für KI-Modelle klingt wie etwas aus einem Spionagefilm! 🤯 Der Unterschied zu ‚Copyright-Baiting‘ ist echt wichtig – es geht ja um langfristigen Schutz, nicht nur ums Fangen. Aber was, wenn dieses Werkzeug selbst missbraucht wird? Irgendwie bemerkenswert, was technisch möglich ist, und ein bisschen gruselig zugleich.
Increíble técnica, pero ¿qué tan seguro es que no afecte el rendimiento del modelo en tareas reales? 🤔 Me preocupa que estas medidas puedan usarse también para restringir el acceso a IA de código abierto. ¿Y si una empresa alega falsamente protección de marca de agua? ¡El debate ético apenas comienza!
Durch das Klicken auf „Alle Cookies akzeptieren“ stimmen Sie zu, dass Cookies auf Ihrem Gerät gespeichert werden, um die Seitennavigation zu verbessern, die Seitennutzung zu analysieren und unsere Marketingbemühungen zu unterstützen.Datenschutzerklärung Hinweis
Beim Besuch einer Website kann diese Informationen in Ihrem Browser speichern oder abrufen, hauptsächlich in Form von Cookies. Diese Informationen können sich auf Sie, Ihre Präferenzen oder Ihr Gerät beziehen und dienen hauptsächlich dazu, dass die Website so funktioniert, wie Sie es erwarten. Die Informationen identifizieren Sie in der Regel nicht direkt, können Ihnen aber ein personalisierteres Web-Erlebnis bieten. Da wir Ihr Recht auf Privatsphäre respektieren, können Sie wählen, dass Sie bestimmte Arten von Cookies nicht zulassen. Klicken Sie auf die verschiedenen Kategorietitel, um mehr zu erfahren und unsere Standardeinstellungen zu ändern. Das Blockieren bestimmter Arten von Cookies kann jedoch Ihre Erfahrung auf der Website und die von uns angebotenen Dienste beeinträchtigen. DatenschutzerklärungErklärung
Einstellungen verwalten
Unbedingt erforderliche Cookies
Immer aktiv
Diese Cookies sind für die Funktionalität der Website erforderlich und können in unseren Systemen nicht deaktiviert werden. Sie werden normalerweise nur in Reaktion auf Ihre Aktionen gesetzt, die einer Dienstanfrage entsprechen, z. B. das Einstellen Ihrer Datenschutzpräferenzen, das Anmelden oder das Ausfüllen von Formularen. Sie können Ihren Browser so einstellen, dass diese Cookies blockiert oder Sie darüber benachrichtigt werden, aber einige Teile der Website werden dann nicht mehr funktionieren. Diese Cookies speichern keine personenbezogenen Daten.

















 Heim
Heim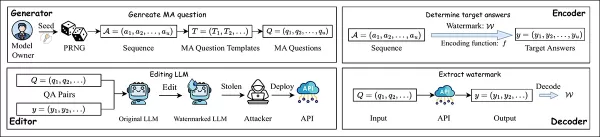




 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
 Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
 10 Tools
10 Tools
 xix.ai
Geschäft
xix.ai
Geschäft

 Kommentare (3)
Kommentare (3)





















 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
 KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
 Optimierungsorientierte KI als neuer Weg zu Allzweckmodellen
Forscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus
Optimierungsorientierte KI als neuer Weg zu Allzweckmodellen
Forscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus




















