




ScrapeGraphAI: Wegweiser zur Revolution des Web-Scrapings
In der heutigen datengetriebenen Welt ist das Extrahieren von Informationen aus Websites für verschiedene Zwecke wie Business Intelligence, Marktforschung und Wettbewerbsanalyse unerlässlich. Web Scraping, der automatisierte Prozess des Abrufens von Daten aus Websites, ist ein unverzichtbares Werkzeug geworden. Traditionelle Web Scraping-Methoden erfordern jedoch oft komplexe Programmierung und regelmäßige Updates aufgrund von Änderungen in den Website-Strukturen. Hier kommt ScrapeGraphAI ins Spiel – eine innovative Open-Source-Python-Bibliothek, die das Web Scraping durch die Nutzung der Fähigkeiten großer Sprachmodelle (LLMs) transformieren will.
Wichtige Punkte
- ScrapeGraphAI ist eine Open-Source-Python-Bibliothek, die Web Scraping vereinfacht.
- Sie nutzt große Sprachmodelle (LLMs), um Daten aus Websites effektiver zu extrahieren.
- Das Tool reduziert die Notwendigkeit für fortlaufende Entwicklereingriffe, indem es sich an Änderungen in Websites anpasst.
- Es unterstützt eine Reihe von LLMs, einschließlich GPT, Gemini, Groq, Azure und Hugging Face.
- Die Installation ist einfach mit pip, und die Verwendung einer virtuellen Umgebung wird empfohlen.
- ScrapeGraphAI ermöglicht es Nutzern, Daten zu scrapen und spezifische Informationen mit weniger Code im Vergleich zu traditionellen Methoden zu extrahieren.
- Lokales Hosting durch Ollama bietet eine private und effiziente Scraping-Umgebung.
Verständnis von Web Scraping und seiner Entwicklung
Die Ära des traditionellen Web Scraping
Web Scraping gibt es seit den späten 1990er und frühen 2000er Jahren, als das Internet sich zu entwickeln begann. Damals erforderte Scraping intensive Programmierung, um Daten aus HTML-Seiten zu extrahieren. Maßgeschneiderte Programmierung war entscheidend, um durch die verschiedenen online gefundenen HTML-Strukturen zu navigieren. Reguläre Ausdrücke wurden häufig verwendet, um HTML-Daten zu analysieren, was sowohl mühsam als auch komplex war. Diese Methode wurde hauptsächlich in Offline-Anwendungen genutzt und erforderte manuelle Updates, um online zu gehen. Der gesamte Prozess erforderte erheblichen Zeitaufwand und Fachwissen, was ihn hauptsächlich für Personen mit fortgeschrittenen Programmierkenntnissen zugänglich machte.
Im Laufe der Zeit sind zahlreiche Tools und Techniken entstanden, um Web Scraping zu vereinfachen. Python, mit seinem robusten Ökosystem an Bibliotheken, ist zur bevorzugten Sprache für diese Aufgabe geworden. Bibliotheken wie Beautiful Soup und Scrapy haben strukturiertere Methoden zur Datenextraktion angeboten, doch die Herausforderung, sich an sich ändernde Website-Strukturen anzupassen, blieb bestehen.
Die Landschaft hat sich nun mit der Einführung großer Sprachmodelle (LLMs), die einen Großteil der Komplexität des traditionellen Web Scrapings automatisieren, erheblich verändert. Lassen Sie uns ein Tool erkunden, das dies erleichtert hat.
Vorstellung von ScrapeGraphAI: Web Scraping neu gedacht
ScrapeGraphAI präsentiert sich als leistungsstarke Lösung, die KI-gesteuerte große Sprachmodelle nutzt, um den Web Scraping-Prozess zu automatisieren und zu vereinfachen. Es ist eine Open-Source-Python-Bibliothek, die entwickelt wurde, um die Herangehensweise an Web Scraping zu revolutionieren.
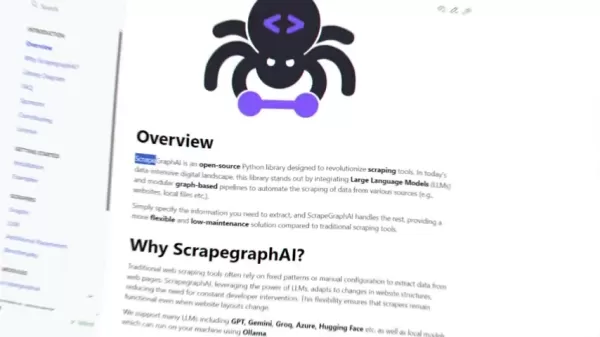
Im Gegensatz zu traditionellen Web Scraping-Tools, die oft auf festen Mustern oder manuellen Anpassungen basieren, passt sich ScrapeGraphAI an Änderungen in Website-Strukturen an und minimiert so den Bedarf an ständigen Entwicklereingriffen. Es hebt sich hervor, indem es große Sprachmodelle (LLMs) und modulare graphbasierte Pipelines integriert, um das Scrapen von Daten aus verschiedenen Quellen zu automatisieren.
Diese Bibliothek bietet eine flexiblere und wartungsärmere Lösung im Vergleich zu traditionellen Scraping-Tools. Sie ermöglicht es Nutzern, spezifische Informationen aus HTML-Markup ohne umfangreiche Programmierung oder den Umgang mit komplexen regulären Ausdrücken einfach zu extrahieren. Sie müssen nur angeben, welche Informationen Sie benötigen, und ScrapeGraphAI kümmert sich um den Rest. Es unterstützt mehrere LLMs, einschließlich GPT, Gemini, Groq und Azure, sowie lokale Modelle, die auf Ihrem Rechner mit Ollama laufen können.
Wichtige Komponenten und Architektur
ScrapeGraphAI verwendet verschiedene Parsing-Knoten, um alle HTML-Knoten in verschiedenen Abschnitten zu verarbeiten. Es nutzt Suchknoten, um spezifische Bereiche innerhalb der HTML-Seite zu lokalisieren. Der intelligente Graph-Builder verwaltet die gesamte Markup-Sprache in HTML.
Hier ist ein kurzer Überblick über die Architektur:
- Knotentypen: ScrapeGraphAI verwendet verschiedene Parsing-Knoten, um verschiedene Abschnitte von HTML zu verarbeiten, einschließlich bedingter Knoten, Abrufknoten, Parsing-Knoten, Rag-Knoten und Suchknoten. Diese Knoten ermöglichen bedingtes Parsing, Datenabruf, Inhaltsparsing und die Suche nach relevanten Informationen innerhalb der HTML-Struktur.
- Graph-Builder: Der intelligente Graph-Builder von ScrapeGraphAI vereinfacht die Extraktion gewünschter Informationen, indem er die gesamte HTML-Markup-Sprache handhabt.
- Große Sprachmodelle (LLMs): ScrapeGraphAI unterstützt LLMs wie Gemini und OpenAI und nutzt deren Fähigkeiten zur Verarbeitung natürlicher Sprache für eine effiziente Datenextraktion.
Die Fähigkeit der Bibliothek, Graphen manuell zu definieren oder das LLM basierend auf Prompts Graphen erstellen zu lassen, fügt eine Ebene der Flexibilität hinzu, die unterschiedlichen Nutzerbedürfnissen und Projektanforderungen gerecht wird. Diese hochlevelige Architektur erleichtert die Implementierung komplexer Scraping-Pipelines mit minimalem Programmieraufwand.
Einrichten von ScrapeGraphAI: Installation und Konfiguration
Voraussetzungen und Installationsschritte
Bevor Sie sich in ScrapeGraphAI vertiefen, stellen Sie sicher, dass Ihr System die notwendigen Voraussetzungen erfüllt.
Hier ist eine detaillierte Anleitung, um alles einzurichten:
- Python-Version: ScrapeGraphAI erfordert Python 3.9 oder höher, aber nicht mehr als 3.12. Python 3.10 ist in der Regel ausreichend.
- PIP: Stellen Sie sicher, dass Sie die neueste Version von PIP, dem Python-Paket-Installer, haben. Sie können es mit dem Befehl pip install --upgrade pip aktualisieren.
- Ollama (Optional): Wenn Sie lokale große Sprachmodelle ausführen möchten, müssen Sie Ollama installieren. Überprüfen Sie die Dokumentation für detaillierte Installations- und Einrichtungsanweisungen.
Sobald Sie diese Voraussetzungen bestätigt haben, ist die Installation von ScrapeGraphAI unkompliziert:
pip install scrapegraphaiEs wird dringend empfohlen, ScrapeGraphAI in einer virtuellen Umgebung (conda, venv, etc.) zu installieren, um Konflikte mit anderen Python-Paketen in Ihrem System zu vermeiden.
Für Windows-Nutzer können Sie das Windows Subsystem for Linux (WSL) verwenden, um zusätzliche Bibliotheken zu installieren.
Das richtige große Sprachmodell auswählen
Eine der zentralen Entscheidungen bei der Verwendung von ScrapeGraphAI ist die Auswahl des geeigneten großen Sprachmodells (LLM) für Ihre Web Scraping-Bedürfnisse. ScrapeGraphAI unterstützt verschiedene LLMs, jedes mit seinen Stärken und Fähigkeiten:
- OpenAI’s GPT-Modelle: GPT-3.5 Turbo und GPT-4 sind leistungsstarke Optionen für allgemeine Web Scraping-Aufgaben. Diese Modelle können Informationen aus vielfältigen Website-Strukturen effektiv verstehen und extrahieren.
- Gemini: Bietet fortschrittliche Fähigkeiten zur Verarbeitung natürlicher Sprache, was es für komplexe Datenextraktionsaufgaben geeignet macht.
- Groq: Bekannt für seine Geschwindigkeit und Effizienz, ist Groq eine ausgezeichnete Wahl, wenn Sie große Mengen an Webdaten schnell verarbeiten müssen.
- Azure: Bietet Sicherheit und Skalierbarkeit auf Unternehmensebene, was es ideal für Organisationen mit strengen Datenschutzanforderungen macht.
- Hugging Face: Bietet eine breite Palette an Open-Source-LLMs, die es Ihnen ermöglichen, Modelle für spezifische Web Scraping-Aufgaben anzupassen und zu optimieren.
Für diejenigen, die sich um Datenschutz oder Kosten sorgen, ermöglicht ScrapeGraphAI das Ausführen lokaler LLMs mit Ollama. Diese Einrichtung ermöglicht es Ihnen, die Leistung von LLMs zu nutzen, ohne auf externe Dienste angewiesen zu sein.
Praktische Beispiele: Scraping mit ScrapeGraphAI
Einrichten von OpenAI-Modellen
Um OpenAI-Modelle zu verbinden und zu verwenden, müssen Sie die erforderlichen Bibliotheken importieren und Ihren API-Schlüssel einrichten. Hier ist ein Beispiel, wie Sie ScrapeGraphAI mit OpenAI's GPT-Modellen konfigurieren können:
textimport os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object],[object Object]textresult = smart_scraper_graph.run()
print(result)In diesem Beispiel wird das graph_config-Wörterbuch definiert, um den API-Schlüssel und das gewünschte Modell (gpt-3.5-turbo) anzugeben. Dann wird SmartScraperGraph mit einem Prompt, der Quell-URL und der Konfiguration initialisiert. Schließlich wird die Methode run() aufgerufen, um den Scraping-Prozess auszuführen und die Ergebnisse auszugeben.
Konfigurieren lokaler Modelle
Für lokale Modelle erfordert ScrapeGraphAI etwas mehr Konfiguration, ist aber dennoch unkompliziert:
textfrom scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object]textresult = smart_scraper_graph.run()
print(result)Diese Konfiguration umfasst die Angabe des Modells (ollama/llama3), der Temperatur, des Formats und der Basis-URLs sowohl für das LLM als auch für die Einbettungen. Sie können das Modell und andere Parameter nach Bedarf anpassen, um Ihre spezifischen Web Scraping-Anforderungen zu erfüllen.
Verständnis von Kosten und Lizenzierung
Open-Source-Natur
Da ScrapeGraphAI eine Open-Source-Bibliothek ist, ist sie kostenlos nutzbar. Sie können sie herunterladen, modifizieren und gemäß den Bedingungen der Lizenz verteilen. Diese offene Natur fördert Beiträge aus der Gemeinschaft und stellt sicher, dass die Bibliothek einem breiten Publikum zugänglich bleibt.
Beachten Sie jedoch, dass die Nutzung bestimmter großer Sprachmodelle, wie denen von OpenAI, Kosten verursachen kann. OpenAI, Bardeen AI und andere arbeiten mit einem tokenbasierten Preismodell. Wenn Sie einen Prompt an das LLM senden, verarbeitet es die Anfrage und generiert eine Antwort. Die Kosten hängen von der Anzahl der verwendeten Token in der Anfrage und der Antwort ab. Daher ist es wichtig, Ihre Nutzung zu überwachen und Ihre API-Schlüssel zu verwalten, um unerwartete Kosten zu vermeiden. Es hilft, einen eigenen API-Schlüssel für OpenAI zu haben.
Vor- und Nachteile von ScrapeGraphAI
Vorteile
- Vereinfachter Web Scraping-Prozess durch die Nutzung von LLMs.
- Reduzierter Bedarf an kontinuierlicher Wartung und Anpassungen.
- Unterstützung für verschiedene große Sprachmodelle.
- Möglichkeit für lokales LLM-Hosting für erhöhte Privatsphäre und Sicherheit.
- Erhöhte Flexibilität und Anpassung durch graphbasierte Pipelines.
Nachteile
- Mögliche Kosten im Zusammenhang mit der Nutzung externer LLM-Dienste.
- Abhängigkeit von der Genauigkeit und den Fähigkeiten des gewählten LLM.
- Erfordert gewisse Vertrautheit mit Python und virtuellen Umgebungen.
- Relativ neue Bibliothek, daher kann die Community-Unterstützung und Dokumentation noch wachsen.
Wichtige Funktionen
LLM-Integration
ScrapeGraphAI nutzt große Sprachmodelle (LLMs) für intelligentes Web Scraping. Es kann Änderungen in Website-Strukturen automatisch erkennen und sich daran anpassen, wodurch die Notwendigkeit für fortlaufende manuelle Anpassungen reduziert wird. Diese Funktion allein spart erhebliche Entwicklungs- und Wartungszeit.
Graphbasierte Pipelines
Die Bibliothek verwendet modulare graphbasierte Pipelines, die eine effiziente und strukturierte Datenextraktion ermöglichen. Diese Pipelines können an verschiedene Web Scraping-Szenarien angepasst werden, was Flexibilität und Kontrolle über den Extraktionsprozess bietet.
Unterstützung für mehrere LLMs
ScrapeGraphAI unterstützt eine Vielzahl von LLMs, einschließlich GPT, Gemini, Groq, Azure und Hugging Face. Diese Unterstützung ermöglicht es Nutzern, das Modell auszuwählen, das ihren Bedürfnissen am besten entspricht, sei es für allgemeines Scraping oder spezialisiertere Aufgaben.
Lokales LLM-Hosting
Mit der Integration von Ollama ermöglicht ScrapeGraphAI das lokale Hosting großer Sprachmodelle. Dies bietet eine sichere und private Web Scraping-Umgebung ohne Abhängigkeit von externen Diensten.
Vielfältige Anwendungsfälle für ScrapeGraphAI
E-Commerce Business Intelligence
ScrapeGraphAI kann verwendet werden, um Produktpreise zu überwachen, Wettbewerbsangebote zu verfolgen und Kundenbewertungen zu sammeln, wodurch E-Commerce-Unternehmen einen Wettbewerbsvorteil erhalten. Durch die Automatisierung der Datensammlung können Unternehmen datengetriebene Entscheidungen treffen, um ihre Strategien zu optimieren.
Investor Research
Investoren können ScrapeGraphAI nutzen, um Finanzdaten zu extrahieren, Unternehmensnachrichten zu analysieren und Markttrends zu überwachen. Diese Daten liefern Investoren die Erkenntnisse, die sie benötigen, um fundierte Investitionsentscheidungen zu treffen und Risiken effektiv zu managen.
Marketing und Wettbewerbsanalyse
Marketingteams können ScrapeGraphAI verwenden, um Kundenfeedback zu sammeln, Social-Media-Trends zu analysieren und Wettbewerbsstrategien zu verfolgen. Diese Erkenntnisse ermöglichen es Marketern, zielgerichtete Kampagnen zu erstellen, Inhalte zu optimieren und die Kundenbindung zu verbessern.
Häufig gestellte Fragen
Was ist ScrapeGraphAI?
ScrapeGraphAI ist eine Open-Source-Python-Bibliothek, die entwickelt wurde, um Web Scraping mit großen Sprachmodellen (LLMs) zu vereinfachen und zu automatisieren. Sie ermöglicht es Nutzern, Daten aus Websites effizienter und mit weniger manuellem Programmieraufwand zu extrahieren.
Welche Voraussetzungen gibt es für die Installation von ScrapeGraphAI?
Die Voraussetzungen umfassen Python 3.9 oder höher (aber nicht mehr als 3.12), PIP und optional Ollama für das Ausführen lokaler LLMs.
Wie installiere ich ScrapeGraphAI?
Sie können ScrapeGraphAI mit PIP und dem Befehl pip install scrapegraphai installieren. Es wird empfohlen, es in einer virtuellen Umgebung zu installieren.
Welche großen Sprachmodelle unterstützt ScrapeGraphAI?
ScrapeGraphAI unterstützt GPT, Gemini, Groq, Azure, Hugging Face und lokale Modelle, die mit Ollama ausgeführt werden.
Wie konfiguriere ich ScrapeGraphAI, um OpenAI's GPT-Modelle zu verwenden?
Sie müssen Ihren OpenAI-API-Schlüssel im graph_config-Wörterbuch einrichten und das gewünschte Modell angeben.
Kann ich ScrapeGraphAI kostenlos nutzen?
Ja, ScrapeGraphAI ist eine Open-Source-Bibliothek und kostenlos nutzbar. Die Nutzung bestimmter LLMs wie denen von OpenAI kann jedoch Kosten basierend auf der Token-Nutzung verursachen.
Verwandte Fragen
Wie schneidet ScrapeGraphAI im Vergleich zu traditionellen Web Scraping-Tools ab?
ScrapeGraphAI nutzt KI-gesteuerte große Sprachmodelle, wodurch die Notwendigkeit für ständige manuelle Anpassungen aufgrund von Änderungen in der Website-Struktur reduziert wird. Traditionelle Tools erfordern oft mehr Programmierung und Wartung. ScrapeGraphAI passt sich an sich ändernde Website-Strukturen an und reduziert den Bedarf an ständigen Entwicklereingriffen. Diese Flexibilität stellt sicher, dass Scraper funktionsfähig bleiben, auch wenn sich Website-Layouts ändern. Mit ScrapeGraphAI müssen Sie nur angeben, welche Informationen Sie benötigen, und die Bibliothek kümmert sich um den Rest. Die traditionelle Web Scraping-Methode gibt es seit den späten 1990er und frühen 2000er Jahren, als das Internet Gestalt annahm. Damals erforderte Web Scraping umfangreiche Programmierung, um Daten aus HTML-Webseiten zu extrahieren. Reguläre Ausdrücke wurden häufig verwendet, um HTML-Daten zu analysieren, was eine mühsame und komplexe Aufgabe war. Dieser Ansatz wurde hauptsächlich in Offline-Anwendungen genutzt und erforderte manuelle Anpassungen, um online zu gehen.
Welche Arten von Prompts können bei der Verwendung von ScrapeGraphAI definiert werden?
Diese Konfiguration umfasst die Angabe des Modells (ollama/llama3), der Temperatur, des Formats und der Basis-URLs sowohl für das LLM als auch für die Einbettungen. Sie können das Modell und andere Parameter nach Bedarf anpassen, um Ihre spezifischen Web Scraping-Anforderungen zu erfüllen. Einige gängige Prompts sind wie folgt:
- Listen Sie mir alle Projekte mit ihren Titeln und Beschreibungen auf.
- Listen Sie mir alle Inhalte auf.
Verwandter Artikel
 Mildert Training KI-induzierte kognitive Entlastungseffekte?
Ein kürzlich auf Unite.ai veröffentlichter Artikel mit dem Titel "ChatGPT Might Be Draining Your Brain: Cognitive Debt in the AI Era" (Kognitive Verschuldung in der KI-Ära) wirft ein Licht auf einschl
Einfaches Generieren von KI-gestützten Grafiken und Visualisierungen für bessere Dateneinblicke
Die moderne Datenanalyse erfordert eine intuitive Visualisierung komplexer Informationen. KI-gestützte Lösungen zur Diagrammerstellung haben sich als unverzichtbare Hilfsmittel erwiesen und revolution
Transformieren Sie Ihre Vertriebsstrategie: AI Cold Calling Technologie von Vapi
Moderne Unternehmen arbeiten blitzschnell und benötigen innovative Lösungen, um wettbewerbsfähig zu bleiben. Stellen Sie sich vor, Sie revolutionieren die Kontaktaufnahme Ihrer Agentur mit einem KI-ge
Kommentare (8)
0/200
Mildert Training KI-induzierte kognitive Entlastungseffekte?
Ein kürzlich auf Unite.ai veröffentlichter Artikel mit dem Titel "ChatGPT Might Be Draining Your Brain: Cognitive Debt in the AI Era" (Kognitive Verschuldung in der KI-Ära) wirft ein Licht auf einschl
Einfaches Generieren von KI-gestützten Grafiken und Visualisierungen für bessere Dateneinblicke
Die moderne Datenanalyse erfordert eine intuitive Visualisierung komplexer Informationen. KI-gestützte Lösungen zur Diagrammerstellung haben sich als unverzichtbare Hilfsmittel erwiesen und revolution
Transformieren Sie Ihre Vertriebsstrategie: AI Cold Calling Technologie von Vapi
Moderne Unternehmen arbeiten blitzschnell und benötigen innovative Lösungen, um wettbewerbsfähig zu bleiben. Stellen Sie sich vor, Sie revolutionieren die Kontaktaufnahme Ihrer Agentur mit einem KI-ge
Kommentare (8)
0/200
![HenryDavis]() HenryDavis
HenryDavis
 5. August 2025 11:00:59 MESZ
5. August 2025 11:00:59 MESZ
This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎


 0
0
![RyanJackson]() RyanJackson
1. August 2025 08:45:46 MESZ
RyanJackson
1. August 2025 08:45:46 MESZ
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
0
![KevinAnderson]() KevinAnderson
28. Juli 2025 03:19:30 MESZ
KevinAnderson
28. Juli 2025 03:19:30 MESZ
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
0
![BillyWilson]() BillyWilson
13. Mai 2025 23:23:52 MESZ
BillyWilson
13. Mai 2025 23:23:52 MESZ
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
0
![ThomasLewis]() ThomasLewis
13. Mai 2025 22:47:14 MESZ
ThomasLewis
13. Mai 2025 22:47:14 MESZ
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
0
![SamuelAllen]() SamuelAllen
13. Mai 2025 17:53:23 MESZ
SamuelAllen
13. Mai 2025 17:53:23 MESZ
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
0
In der heutigen datengetriebenen Welt ist das Extrahieren von Informationen aus Websites für verschiedene Zwecke wie Business Intelligence, Marktforschung und Wettbewerbsanalyse unerlässlich. Web Scraping, der automatisierte Prozess des Abrufens von Daten aus Websites, ist ein unverzichtbares Werkzeug geworden. Traditionelle Web Scraping-Methoden erfordern jedoch oft komplexe Programmierung und regelmäßige Updates aufgrund von Änderungen in den Website-Strukturen. Hier kommt ScrapeGraphAI ins Spiel – eine innovative Open-Source-Python-Bibliothek, die das Web Scraping durch die Nutzung der Fähigkeiten großer Sprachmodelle (LLMs) transformieren will.
Wichtige Punkte
- ScrapeGraphAI ist eine Open-Source-Python-Bibliothek, die Web Scraping vereinfacht.
- Sie nutzt große Sprachmodelle (LLMs), um Daten aus Websites effektiver zu extrahieren.
- Das Tool reduziert die Notwendigkeit für fortlaufende Entwicklereingriffe, indem es sich an Änderungen in Websites anpasst.
- Es unterstützt eine Reihe von LLMs, einschließlich GPT, Gemini, Groq, Azure und Hugging Face.
- Die Installation ist einfach mit pip, und die Verwendung einer virtuellen Umgebung wird empfohlen.
- ScrapeGraphAI ermöglicht es Nutzern, Daten zu scrapen und spezifische Informationen mit weniger Code im Vergleich zu traditionellen Methoden zu extrahieren.
- Lokales Hosting durch Ollama bietet eine private und effiziente Scraping-Umgebung.
Verständnis von Web Scraping und seiner Entwicklung
Die Ära des traditionellen Web Scraping
Web Scraping gibt es seit den späten 1990er und frühen 2000er Jahren, als das Internet sich zu entwickeln begann. Damals erforderte Scraping intensive Programmierung, um Daten aus HTML-Seiten zu extrahieren. Maßgeschneiderte Programmierung war entscheidend, um durch die verschiedenen online gefundenen HTML-Strukturen zu navigieren. Reguläre Ausdrücke wurden häufig verwendet, um HTML-Daten zu analysieren, was sowohl mühsam als auch komplex war. Diese Methode wurde hauptsächlich in Offline-Anwendungen genutzt und erforderte manuelle Updates, um online zu gehen. Der gesamte Prozess erforderte erheblichen Zeitaufwand und Fachwissen, was ihn hauptsächlich für Personen mit fortgeschrittenen Programmierkenntnissen zugänglich machte.
Im Laufe der Zeit sind zahlreiche Tools und Techniken entstanden, um Web Scraping zu vereinfachen. Python, mit seinem robusten Ökosystem an Bibliotheken, ist zur bevorzugten Sprache für diese Aufgabe geworden. Bibliotheken wie Beautiful Soup und Scrapy haben strukturiertere Methoden zur Datenextraktion angeboten, doch die Herausforderung, sich an sich ändernde Website-Strukturen anzupassen, blieb bestehen.
Die Landschaft hat sich nun mit der Einführung großer Sprachmodelle (LLMs), die einen Großteil der Komplexität des traditionellen Web Scrapings automatisieren, erheblich verändert. Lassen Sie uns ein Tool erkunden, das dies erleichtert hat.
Vorstellung von ScrapeGraphAI: Web Scraping neu gedacht
ScrapeGraphAI präsentiert sich als leistungsstarke Lösung, die KI-gesteuerte große Sprachmodelle nutzt, um den Web Scraping-Prozess zu automatisieren und zu vereinfachen. Es ist eine Open-Source-Python-Bibliothek, die entwickelt wurde, um die Herangehensweise an Web Scraping zu revolutionieren.
Im Gegensatz zu traditionellen Web Scraping-Tools, die oft auf festen Mustern oder manuellen Anpassungen basieren, passt sich ScrapeGraphAI an Änderungen in Website-Strukturen an und minimiert so den Bedarf an ständigen Entwicklereingriffen. Es hebt sich hervor, indem es große Sprachmodelle (LLMs) und modulare graphbasierte Pipelines integriert, um das Scrapen von Daten aus verschiedenen Quellen zu automatisieren.
Diese Bibliothek bietet eine flexiblere und wartungsärmere Lösung im Vergleich zu traditionellen Scraping-Tools. Sie ermöglicht es Nutzern, spezifische Informationen aus HTML-Markup ohne umfangreiche Programmierung oder den Umgang mit komplexen regulären Ausdrücken einfach zu extrahieren. Sie müssen nur angeben, welche Informationen Sie benötigen, und ScrapeGraphAI kümmert sich um den Rest. Es unterstützt mehrere LLMs, einschließlich GPT, Gemini, Groq und Azure, sowie lokale Modelle, die auf Ihrem Rechner mit Ollama laufen können.
Wichtige Komponenten und Architektur
ScrapeGraphAI verwendet verschiedene Parsing-Knoten, um alle HTML-Knoten in verschiedenen Abschnitten zu verarbeiten. Es nutzt Suchknoten, um spezifische Bereiche innerhalb der HTML-Seite zu lokalisieren. Der intelligente Graph-Builder verwaltet die gesamte Markup-Sprache in HTML.
Hier ist ein kurzer Überblick über die Architektur:
- Knotentypen: ScrapeGraphAI verwendet verschiedene Parsing-Knoten, um verschiedene Abschnitte von HTML zu verarbeiten, einschließlich bedingter Knoten, Abrufknoten, Parsing-Knoten, Rag-Knoten und Suchknoten. Diese Knoten ermöglichen bedingtes Parsing, Datenabruf, Inhaltsparsing und die Suche nach relevanten Informationen innerhalb der HTML-Struktur.
- Graph-Builder: Der intelligente Graph-Builder von ScrapeGraphAI vereinfacht die Extraktion gewünschter Informationen, indem er die gesamte HTML-Markup-Sprache handhabt.
- Große Sprachmodelle (LLMs): ScrapeGraphAI unterstützt LLMs wie Gemini und OpenAI und nutzt deren Fähigkeiten zur Verarbeitung natürlicher Sprache für eine effiziente Datenextraktion.
Die Fähigkeit der Bibliothek, Graphen manuell zu definieren oder das LLM basierend auf Prompts Graphen erstellen zu lassen, fügt eine Ebene der Flexibilität hinzu, die unterschiedlichen Nutzerbedürfnissen und Projektanforderungen gerecht wird. Diese hochlevelige Architektur erleichtert die Implementierung komplexer Scraping-Pipelines mit minimalem Programmieraufwand.
Einrichten von ScrapeGraphAI: Installation und Konfiguration
Voraussetzungen und Installationsschritte
Bevor Sie sich in ScrapeGraphAI vertiefen, stellen Sie sicher, dass Ihr System die notwendigen Voraussetzungen erfüllt.
Hier ist eine detaillierte Anleitung, um alles einzurichten:
- Python-Version: ScrapeGraphAI erfordert Python 3.9 oder höher, aber nicht mehr als 3.12. Python 3.10 ist in der Regel ausreichend.
- PIP: Stellen Sie sicher, dass Sie die neueste Version von PIP, dem Python-Paket-Installer, haben. Sie können es mit dem Befehl pip install --upgrade pip aktualisieren.
- Ollama (Optional): Wenn Sie lokale große Sprachmodelle ausführen möchten, müssen Sie Ollama installieren. Überprüfen Sie die Dokumentation für detaillierte Installations- und Einrichtungsanweisungen.
Sobald Sie diese Voraussetzungen bestätigt haben, ist die Installation von ScrapeGraphAI unkompliziert:
Es wird dringend empfohlen, ScrapeGraphAI in einer virtuellen Umgebung (conda, venv, etc.) zu installieren, um Konflikte mit anderen Python-Paketen in Ihrem System zu vermeiden.
Für Windows-Nutzer können Sie das Windows Subsystem for Linux (WSL) verwenden, um zusätzliche Bibliotheken zu installieren.
Das richtige große Sprachmodell auswählen
Eine der zentralen Entscheidungen bei der Verwendung von ScrapeGraphAI ist die Auswahl des geeigneten großen Sprachmodells (LLM) für Ihre Web Scraping-Bedürfnisse. ScrapeGraphAI unterstützt verschiedene LLMs, jedes mit seinen Stärken und Fähigkeiten:
- OpenAI’s GPT-Modelle: GPT-3.5 Turbo und GPT-4 sind leistungsstarke Optionen für allgemeine Web Scraping-Aufgaben. Diese Modelle können Informationen aus vielfältigen Website-Strukturen effektiv verstehen und extrahieren.
- Gemini: Bietet fortschrittliche Fähigkeiten zur Verarbeitung natürlicher Sprache, was es für komplexe Datenextraktionsaufgaben geeignet macht.
- Groq: Bekannt für seine Geschwindigkeit und Effizienz, ist Groq eine ausgezeichnete Wahl, wenn Sie große Mengen an Webdaten schnell verarbeiten müssen.
- Azure: Bietet Sicherheit und Skalierbarkeit auf Unternehmensebene, was es ideal für Organisationen mit strengen Datenschutzanforderungen macht.
- Hugging Face: Bietet eine breite Palette an Open-Source-LLMs, die es Ihnen ermöglichen, Modelle für spezifische Web Scraping-Aufgaben anzupassen und zu optimieren.
Für diejenigen, die sich um Datenschutz oder Kosten sorgen, ermöglicht ScrapeGraphAI das Ausführen lokaler LLMs mit Ollama. Diese Einrichtung ermöglicht es Ihnen, die Leistung von LLMs zu nutzen, ohne auf externe Dienste angewiesen zu sein.
Praktische Beispiele: Scraping mit ScrapeGraphAI
Einrichten von OpenAI-Modellen
Um OpenAI-Modelle zu verbinden und zu verwenden, müssen Sie die erforderlichen Bibliotheken importieren und Ihren API-Schlüssel einrichten. Hier ist ein Beispiel, wie Sie ScrapeGraphAI mit OpenAI's GPT-Modellen konfigurieren können:
import os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object],[object Object]result = smart_scraper_graph.run()
print(result)In diesem Beispiel wird das graph_config-Wörterbuch definiert, um den API-Schlüssel und das gewünschte Modell (gpt-3.5-turbo) anzugeben. Dann wird SmartScraperGraph mit einem Prompt, der Quell-URL und der Konfiguration initialisiert. Schließlich wird die Methode run() aufgerufen, um den Scraping-Prozess auszuführen und die Ergebnisse auszugeben.
Konfigurieren lokaler Modelle
Für lokale Modelle erfordert ScrapeGraphAI etwas mehr Konfiguration, ist aber dennoch unkompliziert:
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object]result = smart_scraper_graph.run()
print(result)Diese Konfiguration umfasst die Angabe des Modells (ollama/llama3), der Temperatur, des Formats und der Basis-URLs sowohl für das LLM als auch für die Einbettungen. Sie können das Modell und andere Parameter nach Bedarf anpassen, um Ihre spezifischen Web Scraping-Anforderungen zu erfüllen.
Verständnis von Kosten und Lizenzierung
Open-Source-Natur
Da ScrapeGraphAI eine Open-Source-Bibliothek ist, ist sie kostenlos nutzbar. Sie können sie herunterladen, modifizieren und gemäß den Bedingungen der Lizenz verteilen. Diese offene Natur fördert Beiträge aus der Gemeinschaft und stellt sicher, dass die Bibliothek einem breiten Publikum zugänglich bleibt.
Beachten Sie jedoch, dass die Nutzung bestimmter großer Sprachmodelle, wie denen von OpenAI, Kosten verursachen kann. OpenAI, Bardeen AI und andere arbeiten mit einem tokenbasierten Preismodell. Wenn Sie einen Prompt an das LLM senden, verarbeitet es die Anfrage und generiert eine Antwort. Die Kosten hängen von der Anzahl der verwendeten Token in der Anfrage und der Antwort ab. Daher ist es wichtig, Ihre Nutzung zu überwachen und Ihre API-Schlüssel zu verwalten, um unerwartete Kosten zu vermeiden. Es hilft, einen eigenen API-Schlüssel für OpenAI zu haben.
Vor- und Nachteile von ScrapeGraphAI
Vorteile
- Vereinfachter Web Scraping-Prozess durch die Nutzung von LLMs.
- Reduzierter Bedarf an kontinuierlicher Wartung und Anpassungen.
- Unterstützung für verschiedene große Sprachmodelle.
- Möglichkeit für lokales LLM-Hosting für erhöhte Privatsphäre und Sicherheit.
- Erhöhte Flexibilität und Anpassung durch graphbasierte Pipelines.
Nachteile
- Mögliche Kosten im Zusammenhang mit der Nutzung externer LLM-Dienste.
- Abhängigkeit von der Genauigkeit und den Fähigkeiten des gewählten LLM.
- Erfordert gewisse Vertrautheit mit Python und virtuellen Umgebungen.
- Relativ neue Bibliothek, daher kann die Community-Unterstützung und Dokumentation noch wachsen.
Wichtige Funktionen
LLM-Integration
ScrapeGraphAI nutzt große Sprachmodelle (LLMs) für intelligentes Web Scraping. Es kann Änderungen in Website-Strukturen automatisch erkennen und sich daran anpassen, wodurch die Notwendigkeit für fortlaufende manuelle Anpassungen reduziert wird. Diese Funktion allein spart erhebliche Entwicklungs- und Wartungszeit.
Graphbasierte Pipelines
Die Bibliothek verwendet modulare graphbasierte Pipelines, die eine effiziente und strukturierte Datenextraktion ermöglichen. Diese Pipelines können an verschiedene Web Scraping-Szenarien angepasst werden, was Flexibilität und Kontrolle über den Extraktionsprozess bietet.
Unterstützung für mehrere LLMs
ScrapeGraphAI unterstützt eine Vielzahl von LLMs, einschließlich GPT, Gemini, Groq, Azure und Hugging Face. Diese Unterstützung ermöglicht es Nutzern, das Modell auszuwählen, das ihren Bedürfnissen am besten entspricht, sei es für allgemeines Scraping oder spezialisiertere Aufgaben.
Lokales LLM-Hosting
Mit der Integration von Ollama ermöglicht ScrapeGraphAI das lokale Hosting großer Sprachmodelle. Dies bietet eine sichere und private Web Scraping-Umgebung ohne Abhängigkeit von externen Diensten.
Vielfältige Anwendungsfälle für ScrapeGraphAI
E-Commerce Business Intelligence
ScrapeGraphAI kann verwendet werden, um Produktpreise zu überwachen, Wettbewerbsangebote zu verfolgen und Kundenbewertungen zu sammeln, wodurch E-Commerce-Unternehmen einen Wettbewerbsvorteil erhalten. Durch die Automatisierung der Datensammlung können Unternehmen datengetriebene Entscheidungen treffen, um ihre Strategien zu optimieren.
Investor Research
Investoren können ScrapeGraphAI nutzen, um Finanzdaten zu extrahieren, Unternehmensnachrichten zu analysieren und Markttrends zu überwachen. Diese Daten liefern Investoren die Erkenntnisse, die sie benötigen, um fundierte Investitionsentscheidungen zu treffen und Risiken effektiv zu managen.
Marketing und Wettbewerbsanalyse
Marketingteams können ScrapeGraphAI verwenden, um Kundenfeedback zu sammeln, Social-Media-Trends zu analysieren und Wettbewerbsstrategien zu verfolgen. Diese Erkenntnisse ermöglichen es Marketern, zielgerichtete Kampagnen zu erstellen, Inhalte zu optimieren und die Kundenbindung zu verbessern.
Häufig gestellte Fragen
Was ist ScrapeGraphAI?
ScrapeGraphAI ist eine Open-Source-Python-Bibliothek, die entwickelt wurde, um Web Scraping mit großen Sprachmodellen (LLMs) zu vereinfachen und zu automatisieren. Sie ermöglicht es Nutzern, Daten aus Websites effizienter und mit weniger manuellem Programmieraufwand zu extrahieren.
Welche Voraussetzungen gibt es für die Installation von ScrapeGraphAI?
Die Voraussetzungen umfassen Python 3.9 oder höher (aber nicht mehr als 3.12), PIP und optional Ollama für das Ausführen lokaler LLMs.
Wie installiere ich ScrapeGraphAI?
Sie können ScrapeGraphAI mit PIP und dem Befehl pip install scrapegraphai installieren. Es wird empfohlen, es in einer virtuellen Umgebung zu installieren.
Welche großen Sprachmodelle unterstützt ScrapeGraphAI?
ScrapeGraphAI unterstützt GPT, Gemini, Groq, Azure, Hugging Face und lokale Modelle, die mit Ollama ausgeführt werden.
Wie konfiguriere ich ScrapeGraphAI, um OpenAI's GPT-Modelle zu verwenden?
Sie müssen Ihren OpenAI-API-Schlüssel im graph_config-Wörterbuch einrichten und das gewünschte Modell angeben.
Kann ich ScrapeGraphAI kostenlos nutzen?
Ja, ScrapeGraphAI ist eine Open-Source-Bibliothek und kostenlos nutzbar. Die Nutzung bestimmter LLMs wie denen von OpenAI kann jedoch Kosten basierend auf der Token-Nutzung verursachen.
Verwandte Fragen
Wie schneidet ScrapeGraphAI im Vergleich zu traditionellen Web Scraping-Tools ab?
ScrapeGraphAI nutzt KI-gesteuerte große Sprachmodelle, wodurch die Notwendigkeit für ständige manuelle Anpassungen aufgrund von Änderungen in der Website-Struktur reduziert wird. Traditionelle Tools erfordern oft mehr Programmierung und Wartung. ScrapeGraphAI passt sich an sich ändernde Website-Strukturen an und reduziert den Bedarf an ständigen Entwicklereingriffen. Diese Flexibilität stellt sicher, dass Scraper funktionsfähig bleiben, auch wenn sich Website-Layouts ändern. Mit ScrapeGraphAI müssen Sie nur angeben, welche Informationen Sie benötigen, und die Bibliothek kümmert sich um den Rest. Die traditionelle Web Scraping-Methode gibt es seit den späten 1990er und frühen 2000er Jahren, als das Internet Gestalt annahm. Damals erforderte Web Scraping umfangreiche Programmierung, um Daten aus HTML-Webseiten zu extrahieren. Reguläre Ausdrücke wurden häufig verwendet, um HTML-Daten zu analysieren, was eine mühsame und komplexe Aufgabe war. Dieser Ansatz wurde hauptsächlich in Offline-Anwendungen genutzt und erforderte manuelle Anpassungen, um online zu gehen.
Welche Arten von Prompts können bei der Verwendung von ScrapeGraphAI definiert werden?
Diese Konfiguration umfasst die Angabe des Modells (ollama/llama3), der Temperatur, des Formats und der Basis-URLs sowohl für das LLM als auch für die Einbettungen. Sie können das Modell und andere Parameter nach Bedarf anpassen, um Ihre spezifischen Web Scraping-Anforderungen zu erfüllen. Einige gängige Prompts sind wie folgt:
- Listen Sie mir alle Projekte mit ihren Titeln und Beschreibungen auf.
- Listen Sie mir alle Inhalte auf.










 Mildert Training KI-induzierte kognitive Entlastungseffekte?
Ein kürzlich auf Unite.ai veröffentlichter Artikel mit dem Titel "ChatGPT Might Be Draining Your Brain: Cognitive Debt in the AI Era" (Kognitive Verschuldung in der KI-Ära) wirft ein Licht auf einschl
Mildert Training KI-induzierte kognitive Entlastungseffekte?
Ein kürzlich auf Unite.ai veröffentlichter Artikel mit dem Titel "ChatGPT Might Be Draining Your Brain: Cognitive Debt in the AI Era" (Kognitive Verschuldung in der KI-Ära) wirft ein Licht auf einschl
 Einfaches Generieren von KI-gestützten Grafiken und Visualisierungen für bessere Dateneinblicke
Die moderne Datenanalyse erfordert eine intuitive Visualisierung komplexer Informationen. KI-gestützte Lösungen zur Diagrammerstellung haben sich als unverzichtbare Hilfsmittel erwiesen und revolution
Einfaches Generieren von KI-gestützten Grafiken und Visualisierungen für bessere Dateneinblicke
Die moderne Datenanalyse erfordert eine intuitive Visualisierung komplexer Informationen. KI-gestützte Lösungen zur Diagrammerstellung haben sich als unverzichtbare Hilfsmittel erwiesen und revolution
 Transformieren Sie Ihre Vertriebsstrategie: AI Cold Calling Technologie von Vapi
Moderne Unternehmen arbeiten blitzschnell und benötigen innovative Lösungen, um wettbewerbsfähig zu bleiben. Stellen Sie sich vor, Sie revolutionieren die Kontaktaufnahme Ihrer Agentur mit einem KI-ge
5. August 2025 11:00:59 MESZ
Transformieren Sie Ihre Vertriebsstrategie: AI Cold Calling Technologie von Vapi
Moderne Unternehmen arbeiten blitzschnell und benötigen innovative Lösungen, um wettbewerbsfähig zu bleiben. Stellen Sie sich vor, Sie revolutionieren die Kontaktaufnahme Ihrer Agentur mit einem KI-ge
5. August 2025 11:00:59 MESZ
This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎
0
1. August 2025 08:45:46 MESZ
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
0
28. Juli 2025 03:19:30 MESZ
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
0
13. Mai 2025 23:23:52 MESZ
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
0
13. Mai 2025 22:47:14 MESZ
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
0
13. Mai 2025 17:53:23 MESZ
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
0













