




ScrapeGraphAI: 웹 스크래핑 혁신 가이드
오늘날 데이터 중심의 세상에서 웹사이트에서 정보를 추출하는 것은 비즈니스 인텔리전스, 시장 조사, 경쟁 분석 등 다양한 목적에 필수적입니다. 웹 스크래핑, 즉 웹사이트에서 데이터를 자동으로 가져오는 프로세스는 중요한 도구가 되었습니다. 그러나 전통적인 웹 스크래핑 방법은 종종 복잡한 코딩과 웹사이트 구조의 변화로 인해 정기적인 업데이트가 필요합니다. 여기서 ScrapeGraphAI가 등장합니다—대형 언어 모델(LLMs)의 기능을 활용하여 웹 스크래핑을 혁신적으로 변화시키는 오픈 소스 Python 라이브러리입니다.
주요 포인트
- ScrapeGraphAI는 웹 스크래핑을 간소화하는 오픈 소스 Python 라이브러리입니다.
- 대형 언어 모델(LLMs)을 사용하여 웹사이트에서 데이터를 더 효과적으로 추출합니다.
- 이 도구는 웹사이트의 변화에 적응함으로써 개발자의 지속적인 개입 필요성을 줄입니다.
- GPT, Gemini, Groq, Azure, Hugging Face 등 다양한 LLMs를 지원합니다.
- pip를 통한 설치가 간단하며, 가상 환경 사용이 권장됩니다.
- ScrapeGraphAI는 전통적인 방법에 비해 적은 코드로 데이터를 스크래핑하고 특정 정보를 추출할 수 있게 합니다.
- Ollama를 통한 로컬 호스팅은 비공개적이고 효율적인 스크래핑 환경을 제공합니다.
웹 스크래핑과 그 진화에 대한 이해
전통적인 웹 스크래핑 시대
웹 스크래핑은 인터넷이 발전하기 시작한 1990년대 말과 2000년대 초부터 존재해 왔습니다. 당시 스크래핑은 HTML 페이지에서 데이터를 추출하기 위해 집중적인 코딩을 포함했습니다. 온라인에서 발견되는 다양한 HTML 구조를 탐색하기 위해 맞춤 코딩이 필수적이었습니다. 정규 표현식은 HTML 데이터를 파싱하는 데 자주 사용되었으며, 이는 지루하고 복잡한 작업이었습니다. 이 방법은 주로 오프라인 애플리케이션에서 사용되었으며, 온라인으로 전환하려면 수동 업데이트가 필요했습니다. 전체 프로세스는 상당한 시간과 전문 지식을 요구했으며, 주로 고급 코딩 기술을 가진 사람들에게만 접근 가능했습니다.
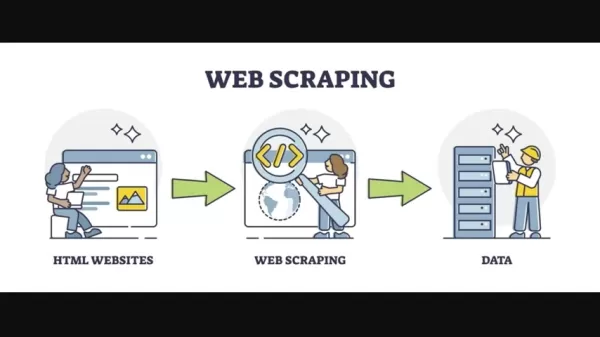
시간이 지나면서 웹 스크래핑을 간소화하기 위해 수많은 도구와 기술이 등장했습니다. Python은 견고한 라이브러리 생태계 덕분에 이 작업에 선호되는 언어가 되었습니다. Beautiful Soup과 Scrapy 같은 라이브러리는 더 구조화된 데이터 추출 방법을 제공했지만, 변화하는 웹사이트 구조에 적응하는 도전은 여전히 남아 있었습니다.
이제 대형 언어 모델(LLMs)의 도입으로 전통적인 웹 스크래핑의 복잡성을 많이 자동화하면서 풍경이 크게 변화했습니다. 이를 더 쉽게 만들어준 도구를 살펴보겠습니다.
ScrapeGraphAI 소개: 웹 스크래핑의 재구성
ScrapeGraphAI는 AI 기반 대형 언어 모델을 활용하여 웹 스크래핑 프로세스를 자동화하고 간소화하는 강력한 솔루션으로 등장했습니다. 이는 웹 스크래핑 접근 방식을 혁신적으로 설계된 오픈 소스 Python 라이브러리입니다.
고정된 패턴이나 수동 조정에 의존하는 전통적인 웹 스크래핑 도구와 달리, ScrapeGraphAI는 웹사이트 구조의 변화에 적응하여 개발자의 지속적인 개입 필요성을 최소화합니다. 대형 언어 모델(LLMs)과 모듈형 그래프 기반 파이프라인을 통합하여 다양한 소스에서 데이터를 자동으로 스크래핑하는 점에서 두드러집니다.
이 라이브러리는 전통적인 스크래핑 도구에 비해 더 유연하고 유지보수가 적은 솔루션을 제공합니다. 사용자는 HTML 마크업에서 특정 정보를 쉽게 추출할 수 있으며, 광범위한 코딩이나 복잡한 정규 표현식을 다룰 필요가 없습니다. 필요한 정보를 지정하기만 하면 ScrapeGraphAI가 나머지를 처리합니다. GPT, Gemini, Groq, Azure를 포함한 여러 LLMs와 Ollama를 사용하여 사용자의 컴퓨터에서 실행할 수 있는 로컬 모델을 지원합니다.
주요 구성 요소와 아키텍처
ScrapeGraphAI는 다양한 섹션의 모든 HTML 노드를 처리하기 위해 서로 다른 파싱 노드를 사용합니다. HTML 페이지 내에서 특정 영역을 정확히 찾아내기 위해 검색 노드를 사용합니다. 스마트 그래프 빌더는 HTML의 모든 마크업 언어를 관리합니다.
다음은 아키텍처에 대한 간략한 개요입니다:
- 노드 유형: ScrapeGraphAI는 조건부 노드, 가져오기 노드, 파싱 노드, Rag 노드, 검색 노드 등 다양한 파싱 노드를 사용하여 HTML의 서로 다른 섹션을 처리합니다. 이러한 노드는 조건부 파싱, 데이터 가져오기, 콘텐츠 파싱, HTML 구조 내에서 관련 정보를 검색하는 것을 가능하게 합니다.
- 그래프 빌더: ScrapeGraphAI의 스마트 그래프 빌더는 HTML 마크업 언어를 모두 처리하여 원하는 정보의 추출을 간소화합니다.
- 대형 언어 모델(LLMs): ScrapeGraphAI는 Gemini와 OpenAI와 같은 LLMs를 지원하며, 효율적인 데이터 추출을 위해 자연어 처리 기능을 활용합니다.
라이브러리는 그래프를 수동으로 정의하거나 LLM이 프롬프트를 기반으로 그래프를 생성하도록 하여 다양한 사용자 요구와 프로젝트 요구사항에 맞는 유연성을 추가합니다. 이 고급 아키텍처는 최소한의 코딩으로 복잡한 스크래핑 파이프라인을 쉽게 구현할 수 있게 합니다.
ScrapeGraphAI 설정: 설치 및 구성
전제 조건 및 설치 단계
ScrapeGraphAI를 시작하기 전에 시스템이 필요한 전제 조건을 충족하는지 확인하세요.
다음은 모든 것을 설정하는 자세한 가이드입니다:
- Python 버전: ScrapeGraphAI는 Python 3.9 이상이 필요하지만 3.12를 초과해서는 안 됩니다. Python 3.10은 일반적으로 충분합니다.
- PIP: 최신 버전의 PIP, Python 패키지 설치 프로그램이 있는지 확인하세요. pip install --upgrade pip 명령을 사용하여 업데이트할 수 있습니다.
- Ollama (선택 사항): 로컬 대형 언어 모델을 실행하려면 Ollama를 설치해야 합니다. 자세한 설치 및 설정 지침은 문서를 확인하세요.
이러한 전제 조건을 확인한 후 ScrapeGraphAI 설치가 간단합니다:
pip install scrapegraphai
시스템의 다른 Python 패키지와의 충돌을 피하기 위해 가상 환경(conda, venv 등)에 ScrapeGraphAI를 설치하는 것이 매우 권장됩니다.
Windows 사용자는 추가 라이브러리를 설치하기 위해 Windows Subsystem for Linux(WSL)를 사용할 수 있습니다.
적절한 대형 언어 모델 선택
ScrapeGraphAI를 사용할 때 중요한 결정 중 하나는 웹 스크래핑 요구에 맞는 적절한 대형 언어 모델(LLM)을 선택하는 것입니다. ScrapeGraphAI는 각기 장점과 능력을 가진 다양한 LLMs를 지원합니다:
- OpenAI의 GPT 모델: GPT-3.5 Turbo와 GPT-4는 일반적인 웹 스크래핑 작업에 강력한 옵션입니다. 이 모델들은 다양한 웹사이트 구조에서 정보를 효과적으로 이해하고 추출할 수 있습니다.
- Gemini: 고급 자연어 처리 기능을 제공하여 복잡한 데이터 추출 작업에 적합합니다.
- Groq: 속도와 효율성으로 잘 알려져 있으며, 대량의 웹 데이터를 빠르게 처리해야 할 때 탁월한 선택입니다.
- Azure: 엔터프라이즈급 보안과 확장성을 제공하여 엄격한 데이터 프라이버시 요구사항이 있는 조직에 이상적입니다.
- Hugging Face: 다양한 오픈 소스 LLMs를 제공하여 특정 웹 스크래핑 작업에 맞게 모델을 사용자 정의하고 미세 조정할 수 있습니다.
데이터 프라이버시나 비용이 우려되는 사용자를 위해 ScrapeGraphAI는 Ollama를 사용하여 로컬 LLMs를 실행할 수 있도록 합니다. 이 설정은 외부 서비스에 의존하지 않고 LLMs의 힘을 활용할 수 있게 합니다.
실제 예제: ScrapeGraphAI로 스크래핑
OpenAI 모델 설정
OpenAI 모델을 연결하고 사용하려면 필요한 라이브러리를 가져오고 API 키를 설정해야 합니다. 다음은 ScrapeGraphAI를 OpenAI의 GPT 모델과 구성하는 방법의 예입니다:
textimport os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],
,[object Object],
,[object Object],
,[object Object],
,[object Object],textresult = smart_scraper_graph.run()
print(result)
이 예제에서 graph_config 딕셔너리는 API 키와 사용하려는 모델(gpt-3.5-turbo)을 지정하기 위해 정의됩니다. 그런 다음 SmartScraperGraph는 프롬프트, 소스 URL, 구성을 사용하여 초기화됩니다. 마지막으로 run() 메서드가 호출되어 스크래핑 프로세스를 실행하고 결과를 출력합니다.
로컬 모델 구성
로컬 모델의 경우 ScrapeGraphAI는 약간 더 많은 구성이 필요하지만 여전히 간단합니다:
textfrom scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],
,[object Object],
,[object Object],
,[object Object],textresult = smart_scraper_graph.run()
print(result)
이 구성은 모델(ollama/llama3), 온도, 형식, LLM 및 임베딩에 대한 기본 URL을 지정하는 것을 포함합니다. 특정 웹 스크래핑 요구사항에 맞게 모델 및 기타 매개변수를 조정할 수 있습니다.
비용 및 라이선스 이해
오픈 소스 특성
ScrapeGraphAI는 오픈 소스 라이브러리이므로 무료로 사용할 수 있습니다. 라이선스 조건에 따라 다운로드, 수정, 배포할 수 있습니다. 이 오픈 특성은 커뮤니티 기여를 장려하고 라이브러리가 광범위한 사용자에게 접근 가능하도록 보장합니다.
그러나 OpenAI와 같은 특정 대형 언어 모델을 사용하면 비용이 발생할 수 있습니다. OpenAI, Bardeen AI 등은 토큰 기반 가격 모델로 운영됩니다. LLM에 프롬프트를 보내면 요청을 처리하고 응답을 생성합니다. 비용은 프롬프트와 응답에 사용된 토큰 수에 따라 달라집니다. 따라서 예기치 않은 요금을 피하기 위해 사용량을 모니터링하고 API 키를 관리하는 것이 중요합니다. OpenAI용 자신의 API 키를 보유하는 것이 도움이 됩니다.
ScrapeGraphAI의 장점과 단점
장점
- LLMs를 사용한 간소화된 웹 스크래핑 프로세스.
- 지속적인 유지보수 및 조정 필요성 감소.
- 다양한 대형 언어 모델 지원.
- 향상된 프라이버시와 보안을 위한 로컬 LLM 호스팅 옵션.
- 그래프 기반 파이프라인을 통한 유연성과 사용자 정의 증가.
단점
- 외부 LLM 서비스 사용과 관련된 잠재적 비용.
- 선택한 LLM의 정확성과 능력에 대한 의존성.
- Python 및 가상 환경에 대한 약간의 익숙함 필요.
- 상대적으로 새로운 라이브러리로, 커뮤니티 지원과 문서가 아직 성장 중일 수 있음.
주요 기능
LLM 통합
ScrapeGraphAI는 지능적인 웹 스크래핑을 위해 대형 언어 모델(LLMs)을 활용합니다. 웹사이트 구조의 변화를 자동으로 감지하고 적응하여 지속적인 수동 조정의 필요성을 줄입니다. 이 기능만으로도 상당한 개발 및 유지보수 시간을 절약할 수 있습니다.
그래프 기반 파이프라인
이 라이브러리는 효율적이고 구조화된 데이터 추출을 가능하게 하는 모듈형 그래프 기반 파이프라인을 사용합니다. 이러한 파이프라인은 다양한 웹 스크래핑 시나리오에 맞게 사용자 정의할 수 있어 추출 프로세스에 유연성과 제어력을 제공합니다.
다중 LLM 지원
ScrapeGraphAI는 GPT, Gemini, Groq, Azure, Hugging Face를 포함한 다양한 LLMs를 지원합니다. 이 지원을 통해 사용자는 일반적인 스크래핑 또는 보다 전문화된 작업에 가장 적합한 모델을 선택할 수 있습니다.
로컬 LLM 호스팅
Ollama 통합을 통해 ScrapeGraphAI는 대형 언어 모델을 로컬에서 호스팅할 수 있도록 합니다. 이를 통해 외부 서비스에 의존하지 않고 안전하고 비공개적인 웹 스크래핑 환경을 제공합니다.
ScrapeGraphAI의 다양한 사용 사례
전자상거래 비즈니스 인텔리전스
ScrapeGraphAI는 제품 가격을 모니터링하고, 경쟁 업체의 오퍼링을 추적하며, 고객 리뷰를 수집하여 전자상거래 비즈니스에 경쟁 우위를 제공할 수 있습니다. 이 데이터를 자동으로 수집함으로써 기업은 데이터 기반 결정을 내려 전략을 최적화할 수 있습니다.
투자자 조사
투자자는 ScrapeGraphAI를 활용하여 재무 데이터를 추출하고, 회사 뉴스를 분석하며, 시장 동향을 모니터링할 수 있습니다. 이 데이터는 투자자가 정보에 입각한 투자 결정을 내리고 위험을 효과적으로 관리하는 데 필요한 통찰력을 제공합니다.
마케팅 및 경쟁 분석
마케팅 팀은 ScrapeGraphAI를 사용하여 고객 피드백을 수집하고, 소셜 미디어 트렌드를 분석하며, 경쟁 업체 전략을 추적할 수 있습니다. 이러한 통찰력은 마케터가 타겟팅된 캠페인을 만들고, 콘텐츠를 최적화하며, 고객 참여를 개선할 수 있게 합니다.
자주 묻는 질문
ScrapeGraphAI란 무엇인가요?
ScrapeGraphAI는 대형 언어 모델(LLMs)을 사용하여 웹 스크래핑을 간소화하고 자동화하도록 설계된 오픈 소스 Python 라이브러리입니다. 이를 통해 사용자는 웹사이트에서 데이터를 더 효율적으로 추출하고 수동 코딩을 줄일 수 있습니다.
ScrapeGraphAI 설치에 필요한 전제 조건은 무엇인가요?
전제 조건에는 Python 3.9 이상(3.12 이하), PIP, 그리고 로컬 LLMs를 실행하기 위한 선택적 Ollama가 포함됩니다.
ScrapeGraphAI를 어떻게 설치하나요?
pip install scrapegraphai 명령을 사용하여 ScrapeGraphAI를 설치할 수 있습니다. 가상 환경에 설치하는 것이 권장됩니다.
ScrapeGraphAI는 어떤 대형 언어 모델을 지원하나요?
ScrapeGraphAI는 GPT, Gemini, Groq, Azure, Hugging Face, 그리고 Ollama를 사용하여 실행되는 로컬 모델을 지원합니다.
OpenAI의 GPT 모델을 사용하도록 ScrapeGraphAI를 구성하려면 어떻게 하나요?
graph_config 딕셔너리에서 OpenAI API 키를 설정하고 사용하려는 모델을 지정해야 합니다.
ScrapeGraphAI를 무료로 사용할 수 있나요?
네, ScrapeGraphAI는 오픈 소스 라이브러리이므로 무료로 사용할 수 있습니다. 그러나 OpenAI와 같은 특정 LLMs를 사용하면 토큰 사용량에 따라 비용이 발생할 수 있습니다.
관련 질문
ScrapeGraphAI는 전통적인 웹 스크래핑 도구와 어떻게 비교되나요?
ScrapeGraphAI는 AI 기반 대형 언어 모델을 활용하여 웹사이트 구조 변경으로 인한 지속적인 수동 조정의 필요성을 줄입니다. 전통적인 도구는 종종 더 많은 코딩과 유지보수를 요구합니다. ScrapeGraphAI는 웹사이트 구조의 변화에 적응하여 스크래퍼가 레이아웃이 변경되더라도 기능을 유지하도록 합니다. ScrapeGraphAI를 사용하면 필요한 정보를 지정하기만 하면 라이브러리가 나머지를 처리합니다. 전통적인 웹 스크래핑 방법은 인터넷이 형성되기 시작한 1990년대 말과 2000년대 초부터 존재해 왔습니다. 당시 웹 스크래핑은 HTML 웹페이지에서 데이터를 추출하기 위해 무거운 코딩을 포함했습니다. 정규 표현식은 HTML 데이터를 파싱하는 데 일반적으로 사용되었으며, 이는 지루하고 복잡한 작업이었습니다. 이 접근법은 주로 오프라인 애플리케이션에서 사용되었으며, 개발자가 수동으로 온라인으로 전환해야 했습니다.
ScrapeGraphAI를 사용할 때 어떤 종류의 프롬프트를 정의할 수 있나요?
이 구성은 모델(ollama/llama3), 온도, 형식, LLM 및 임베딩에 대한 기본 URL을 지정하는 것을 포함합니다. 특정 웹 스크래핑 요구사항에 맞게 모델 및 기타 매개변수를 조정할 수 있습니다. 일반적인 프롬프트는 다음과 같습니다:
- 모든 프로젝트의 제목과 설명을 나열하세요.
- 모든 콘텐츠를 나열하세요.
관련 기사
 놀라운 디지털 혁신으로 메타버스에서 마이클 잭슨을 재창조하는 AI
인공지능은 창의성, 엔터테인먼트, 문화 유산에 대한 우리의 이해를 근본적으로 바꾸고 있습니다. 마이클 잭슨에 대한 인공지능의 해석을 통해 최첨단 기술이 어떻게 전설적인 문화 인물에 새로운 생명을 불어넣을 수 있는지 살펴봅니다. 슈퍼 히어로의 화신에서 판타지 세계의 전사에 이르기까지 획기적인 변신은 디지털 아트와 가상 세계 경험의 지평을 넓히는 동시에 팝의
훈련이 AI로 인한 인지 오프로딩 효과를 완화할 수 있나요?
최근 Unite.ai의 'ChatGPT가 뇌를 고갈시킬 수 있습니다: 인공지능 시대의 인지적 부채'라는 제목의 기사에서 MIT의 연구 결과를 조명했습니다. 저널리스트 알렉스 맥팔랜드는 과도한 AI 의존도가 어떻게 필수적인 인지 능력, 특히 비판적 사고와 판단력을 약화시킬 수 있는지에 대한 설득력 있는 증거를 자세히 설명했습니다. 이러한 연구 결과는 다른 수
더 나은 데이터 인사이트를 위한 AI 기반 그래프 및 시각화를 쉽게 생성하기
최신 데이터 분석에는 복잡한 정보를 직관적으로 시각화할 수 있어야 합니다. AI 기반 그래프 생성 솔루션은 전문가들이 원시 데이터를 매력적인 시각적 스토리로 변환하는 방법에 혁신을 일으키며 필수적인 자산으로 부상했습니다. 이러한 지능형 시스템은 정밀도를 유지하면서 수동 차트 생성을 제거하여 기술 및 비기술 사용자 모두 자동화된 시각화를 통해 실행 가능한 인
의견 (8)
0/200
놀라운 디지털 혁신으로 메타버스에서 마이클 잭슨을 재창조하는 AI
인공지능은 창의성, 엔터테인먼트, 문화 유산에 대한 우리의 이해를 근본적으로 바꾸고 있습니다. 마이클 잭슨에 대한 인공지능의 해석을 통해 최첨단 기술이 어떻게 전설적인 문화 인물에 새로운 생명을 불어넣을 수 있는지 살펴봅니다. 슈퍼 히어로의 화신에서 판타지 세계의 전사에 이르기까지 획기적인 변신은 디지털 아트와 가상 세계 경험의 지평을 넓히는 동시에 팝의
훈련이 AI로 인한 인지 오프로딩 효과를 완화할 수 있나요?
최근 Unite.ai의 'ChatGPT가 뇌를 고갈시킬 수 있습니다: 인공지능 시대의 인지적 부채'라는 제목의 기사에서 MIT의 연구 결과를 조명했습니다. 저널리스트 알렉스 맥팔랜드는 과도한 AI 의존도가 어떻게 필수적인 인지 능력, 특히 비판적 사고와 판단력을 약화시킬 수 있는지에 대한 설득력 있는 증거를 자세히 설명했습니다. 이러한 연구 결과는 다른 수
더 나은 데이터 인사이트를 위한 AI 기반 그래프 및 시각화를 쉽게 생성하기
최신 데이터 분석에는 복잡한 정보를 직관적으로 시각화할 수 있어야 합니다. AI 기반 그래프 생성 솔루션은 전문가들이 원시 데이터를 매력적인 시각적 스토리로 변환하는 방법에 혁신을 일으키며 필수적인 자산으로 부상했습니다. 이러한 지능형 시스템은 정밀도를 유지하면서 수동 차트 생성을 제거하여 기술 및 비기술 사용자 모두 자동화된 시각화를 통해 실행 가능한 인
의견 (8)
0/200
![HenryDavis]() HenryDavis
HenryDavis
 2025년 8월 5일 오후 6시 0분 59초 GMT+09:00
2025년 8월 5일 오후 6시 0분 59초 GMT+09:00
This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎


 0
0
![RyanJackson]() RyanJackson
2025년 8월 1일 오후 3시 45분 46초 GMT+09:00
RyanJackson
2025년 8월 1일 오후 3시 45분 46초 GMT+09:00
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
0
![KevinAnderson]() KevinAnderson
2025년 7월 28일 오전 10시 19분 30초 GMT+09:00
KevinAnderson
2025년 7월 28일 오전 10시 19분 30초 GMT+09:00
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
0
![BillyWilson]() BillyWilson
2025년 5월 14일 오전 6시 23분 52초 GMT+09:00
BillyWilson
2025년 5월 14일 오전 6시 23분 52초 GMT+09:00
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
0
![ThomasLewis]() ThomasLewis
2025년 5월 14일 오전 5시 47분 14초 GMT+09:00
ThomasLewis
2025년 5월 14일 오전 5시 47분 14초 GMT+09:00
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
0
![SamuelAllen]() SamuelAllen
2025년 5월 14일 오전 12시 53분 23초 GMT+09:00
SamuelAllen
2025년 5월 14일 오전 12시 53분 23초 GMT+09:00
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
0
오늘날 데이터 중심의 세상에서 웹사이트에서 정보를 추출하는 것은 비즈니스 인텔리전스, 시장 조사, 경쟁 분석 등 다양한 목적에 필수적입니다. 웹 스크래핑, 즉 웹사이트에서 데이터를 자동으로 가져오는 프로세스는 중요한 도구가 되었습니다. 그러나 전통적인 웹 스크래핑 방법은 종종 복잡한 코딩과 웹사이트 구조의 변화로 인해 정기적인 업데이트가 필요합니다. 여기서 ScrapeGraphAI가 등장합니다—대형 언어 모델(LLMs)의 기능을 활용하여 웹 스크래핑을 혁신적으로 변화시키는 오픈 소스 Python 라이브러리입니다.
주요 포인트
- ScrapeGraphAI는 웹 스크래핑을 간소화하는 오픈 소스 Python 라이브러리입니다.
- 대형 언어 모델(LLMs)을 사용하여 웹사이트에서 데이터를 더 효과적으로 추출합니다.
- 이 도구는 웹사이트의 변화에 적응함으로써 개발자의 지속적인 개입 필요성을 줄입니다.
- GPT, Gemini, Groq, Azure, Hugging Face 등 다양한 LLMs를 지원합니다.
- pip를 통한 설치가 간단하며, 가상 환경 사용이 권장됩니다.
- ScrapeGraphAI는 전통적인 방법에 비해 적은 코드로 데이터를 스크래핑하고 특정 정보를 추출할 수 있게 합니다.
- Ollama를 통한 로컬 호스팅은 비공개적이고 효율적인 스크래핑 환경을 제공합니다.
웹 스크래핑과 그 진화에 대한 이해
전통적인 웹 스크래핑 시대
웹 스크래핑은 인터넷이 발전하기 시작한 1990년대 말과 2000년대 초부터 존재해 왔습니다. 당시 스크래핑은 HTML 페이지에서 데이터를 추출하기 위해 집중적인 코딩을 포함했습니다. 온라인에서 발견되는 다양한 HTML 구조를 탐색하기 위해 맞춤 코딩이 필수적이었습니다. 정규 표현식은 HTML 데이터를 파싱하는 데 자주 사용되었으며, 이는 지루하고 복잡한 작업이었습니다. 이 방법은 주로 오프라인 애플리케이션에서 사용되었으며, 온라인으로 전환하려면 수동 업데이트가 필요했습니다. 전체 프로세스는 상당한 시간과 전문 지식을 요구했으며, 주로 고급 코딩 기술을 가진 사람들에게만 접근 가능했습니다.
시간이 지나면서 웹 스크래핑을 간소화하기 위해 수많은 도구와 기술이 등장했습니다. Python은 견고한 라이브러리 생태계 덕분에 이 작업에 선호되는 언어가 되었습니다. Beautiful Soup과 Scrapy 같은 라이브러리는 더 구조화된 데이터 추출 방법을 제공했지만, 변화하는 웹사이트 구조에 적응하는 도전은 여전히 남아 있었습니다.
이제 대형 언어 모델(LLMs)의 도입으로 전통적인 웹 스크래핑의 복잡성을 많이 자동화하면서 풍경이 크게 변화했습니다. 이를 더 쉽게 만들어준 도구를 살펴보겠습니다.
ScrapeGraphAI 소개: 웹 스크래핑의 재구성
ScrapeGraphAI는 AI 기반 대형 언어 모델을 활용하여 웹 스크래핑 프로세스를 자동화하고 간소화하는 강력한 솔루션으로 등장했습니다. 이는 웹 스크래핑 접근 방식을 혁신적으로 설계된 오픈 소스 Python 라이브러리입니다.
고정된 패턴이나 수동 조정에 의존하는 전통적인 웹 스크래핑 도구와 달리, ScrapeGraphAI는 웹사이트 구조의 변화에 적응하여 개발자의 지속적인 개입 필요성을 최소화합니다. 대형 언어 모델(LLMs)과 모듈형 그래프 기반 파이프라인을 통합하여 다양한 소스에서 데이터를 자동으로 스크래핑하는 점에서 두드러집니다.
이 라이브러리는 전통적인 스크래핑 도구에 비해 더 유연하고 유지보수가 적은 솔루션을 제공합니다. 사용자는 HTML 마크업에서 특정 정보를 쉽게 추출할 수 있으며, 광범위한 코딩이나 복잡한 정규 표현식을 다룰 필요가 없습니다. 필요한 정보를 지정하기만 하면 ScrapeGraphAI가 나머지를 처리합니다. GPT, Gemini, Groq, Azure를 포함한 여러 LLMs와 Ollama를 사용하여 사용자의 컴퓨터에서 실행할 수 있는 로컬 모델을 지원합니다.
주요 구성 요소와 아키텍처
ScrapeGraphAI는 다양한 섹션의 모든 HTML 노드를 처리하기 위해 서로 다른 파싱 노드를 사용합니다. HTML 페이지 내에서 특정 영역을 정확히 찾아내기 위해 검색 노드를 사용합니다. 스마트 그래프 빌더는 HTML의 모든 마크업 언어를 관리합니다.
다음은 아키텍처에 대한 간략한 개요입니다:
- 노드 유형: ScrapeGraphAI는 조건부 노드, 가져오기 노드, 파싱 노드, Rag 노드, 검색 노드 등 다양한 파싱 노드를 사용하여 HTML의 서로 다른 섹션을 처리합니다. 이러한 노드는 조건부 파싱, 데이터 가져오기, 콘텐츠 파싱, HTML 구조 내에서 관련 정보를 검색하는 것을 가능하게 합니다.
- 그래프 빌더: ScrapeGraphAI의 스마트 그래프 빌더는 HTML 마크업 언어를 모두 처리하여 원하는 정보의 추출을 간소화합니다.
- 대형 언어 모델(LLMs): ScrapeGraphAI는 Gemini와 OpenAI와 같은 LLMs를 지원하며, 효율적인 데이터 추출을 위해 자연어 처리 기능을 활용합니다.
라이브러리는 그래프를 수동으로 정의하거나 LLM이 프롬프트를 기반으로 그래프를 생성하도록 하여 다양한 사용자 요구와 프로젝트 요구사항에 맞는 유연성을 추가합니다. 이 고급 아키텍처는 최소한의 코딩으로 복잡한 스크래핑 파이프라인을 쉽게 구현할 수 있게 합니다.
ScrapeGraphAI 설정: 설치 및 구성
전제 조건 및 설치 단계
ScrapeGraphAI를 시작하기 전에 시스템이 필요한 전제 조건을 충족하는지 확인하세요.
다음은 모든 것을 설정하는 자세한 가이드입니다:
- Python 버전: ScrapeGraphAI는 Python 3.9 이상이 필요하지만 3.12를 초과해서는 안 됩니다. Python 3.10은 일반적으로 충분합니다.
- PIP: 최신 버전의 PIP, Python 패키지 설치 프로그램이 있는지 확인하세요. pip install --upgrade pip 명령을 사용하여 업데이트할 수 있습니다.
- Ollama (선택 사항): 로컬 대형 언어 모델을 실행하려면 Ollama를 설치해야 합니다. 자세한 설치 및 설정 지침은 문서를 확인하세요.
이러한 전제 조건을 확인한 후 ScrapeGraphAI 설치가 간단합니다:
시스템의 다른 Python 패키지와의 충돌을 피하기 위해 가상 환경(conda, venv 등)에 ScrapeGraphAI를 설치하는 것이 매우 권장됩니다.
Windows 사용자는 추가 라이브러리를 설치하기 위해 Windows Subsystem for Linux(WSL)를 사용할 수 있습니다.
적절한 대형 언어 모델 선택
ScrapeGraphAI를 사용할 때 중요한 결정 중 하나는 웹 스크래핑 요구에 맞는 적절한 대형 언어 모델(LLM)을 선택하는 것입니다. ScrapeGraphAI는 각기 장점과 능력을 가진 다양한 LLMs를 지원합니다:
- OpenAI의 GPT 모델: GPT-3.5 Turbo와 GPT-4는 일반적인 웹 스크래핑 작업에 강력한 옵션입니다. 이 모델들은 다양한 웹사이트 구조에서 정보를 효과적으로 이해하고 추출할 수 있습니다.
- Gemini: 고급 자연어 처리 기능을 제공하여 복잡한 데이터 추출 작업에 적합합니다.
- Groq: 속도와 효율성으로 잘 알려져 있으며, 대량의 웹 데이터를 빠르게 처리해야 할 때 탁월한 선택입니다.
- Azure: 엔터프라이즈급 보안과 확장성을 제공하여 엄격한 데이터 프라이버시 요구사항이 있는 조직에 이상적입니다.
- Hugging Face: 다양한 오픈 소스 LLMs를 제공하여 특정 웹 스크래핑 작업에 맞게 모델을 사용자 정의하고 미세 조정할 수 있습니다.
데이터 프라이버시나 비용이 우려되는 사용자를 위해 ScrapeGraphAI는 Ollama를 사용하여 로컬 LLMs를 실행할 수 있도록 합니다. 이 설정은 외부 서비스에 의존하지 않고 LLMs의 힘을 활용할 수 있게 합니다.
실제 예제: ScrapeGraphAI로 스크래핑
OpenAI 모델 설정
OpenAI 모델을 연결하고 사용하려면 필요한 라이브러리를 가져오고 API 키를 설정해야 합니다. 다음은 ScrapeGraphAI를 OpenAI의 GPT 모델과 구성하는 방법의 예입니다:
import os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],
,[object Object],
,[object Object],
,[object Object],
,[object Object],result = smart_scraper_graph.run()
print(result)이 예제에서 graph_config 딕셔너리는 API 키와 사용하려는 모델(gpt-3.5-turbo)을 지정하기 위해 정의됩니다. 그런 다음 SmartScraperGraph는 프롬프트, 소스 URL, 구성을 사용하여 초기화됩니다. 마지막으로 run() 메서드가 호출되어 스크래핑 프로세스를 실행하고 결과를 출력합니다.
로컬 모델 구성
로컬 모델의 경우 ScrapeGraphAI는 약간 더 많은 구성이 필요하지만 여전히 간단합니다:
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],
,[object Object],
,[object Object],
,[object Object],result = smart_scraper_graph.run()
print(result)이 구성은 모델(ollama/llama3), 온도, 형식, LLM 및 임베딩에 대한 기본 URL을 지정하는 것을 포함합니다. 특정 웹 스크래핑 요구사항에 맞게 모델 및 기타 매개변수를 조정할 수 있습니다.
비용 및 라이선스 이해
오픈 소스 특성
ScrapeGraphAI는 오픈 소스 라이브러리이므로 무료로 사용할 수 있습니다. 라이선스 조건에 따라 다운로드, 수정, 배포할 수 있습니다. 이 오픈 특성은 커뮤니티 기여를 장려하고 라이브러리가 광범위한 사용자에게 접근 가능하도록 보장합니다.
그러나 OpenAI와 같은 특정 대형 언어 모델을 사용하면 비용이 발생할 수 있습니다. OpenAI, Bardeen AI 등은 토큰 기반 가격 모델로 운영됩니다. LLM에 프롬프트를 보내면 요청을 처리하고 응답을 생성합니다. 비용은 프롬프트와 응답에 사용된 토큰 수에 따라 달라집니다. 따라서 예기치 않은 요금을 피하기 위해 사용량을 모니터링하고 API 키를 관리하는 것이 중요합니다. OpenAI용 자신의 API 키를 보유하는 것이 도움이 됩니다.
ScrapeGraphAI의 장점과 단점
장점
- LLMs를 사용한 간소화된 웹 스크래핑 프로세스.
- 지속적인 유지보수 및 조정 필요성 감소.
- 다양한 대형 언어 모델 지원.
- 향상된 프라이버시와 보안을 위한 로컬 LLM 호스팅 옵션.
- 그래프 기반 파이프라인을 통한 유연성과 사용자 정의 증가.
단점
- 외부 LLM 서비스 사용과 관련된 잠재적 비용.
- 선택한 LLM의 정확성과 능력에 대한 의존성.
- Python 및 가상 환경에 대한 약간의 익숙함 필요.
- 상대적으로 새로운 라이브러리로, 커뮤니티 지원과 문서가 아직 성장 중일 수 있음.
주요 기능
LLM 통합
ScrapeGraphAI는 지능적인 웹 스크래핑을 위해 대형 언어 모델(LLMs)을 활용합니다. 웹사이트 구조의 변화를 자동으로 감지하고 적응하여 지속적인 수동 조정의 필요성을 줄입니다. 이 기능만으로도 상당한 개발 및 유지보수 시간을 절약할 수 있습니다.
그래프 기반 파이프라인
이 라이브러리는 효율적이고 구조화된 데이터 추출을 가능하게 하는 모듈형 그래프 기반 파이프라인을 사용합니다. 이러한 파이프라인은 다양한 웹 스크래핑 시나리오에 맞게 사용자 정의할 수 있어 추출 프로세스에 유연성과 제어력을 제공합니다.
다중 LLM 지원
ScrapeGraphAI는 GPT, Gemini, Groq, Azure, Hugging Face를 포함한 다양한 LLMs를 지원합니다. 이 지원을 통해 사용자는 일반적인 스크래핑 또는 보다 전문화된 작업에 가장 적합한 모델을 선택할 수 있습니다.
로컬 LLM 호스팅
Ollama 통합을 통해 ScrapeGraphAI는 대형 언어 모델을 로컬에서 호스팅할 수 있도록 합니다. 이를 통해 외부 서비스에 의존하지 않고 안전하고 비공개적인 웹 스크래핑 환경을 제공합니다.
ScrapeGraphAI의 다양한 사용 사례
전자상거래 비즈니스 인텔리전스
ScrapeGraphAI는 제품 가격을 모니터링하고, 경쟁 업체의 오퍼링을 추적하며, 고객 리뷰를 수집하여 전자상거래 비즈니스에 경쟁 우위를 제공할 수 있습니다. 이 데이터를 자동으로 수집함으로써 기업은 데이터 기반 결정을 내려 전략을 최적화할 수 있습니다.
투자자 조사
투자자는 ScrapeGraphAI를 활용하여 재무 데이터를 추출하고, 회사 뉴스를 분석하며, 시장 동향을 모니터링할 수 있습니다. 이 데이터는 투자자가 정보에 입각한 투자 결정을 내리고 위험을 효과적으로 관리하는 데 필요한 통찰력을 제공합니다.
마케팅 및 경쟁 분석
마케팅 팀은 ScrapeGraphAI를 사용하여 고객 피드백을 수집하고, 소셜 미디어 트렌드를 분석하며, 경쟁 업체 전략을 추적할 수 있습니다. 이러한 통찰력은 마케터가 타겟팅된 캠페인을 만들고, 콘텐츠를 최적화하며, 고객 참여를 개선할 수 있게 합니다.
자주 묻는 질문
ScrapeGraphAI란 무엇인가요?
ScrapeGraphAI는 대형 언어 모델(LLMs)을 사용하여 웹 스크래핑을 간소화하고 자동화하도록 설계된 오픈 소스 Python 라이브러리입니다. 이를 통해 사용자는 웹사이트에서 데이터를 더 효율적으로 추출하고 수동 코딩을 줄일 수 있습니다.
ScrapeGraphAI 설치에 필요한 전제 조건은 무엇인가요?
전제 조건에는 Python 3.9 이상(3.12 이하), PIP, 그리고 로컬 LLMs를 실행하기 위한 선택적 Ollama가 포함됩니다.
ScrapeGraphAI를 어떻게 설치하나요?
pip install scrapegraphai 명령을 사용하여 ScrapeGraphAI를 설치할 수 있습니다. 가상 환경에 설치하는 것이 권장됩니다.
ScrapeGraphAI는 어떤 대형 언어 모델을 지원하나요?
ScrapeGraphAI는 GPT, Gemini, Groq, Azure, Hugging Face, 그리고 Ollama를 사용하여 실행되는 로컬 모델을 지원합니다.
OpenAI의 GPT 모델을 사용하도록 ScrapeGraphAI를 구성하려면 어떻게 하나요?
graph_config 딕셔너리에서 OpenAI API 키를 설정하고 사용하려는 모델을 지정해야 합니다.
ScrapeGraphAI를 무료로 사용할 수 있나요?
네, ScrapeGraphAI는 오픈 소스 라이브러리이므로 무료로 사용할 수 있습니다. 그러나 OpenAI와 같은 특정 LLMs를 사용하면 토큰 사용량에 따라 비용이 발생할 수 있습니다.
관련 질문
ScrapeGraphAI는 전통적인 웹 스크래핑 도구와 어떻게 비교되나요?
ScrapeGraphAI는 AI 기반 대형 언어 모델을 활용하여 웹사이트 구조 변경으로 인한 지속적인 수동 조정의 필요성을 줄입니다. 전통적인 도구는 종종 더 많은 코딩과 유지보수를 요구합니다. ScrapeGraphAI는 웹사이트 구조의 변화에 적응하여 스크래퍼가 레이아웃이 변경되더라도 기능을 유지하도록 합니다. ScrapeGraphAI를 사용하면 필요한 정보를 지정하기만 하면 라이브러리가 나머지를 처리합니다. 전통적인 웹 스크래핑 방법은 인터넷이 형성되기 시작한 1990년대 말과 2000년대 초부터 존재해 왔습니다. 당시 웹 스크래핑은 HTML 웹페이지에서 데이터를 추출하기 위해 무거운 코딩을 포함했습니다. 정규 표현식은 HTML 데이터를 파싱하는 데 일반적으로 사용되었으며, 이는 지루하고 복잡한 작업이었습니다. 이 접근법은 주로 오프라인 애플리케이션에서 사용되었으며, 개발자가 수동으로 온라인으로 전환해야 했습니다.
ScrapeGraphAI를 사용할 때 어떤 종류의 프롬프트를 정의할 수 있나요?
이 구성은 모델(ollama/llama3), 온도, 형식, LLM 및 임베딩에 대한 기본 URL을 지정하는 것을 포함합니다. 특정 웹 스크래핑 요구사항에 맞게 모델 및 기타 매개변수를 조정할 수 있습니다. 일반적인 프롬프트는 다음과 같습니다:
- 모든 프로젝트의 제목과 설명을 나열하세요.
- 모든 콘텐츠를 나열하세요.










 놀라운 디지털 혁신으로 메타버스에서 마이클 잭슨을 재창조하는 AI
인공지능은 창의성, 엔터테인먼트, 문화 유산에 대한 우리의 이해를 근본적으로 바꾸고 있습니다. 마이클 잭슨에 대한 인공지능의 해석을 통해 최첨단 기술이 어떻게 전설적인 문화 인물에 새로운 생명을 불어넣을 수 있는지 살펴봅니다. 슈퍼 히어로의 화신에서 판타지 세계의 전사에 이르기까지 획기적인 변신은 디지털 아트와 가상 세계 경험의 지평을 넓히는 동시에 팝의
놀라운 디지털 혁신으로 메타버스에서 마이클 잭슨을 재창조하는 AI
인공지능은 창의성, 엔터테인먼트, 문화 유산에 대한 우리의 이해를 근본적으로 바꾸고 있습니다. 마이클 잭슨에 대한 인공지능의 해석을 통해 최첨단 기술이 어떻게 전설적인 문화 인물에 새로운 생명을 불어넣을 수 있는지 살펴봅니다. 슈퍼 히어로의 화신에서 판타지 세계의 전사에 이르기까지 획기적인 변신은 디지털 아트와 가상 세계 경험의 지평을 넓히는 동시에 팝의
 훈련이 AI로 인한 인지 오프로딩 효과를 완화할 수 있나요?
최근 Unite.ai의 'ChatGPT가 뇌를 고갈시킬 수 있습니다: 인공지능 시대의 인지적 부채'라는 제목의 기사에서 MIT의 연구 결과를 조명했습니다. 저널리스트 알렉스 맥팔랜드는 과도한 AI 의존도가 어떻게 필수적인 인지 능력, 특히 비판적 사고와 판단력을 약화시킬 수 있는지에 대한 설득력 있는 증거를 자세히 설명했습니다. 이러한 연구 결과는 다른 수
훈련이 AI로 인한 인지 오프로딩 효과를 완화할 수 있나요?
최근 Unite.ai의 'ChatGPT가 뇌를 고갈시킬 수 있습니다: 인공지능 시대의 인지적 부채'라는 제목의 기사에서 MIT의 연구 결과를 조명했습니다. 저널리스트 알렉스 맥팔랜드는 과도한 AI 의존도가 어떻게 필수적인 인지 능력, 특히 비판적 사고와 판단력을 약화시킬 수 있는지에 대한 설득력 있는 증거를 자세히 설명했습니다. 이러한 연구 결과는 다른 수
 더 나은 데이터 인사이트를 위한 AI 기반 그래프 및 시각화를 쉽게 생성하기
최신 데이터 분석에는 복잡한 정보를 직관적으로 시각화할 수 있어야 합니다. AI 기반 그래프 생성 솔루션은 전문가들이 원시 데이터를 매력적인 시각적 스토리로 변환하는 방법에 혁신을 일으키며 필수적인 자산으로 부상했습니다. 이러한 지능형 시스템은 정밀도를 유지하면서 수동 차트 생성을 제거하여 기술 및 비기술 사용자 모두 자동화된 시각화를 통해 실행 가능한 인
2025년 8월 5일 오후 6시 0분 59초 GMT+09:00
더 나은 데이터 인사이트를 위한 AI 기반 그래프 및 시각화를 쉽게 생성하기
최신 데이터 분석에는 복잡한 정보를 직관적으로 시각화할 수 있어야 합니다. AI 기반 그래프 생성 솔루션은 전문가들이 원시 데이터를 매력적인 시각적 스토리로 변환하는 방법에 혁신을 일으키며 필수적인 자산으로 부상했습니다. 이러한 지능형 시스템은 정밀도를 유지하면서 수동 차트 생성을 제거하여 기술 및 비기술 사용자 모두 자동화된 시각화를 통해 실행 가능한 인
2025년 8월 5일 오후 6시 0분 59초 GMT+09:00
This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎
0
2025년 8월 1일 오후 3시 45분 46초 GMT+09:00
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
0
2025년 7월 28일 오전 10시 19분 30초 GMT+09:00
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
0
2025년 5월 14일 오전 6시 23분 52초 GMT+09:00
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
0
2025년 5월 14일 오전 5시 47분 14초 GMT+09:00
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
0
2025년 5월 14일 오전 12시 53분 23초 GMT+09:00
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
0













