
















 首頁
首頁ScrapeGraphAI:革新網頁抓取指南
在當今數據驅動的世界中,從網站提取資訊對於商業智慧、市場研究和競爭分析等各種目的至關重要。網頁抓取,作為從網站自動提取數據的過程,已成為重要工具。然而,傳統網頁抓取方法通常需要複雜的編碼和因網站結構變化而定期更新。這就是 ScrapeGraphAI 的用武之地——一個創新的開源 Python 庫,旨在通過利用大型語言模型(LLMs)的能力來轉變網頁抓取方式。
重點
- ScrapeGraphAI 是一個開源 Python 庫,簡化網頁抓取。
- 它使用大型語言模型(LLMs)更有效地從網站提取數據。
- 該工具通過適應網站變化,減少對開發者的持續干預需求。
- 它支援多種 LLMs,包括 GPT、Gemini、Groq、Azure 和 Hugging Face。
- 使用 pip 安裝簡單,建議使用虛擬環境。
- 與傳統方法相比,ScrapeGraphAI 能以更少的代碼抓取數據並提取特定資訊。
- 通過 Ollama 進行本地托管,提供私有且高效的抓取環境。
了解網頁抓取及其演變
傳統網頁抓取時代
網頁抓取自1990年代末和2000年代初,隨著互聯網的發展而出現。當時,抓取需要大量編碼以從 HTML 頁面提取數據。自定義編碼對於導航不同的線上 HTML 結構至關重要。經常用正則表達式來解析 HTML 數據,這既繁瑣又複雜。這種方法主要用於離線應用,需要手動更新才能上線。整個過程需要大量時間和專業知識,主要限於具備高級編碼技能的人使用。
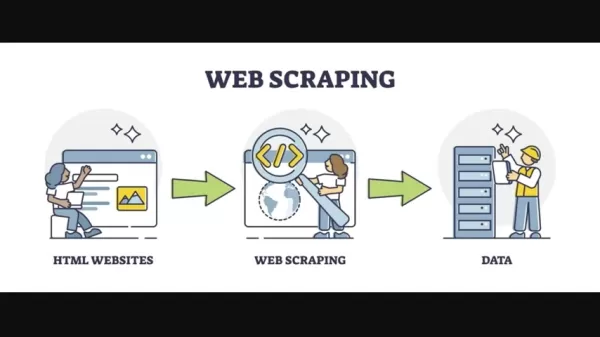
隨著時間推移,許多工具和技術出現以簡化網頁抓取。Python 以其強大的庫生態系統成為首選語言。像 Beautiful Soup 和 Scrapy 這樣的庫提供了更結構化的數據提取方法,但適應網站結構變化的挑戰依然存在。
隨著大型語言模型(LLMs)的引入,網頁抓取的格局已顯著改變,自動化了許多傳統網頁抓取的複雜性。讓我們來探索一個讓這一切變得更簡單的工具。
介紹 ScrapeGraphAI:重新定義網頁抓取
ScrapeGraphAI 是一個強大的解決方案,利用 AI 驅動的大型語言模型來自動化和簡化網頁抓取過程。它是一個開源 Python 庫,旨在革新我們處理網頁抓取的方式。
與通常依賴固定模式或手動調整的傳統網頁抓取工具不同,ScrapeGraphAI 能適應網站結構的變化,最大程度減少對開發者的持續干預需求。它通過整合大型語言模型(LLMs)和模組化圖形管道來自動化從各種來源抓取數據,脫穎而出。
該庫提供比傳統抓取工具更靈活且低維護的解決方案。它允許用戶從 HTML 標記中輕鬆提取特定資訊,無需大量編碼或處理複雜的正則表達式。你只需指定所需資訊,ScrapeGraphAI 會處理其餘部分。它支援多種 LLMs,包括 GPT、Gemini、Groq 和 Azure,以及可通過 Ollama 在本地運行的模型。
關鍵組件與架構
ScrapeGraphAI 使用不同的解析節點來處理各個部分的 HTML 節點。它使用搜索節點來精確定位 HTML 頁面中的特定區域。智能圖形構建器管理所有 HTML 標記語言。
以下是其架構的簡要概述:
- 節點類型: ScrapeGraphAI 使用多種解析節點來處理 HTML 的不同部分,包括條件節點、獲取節點、解析節點、Rag 節點和搜索節點。這些節點支援條件解析、數據獲取、內容解析和在 HTML 結構中搜索相關資訊。
- 圖形構建器: ScrapeGraphAI 的智能圖形構建器通過處理所有 HTML 標記語言,簡化所需資訊的提取。
- 大型語言模型(LLMs): ScrapeGraphAI 支援 Gemini 和 OpenAI 等 LLMs,利用其自然語言處理能力進行高效數據提取。
該庫允許手動定義圖形或讓 LLM 根據提示創建圖形,增加了靈活性,滿足不同用戶需求和項目要求。這種高層次架構使實現複雜的抓取管道變得更簡單,只需最少的編碼。
設置 ScrapeGraphAI:安裝與配置
先決條件與安裝步驟
在開始使用 ScrapeGraphAI 之前,請確保你的系統滿足必要的先決條件。
以下是設置的詳細指南:
- Python 版本: ScrapeGraphAI 需要 Python 3.9 或更高版本,但不超過 3.12。Python 3.10 通常足夠。
- PIP: 確保你擁有最新版本的 PIP,Python 套件安裝程式。你可以使用命令 pip install --upgrade pip 更新它。
- Ollama(可選): 如果你計劃運行本地大型語言模型,需安裝 Ollama。請參閱文件以獲取詳細的安裝和設置說明。
確認這些先決條件後,安裝 ScrapeGraphAI 非常簡單:
pip install scrapegraphai強烈建議在虛擬環境(conda、venv 等)中安裝 ScrapeGraphAI,以避免與系統中其他 Python 套件衝突。
對於 Windows 用戶,你可以使用 Windows 子系統 Linux(WSL)安裝額外庫。
選擇合適的大型語言模型
使用 ScrapeGraphAI 時的關鍵決定之一是為你的網頁抓取需求選擇合適的大型語言模型(LLM)。ScrapeGraphAI 支援多種 LLMs,每種都有其優勢和能力:
- OpenAI 的 GPT 模型: GPT-3.5 Turbo 和 GPT-4 是通用網頁抓取任務的強大選擇。這些模型能有效理解和提取不同網站結構的資訊。
- Gemini: 提供先進的自然語言處理能力,適用於複雜的數據提取任務。
- Groq: 以速度和效率著稱,當需要快速處理大量網頁數據時,Groq 是絕佳選擇。
- Azure: 提供企業級安全性和可擴展性,適合有嚴格數據隱私要求的組織。
- Hugging Face: 提供廣泛的開源 LLMs,允許你為特定網頁抓取任務自定義和微調模型。
對於關注數據隱私或成本的用戶,ScrapeGraphAI 允許使用 Ollama 運行本地 LLMs。這種設置使你能利用 LLMs 的力量,而無需依賴外部服務。
實際範例:使用 ScrapeGraphAI 進行抓取
設置 OpenAI 模型
要連接和使用 OpenAI 模型,你需要導入必要的庫並設置你的 API 金鑰。以下是如何配置 ScrapeGraphAI 以使用 OpenAI 的 GPT 模型的範例:
textimport os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object],[object Object]textresult = smart_scraper_graph.run()
print(result)在此範例中,graph_config 字典用於指定 API 金鑰和要使用的模型(gpt-3.5-turbo)。然後,使用提示、來源 URL 和配置初始化 SmartScraperGraph。最後,調用 run() 方法執行抓取過程並列印結果。
配置本地模型
對於本地模型,ScrapeGraphAI 需要更多配置,但仍然簡單:
textfrom scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object]textresult = smart_scraper_graph.run()
print(result)此配置包括指定模型(ollama/llama3)、溫度、格式以及 LLM 和嵌入的基礎 URL。你可以根據特定網頁抓取需求調整模型和其他參數。
了解成本與許可
開源特性
由於 ScrapeGraphAI 是一個開源庫,它是免費使用的。你可以根據許可條款下載、修改和分發它。這種開源特性鼓勵社群貢獻,確保該庫對廣大用戶保持可訪問性。
然而,請注意,使用某些大型語言模型(如 OpenAI 的模型)可能會產生費用。OpenAI、Bardeen AI 等採用基於代幣的計費模式。當你向 LLM 發送提示時,它會處理請求並生成回應。費用取決於提示和回應中使用的代幣數量。因此,監控使用情況並管理 API 金鑰以避免意外費用至關重要。擁有自己的 OpenAI API 金鑰有助於管理。
ScrapeGraphAI 的優缺點
優點
- 使用 LLMs 簡化網頁抓取過程。
- 減少持續維護和調整的需求。
- 支援多種大型語言模型。
- 提供本地 LLM 托管選項,增強隱私和安全性。
- 通過基於圖形的管道增加靈活性和自定義能力。
缺點
- 使用外部 LLM 服務可能產生費用。
- 依賴所選 LLM 的準確性和能力。
- 需要對 Python 和虛擬環境有一定熟悉度。
- 相對較新的庫,社群支援和文件可能仍在發展中。
主要功能
LLM 整合
ScrapeGraphAI 利用大型語言模型(LLMs)進行智能網頁抓取。它能自動檢測並適應網站結構的變化,減少持續手動調整的需求。這一功能節省了大量開發和維護時間。
基於圖形的管道
該庫採用模組化基於圖形的管道,允許高效且結構化的數據提取。這些管道可以自定義以適應不同的網頁抓取場景,提供靈活性和對提取過程的控制。
支援多種 LLMs
ScrapeGraphAI 支援多種 LLMs,包括 GPT、Gemini、Groq、Azure 和 Hugging Face。這種支援使用戶能選擇最適合其需求的模型,無論是用於通用抓取還是更專業的任務。
本地 LLM 托管
通過與 Ollama 整合,ScrapeGraphAI 允許本地托管大型語言模型。這提供了安全且私密的網頁抓取環境,無需依賴外部服務。
ScrapeGraphAI 的多樣化應用場景
電子商務商業智慧
ScrapeGraphAI 可監控產品價格、追蹤競爭對手產品並收集客戶評論,為電子商務企業提供競爭優勢。通過自動化這些數據的收集,企業能做出數據驅動的決策以優化策略。
投資者研究
投資者可利用 ScrapeGraphAI 提取財務數據、分析公司新聞並監控市場趨勢。這些數據為投資者提供做出明智投資決策和管理風險所需的洞察。
行銷與競爭分析
行銷團隊可使用 ScrapeGraphAI 收集客戶反饋、分析社交媒體趨勢並追蹤競爭對手的策略。這些洞察使行銷人員能創建目標明確的活動、優化內容並提升客戶參與度。
常見問題
什麼是 ScrapeGraphAI?
ScrapeGraphAI 是一個開源 Python 庫,旨在使用大型語言模型(LLMs)簡化和自動化網頁抓取。它允許用戶更高效地從網站提取數據,且需要較少的手動編碼。
安裝 ScrapeGraphAI 的先決條件是什麼?
先決條件包括 Python 3.9 或更高版本(但不超過 3.12)、PIP,以及可選的 Ollama 用於運行本地 LLMs。
如何安裝 ScrapeGraphAI?
你可以使用 PIP 命令 pip install scrapegraphai 安裝 ScrapeGraphAI。建議在虛擬環境中安裝。
ScrapeGraphAI 支援哪些大型語言模型?
ScrapeGraphAI 支援 GPT、Gemini、Groq、Azure、Hugging Face 以及使用 Ollama 運行的本地模型。
如何配置 ScrapeGraphAI 以使用 OpenAI 的 GPT 模型?
你需要在 graph_config 字典中設置 OpenAI API 金鑰並指定要使用的模型。
我可以免費使用 ScrapeGraphAI 嗎?
是的,ScrapeGraphAI 是一個開源庫,免費使用。然而,使用像 OpenAI 的某些 LLMs 可能會根據代幣使用量產生費用。
相關問題
ScrapeGraphAI 與傳統網頁抓取工具相比如何?
ScrapeGraphAI 利用 AI 驅動的大型語言模型,減少因網站結構變化而需持續手動調整的需求。傳統工具通常需要更多編碼和維護。ScrapeGraphAI 能適應網站結構的變化,減少對開發者的持續干預需求。這種靈活性確保即使網站佈局改變,抓取器仍能正常運作。使用 ScrapeGraphAI,你只需指定所需資訊,該庫會處理其餘部分。傳統網頁抓取方法自1990年代末和2000年代初互聯網形成時就已存在。當時,網頁抓取需要大量編碼以從 HTML 網頁提取數據。常用正則表達式來解析 HTML 數據,這是一項繁瑣且複雜的任務。這種方法主要用於離線應用,需開發者手動使其上線。
使用 ScrapeGraphAI 時可以定義哪些提示?
此配置包括指定模型(ollama/llama3)、溫度、格式以及 LLM 和嵌入的基礎 URL。你可以根據特定網頁抓取需求調整模型和其他參數。一些常見提示如下:
- 列出所有項目的標題和描述。
- 列出所有內容。
相關文章
 WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
相關專題推薦
商業
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
相關專題推薦
商業
 最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
 10 個工具
10 個工具
 xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai
代碼
最適合自動化單元測試的最佳AI工具:一鍵生成Jest、PyTest和JUnit測試用例
探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

 評論 (8)
0/500
評論 (8)
0/500
![HenryDavis]()
This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎
![RyanJackson]()
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
![KevinAnderson]()
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
![BillyWilson]()
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
![ThomasLewis]()
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
![SamuelAllen]()
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
在當今數據驅動的世界中,從網站提取資訊對於商業智慧、市場研究和競爭分析等各種目的至關重要。網頁抓取,作為從網站自動提取數據的過程,已成為重要工具。然而,傳統網頁抓取方法通常需要複雜的編碼和因網站結構變化而定期更新。這就是 ScrapeGraphAI 的用武之地——一個創新的開源 Python 庫,旨在通過利用大型語言模型(LLMs)的能力來轉變網頁抓取方式。
重點
- ScrapeGraphAI 是一個開源 Python 庫,簡化網頁抓取。
- 它使用大型語言模型(LLMs)更有效地從網站提取數據。
- 該工具通過適應網站變化,減少對開發者的持續干預需求。
- 它支援多種 LLMs,包括 GPT、Gemini、Groq、Azure 和 Hugging Face。
- 使用 pip 安裝簡單,建議使用虛擬環境。
- 與傳統方法相比,ScrapeGraphAI 能以更少的代碼抓取數據並提取特定資訊。
- 通過 Ollama 進行本地托管,提供私有且高效的抓取環境。
了解網頁抓取及其演變
傳統網頁抓取時代
網頁抓取自1990年代末和2000年代初,隨著互聯網的發展而出現。當時,抓取需要大量編碼以從 HTML 頁面提取數據。自定義編碼對於導航不同的線上 HTML 結構至關重要。經常用正則表達式來解析 HTML 數據,這既繁瑣又複雜。這種方法主要用於離線應用,需要手動更新才能上線。整個過程需要大量時間和專業知識,主要限於具備高級編碼技能的人使用。
隨著時間推移,許多工具和技術出現以簡化網頁抓取。Python 以其強大的庫生態系統成為首選語言。像 Beautiful Soup 和 Scrapy 這樣的庫提供了更結構化的數據提取方法,但適應網站結構變化的挑戰依然存在。
隨著大型語言模型(LLMs)的引入,網頁抓取的格局已顯著改變,自動化了許多傳統網頁抓取的複雜性。讓我們來探索一個讓這一切變得更簡單的工具。
介紹 ScrapeGraphAI:重新定義網頁抓取
ScrapeGraphAI 是一個強大的解決方案,利用 AI 驅動的大型語言模型來自動化和簡化網頁抓取過程。它是一個開源 Python 庫,旨在革新我們處理網頁抓取的方式。
與通常依賴固定模式或手動調整的傳統網頁抓取工具不同,ScrapeGraphAI 能適應網站結構的變化,最大程度減少對開發者的持續干預需求。它通過整合大型語言模型(LLMs)和模組化圖形管道來自動化從各種來源抓取數據,脫穎而出。
該庫提供比傳統抓取工具更靈活且低維護的解決方案。它允許用戶從 HTML 標記中輕鬆提取特定資訊,無需大量編碼或處理複雜的正則表達式。你只需指定所需資訊,ScrapeGraphAI 會處理其餘部分。它支援多種 LLMs,包括 GPT、Gemini、Groq 和 Azure,以及可通過 Ollama 在本地運行的模型。
關鍵組件與架構
ScrapeGraphAI 使用不同的解析節點來處理各個部分的 HTML 節點。它使用搜索節點來精確定位 HTML 頁面中的特定區域。智能圖形構建器管理所有 HTML 標記語言。
以下是其架構的簡要概述:
- 節點類型: ScrapeGraphAI 使用多種解析節點來處理 HTML 的不同部分,包括條件節點、獲取節點、解析節點、Rag 節點和搜索節點。這些節點支援條件解析、數據獲取、內容解析和在 HTML 結構中搜索相關資訊。
- 圖形構建器: ScrapeGraphAI 的智能圖形構建器通過處理所有 HTML 標記語言,簡化所需資訊的提取。
- 大型語言模型(LLMs): ScrapeGraphAI 支援 Gemini 和 OpenAI 等 LLMs,利用其自然語言處理能力進行高效數據提取。
該庫允許手動定義圖形或讓 LLM 根據提示創建圖形,增加了靈活性,滿足不同用戶需求和項目要求。這種高層次架構使實現複雜的抓取管道變得更簡單,只需最少的編碼。
設置 ScrapeGraphAI:安裝與配置
先決條件與安裝步驟
在開始使用 ScrapeGraphAI 之前,請確保你的系統滿足必要的先決條件。
以下是設置的詳細指南:
- Python 版本: ScrapeGraphAI 需要 Python 3.9 或更高版本,但不超過 3.12。Python 3.10 通常足夠。
- PIP: 確保你擁有最新版本的 PIP,Python 套件安裝程式。你可以使用命令 pip install --upgrade pip 更新它。
- Ollama(可選): 如果你計劃運行本地大型語言模型,需安裝 Ollama。請參閱文件以獲取詳細的安裝和設置說明。
確認這些先決條件後,安裝 ScrapeGraphAI 非常簡單:
強烈建議在虛擬環境(conda、venv 等)中安裝 ScrapeGraphAI,以避免與系統中其他 Python 套件衝突。
對於 Windows 用戶,你可以使用 Windows 子系統 Linux(WSL)安裝額外庫。
選擇合適的大型語言模型
使用 ScrapeGraphAI 時的關鍵決定之一是為你的網頁抓取需求選擇合適的大型語言模型(LLM)。ScrapeGraphAI 支援多種 LLMs,每種都有其優勢和能力:
- OpenAI 的 GPT 模型: GPT-3.5 Turbo 和 GPT-4 是通用網頁抓取任務的強大選擇。這些模型能有效理解和提取不同網站結構的資訊。
- Gemini: 提供先進的自然語言處理能力,適用於複雜的數據提取任務。
- Groq: 以速度和效率著稱,當需要快速處理大量網頁數據時,Groq 是絕佳選擇。
- Azure: 提供企業級安全性和可擴展性,適合有嚴格數據隱私要求的組織。
- Hugging Face: 提供廣泛的開源 LLMs,允許你為特定網頁抓取任務自定義和微調模型。
對於關注數據隱私或成本的用戶,ScrapeGraphAI 允許使用 Ollama 運行本地 LLMs。這種設置使你能利用 LLMs 的力量,而無需依賴外部服務。
實際範例:使用 ScrapeGraphAI 進行抓取
設置 OpenAI 模型
要連接和使用 OpenAI 模型,你需要導入必要的庫並設置你的 API 金鑰。以下是如何配置 ScrapeGraphAI 以使用 OpenAI 的 GPT 模型的範例:
import os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object],[object Object]result = smart_scraper_graph.run()
print(result)在此範例中,graph_config 字典用於指定 API 金鑰和要使用的模型(gpt-3.5-turbo)。然後,使用提示、來源 URL 和配置初始化 SmartScraperGraph。最後,調用 run() 方法執行抓取過程並列印結果。
配置本地模型
對於本地模型,ScrapeGraphAI 需要更多配置,但仍然簡單:
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object]result = smart_scraper_graph.run()
print(result)此配置包括指定模型(ollama/llama3)、溫度、格式以及 LLM 和嵌入的基礎 URL。你可以根據特定網頁抓取需求調整模型和其他參數。
了解成本與許可
開源特性
由於 ScrapeGraphAI 是一個開源庫,它是免費使用的。你可以根據許可條款下載、修改和分發它。這種開源特性鼓勵社群貢獻,確保該庫對廣大用戶保持可訪問性。
然而,請注意,使用某些大型語言模型(如 OpenAI 的模型)可能會產生費用。OpenAI、Bardeen AI 等採用基於代幣的計費模式。當你向 LLM 發送提示時,它會處理請求並生成回應。費用取決於提示和回應中使用的代幣數量。因此,監控使用情況並管理 API 金鑰以避免意外費用至關重要。擁有自己的 OpenAI API 金鑰有助於管理。
ScrapeGraphAI 的優缺點
優點
- 使用 LLMs 簡化網頁抓取過程。
- 減少持續維護和調整的需求。
- 支援多種大型語言模型。
- 提供本地 LLM 托管選項,增強隱私和安全性。
- 通過基於圖形的管道增加靈活性和自定義能力。
缺點
- 使用外部 LLM 服務可能產生費用。
- 依賴所選 LLM 的準確性和能力。
- 需要對 Python 和虛擬環境有一定熟悉度。
- 相對較新的庫,社群支援和文件可能仍在發展中。
主要功能
LLM 整合
ScrapeGraphAI 利用大型語言模型(LLMs)進行智能網頁抓取。它能自動檢測並適應網站結構的變化,減少持續手動調整的需求。這一功能節省了大量開發和維護時間。
基於圖形的管道
該庫採用模組化基於圖形的管道,允許高效且結構化的數據提取。這些管道可以自定義以適應不同的網頁抓取場景,提供靈活性和對提取過程的控制。
支援多種 LLMs
ScrapeGraphAI 支援多種 LLMs,包括 GPT、Gemini、Groq、Azure 和 Hugging Face。這種支援使用戶能選擇最適合其需求的模型,無論是用於通用抓取還是更專業的任務。
本地 LLM 托管
通過與 Ollama 整合,ScrapeGraphAI 允許本地托管大型語言模型。這提供了安全且私密的網頁抓取環境,無需依賴外部服務。
ScrapeGraphAI 的多樣化應用場景
電子商務商業智慧
ScrapeGraphAI 可監控產品價格、追蹤競爭對手產品並收集客戶評論,為電子商務企業提供競爭優勢。通過自動化這些數據的收集,企業能做出數據驅動的決策以優化策略。
投資者研究
投資者可利用 ScrapeGraphAI 提取財務數據、分析公司新聞並監控市場趨勢。這些數據為投資者提供做出明智投資決策和管理風險所需的洞察。
行銷與競爭分析
行銷團隊可使用 ScrapeGraphAI 收集客戶反饋、分析社交媒體趨勢並追蹤競爭對手的策略。這些洞察使行銷人員能創建目標明確的活動、優化內容並提升客戶參與度。
常見問題
什麼是 ScrapeGraphAI?
ScrapeGraphAI 是一個開源 Python 庫,旨在使用大型語言模型(LLMs)簡化和自動化網頁抓取。它允許用戶更高效地從網站提取數據,且需要較少的手動編碼。
安裝 ScrapeGraphAI 的先決條件是什麼?
先決條件包括 Python 3.9 或更高版本(但不超過 3.12)、PIP,以及可選的 Ollama 用於運行本地 LLMs。
如何安裝 ScrapeGraphAI?
你可以使用 PIP 命令 pip install scrapegraphai 安裝 ScrapeGraphAI。建議在虛擬環境中安裝。
ScrapeGraphAI 支援哪些大型語言模型?
ScrapeGraphAI 支援 GPT、Gemini、Groq、Azure、Hugging Face 以及使用 Ollama 運行的本地模型。
如何配置 ScrapeGraphAI 以使用 OpenAI 的 GPT 模型?
你需要在 graph_config 字典中設置 OpenAI API 金鑰並指定要使用的模型。
我可以免費使用 ScrapeGraphAI 嗎?
是的,ScrapeGraphAI 是一個開源庫,免費使用。然而,使用像 OpenAI 的某些 LLMs 可能會根據代幣使用量產生費用。
相關問題
ScrapeGraphAI 與傳統網頁抓取工具相比如何?
ScrapeGraphAI 利用 AI 驅動的大型語言模型,減少因網站結構變化而需持續手動調整的需求。傳統工具通常需要更多編碼和維護。ScrapeGraphAI 能適應網站結構的變化,減少對開發者的持續干預需求。這種靈活性確保即使網站佈局改變,抓取器仍能正常運作。使用 ScrapeGraphAI,你只需指定所需資訊,該庫會處理其餘部分。傳統網頁抓取方法自1990年代末和2000年代初互聯網形成時就已存在。當時,網頁抓取需要大量編碼以從 HTML 網頁提取數據。常用正則表達式來解析 HTML 數據,這是一項繁瑣且複雜的任務。這種方法主要用於離線應用,需開發者手動使其上線。
使用 ScrapeGraphAI 時可以定義哪些提示?
此配置包括指定模型(ollama/llama3)、溫度、格式以及 LLM 和嵌入的基礎 URL。你可以根據特定網頁抓取需求調整模型和其他參數。一些常見提示如下:
- 列出所有項目的標題和描述。
- 列出所有內容。










 WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
 Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
 DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎













