




ScrapeGraphAI: Guía para Revolucionar el Web Scraping
En el mundo actual impulsado por datos, extraer información de sitios web es esencial para diversos propósitos, como inteligencia de negocios, investigación de mercado y análisis competitivo. El web scraping, el proceso automatizado de obtener datos de sitios web, se ha convertido en una herramienta vital. Sin embargo, los métodos tradicionales de web scraping a menudo requieren una codificación compleja y actualizaciones regulares debido a los cambios en las estructuras de los sitios web. Aquí es donde entra en juego ScrapeGraphAI, una innovadora biblioteca de Python de código abierto que busca transformar el web scraping al aprovechar las capacidades de los modelos de lenguaje de gran escala (LLMs).
Puntos clave
- ScrapeGraphAI es una biblioteca de Python de código abierto que simplifica el web scraping.
- Utiliza modelos de lenguaje de gran escala (LLMs) para extraer datos de sitios web de manera más efectiva.
- La herramienta reduce la necesidad de intervención continua de desarrolladores al adaptarse a los cambios en los sitios web.
- Es compatible con una variedad de LLMs, incluyendo GPT, Gemini, Groq, Azure y Hugging Face.
- La instalación es sencilla con pip, y se recomienda usar un entorno virtual.
- ScrapeGraphAI permite a los usuarios extraer datos y obtener información específica con menos código en comparación con los métodos tradicionales.
- El alojamiento local a través de Ollama ofrece un entorno de scraping privado y eficiente.
Entendiendo el web scraping y su evolución
La era del web scraping tradicional
El web scraping existe desde finales de los años 90 y principios de los 2000, cuando internet comenzó a evolucionar. En ese entonces, el scraping involucraba una codificación intensiva para extraer datos de páginas HTML. La codificación personalizada era crucial para navegar a través de las diferentes estructuras HTML que se encontraban en línea. Las expresiones regulares se usaban frecuentemente para analizar datos HTML, lo que era tedioso y complejo. Este método se utilizaba principalmente en aplicaciones sin conexión, requiriendo actualizaciones manuales para operar en línea. Todo el proceso demandaba un tiempo considerable y experiencia, haciéndolo accesible principalmente para aquellos con habilidades avanzadas de codificación.
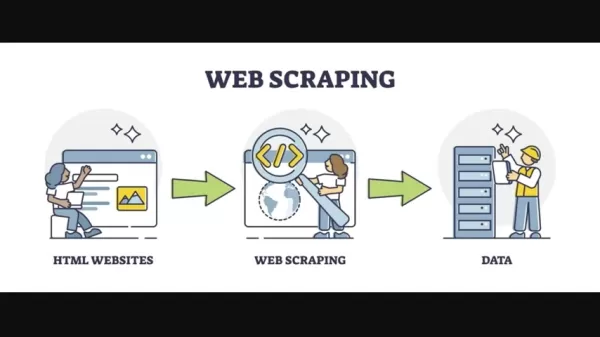
Con el tiempo, han surgido numerosas herramientas y técnicas para simplificar el web scraping. Python, con su robusto ecosistema de bibliotecas, se ha convertido en un lenguaje preferido para esta tarea. Bibliotecas como Beautiful Soup y Scrapy han ofrecido métodos de extracción de datos más estructurados, pero el desafío de adaptarse a los cambios en las estructuras de los sitios web persistía.
El panorama ha cambiado significativamente con la introducción de modelos de lenguaje de gran escala (LLMs) que automatizan gran parte de la complejidad del web scraping tradicional. Exploremos una herramienta que ha facilitado esto.
Presentando ScrapeGraphAI: Web Scraping Reimaginado
ScrapeGraphAI surge como una solución poderosa, utilizando modelos de lenguaje de gran escala impulsados por IA para automatizar y simplificar el proceso de web scraping. Es una biblioteca de Python de código abierto diseñada para revolucionar la forma en que abordamos el web scraping.
A diferencia de las herramientas tradicionales de web scraping, que a menudo dependen de patrones fijos o ajustes manuales, ScrapeGraphAI se adapta a los cambios en las estructuras de los sitios web, minimizando la necesidad de intervención constante de desarrolladores. Se destaca por integrar modelos de lenguaje de gran escala (LLMs) y pipelines modulares basados en grafos para automatizar la extracción de datos de diversas fuentes.
Esta biblioteca proporciona una solución más flexible y de bajo mantenimiento en comparación con las herramientas de scraping tradicionales. Permite a los usuarios extraer información específica de marcado HTML sin necesidad de una codificación extensa o lidiar con expresiones regulares complejas. Solo necesitas especificar qué información necesitas, y ScrapeGraphAI se encarga del resto. Es compatible con múltiples LLMs, incluyendo GPT, Gemini, Groq y Azure, así como modelos locales que pueden ejecutarse en tu máquina usando Ollama.
Componentes clave y arquitectura
ScrapeGraphAI emplea diferentes nodos de análisis para manejar todos los nodos HTML en varias secciones. Utiliza nodos de búsqueda para identificar áreas específicas dentro de la página HTML. El constructor de grafos inteligente gestiona todo el lenguaje de marcado en HTML.
Aquí tienes una visión general de su arquitectura:
- Tipos de nodos: ScrapeGraphAI utiliza varios nodos de análisis para procesar diferentes secciones de HTML, incluyendo nodos condicionales, nodos de obtención, nodos de análisis, nodos Rag y nodos de búsqueda. Estos nodos permiten el análisis condicional, la obtención de datos, el análisis de contenido y la búsqueda de información relevante dentro de la estructura HTML.
- Constructor de grafos: El constructor de grafos inteligente de ScrapeGraphAI simplifica la extracción de la información deseada al manejar todo el lenguaje de marcado HTML.
- Modelos de lenguaje de gran escala (LLMs): ScrapeGraphAI es compatible con LLMs como Gemini y OpenAI, aprovechando sus capacidades de procesamiento de lenguaje natural para una extracción de datos eficiente.
La capacidad de la biblioteca para definir grafos manualmente o permitir que el LLM cree grafos basados en prompts agrega una capa de flexibilidad que satisface diferentes necesidades y requisitos de proyectos de los usuarios. Esta arquitectura de alto nivel facilita la implementación de pipelines de scraping complejos con un mínimo de codificación.
Configurando ScrapeGraphAI: Instalación y configuración
Requisitos previos y pasos de instalación
Antes de sumergirte en ScrapeGraphAI, asegúrate de que tu sistema cumpla con los requisitos necesarios.
Aquí tienes una guía detallada para configurarlo todo:
- Versión de Python: ScrapeGraphAI requiere Python 3.9 o superior, pero no más de 3.12. Python 3.10 suele ser suficiente.
- PIP: Asegúrate de tener la última versión de PIP, el instalador de paquetes de Python. Puedes actualizarlo usando el comando pip install --upgrade pip.
- Ollama (Opcional): Si planeas ejecutar modelos de lenguaje de gran escala locales, necesitarás instalar Ollama. Consulta la documentación para obtener instrucciones detalladas de instalación y configuración.
Una vez que hayas confirmado estos requisitos previos, instalar ScrapeGraphAI es sencillo:
pip install scrapegraphaiEs altamente recomendable instalar ScrapeGraphAI en un entorno virtual (conda, venv, etc.) para evitar conflictos con otros paquetes de Python en tu sistema.
Para usuarios de Windows, puedes usar el Subsistema de Windows para Linux (WSL) para instalar bibliotecas adicionales.
Eligiendo el modelo de lenguaje de gran escala adecuado
Una de las decisiones clave al usar ScrapeGraphAI es seleccionar el modelo de lenguaje de gran escala (LLM) adecuado para tus necesidades de web scraping. ScrapeGraphAI es compatible con varios LLMs, cada uno con sus fortalezas y capacidades:
- Modelos GPT de OpenAI: GPT-3.5 Turbo y GPT-4 son opciones potentes para tareas de web scraping de propósito general. Estos modelos pueden entender y extraer información de estructuras de sitios web diversas de manera efectiva.
- Gemini: Ofrece capacidades avanzadas de procesamiento de lenguaje natural, lo que lo hace adecuado para tareas de extracción de datos complejas.
- Groq: Conocido por su velocidad y eficiencia, Groq es una excelente opción cuando necesitas procesar grandes volúmenes de datos web rápidamente.
- Azure: Proporciona seguridad y escalabilidad de grado empresarial, lo que lo hace ideal para organizaciones con requisitos estrictos de privacidad de datos.
- Hugging Face: Ofrece una amplia gama de LLMs de código abierto, lo que te permite personalizar y ajustar modelos para tareas específicas de web scraping.
Para aquellos preocupados por la privacidad o los costos de los datos, ScrapeGraphAI permite ejecutar LLMs locales usando Ollama. Esta configuración te permite aprovechar el poder de los LLMs sin depender de servicios externos.
Ejemplos prácticos: Scraping con ScrapeGraphAI
Configurando modelos de OpenAI
Para conectar y usar modelos de OpenAI, necesitarás importar las bibliotecas necesarias y configurar tu clave API. Aquí tienes un ejemplo de cómo configurar ScrapeGraphAI con los modelos GPT de OpenAI:
textimport os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object],[object Object]textresult = smart_scraper_graph.run()
print(result)En este ejemplo, el diccionario graph_config se define para especificar la clave API y el modelo que deseas usar (gpt-3.5-turbo). Luego, se inicializa SmartScraperGraph con un prompt, la URL de origen y la configuración. Finalmente, se llama al método run() para ejecutar el proceso de scraping e imprimir los resultados.
Configurando modelos locales
Para modelos locales, ScrapeGraphAI requiere un poco más de configuración, pero sigue siendo sencillo:
textfrom scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object]textresult = smart_scraper_graph.run()
print(result)Esta configuración incluye especificar el modelo (ollama/llama3), la temperatura, el formato y las URLs base para el LLM y los embeddings. Puedes ajustar el modelo y otros parámetros según sea necesario para adaptarse a tus requisitos específicos de web scraping.
Entendiendo costos y licencias
Naturaleza de código abierto
Dado que ScrapeGraphAI es una biblioteca de código abierto, es gratuita para usar. Puedes descargarla, modificarla y distribuirla según los términos de la licencia. Esta naturaleza abierta fomenta las contribuciones de la comunidad y asegura que la biblioteca siga siendo accesible para una amplia audiencia.
Sin embargo, ten en cuenta que el uso de ciertos modelos de lenguaje de gran escala, como los de OpenAI, puede generar costos. OpenAI, Bardeen AI y otros operan con un modelo de precios basado en tokens. Cuando envías un prompt al LLM, este procesa la solicitud y genera una respuesta. El costo depende de la cantidad de tokens utilizados en el prompt y la respuesta. Por lo tanto, es esencial monitorear tu uso y gestionar tus claves API para evitar cargos inesperados. Es útil tener tu propia clave API para OpenAI.
Ventajas y desventajas de ScrapeGraphAI
Ventajas
- Proceso de web scraping simplificado usando LLMs.
- Reducción de la necesidad de mantenimiento y ajustes continuos.
- Compatibilidad con varios modelos de lenguaje de gran escala.
- Opción de alojamiento local de LLMs para mayor privacidad y seguridad.
- Mayor flexibilidad y personalización a través de pipelines basados en grafos.
Desventajas
- Costos potenciales asociados con el uso de servicios de LLMs externos.
- Dependencia de la precisión y las capacidades del LLM elegido.
- Requiere cierta familiaridad con Python y entornos virtuales.
- Biblioteca relativamente nueva, por lo que el soporte de la comunidad y la documentación aún pueden estar creciendo.
Características clave
Integración con LLMs
ScrapeGraphAI aprovecha los modelos de lenguaje de gran escala (LLMs) para un web scraping inteligente. Puede detectar y adaptarse automáticamente a los cambios en las estructuras de los sitios web, reduciendo la necesidad de ajustes manuales continuos. Esta característica por sí sola ahorra un tiempo significativo de desarrollo y mantenimiento.
Pipelines basados en grafos
La biblioteca emplea pipelines modulares basados en grafos que permiten una extracción de datos eficiente y estructurada. Estos pipelines pueden personalizarse para adaptarse a diferentes escenarios de web scraping, proporcionando flexibilidad y control sobre el proceso de extracción.
Compatibilidad con múltiples LLMs
ScrapeGraphAI es compatible con una variedad de LLMs, incluyendo GPT, Gemini, Groq, Azure y Hugging Face. Esta compatibilidad permite a los usuarios seleccionar el modelo que mejor se adapte a sus necesidades, ya sea para scraping de propósito general o tareas más especializadas.
Alojamiento local de LLMs
Con la integración de Ollama, ScrapeGraphAI permite alojar modelos de lenguaje de gran escala localmente. Esto proporciona un entorno de web scraping seguro y privado, sin depender de servicios externos.
Casos de uso diversos para ScrapeGraphAI
Inteligencia de negocios para comercio electrónico
ScrapeGraphAI puede usarse para monitorear precios de productos, rastrear ofertas de competidores y recopilar reseñas de clientes, proporcionando a las empresas de comercio electrónico una ventaja competitiva. Al automatizar la recolección de estos datos, las empresas pueden tomar decisiones basadas en datos para optimizar sus estrategias.
Investigación para inversores
Los inversores pueden aprovechar ScrapeGraphAI para extraer datos financieros, analizar noticias de empresas y monitorear tendencias de mercado. Estos datos proporcionan a los inversores la información necesaria para tomar decisiones de inversión informadas y gestionar riesgos de manera efectiva.
Análisis de marketing y competitivo
Los equipos de marketing pueden usar ScrapeGraphAI para recopilar comentarios de clientes, analizar tendencias de redes sociales y rastrear estrategias de competidores. Estas ideas permiten a los marketers crear campañas dirigidas, optimizar su contenido y mejorar la participación del cliente.
Preguntas frecuentes
¿Qué es ScrapeGraphAI?
ScrapeGraphAI es una biblioteca de Python de código abierto diseñada para simplificar y automatizar el web scraping utilizando modelos de lenguaje de gran escala (LLMs). Permite a los usuarios extraer datos de sitios web de manera más eficiente y con menos codificación manual.
¿Cuáles son los requisitos previos para instalar ScrapeGraphAI?
Los requisitos previos incluyen Python 3.9 o superior (pero no más de 3.12), PIP y, opcionalmente, Ollama para ejecutar LLMs locales.
¿Cómo instalo ScrapeGraphAI?
Puedes instalar ScrapeGraphAI usando PIP con el comando pip install scrapegraphai. Se recomienda instalarlo en un entorno virtual.
¿Qué modelos de lenguaje de gran escala soporta ScrapeGraphAI?
ScrapeGraphAI es compatible con GPT, Gemini, Groq, Azure, Hugging Face y modelos locales ejecutados usando Ollama.
¿Cómo configuro ScrapeGraphAI para usar los modelos GPT de OpenAI?
Necesitas configurar tu clave API de OpenAI en el diccionario graph_config y especificar el modelo que deseas usar.
¿Puedo usar ScrapeGraphAI gratis?
Sí, ScrapeGraphAI es una biblioteca de código abierto y es gratuita para usar. Sin embargo, el uso de ciertos LLMs como los de OpenAI puede generar costos basados en el uso de tokens.
Preguntas relacionadas
¿Cómo se compara ScrapeGraphAI con las herramientas de web scraping tradicionales?
ScrapeGraphAI aprovecha los modelos de lenguaje de gran escala impulsados por IA, reduciendo la necesidad de ajustes manuales constantes debido a los cambios en la estructura de los sitios web. Las herramientas tradicionales a menudo requieren más codificación y mantenimiento. ScrapeGraphAI se adapta a los cambios en las estructuras de los sitios web, reduciendo la necesidad de intervención constante de desarrolladores. Esta flexibilidad asegura que los scrapers sigan siendo funcionales incluso cuando cambian los diseños de los sitios web. Con ScrapeGraphAI, solo necesitas especificar qué información necesitas, y la biblioteca se encarga del resto. El método tradicional de web scraping ha existido desde finales de los años 90 y principios de los 2000, cuando internet comenzó a tomar forma. En esos días, el web scraping involucraba una codificación pesada para extraer datos de páginas web HTML. Las expresiones regulares se usaban comúnmente para analizar datos HTML, lo que era una tarea tediosa y compleja. Este enfoque se utilizaba principalmente en aplicaciones sin conexión, requiriendo que los desarrolladores las pusieran en línea manualmente.
¿Qué tipo de prompts se pueden definir al usar ScrapeGraphAI?
Esta configuración incluye especificar el modelo (ollama/llama3), la temperatura, el formato y las URLs base para el LLM y los embeddings. Puedes ajustar el modelo y otros parámetros según sea necesario para adaptarse a tus requisitos específicos de web scraping. Algunos prompts comunes son los siguientes:
- Listar todos los proyectos con sus títulos y descripciones.
- Listar todo el contenido.
Artículo relacionado
 Edición de audio maestra en DaVinci Resolve: Guía Fairlight para Sonido Profesional
Un audio nítido separa las producciones amateur de los contenidos de vídeo profesionales. La página Fairlight de DaVinci Resolve ofrece a cineastas y creadores de contenidos sofisticadas herramientas
La IA de Google ya gestiona las llamadas telefónicas por ti
Google ha ampliado a todos los usuarios de EE.UU. su función de llamadas con inteligencia artificial a través de la Búsqueda, lo que permite a los clientes consultar precios y disponibilidad con empre
Trump exime a smartphones, ordenadores y chips de la subida de aranceles
La administración Trump ha concedido exclusiones para smartphones, ordenadores y diversos dispositivos electrónicos de las recientes subidas de aranceles, incluso cuando se importan de China, según in
comentario (8)
0/200
Edición de audio maestra en DaVinci Resolve: Guía Fairlight para Sonido Profesional
Un audio nítido separa las producciones amateur de los contenidos de vídeo profesionales. La página Fairlight de DaVinci Resolve ofrece a cineastas y creadores de contenidos sofisticadas herramientas
La IA de Google ya gestiona las llamadas telefónicas por ti
Google ha ampliado a todos los usuarios de EE.UU. su función de llamadas con inteligencia artificial a través de la Búsqueda, lo que permite a los clientes consultar precios y disponibilidad con empre
Trump exime a smartphones, ordenadores y chips de la subida de aranceles
La administración Trump ha concedido exclusiones para smartphones, ordenadores y diversos dispositivos electrónicos de las recientes subidas de aranceles, incluso cuando se importan de China, según in
comentario (8)
0/200
![HenryDavis]() HenryDavis
HenryDavis
 5 de agosto de 2025 11:00:59 GMT+02:00
5 de agosto de 2025 11:00:59 GMT+02:00
This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎


 0
0
![RyanJackson]() RyanJackson
1 de agosto de 2025 08:45:46 GMT+02:00
RyanJackson
1 de agosto de 2025 08:45:46 GMT+02:00
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
0
![KevinAnderson]() KevinAnderson
28 de julio de 2025 03:19:30 GMT+02:00
KevinAnderson
28 de julio de 2025 03:19:30 GMT+02:00
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
0
![BillyWilson]() BillyWilson
13 de mayo de 2025 23:23:52 GMT+02:00
BillyWilson
13 de mayo de 2025 23:23:52 GMT+02:00
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
0
![ThomasLewis]() ThomasLewis
13 de mayo de 2025 22:47:14 GMT+02:00
ThomasLewis
13 de mayo de 2025 22:47:14 GMT+02:00
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
0
![SamuelAllen]() SamuelAllen
13 de mayo de 2025 17:53:23 GMT+02:00
SamuelAllen
13 de mayo de 2025 17:53:23 GMT+02:00
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
0
En el mundo actual impulsado por datos, extraer información de sitios web es esencial para diversos propósitos, como inteligencia de negocios, investigación de mercado y análisis competitivo. El web scraping, el proceso automatizado de obtener datos de sitios web, se ha convertido en una herramienta vital. Sin embargo, los métodos tradicionales de web scraping a menudo requieren una codificación compleja y actualizaciones regulares debido a los cambios en las estructuras de los sitios web. Aquí es donde entra en juego ScrapeGraphAI, una innovadora biblioteca de Python de código abierto que busca transformar el web scraping al aprovechar las capacidades de los modelos de lenguaje de gran escala (LLMs).
Puntos clave
- ScrapeGraphAI es una biblioteca de Python de código abierto que simplifica el web scraping.
- Utiliza modelos de lenguaje de gran escala (LLMs) para extraer datos de sitios web de manera más efectiva.
- La herramienta reduce la necesidad de intervención continua de desarrolladores al adaptarse a los cambios en los sitios web.
- Es compatible con una variedad de LLMs, incluyendo GPT, Gemini, Groq, Azure y Hugging Face.
- La instalación es sencilla con pip, y se recomienda usar un entorno virtual.
- ScrapeGraphAI permite a los usuarios extraer datos y obtener información específica con menos código en comparación con los métodos tradicionales.
- El alojamiento local a través de Ollama ofrece un entorno de scraping privado y eficiente.
Entendiendo el web scraping y su evolución
La era del web scraping tradicional
El web scraping existe desde finales de los años 90 y principios de los 2000, cuando internet comenzó a evolucionar. En ese entonces, el scraping involucraba una codificación intensiva para extraer datos de páginas HTML. La codificación personalizada era crucial para navegar a través de las diferentes estructuras HTML que se encontraban en línea. Las expresiones regulares se usaban frecuentemente para analizar datos HTML, lo que era tedioso y complejo. Este método se utilizaba principalmente en aplicaciones sin conexión, requiriendo actualizaciones manuales para operar en línea. Todo el proceso demandaba un tiempo considerable y experiencia, haciéndolo accesible principalmente para aquellos con habilidades avanzadas de codificación.
Con el tiempo, han surgido numerosas herramientas y técnicas para simplificar el web scraping. Python, con su robusto ecosistema de bibliotecas, se ha convertido en un lenguaje preferido para esta tarea. Bibliotecas como Beautiful Soup y Scrapy han ofrecido métodos de extracción de datos más estructurados, pero el desafío de adaptarse a los cambios en las estructuras de los sitios web persistía.
El panorama ha cambiado significativamente con la introducción de modelos de lenguaje de gran escala (LLMs) que automatizan gran parte de la complejidad del web scraping tradicional. Exploremos una herramienta que ha facilitado esto.
Presentando ScrapeGraphAI: Web Scraping Reimaginado
ScrapeGraphAI surge como una solución poderosa, utilizando modelos de lenguaje de gran escala impulsados por IA para automatizar y simplificar el proceso de web scraping. Es una biblioteca de Python de código abierto diseñada para revolucionar la forma en que abordamos el web scraping.
A diferencia de las herramientas tradicionales de web scraping, que a menudo dependen de patrones fijos o ajustes manuales, ScrapeGraphAI se adapta a los cambios en las estructuras de los sitios web, minimizando la necesidad de intervención constante de desarrolladores. Se destaca por integrar modelos de lenguaje de gran escala (LLMs) y pipelines modulares basados en grafos para automatizar la extracción de datos de diversas fuentes.
Esta biblioteca proporciona una solución más flexible y de bajo mantenimiento en comparación con las herramientas de scraping tradicionales. Permite a los usuarios extraer información específica de marcado HTML sin necesidad de una codificación extensa o lidiar con expresiones regulares complejas. Solo necesitas especificar qué información necesitas, y ScrapeGraphAI se encarga del resto. Es compatible con múltiples LLMs, incluyendo GPT, Gemini, Groq y Azure, así como modelos locales que pueden ejecutarse en tu máquina usando Ollama.
Componentes clave y arquitectura
ScrapeGraphAI emplea diferentes nodos de análisis para manejar todos los nodos HTML en varias secciones. Utiliza nodos de búsqueda para identificar áreas específicas dentro de la página HTML. El constructor de grafos inteligente gestiona todo el lenguaje de marcado en HTML.
Aquí tienes una visión general de su arquitectura:
- Tipos de nodos: ScrapeGraphAI utiliza varios nodos de análisis para procesar diferentes secciones de HTML, incluyendo nodos condicionales, nodos de obtención, nodos de análisis, nodos Rag y nodos de búsqueda. Estos nodos permiten el análisis condicional, la obtención de datos, el análisis de contenido y la búsqueda de información relevante dentro de la estructura HTML.
- Constructor de grafos: El constructor de grafos inteligente de ScrapeGraphAI simplifica la extracción de la información deseada al manejar todo el lenguaje de marcado HTML.
- Modelos de lenguaje de gran escala (LLMs): ScrapeGraphAI es compatible con LLMs como Gemini y OpenAI, aprovechando sus capacidades de procesamiento de lenguaje natural para una extracción de datos eficiente.
La capacidad de la biblioteca para definir grafos manualmente o permitir que el LLM cree grafos basados en prompts agrega una capa de flexibilidad que satisface diferentes necesidades y requisitos de proyectos de los usuarios. Esta arquitectura de alto nivel facilita la implementación de pipelines de scraping complejos con un mínimo de codificación.
Configurando ScrapeGraphAI: Instalación y configuración
Requisitos previos y pasos de instalación
Antes de sumergirte en ScrapeGraphAI, asegúrate de que tu sistema cumpla con los requisitos necesarios.
Aquí tienes una guía detallada para configurarlo todo:
- Versión de Python: ScrapeGraphAI requiere Python 3.9 o superior, pero no más de 3.12. Python 3.10 suele ser suficiente.
- PIP: Asegúrate de tener la última versión de PIP, el instalador de paquetes de Python. Puedes actualizarlo usando el comando pip install --upgrade pip.
- Ollama (Opcional): Si planeas ejecutar modelos de lenguaje de gran escala locales, necesitarás instalar Ollama. Consulta la documentación para obtener instrucciones detalladas de instalación y configuración.
Una vez que hayas confirmado estos requisitos previos, instalar ScrapeGraphAI es sencillo:
Es altamente recomendable instalar ScrapeGraphAI en un entorno virtual (conda, venv, etc.) para evitar conflictos con otros paquetes de Python en tu sistema.
Para usuarios de Windows, puedes usar el Subsistema de Windows para Linux (WSL) para instalar bibliotecas adicionales.
Eligiendo el modelo de lenguaje de gran escala adecuado
Una de las decisiones clave al usar ScrapeGraphAI es seleccionar el modelo de lenguaje de gran escala (LLM) adecuado para tus necesidades de web scraping. ScrapeGraphAI es compatible con varios LLMs, cada uno con sus fortalezas y capacidades:
- Modelos GPT de OpenAI: GPT-3.5 Turbo y GPT-4 son opciones potentes para tareas de web scraping de propósito general. Estos modelos pueden entender y extraer información de estructuras de sitios web diversas de manera efectiva.
- Gemini: Ofrece capacidades avanzadas de procesamiento de lenguaje natural, lo que lo hace adecuado para tareas de extracción de datos complejas.
- Groq: Conocido por su velocidad y eficiencia, Groq es una excelente opción cuando necesitas procesar grandes volúmenes de datos web rápidamente.
- Azure: Proporciona seguridad y escalabilidad de grado empresarial, lo que lo hace ideal para organizaciones con requisitos estrictos de privacidad de datos.
- Hugging Face: Ofrece una amplia gama de LLMs de código abierto, lo que te permite personalizar y ajustar modelos para tareas específicas de web scraping.
Para aquellos preocupados por la privacidad o los costos de los datos, ScrapeGraphAI permite ejecutar LLMs locales usando Ollama. Esta configuración te permite aprovechar el poder de los LLMs sin depender de servicios externos.
Ejemplos prácticos: Scraping con ScrapeGraphAI
Configurando modelos de OpenAI
Para conectar y usar modelos de OpenAI, necesitarás importar las bibliotecas necesarias y configurar tu clave API. Aquí tienes un ejemplo de cómo configurar ScrapeGraphAI con los modelos GPT de OpenAI:
import os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object],[object Object]result = smart_scraper_graph.run()
print(result)En este ejemplo, el diccionario graph_config se define para especificar la clave API y el modelo que deseas usar (gpt-3.5-turbo). Luego, se inicializa SmartScraperGraph con un prompt, la URL de origen y la configuración. Finalmente, se llama al método run() para ejecutar el proceso de scraping e imprimir los resultados.
Configurando modelos locales
Para modelos locales, ScrapeGraphAI requiere un poco más de configuración, pero sigue siendo sencillo:
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object]result = smart_scraper_graph.run()
print(result)Esta configuración incluye especificar el modelo (ollama/llama3), la temperatura, el formato y las URLs base para el LLM y los embeddings. Puedes ajustar el modelo y otros parámetros según sea necesario para adaptarse a tus requisitos específicos de web scraping.
Entendiendo costos y licencias
Naturaleza de código abierto
Dado que ScrapeGraphAI es una biblioteca de código abierto, es gratuita para usar. Puedes descargarla, modificarla y distribuirla según los términos de la licencia. Esta naturaleza abierta fomenta las contribuciones de la comunidad y asegura que la biblioteca siga siendo accesible para una amplia audiencia.
Sin embargo, ten en cuenta que el uso de ciertos modelos de lenguaje de gran escala, como los de OpenAI, puede generar costos. OpenAI, Bardeen AI y otros operan con un modelo de precios basado en tokens. Cuando envías un prompt al LLM, este procesa la solicitud y genera una respuesta. El costo depende de la cantidad de tokens utilizados en el prompt y la respuesta. Por lo tanto, es esencial monitorear tu uso y gestionar tus claves API para evitar cargos inesperados. Es útil tener tu propia clave API para OpenAI.
Ventajas y desventajas de ScrapeGraphAI
Ventajas
- Proceso de web scraping simplificado usando LLMs.
- Reducción de la necesidad de mantenimiento y ajustes continuos.
- Compatibilidad con varios modelos de lenguaje de gran escala.
- Opción de alojamiento local de LLMs para mayor privacidad y seguridad.
- Mayor flexibilidad y personalización a través de pipelines basados en grafos.
Desventajas
- Costos potenciales asociados con el uso de servicios de LLMs externos.
- Dependencia de la precisión y las capacidades del LLM elegido.
- Requiere cierta familiaridad con Python y entornos virtuales.
- Biblioteca relativamente nueva, por lo que el soporte de la comunidad y la documentación aún pueden estar creciendo.
Características clave
Integración con LLMs
ScrapeGraphAI aprovecha los modelos de lenguaje de gran escala (LLMs) para un web scraping inteligente. Puede detectar y adaptarse automáticamente a los cambios en las estructuras de los sitios web, reduciendo la necesidad de ajustes manuales continuos. Esta característica por sí sola ahorra un tiempo significativo de desarrollo y mantenimiento.
Pipelines basados en grafos
La biblioteca emplea pipelines modulares basados en grafos que permiten una extracción de datos eficiente y estructurada. Estos pipelines pueden personalizarse para adaptarse a diferentes escenarios de web scraping, proporcionando flexibilidad y control sobre el proceso de extracción.
Compatibilidad con múltiples LLMs
ScrapeGraphAI es compatible con una variedad de LLMs, incluyendo GPT, Gemini, Groq, Azure y Hugging Face. Esta compatibilidad permite a los usuarios seleccionar el modelo que mejor se adapte a sus necesidades, ya sea para scraping de propósito general o tareas más especializadas.
Alojamiento local de LLMs
Con la integración de Ollama, ScrapeGraphAI permite alojar modelos de lenguaje de gran escala localmente. Esto proporciona un entorno de web scraping seguro y privado, sin depender de servicios externos.
Casos de uso diversos para ScrapeGraphAI
Inteligencia de negocios para comercio electrónico
ScrapeGraphAI puede usarse para monitorear precios de productos, rastrear ofertas de competidores y recopilar reseñas de clientes, proporcionando a las empresas de comercio electrónico una ventaja competitiva. Al automatizar la recolección de estos datos, las empresas pueden tomar decisiones basadas en datos para optimizar sus estrategias.
Investigación para inversores
Los inversores pueden aprovechar ScrapeGraphAI para extraer datos financieros, analizar noticias de empresas y monitorear tendencias de mercado. Estos datos proporcionan a los inversores la información necesaria para tomar decisiones de inversión informadas y gestionar riesgos de manera efectiva.
Análisis de marketing y competitivo
Los equipos de marketing pueden usar ScrapeGraphAI para recopilar comentarios de clientes, analizar tendencias de redes sociales y rastrear estrategias de competidores. Estas ideas permiten a los marketers crear campañas dirigidas, optimizar su contenido y mejorar la participación del cliente.
Preguntas frecuentes
¿Qué es ScrapeGraphAI?
ScrapeGraphAI es una biblioteca de Python de código abierto diseñada para simplificar y automatizar el web scraping utilizando modelos de lenguaje de gran escala (LLMs). Permite a los usuarios extraer datos de sitios web de manera más eficiente y con menos codificación manual.
¿Cuáles son los requisitos previos para instalar ScrapeGraphAI?
Los requisitos previos incluyen Python 3.9 o superior (pero no más de 3.12), PIP y, opcionalmente, Ollama para ejecutar LLMs locales.
¿Cómo instalo ScrapeGraphAI?
Puedes instalar ScrapeGraphAI usando PIP con el comando pip install scrapegraphai. Se recomienda instalarlo en un entorno virtual.
¿Qué modelos de lenguaje de gran escala soporta ScrapeGraphAI?
ScrapeGraphAI es compatible con GPT, Gemini, Groq, Azure, Hugging Face y modelos locales ejecutados usando Ollama.
¿Cómo configuro ScrapeGraphAI para usar los modelos GPT de OpenAI?
Necesitas configurar tu clave API de OpenAI en el diccionario graph_config y especificar el modelo que deseas usar.
¿Puedo usar ScrapeGraphAI gratis?
Sí, ScrapeGraphAI es una biblioteca de código abierto y es gratuita para usar. Sin embargo, el uso de ciertos LLMs como los de OpenAI puede generar costos basados en el uso de tokens.
Preguntas relacionadas
¿Cómo se compara ScrapeGraphAI con las herramientas de web scraping tradicionales?
ScrapeGraphAI aprovecha los modelos de lenguaje de gran escala impulsados por IA, reduciendo la necesidad de ajustes manuales constantes debido a los cambios en la estructura de los sitios web. Las herramientas tradicionales a menudo requieren más codificación y mantenimiento. ScrapeGraphAI se adapta a los cambios en las estructuras de los sitios web, reduciendo la necesidad de intervención constante de desarrolladores. Esta flexibilidad asegura que los scrapers sigan siendo funcionales incluso cuando cambian los diseños de los sitios web. Con ScrapeGraphAI, solo necesitas especificar qué información necesitas, y la biblioteca se encarga del resto. El método tradicional de web scraping ha existido desde finales de los años 90 y principios de los 2000, cuando internet comenzó a tomar forma. En esos días, el web scraping involucraba una codificación pesada para extraer datos de páginas web HTML. Las expresiones regulares se usaban comúnmente para analizar datos HTML, lo que era una tarea tediosa y compleja. Este enfoque se utilizaba principalmente en aplicaciones sin conexión, requiriendo que los desarrolladores las pusieran en línea manualmente.
¿Qué tipo de prompts se pueden definir al usar ScrapeGraphAI?
Esta configuración incluye especificar el modelo (ollama/llama3), la temperatura, el formato y las URLs base para el LLM y los embeddings. Puedes ajustar el modelo y otros parámetros según sea necesario para adaptarse a tus requisitos específicos de web scraping. Algunos prompts comunes son los siguientes:
- Listar todos los proyectos con sus títulos y descripciones.
- Listar todo el contenido.










 Edición de audio maestra en DaVinci Resolve: Guía Fairlight para Sonido Profesional
Un audio nítido separa las producciones amateur de los contenidos de vídeo profesionales. La página Fairlight de DaVinci Resolve ofrece a cineastas y creadores de contenidos sofisticadas herramientas
Edición de audio maestra en DaVinci Resolve: Guía Fairlight para Sonido Profesional
Un audio nítido separa las producciones amateur de los contenidos de vídeo profesionales. La página Fairlight de DaVinci Resolve ofrece a cineastas y creadores de contenidos sofisticadas herramientas
 La IA de Google ya gestiona las llamadas telefónicas por ti
Google ha ampliado a todos los usuarios de EE.UU. su función de llamadas con inteligencia artificial a través de la Búsqueda, lo que permite a los clientes consultar precios y disponibilidad con empre
La IA de Google ya gestiona las llamadas telefónicas por ti
Google ha ampliado a todos los usuarios de EE.UU. su función de llamadas con inteligencia artificial a través de la Búsqueda, lo que permite a los clientes consultar precios y disponibilidad con empre
 Trump exime a smartphones, ordenadores y chips de la subida de aranceles
La administración Trump ha concedido exclusiones para smartphones, ordenadores y diversos dispositivos electrónicos de las recientes subidas de aranceles, incluso cuando se importan de China, según in
5 de agosto de 2025 11:00:59 GMT+02:00
Trump exime a smartphones, ordenadores y chips de la subida de aranceles
La administración Trump ha concedido exclusiones para smartphones, ordenadores y diversos dispositivos electrónicos de las recientes subidas de aranceles, incluso cuando se importan de China, según in
5 de agosto de 2025 11:00:59 GMT+02:00
This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎
0
1 de agosto de 2025 08:45:46 GMT+02:00
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
0
28 de julio de 2025 03:19:30 GMT+02:00
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
0
13 de mayo de 2025 23:23:52 GMT+02:00
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
0
13 de mayo de 2025 22:47:14 GMT+02:00
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
0
13 de mayo de 2025 17:53:23 GMT+02:00
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
0













