
















 家
家ScrapeGraphAI:ウェブスクレイピングの革新ガイド
今日のデータ駆動型社会では、ビジネスインテリジェンス、市場調査、競争分析など、さまざまな目的のためにウェブサイトから情報を抽出することが不可欠です。ウェブスクレイピング、つまりウェブサイトからデータを自動的に取得するプロセスは、重要なツールとなっています。しかし、従来のウェブスクレイピング手法では、ウェブサイトの構造変更に伴い、複雑なコーディングや定期的な更新が必要でした。ここでScrapeGraphAIが登場します。これは、大規模言語モデル(LLMs)の能力を活用することで、ウェブスクレイピングを変革することを目指す革新的なオープンソースのPythonライブラリです。
主なポイント
- ScrapeGraphAIは、ウェブスクレイピングを簡素化するオープンソースのPythonライブラリです。
- 大規模言語モデル(LLMs)を使用して、ウェブサイトからデータをより効果的に抽出します。
- ウェブサイトの変更に適応することで、開発者の継続的な介入の必要性を軽減します。
- GPT、Gemini、Groq、Azure、Hugging Faceなど、さまざまなLLMsをサポートしています。
- pipを使用した簡単なインストールが可能で、仮想環境の使用が推奨されます。
- ScrapeGraphAIは、従来の方法に比べて少ないコードでデータのスクレイピングと特定の情報抽出を可能にします。
- Ollamaを通じたローカルホスティングにより、プライベートで効率的なスクレイピング環境を提供します。
ウェブスクレイピングとその進化を理解する
従来のウェブスクレイピング時代
ウェブスクレイピングは、インターネットが発展し始めた1990年代後半から2000年代初頭から存在しています。当時、スクレイピングにはHTMLページからデータを抽出するための集中的なコーディングが必要でした。オンラインで見つかるさまざまなHTML構造をナビゲートするためには、カスタムコーディングが不可欠でした。HTMLデータを解析するために正規表現がよく使用され、これは面倒で複雑な作業でした。この方法は主にオフラインアプリケーションで使用され、オンラインにするには手動での更新が必要でした。このプロセス全体にはかなりの時間と専門知識が必要で、主に高度なコーディングスキルを持つ人にしかアクセスできませんでした。
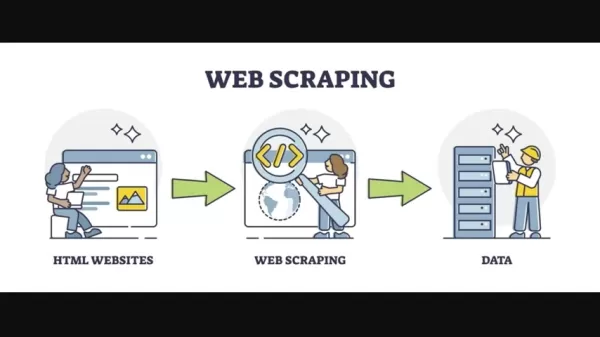
時間が経つにつれて、ウェブスクレイピングを簡素化するための多くのツールや技術が登場しました。Pythonはその堅牢なライブラリエコシステムにより、このタスクの優先言語となりました。Beautiful SoupやScrapyなどのライブラリは、より構造化されたデータ抽出方法を提供しましたが、ウェブサイトの構造変更に適応するという課題は依然として残っていました。
大規模言語モデル(LLMs)の導入により、従来のウェブスクレイピングの複雑さの多くを自動化するようになり、状況は大きく変わりました。このプロセスを簡単にするツールを探ってみましょう。
ScrapeGraphAIの紹介:ウェブスクレイピングの再構築
ScrapeGraphAIは、AI駆動の大規模言語モデルを活用してウェブスクレイピングプロセスを自動化および簡素化する強力なソリューションとして登場します。これは、ウェブスクレイピングのアプローチを革新するために設計されたオープンソースのPythonライブラリです。
固定パターンや手動調整に依存する従来のウェブスクレイピングツールとは異なり、ScrapeGraphAIはウェブサイトの構造変更に適応し、開発者の継続的な介入の必要性を最小限に抑えます。大規模言語モデル(LLMs)とモジュラーなグラフベースのパイプラインを統合することで、さまざまなソースからのデータスクレイピングを自動化することが際立っています。
このライブラリは、従来のスクレイピングツールに比べて柔軟でメンテナンスの少ないソリューションを提供します。HTMLマークアップから特定の情報を簡単に抽出でき、複雑な正規表現や広範なコーディングを必要としません。必要な情報を指定するだけで、ScrapeGraphAIが残りを処理します。GPT、Gemini、Groq、Azureなどの複数のLLMsをサポートし、Ollamaを使用してローカルで実行できるローカルモデルもサポートしています。
主要なコンポーネントとアーキテクチャ
ScrapeGraphAIは、さまざまなセクションのすべてのHTMLノードを処理するために異なる解析ノードを採用しています。HTMLページ内の特定の領域を特定するために検索ノードを使用します。スマートなグラフビルダーは、HTMLのすべてのマークアップ言語を管理します。
以下は、そのアーキテクチャの簡単な概要です:
- ノードタイプ: ScrapeGraphAIは、条件付きノード、フェッチノード、解析ノード、Ragノード、検索ノードなど、さまざまな解析ノードを使用して、HTMLの異なるセクションを処理します。これらのノードは、条件付き解析、データ取得、コンテンツ解析、HTML構造内の関連情報の検索を可能にします。
- グラフビルダー: ScrapeGraphAIのスマートなグラフビルダーは、HTMLマークアップ言語をすべて処理することで、希望する情報の抽出を簡素化します。
- 大規模言語モデル(LLMs): ScrapeGraphAIは、GeminiやOpenAIなどのLLMsをサポートし、その自然言語処理能力を活用して効率的なデータ抽出を行います。
このライブラリは、グラフを手動で定義したり、LLMがプロンプトに基づいてグラフを作成したりする機能を備えており、さまざまなユーザーのニーズやプロジェクト要件に対応する柔軟性を提供します。この高レベルなアーキテクチャにより、最小限のコーディングで複雑なスクレイピングパイプラインの実装が容易になります。
ScrapeGraphAIのセットアップ:インストールと設定
前提条件とインストール手順
ScrapeGraphAIに取り組む前に、システムが必要な前提条件を満たしていることを確認してください。
以下は、すべてをセットアップするための詳細なガイドです:
- Pythonバージョン: ScrapeGraphAIにはPython 3.9以上が必要ですが、3.12を超えるものは使用できません。通常、Python 3.10で十分です。
- PIP: Pythonパッケージインストーラーの最新バージョンであるPIPが必要です。コマンド pip install --upgrade pip を使用して更新できます。
- Ollama(オプション): ローカルの大規模言語モデルを実行する予定の場合、Ollamaをインストールする必要があります。詳細なインストールおよびセットアップ手順については、ドキュメントを確認してください。
これらの前提条件を確認したら、ScrapeGraphAIのインストールは簡単です:
pip install scrapegraphaiシステム内の他のPythonパッケージとの競合を避けるため、仮想環境(conda、venvなど)にScrapeGraphAIをインストールすることを強くお勧めします。
Windowsユーザーの場合、追加のライブラリをインストールするためにWindows Subsystem for Linux(WSL)を使用できます。
適切な大規模言語モデルの選択
ScrapeGraphAIを使用する際の重要な決定の一つは、ウェブスクレイピングのニーズに適した大規模言語モデル(LLM)を選択することです。ScrapeGraphAIは、それぞれの強みと能力を持つさまざまなLLMsをサポートしています:
- OpenAIのGPTモデル: GPT-3.5 TurboおよびGPT-4は、一般的なウェブスクレイピングタスクに強力な選択肢です。これらのモデルは、多様なウェブサイト構造から情報を効果的に理解し抽出できます。
- Gemini: 高度な自然言語処理能力を提供し、複雑なデータ抽出タスクに適しています。
- Groq: 速度と効率性で知られており、大量のウェブデータを迅速に処理する必要がある場合に優れた選択肢です。
- Azure: エンタープライズグレードのセキュリティとスケーラビリティを提供し、厳格なデータプライバシー要件を持つ組織に最適です。
- Hugging Face: 幅広いオープンソースのLLMsを提供し、特定のウェブスクレイピングタスク向けにモデルをカスタマイズおよび微調整できます。
データプライバシーやコストが気になる場合、ScrapeGraphAIはOllamaを使用してローカルのLLMsを実行できます。このセットアップにより、外部サービスに依存せずにLLMsの力を活用できます。
実際の例:ScrapeGraphAIでのスクレイピング
OpenAIモデルのセットアップ
OpenAIモデルを接続して使用するには、必要なライブラリをインポートし、APIキーを設定する必要があります。以下は、ScrapeGraphAIをOpenAIのGPTモデルで設定する方法の例です:
textimport os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object],[object Object]textresult = smart_scraper_graph.run()
print(result)この例では、graph_config ディクショナリを定義して、APIキーと使用したいモデル(gpt-3.5-turbo)を指定します。次に、プロンプト、ソースURL、設定でSmartScraperGraphを初期化します。最後に、run() メソッドを呼び出してスクレイピングプロセスを実行し、結果を出力します。
ローカルモデルの設定
ローカルモデルの場合、ScrapeGraphAIにはもう少し設定が必要ですが、それでも簡単です:
textfrom scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object]textresult = smart_scraper_graph.run()
print(result)この設定では、モデル(ollama/llama3)、温度、フォーマット、LLMおよび埋め込みのベースURLを指定します。特定のウェブスクレイピング要件に合わせて、モデルやその他のパラメータを調整できます。
コストとライセンスの理解
オープンソースの性質
ScrapeGraphAIはオープンソースライブラリであるため、無料で使用できます。ライセンスの条件に従って、ダウンロード、変更、配布が可能です。このオープンな性質は、コミュニティの貢献を促し、幅広いユーザーにライブラリをアクセス可能にします。
ただし、OpenAIなどの特定の大型言語モデルの使用にはコストがかかる場合があります。OpenAI、Bardeen AIなどはトークンベースの料金モデルで運営されています。LLMにプロンプトを送信すると、リクエストを処理して応答を生成します。コストは、プロンプトと応答で使用されたトークンの数に依存します。そのため、使用量を監視し、APIキーを管理して予期しない料金を避けることが重要です。OpenAI用の独自のAPIキーを持つことが役立ちます。
ScrapeGraphAIの利点と欠点
利点
- LLMsを使用した簡素化されたウェブスクレイピングプロセス。
- 継続的なメンテナンスと調整の必要性の軽減。
- さまざまな大型言語モデルのサポート。
- プライバシーとセキュリティを強化するためのローカルLLMホスティングオプション。
- グラフベースのパイプラインによる柔軟性とカスタマイズの向上。
欠点
- 外部LLMサービスの使用に関連する潜在的なコスト。
- 選択したLLMの精度と能力への依存。
- Pythonと仮想環境にある程度の知識が必要。
- 比較的新しいライブラリのため、コミュニティサポートとドキュメントがまだ成長中である可能性。
主な機能
LLM統合
ScrapeGraphAIは、インテリジェントなウェブスクレイピングのために大型言語モデル(LLMs)を活用します。ウェブサイトの構造変更を自動的に検出し適応するため、継続的な手動調整の必要性を軽減します。この機能だけで、開発およびメンテナンス時間を大幅に節約できます。
グラフベースのパイプライン
このライブラリは、効率的で構造化されたデータ抽出を可能にするモジュラーなグラフベースのパイプラインを採用しています。これらのパイプラインは、さまざまなウェブスクレイピングシナリオに合わせてカスタマイズでき、抽出プロセスに柔軟性と制御を提供します。
複数のLLMのサポート
ScrapeGraphAIは、GPT、Gemini、Groq、Azure、Hugging Faceなど、さまざまなLLMsをサポートしています。このサポートにより、ユーザーは一般的なスクレイピングやより専門的なタスクに最適なモデルを選択できます。
ローカルLLMホスティング
Ollamaの統合により、ScrapeGraphAIは大型言語モデルをローカルでホストできます。これにより、外部サービスに依存せずに安全でプライベートなウェブスクレイピング環境を提供します。
ScrapeGraphAIの多様なユースケース
電子商取引ビジネスインテリジェンス
ScrapeGraphAIは、製品価格の監視、競合他社の提供の追跡、顧客レビューの収集に使用でき、電子商取引ビジネスに競争優位性を提供します。このデータの自動収集により、企業はデータ駆動型の意思決定を行い、戦略を最適化できます。
投資家向けリサーチ
投資家は、ScrapeGraphAIを活用して財務データを抽出、企業ニュースを分析、市場動向を監視できます。このデータは、投資家が情報に基づいた投資決定を行い、リスクを効果的に管理するために必要な洞察を提供します。
マーケティングと競争分析
マーケティングチームは、ScrapeGraphAIを使用して顧客フィードバックを収集、ソーシャルメディアのトレンドを分析、競合他社の戦略を追跡できます。これらの洞察により、マーケティング担当者はターゲットを絞ったキャンペーンを作成、コンテンツを最適化、顧客エンゲージメントを向上させることができます。
よくある質問
ScrapeGraphAIとは何ですか?
ScrapeGraphAIは、大規模言語モデル(LLMs)を使用してウェブスクレイピングを簡素化および自動化するために設計されたオープンソースのPythonライブラリです。ユーザーはより効率的に、少ない手動コーディングでウェブサイトからデータを抽出できます。
ScrapeGraphAIのインストールに必要な前提条件は何ですか?
前提条件には、Python 3.9以上(ただし3.12以下)、PIP、そしてオプションでローカルLLMsを実行するためのOllamaが含まれます。
ScrapeGraphAIのインストール方法は?
コマンド pip install scrapegraphai を使用してPIPでScrapeGraphAIをインストールできます。仮想環境でのインストールが推奨されます。
ScrapeGraphAIはどの大規模言語モデルをサポートしていますか?
ScrapeGraphAIは、GPT、Gemini、Groq、Azure、Hugging Face、およびOllamaを使用して実行されるローカルモデルをサポートしています。
OpenAIのGPTモデルを使用するためにScrapeGraphAIを設定するにはどうすればいいですか?
graph_config ディクショナリでOpenAIのAPIキーを設定し、使用したいモデルを指定する必要があります。
ScrapeGraphAIは無料で使用できますか?
はい、ScrapeGraphAIはオープンソースライブラリであり、無料で使用できます。ただし、OpenAIなどの特定のLLMsの使用には、トークンの使用量に基づいてコストがかかる場合があります。
関連する質問
ScrapeGraphAIは従来のウェブスクレイピングツールとどう比較されますか?
ScrapeGraphAIは、AI駆動の大規模言語モデルを活用し、ウェブサイトの構造変更による継続的な手動調整の必要性を軽減します。従来のツールは、より多くのコーディングとメンテナンスを必要とします。ScrapeGraphAIは、ウェブサイトのレイアウトが変更されてもスクレイパーが機能し続けるように、変更に適応します。この柔軟性により、必要な情報を指定するだけで、ライブラリが残りを処理します。従来のウェブスクレイピング方法は、インターネットが形を成し始めた1990年代後半から2000年代初頭から存在しています。当時、ウェブスクレイピングにはHTMLウェブページからデータを抽出するための重いコーディングが必要でした。HTMLデータを解析するために正規表現が一般的に使用され、面倒で複雑な作業でした。このアプローチは主にオフラインアプリケーションで使用され、開発者が手動でオンラインにする必要がありました。
ScrapeGraphAIを使用する際に定義できるプロンプトの種類は何ですか?
この設定には、モデル(ollama/llama3)、温度、フォーマット、LLMおよび埋め込みのベースURLの指定が含まれます。特定のウェブスクレイピング要件に合わせて、モデルやその他のパラメータを調整できます。一般的なプロンプトには以下のようなものがあります:
- すべてのプロジェクトのタイトルと説明をリストしてください。
- すべてのコンテンツをリストしてください。
関連記事
 中国電信がMianbi Intelligenceに出資、LLMおよびデータインフラ向けに資本金を71万3000元に増資
大規模モデル分野における「ナショナルチーム」と清華大学の主導的な存在が、戦略的連携をさらに強化している。 2026年3月1日、Qichachaの最新の企業登録データによると、北京Mianbi Intelligent Technology Co., Ltd.は大幅な資本構成の再編を行い、通信大手や業界ファンドからの出資を正式に受け入れた。この動きは単なる資本注入にとどまらず、パブリックデータプラット
タオティアン・グループ、AIネイティブへの事業再編を加速、インターンに無料トークン割当を付与
TaoTian Groupは最近、「AI生産性向上プラン」を導入しました。これは、リソースの配分やツールの補助を通じて、AI技術のEC業務や研究開発ワークフローへの統合を加速させることを目的としています。このプログラムは現在、すべてのインターン生が利用可能となっており、インターン期間中、正社員と同等のAIアクセス権限、計算リソースの割り当て、および承認プロセスが付与されます。3月17日より、Tao
グリアン、市場開拓に向け企業のAIインフラをターゲットに
エンタープライズAIの主導権を巡る競争が激化している。マイクロソフトは「Copilot」をOfficeに組み込み、Googleは「Gemini」をWorkspaceに統合しており、OpenAIとAnthropicの両社は企業向けに直接販売を行っている。一方、現在ではほぼすべてのSaaSベンダーがAIアシスタントを搭載している。ユーザーインターフェースの主導権争いが激化する中、Gleanは目立たない
関連特集おすすめ
書き込み
中国電信がMianbi Intelligenceに出資、LLMおよびデータインフラ向けに資本金を71万3000元に増資
大規模モデル分野における「ナショナルチーム」と清華大学の主導的な存在が、戦略的連携をさらに強化している。 2026年3月1日、Qichachaの最新の企業登録データによると、北京Mianbi Intelligent Technology Co., Ltd.は大幅な資本構成の再編を行い、通信大手や業界ファンドからの出資を正式に受け入れた。この動きは単なる資本注入にとどまらず、パブリックデータプラット
タオティアン・グループ、AIネイティブへの事業再編を加速、インターンに無料トークン割当を付与
TaoTian Groupは最近、「AI生産性向上プラン」を導入しました。これは、リソースの配分やツールの補助を通じて、AI技術のEC業務や研究開発ワークフローへの統合を加速させることを目的としています。このプログラムは現在、すべてのインターン生が利用可能となっており、インターン期間中、正社員と同等のAIアクセス権限、計算リソースの割り当て、および承認プロセスが付与されます。3月17日より、Tao
グリアン、市場開拓に向け企業のAIインフラをターゲットに
エンタープライズAIの主導権を巡る競争が激化している。マイクロソフトは「Copilot」をOfficeに組み込み、Googleは「Gemini」をWorkspaceに統合しており、OpenAIとAnthropicの両社は企業向けに直接販売を行っている。一方、現在ではほぼすべてのSaaSベンダーがAIアシスタントを搭載している。ユーザーインターフェースの主導権争いが激化する中、Gleanは目立たない
関連特集おすすめ
書き込み
 最高のAI仙侠・武侠アシスタント:壮大な修練の物語と武術の演出を執筆
最高のAI仙侠・武侠アシスタント:壮大な修練の物語と武術の演出を執筆
2026年版、壮大な仙侠・武侠物語を創作するための最高のAIアシスタントをご紹介。XIX.AIが厳選したこのリストには、修練の進捗管理や武術の演出を完璧にこなす、高評価で画期的なツールが揃っています。無料版と有料版を実際のテスト結果で比較。あなたの創造力を解き放ち、今すぐ執筆を始めましょう!
 10 ツール
10 ツール
 xix.ai
コード
AIモバイルアプリ開発ツール:プロンプトからクロスプラットフォーム対応のFlutterおよびReact Nativeコードを生成する
xix.ai
コード
AIモバイルアプリ開発ツール:プロンプトからクロスプラットフォーム対応のFlutterおよびReact Nativeコードを生成する
2026年に最も優れたAIモバイルアプリ開発ツールをFlutterおよびReact Native向けにご紹介します。当社が厳選した高評価のツール群は、プロンプトからクロスプラットフォーム対応のコードを自動生成する、画期的なソリューションです。無料版と有料版を実際のテストで比較し、より迅速な開発と高品質なアプリの構築を実現してください。XIX.AIでランキングをご確認ください!
10 ツール
xix.ai
コード
おすすめのAI Chrome拡張機能ジェネレーター:プログラミングの知識がなくてもカスタムブラウザ拡張機能を作成
XIX.AIで、2026年おすすめのAI Chrome拡張機能ジェネレーターを発見しましょう。厳選されたこのリストには、コーディング不要で独自のブラウザ拡張機能を作成できる、高評価の「必見」ツールが揃っています。無料版と有料版の比較や実機テストの結果を確認し、生産性を飛躍的に向上させましょう。最新のランキングをチェックして、あなたにぴったりのツールを今すぐ見つけましょう!
10 ツール
xix.ai
テキスト読み上げ
最高のAI多言語TTS:50以上の言語で本物のネイティブなアクセントの音声を生成する
2026年に最も優れたAI多言語TTSツールを探そう。50以上の言語で本物のネイティブな発音が再現可能だ。当社が厳選したランキングをチェックし、無料版と有料版の比較や実際の使用テスト結果も確認してみてください。XIX.AIで自分に最適な音声ツールを見つけ出し、今日から世界中とのコミュニケーションをスムーズに始めましょう。
10 ツール
xix.ai
ミーティングアシスタント
よりスマートで迅速なコラボレーションを実現する、最高のAI会議自動化ツール
2026年最新の、高評価を得ているAI会議自動化ツールを紹介。よりスマートで迅速なコラボレーションを実現します。厳選されたリストには、議事録、要約、アクションアイテムを自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。チームの生産性を最大限に引き出しましょう。今すぐXIX.AIで厳選されたツールをご覧ください。
10 ツール
xix.ai
プロンプト
Infrastructure-as-Code 向け AI プロンプト:Terraform および Docker の設定を安全にデプロイする
2026年最新の「Infrastructure-as-Code」向け高評価AIプロンプトをご紹介します。XIX.AIが厳選したプロンプトを活用すれば、TerraformやDockerの設定を安全にデプロイし、クラウド環境のセットアップを自動化し、DevOpsの生産性を向上させることができます。実際のテスト結果をもとに、無料版と有料版の比較も可能です。今すぐチェックして、AIの真価を引き出しましょう。
10 ツール
xix.ai

 コメント (8)
0/500
コメント (8)
0/500
![HenryDavis]()
This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎
![RyanJackson]()
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
![KevinAnderson]()
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
![BillyWilson]()
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
![ThomasLewis]()
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
![SamuelAllen]()
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
今日のデータ駆動型社会では、ビジネスインテリジェンス、市場調査、競争分析など、さまざまな目的のためにウェブサイトから情報を抽出することが不可欠です。ウェブスクレイピング、つまりウェブサイトからデータを自動的に取得するプロセスは、重要なツールとなっています。しかし、従来のウェブスクレイピング手法では、ウェブサイトの構造変更に伴い、複雑なコーディングや定期的な更新が必要でした。ここでScrapeGraphAIが登場します。これは、大規模言語モデル(LLMs)の能力を活用することで、ウェブスクレイピングを変革することを目指す革新的なオープンソースのPythonライブラリです。
主なポイント
- ScrapeGraphAIは、ウェブスクレイピングを簡素化するオープンソースのPythonライブラリです。
- 大規模言語モデル(LLMs)を使用して、ウェブサイトからデータをより効果的に抽出します。
- ウェブサイトの変更に適応することで、開発者の継続的な介入の必要性を軽減します。
- GPT、Gemini、Groq、Azure、Hugging Faceなど、さまざまなLLMsをサポートしています。
- pipを使用した簡単なインストールが可能で、仮想環境の使用が推奨されます。
- ScrapeGraphAIは、従来の方法に比べて少ないコードでデータのスクレイピングと特定の情報抽出を可能にします。
- Ollamaを通じたローカルホスティングにより、プライベートで効率的なスクレイピング環境を提供します。
ウェブスクレイピングとその進化を理解する
従来のウェブスクレイピング時代
ウェブスクレイピングは、インターネットが発展し始めた1990年代後半から2000年代初頭から存在しています。当時、スクレイピングにはHTMLページからデータを抽出するための集中的なコーディングが必要でした。オンラインで見つかるさまざまなHTML構造をナビゲートするためには、カスタムコーディングが不可欠でした。HTMLデータを解析するために正規表現がよく使用され、これは面倒で複雑な作業でした。この方法は主にオフラインアプリケーションで使用され、オンラインにするには手動での更新が必要でした。このプロセス全体にはかなりの時間と専門知識が必要で、主に高度なコーディングスキルを持つ人にしかアクセスできませんでした。
時間が経つにつれて、ウェブスクレイピングを簡素化するための多くのツールや技術が登場しました。Pythonはその堅牢なライブラリエコシステムにより、このタスクの優先言語となりました。Beautiful SoupやScrapyなどのライブラリは、より構造化されたデータ抽出方法を提供しましたが、ウェブサイトの構造変更に適応するという課題は依然として残っていました。
大規模言語モデル(LLMs)の導入により、従来のウェブスクレイピングの複雑さの多くを自動化するようになり、状況は大きく変わりました。このプロセスを簡単にするツールを探ってみましょう。
ScrapeGraphAIの紹介:ウェブスクレイピングの再構築
ScrapeGraphAIは、AI駆動の大規模言語モデルを活用してウェブスクレイピングプロセスを自動化および簡素化する強力なソリューションとして登場します。これは、ウェブスクレイピングのアプローチを革新するために設計されたオープンソースのPythonライブラリです。
固定パターンや手動調整に依存する従来のウェブスクレイピングツールとは異なり、ScrapeGraphAIはウェブサイトの構造変更に適応し、開発者の継続的な介入の必要性を最小限に抑えます。大規模言語モデル(LLMs)とモジュラーなグラフベースのパイプラインを統合することで、さまざまなソースからのデータスクレイピングを自動化することが際立っています。
このライブラリは、従来のスクレイピングツールに比べて柔軟でメンテナンスの少ないソリューションを提供します。HTMLマークアップから特定の情報を簡単に抽出でき、複雑な正規表現や広範なコーディングを必要としません。必要な情報を指定するだけで、ScrapeGraphAIが残りを処理します。GPT、Gemini、Groq、Azureなどの複数のLLMsをサポートし、Ollamaを使用してローカルで実行できるローカルモデルもサポートしています。
主要なコンポーネントとアーキテクチャ
ScrapeGraphAIは、さまざまなセクションのすべてのHTMLノードを処理するために異なる解析ノードを採用しています。HTMLページ内の特定の領域を特定するために検索ノードを使用します。スマートなグラフビルダーは、HTMLのすべてのマークアップ言語を管理します。
以下は、そのアーキテクチャの簡単な概要です:
- ノードタイプ: ScrapeGraphAIは、条件付きノード、フェッチノード、解析ノード、Ragノード、検索ノードなど、さまざまな解析ノードを使用して、HTMLの異なるセクションを処理します。これらのノードは、条件付き解析、データ取得、コンテンツ解析、HTML構造内の関連情報の検索を可能にします。
- グラフビルダー: ScrapeGraphAIのスマートなグラフビルダーは、HTMLマークアップ言語をすべて処理することで、希望する情報の抽出を簡素化します。
- 大規模言語モデル(LLMs): ScrapeGraphAIは、GeminiやOpenAIなどのLLMsをサポートし、その自然言語処理能力を活用して効率的なデータ抽出を行います。
このライブラリは、グラフを手動で定義したり、LLMがプロンプトに基づいてグラフを作成したりする機能を備えており、さまざまなユーザーのニーズやプロジェクト要件に対応する柔軟性を提供します。この高レベルなアーキテクチャにより、最小限のコーディングで複雑なスクレイピングパイプラインの実装が容易になります。
ScrapeGraphAIのセットアップ:インストールと設定
前提条件とインストール手順
ScrapeGraphAIに取り組む前に、システムが必要な前提条件を満たしていることを確認してください。
以下は、すべてをセットアップするための詳細なガイドです:
- Pythonバージョン: ScrapeGraphAIにはPython 3.9以上が必要ですが、3.12を超えるものは使用できません。通常、Python 3.10で十分です。
- PIP: Pythonパッケージインストーラーの最新バージョンであるPIPが必要です。コマンド pip install --upgrade pip を使用して更新できます。
- Ollama(オプション): ローカルの大規模言語モデルを実行する予定の場合、Ollamaをインストールする必要があります。詳細なインストールおよびセットアップ手順については、ドキュメントを確認してください。
これらの前提条件を確認したら、ScrapeGraphAIのインストールは簡単です:
システム内の他のPythonパッケージとの競合を避けるため、仮想環境(conda、venvなど)にScrapeGraphAIをインストールすることを強くお勧めします。
Windowsユーザーの場合、追加のライブラリをインストールするためにWindows Subsystem for Linux(WSL)を使用できます。
適切な大規模言語モデルの選択
ScrapeGraphAIを使用する際の重要な決定の一つは、ウェブスクレイピングのニーズに適した大規模言語モデル(LLM)を選択することです。ScrapeGraphAIは、それぞれの強みと能力を持つさまざまなLLMsをサポートしています:
- OpenAIのGPTモデル: GPT-3.5 TurboおよびGPT-4は、一般的なウェブスクレイピングタスクに強力な選択肢です。これらのモデルは、多様なウェブサイト構造から情報を効果的に理解し抽出できます。
- Gemini: 高度な自然言語処理能力を提供し、複雑なデータ抽出タスクに適しています。
- Groq: 速度と効率性で知られており、大量のウェブデータを迅速に処理する必要がある場合に優れた選択肢です。
- Azure: エンタープライズグレードのセキュリティとスケーラビリティを提供し、厳格なデータプライバシー要件を持つ組織に最適です。
- Hugging Face: 幅広いオープンソースのLLMsを提供し、特定のウェブスクレイピングタスク向けにモデルをカスタマイズおよび微調整できます。
データプライバシーやコストが気になる場合、ScrapeGraphAIはOllamaを使用してローカルのLLMsを実行できます。このセットアップにより、外部サービスに依存せずにLLMsの力を活用できます。
実際の例:ScrapeGraphAIでのスクレイピング
OpenAIモデルのセットアップ
OpenAIモデルを接続して使用するには、必要なライブラリをインポートし、APIキーを設定する必要があります。以下は、ScrapeGraphAIをOpenAIのGPTモデルで設定する方法の例です:
import os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object],[object Object]result = smart_scraper_graph.run()
print(result)この例では、graph_config ディクショナリを定義して、APIキーと使用したいモデル(gpt-3.5-turbo)を指定します。次に、プロンプト、ソースURL、設定でSmartScraperGraphを初期化します。最後に、run() メソッドを呼び出してスクレイピングプロセスを実行し、結果を出力します。
ローカルモデルの設定
ローカルモデルの場合、ScrapeGraphAIにはもう少し設定が必要ですが、それでも簡単です:
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
,[object Object],[object Object],[object Object],[object Object]result = smart_scraper_graph.run()
print(result)この設定では、モデル(ollama/llama3)、温度、フォーマット、LLMおよび埋め込みのベースURLを指定します。特定のウェブスクレイピング要件に合わせて、モデルやその他のパラメータを調整できます。
コストとライセンスの理解
オープンソースの性質
ScrapeGraphAIはオープンソースライブラリであるため、無料で使用できます。ライセンスの条件に従って、ダウンロード、変更、配布が可能です。このオープンな性質は、コミュニティの貢献を促し、幅広いユーザーにライブラリをアクセス可能にします。
ただし、OpenAIなどの特定の大型言語モデルの使用にはコストがかかる場合があります。OpenAI、Bardeen AIなどはトークンベースの料金モデルで運営されています。LLMにプロンプトを送信すると、リクエストを処理して応答を生成します。コストは、プロンプトと応答で使用されたトークンの数に依存します。そのため、使用量を監視し、APIキーを管理して予期しない料金を避けることが重要です。OpenAI用の独自のAPIキーを持つことが役立ちます。
ScrapeGraphAIの利点と欠点
利点
- LLMsを使用した簡素化されたウェブスクレイピングプロセス。
- 継続的なメンテナンスと調整の必要性の軽減。
- さまざまな大型言語モデルのサポート。
- プライバシーとセキュリティを強化するためのローカルLLMホスティングオプション。
- グラフベースのパイプラインによる柔軟性とカスタマイズの向上。
欠点
- 外部LLMサービスの使用に関連する潜在的なコスト。
- 選択したLLMの精度と能力への依存。
- Pythonと仮想環境にある程度の知識が必要。
- 比較的新しいライブラリのため、コミュニティサポートとドキュメントがまだ成長中である可能性。
主な機能
LLM統合
ScrapeGraphAIは、インテリジェントなウェブスクレイピングのために大型言語モデル(LLMs)を活用します。ウェブサイトの構造変更を自動的に検出し適応するため、継続的な手動調整の必要性を軽減します。この機能だけで、開発およびメンテナンス時間を大幅に節約できます。
グラフベースのパイプライン
このライブラリは、効率的で構造化されたデータ抽出を可能にするモジュラーなグラフベースのパイプラインを採用しています。これらのパイプラインは、さまざまなウェブスクレイピングシナリオに合わせてカスタマイズでき、抽出プロセスに柔軟性と制御を提供します。
複数のLLMのサポート
ScrapeGraphAIは、GPT、Gemini、Groq、Azure、Hugging Faceなど、さまざまなLLMsをサポートしています。このサポートにより、ユーザーは一般的なスクレイピングやより専門的なタスクに最適なモデルを選択できます。
ローカルLLMホスティング
Ollamaの統合により、ScrapeGraphAIは大型言語モデルをローカルでホストできます。これにより、外部サービスに依存せずに安全でプライベートなウェブスクレイピング環境を提供します。
ScrapeGraphAIの多様なユースケース
電子商取引ビジネスインテリジェンス
ScrapeGraphAIは、製品価格の監視、競合他社の提供の追跡、顧客レビューの収集に使用でき、電子商取引ビジネスに競争優位性を提供します。このデータの自動収集により、企業はデータ駆動型の意思決定を行い、戦略を最適化できます。
投資家向けリサーチ
投資家は、ScrapeGraphAIを活用して財務データを抽出、企業ニュースを分析、市場動向を監視できます。このデータは、投資家が情報に基づいた投資決定を行い、リスクを効果的に管理するために必要な洞察を提供します。
マーケティングと競争分析
マーケティングチームは、ScrapeGraphAIを使用して顧客フィードバックを収集、ソーシャルメディアのトレンドを分析、競合他社の戦略を追跡できます。これらの洞察により、マーケティング担当者はターゲットを絞ったキャンペーンを作成、コンテンツを最適化、顧客エンゲージメントを向上させることができます。
よくある質問
ScrapeGraphAIとは何ですか?
ScrapeGraphAIは、大規模言語モデル(LLMs)を使用してウェブスクレイピングを簡素化および自動化するために設計されたオープンソースのPythonライブラリです。ユーザーはより効率的に、少ない手動コーディングでウェブサイトからデータを抽出できます。
ScrapeGraphAIのインストールに必要な前提条件は何ですか?
前提条件には、Python 3.9以上(ただし3.12以下)、PIP、そしてオプションでローカルLLMsを実行するためのOllamaが含まれます。
ScrapeGraphAIのインストール方法は?
コマンド pip install scrapegraphai を使用してPIPでScrapeGraphAIをインストールできます。仮想環境でのインストールが推奨されます。
ScrapeGraphAIはどの大規模言語モデルをサポートしていますか?
ScrapeGraphAIは、GPT、Gemini、Groq、Azure、Hugging Face、およびOllamaを使用して実行されるローカルモデルをサポートしています。
OpenAIのGPTモデルを使用するためにScrapeGraphAIを設定するにはどうすればいいですか?
graph_config ディクショナリでOpenAIのAPIキーを設定し、使用したいモデルを指定する必要があります。
ScrapeGraphAIは無料で使用できますか?
はい、ScrapeGraphAIはオープンソースライブラリであり、無料で使用できます。ただし、OpenAIなどの特定のLLMsの使用には、トークンの使用量に基づいてコストがかかる場合があります。
関連する質問
ScrapeGraphAIは従来のウェブスクレイピングツールとどう比較されますか?
ScrapeGraphAIは、AI駆動の大規模言語モデルを活用し、ウェブサイトの構造変更による継続的な手動調整の必要性を軽減します。従来のツールは、より多くのコーディングとメンテナンスを必要とします。ScrapeGraphAIは、ウェブサイトのレイアウトが変更されてもスクレイパーが機能し続けるように、変更に適応します。この柔軟性により、必要な情報を指定するだけで、ライブラリが残りを処理します。従来のウェブスクレイピング方法は、インターネットが形を成し始めた1990年代後半から2000年代初頭から存在しています。当時、ウェブスクレイピングにはHTMLウェブページからデータを抽出するための重いコーディングが必要でした。HTMLデータを解析するために正規表現が一般的に使用され、面倒で複雑な作業でした。このアプローチは主にオフラインアプリケーションで使用され、開発者が手動でオンラインにする必要がありました。
ScrapeGraphAIを使用する際に定義できるプロンプトの種類は何ですか?
この設定には、モデル(ollama/llama3)、温度、フォーマット、LLMおよび埋め込みのベースURLの指定が含まれます。特定のウェブスクレイピング要件に合わせて、モデルやその他のパラメータを調整できます。一般的なプロンプトには以下のようなものがあります:
- すべてのプロジェクトのタイトルと説明をリストしてください。
- すべてのコンテンツをリストしてください。










 中国電信がMianbi Intelligenceに出資、LLMおよびデータインフラ向けに資本金を71万3000元に増資
大規模モデル分野における「ナショナルチーム」と清華大学の主導的な存在が、戦略的連携をさらに強化している。 2026年3月1日、Qichachaの最新の企業登録データによると、北京Mianbi Intelligent Technology Co., Ltd.は大幅な資本構成の再編を行い、通信大手や業界ファンドからの出資を正式に受け入れた。この動きは単なる資本注入にとどまらず、パブリックデータプラット
中国電信がMianbi Intelligenceに出資、LLMおよびデータインフラ向けに資本金を71万3000元に増資
大規模モデル分野における「ナショナルチーム」と清華大学の主導的な存在が、戦略的連携をさらに強化している。 2026年3月1日、Qichachaの最新の企業登録データによると、北京Mianbi Intelligent Technology Co., Ltd.は大幅な資本構成の再編を行い、通信大手や業界ファンドからの出資を正式に受け入れた。この動きは単なる資本注入にとどまらず、パブリックデータプラット
 タオティアン・グループ、AIネイティブへの事業再編を加速、インターンに無料トークン割当を付与
TaoTian Groupは最近、「AI生産性向上プラン」を導入しました。これは、リソースの配分やツールの補助を通じて、AI技術のEC業務や研究開発ワークフローへの統合を加速させることを目的としています。このプログラムは現在、すべてのインターン生が利用可能となっており、インターン期間中、正社員と同等のAIアクセス権限、計算リソースの割り当て、および承認プロセスが付与されます。3月17日より、Tao
タオティアン・グループ、AIネイティブへの事業再編を加速、インターンに無料トークン割当を付与
TaoTian Groupは最近、「AI生産性向上プラン」を導入しました。これは、リソースの配分やツールの補助を通じて、AI技術のEC業務や研究開発ワークフローへの統合を加速させることを目的としています。このプログラムは現在、すべてのインターン生が利用可能となっており、インターン期間中、正社員と同等のAIアクセス権限、計算リソースの割り当て、および承認プロセスが付与されます。3月17日より、Tao
 グリアン、市場開拓に向け企業のAIインフラをターゲットに
エンタープライズAIの主導権を巡る競争が激化している。マイクロソフトは「Copilot」をOfficeに組み込み、Googleは「Gemini」をWorkspaceに統合しており、OpenAIとAnthropicの両社は企業向けに直接販売を行っている。一方、現在ではほぼすべてのSaaSベンダーがAIアシスタントを搭載している。ユーザーインターフェースの主導権争いが激化する中、Gleanは目立たない
グリアン、市場開拓に向け企業のAIインフラをターゲットに
エンタープライズAIの主導権を巡る競争が激化している。マイクロソフトは「Copilot」をOfficeに組み込み、Googleは「Gemini」をWorkspaceに統合しており、OpenAIとAnthropicの両社は企業向けに直接販売を行っている。一方、現在ではほぼすべてのSaaSベンダーがAIアシスタントを搭載している。ユーザーインターフェースの主導権争いが激化する中、Gleanは目立たない

2026年版、壮大な仙侠・武侠物語を創作するための最高のAIアシスタントをご紹介。XIX.AIが厳選したこのリストには、修練の進捗管理や武術の演出を完璧にこなす、高評価で画期的なツールが揃っています。無料版と有料版を実際のテスト結果で比較。あなたの創造力を解き放ち、今すぐ執筆を始めましょう!
10 ツール
xix.ai

2026年に最も優れたAIモバイルアプリ開発ツールをFlutterおよびReact Native向けにご紹介します。当社が厳選した高評価のツール群は、プロンプトからクロスプラットフォーム対応のコードを自動生成する、画期的なソリューションです。無料版と有料版を実際のテストで比較し、より迅速な開発と高品質なアプリの構築を実現してください。XIX.AIでランキングをご確認ください!
10 ツール
xix.ai

XIX.AIで、2026年おすすめのAI Chrome拡張機能ジェネレーターを発見しましょう。厳選されたこのリストには、コーディング不要で独自のブラウザ拡張機能を作成できる、高評価の「必見」ツールが揃っています。無料版と有料版の比較や実機テストの結果を確認し、生産性を飛躍的に向上させましょう。最新のランキングをチェックして、あなたにぴったりのツールを今すぐ見つけましょう!
10 ツール
xix.ai

2026年に最も優れたAI多言語TTSツールを探そう。50以上の言語で本物のネイティブな発音が再現可能だ。当社が厳選したランキングをチェックし、無料版と有料版の比較や実際の使用テスト結果も確認してみてください。XIX.AIで自分に最適な音声ツールを見つけ出し、今日から世界中とのコミュニケーションをスムーズに始めましょう。
10 ツール
xix.ai

2026年最新の、高評価を得ているAI会議自動化ツールを紹介。よりスマートで迅速なコラボレーションを実現します。厳選されたリストには、議事録、要約、アクションアイテムを自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。チームの生産性を最大限に引き出しましょう。今すぐXIX.AIで厳選されたツールをご覧ください。
10 ツール
xix.ai

2026年最新の「Infrastructure-as-Code」向け高評価AIプロンプトをご紹介します。XIX.AIが厳選したプロンプトを活用すれば、TerraformやDockerの設定を安全にデプロイし、クラウド環境のセットアップを自動化し、DevOpsの生産性を向上させることができます。実際のテスト結果をもとに、無料版と有料版の比較も可能です。今すぐチェックして、AIの真価を引き出しましょう。
10 ツール
xix.ai

This ScrapeGraphAI guide is a game-changer! Web scraping’s always been a hassle, but this makes it sound so seamless. Curious how it handles dynamic sites—any real-world examples out there? 😎
Super cool guide on ScrapeGraphAI! Makes web scraping sound like a breeze. Anyone tried this for market research yet? 😎
This ScrapeGraphAI guide is a game-changer! 😍 Web scraping always felt like a techy maze, but this makes it sound so slick and efficient. I’m curious how it handles tricky dynamic sites—any tips for beginners diving in?
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎













