
















 Home
HomeMistral unveils open-source speech generation model
French AI company Mistral unveiled a new open-source text-to-speech model on Thursday, designed for voice AI assistants and enterprise applications like customer support. The model enables businesses to build voice agents for sales and customer engagement, positioning Mistral as a direct competitor to ElevenLabs, Deepgram, and OpenAI.
Called Voxtral TTS, the model supports nine languages, including English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic.
"Our customers have been asking for a speech model. So we built a small-sized speech model that can fit on a smartwatch, a smartphone, a laptop, or other edge devices. The cost is a fraction of anything else on the market, yet it delivers state-of-the-art performance," said Pierre Stock, VP of science operations at Mistral AI, in a phone interview with TechCrunch.
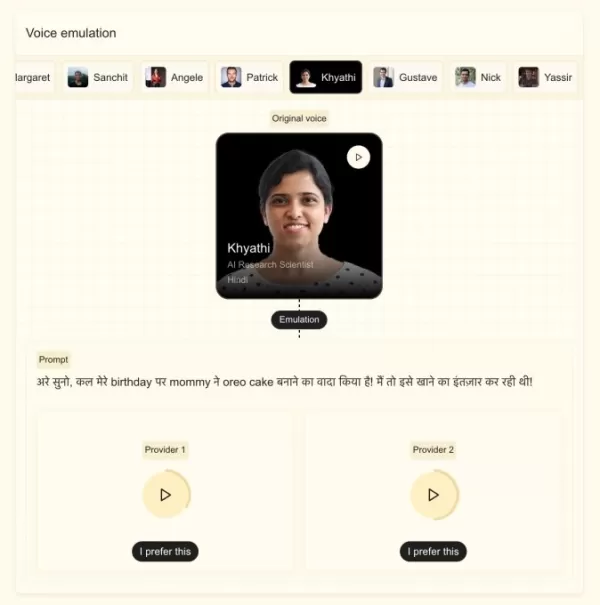
Image credit: Mistral
Mistral states the new model can adapt to a custom voice using a sample shorter than five seconds, capturing subtle accents, inflections, intonations, and irregularities in speech flow. Built on Ministral 3B, it can switch between languages smoothly while preserving voice characteristics, making it ideal for dubbing or real-time translation. Stock noted the company aimed to make the model sound human, not robotic.
According to the company, the model is built for real-time performance. Its time-to-first-audio (TTFA) — the time between receiving input and beginning to 'speak' — is 90ms for a 10-second sample of 500 characters. The model also achieves a real-time factor (RTF) of 6x, meaning it can generate a 10-second clip in roughly 1.6 seconds.
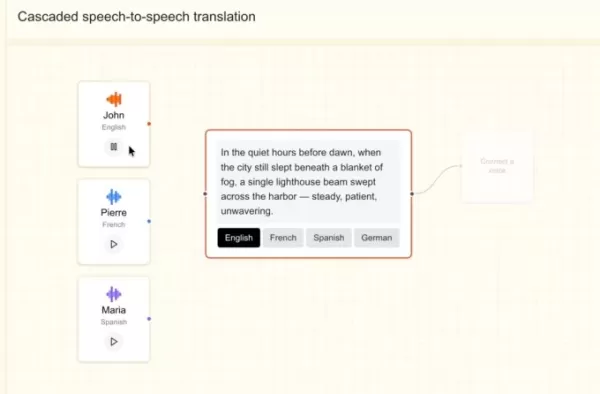
Image credit: Mistral AI
Earlier this year, Mistral launched two transcription models — one for large-scale batch processing, the other for low-latency real-time use cases. With the new speech model, the company appears to be building a comprehensive suite of voice products for enterprises.
Stock added, "We plan to create an end-to-end platform capable of handling multimodal input streams — audio, text, and image — as well as output. The key advantage is that an end-to-end agentic system supporting audio input and output provides much richer information."
Mistral positions its open-source nature and customization capabilities as key differentiators, allowing enterprises to tune the model to their specific needs, thus favoring it over competitor solutions.
Related article
 Spotify unveils AI audiobook creation tool powered by ElevenLabs
As part of its latest announcements, Spotify introduced a new AI tool powered by ElevenLabs that lets authors self-publish audiobooks directly through the Spotify for Authors platform. During its Investor Day event, the company confirmed the feature
Top AI Dictation Apps: Expert Reviews and Rankings
AI dictation apps have made remarkable progress in a relatively short period. For a long time, they were sluggish and prone to errors, requiring users to speak with a specific accent and perfect clarity.This has changed with advancements in large lan
Wispr Flow Bets on Voice AI's Future in India Despite Challenges
India's digital landscape is deeply engaged with voice technology, from voice notes to multilingual messaging. Transforming these widespread habits into a scalable AI business presents significant challenges, given the country's linguistic diversity,
Related Special Topic Recommendations
Productivity
Spotify unveils AI audiobook creation tool powered by ElevenLabs
As part of its latest announcements, Spotify introduced a new AI tool powered by ElevenLabs that lets authors self-publish audiobooks directly through the Spotify for Authors platform. During its Investor Day event, the company confirmed the feature
Top AI Dictation Apps: Expert Reviews and Rankings
AI dictation apps have made remarkable progress in a relatively short period. For a long time, they were sluggish and prone to errors, requiring users to speak with a specific accent and perfect clarity.This has changed with advancements in large lan
Wispr Flow Bets on Voice AI's Future in India Despite Challenges
India's digital landscape is deeply engaged with voice technology, from voice notes to multilingual messaging. Transforming these widespread habits into a scalable AI business presents significant challenges, given the country's linguistic diversity,
Related Special Topic Recommendations
Productivity
 AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
 10 tools
10 tools
 xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai
Data Analysis
Best AI Data Visualization Tools: Auto-Generate Interactive BI Dashboards from Raw Files
Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

 Comments (0)
0/500
Comments (0)
0/500
French AI company Mistral unveiled a new open-source text-to-speech model on Thursday, designed for voice AI assistants and enterprise applications like customer support. The model enables businesses to build voice agents for sales and customer engagement, positioning Mistral as a direct competitor to ElevenLabs, Deepgram, and OpenAI.
Called Voxtral TTS, the model supports nine languages, including English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic.
"Our customers have been asking for a speech model. So we built a small-sized speech model that can fit on a smartwatch, a smartphone, a laptop, or other edge devices. The cost is a fraction of anything else on the market, yet it delivers state-of-the-art performance," said Pierre Stock, VP of science operations at Mistral AI, in a phone interview with TechCrunch.
Image credit: Mistral
Mistral states the new model can adapt to a custom voice using a sample shorter than five seconds, capturing subtle accents, inflections, intonations, and irregularities in speech flow. Built on Ministral 3B, it can switch between languages smoothly while preserving voice characteristics, making it ideal for dubbing or real-time translation. Stock noted the company aimed to make the model sound human, not robotic.
According to the company, the model is built for real-time performance. Its time-to-first-audio (TTFA) — the time between receiving input and beginning to 'speak' — is 90ms for a 10-second sample of 500 characters. The model also achieves a real-time factor (RTF) of 6x, meaning it can generate a 10-second clip in roughly 1.6 seconds.
Image credit: Mistral AI
Earlier this year, Mistral launched two transcription models — one for large-scale batch processing, the other for low-latency real-time use cases. With the new speech model, the company appears to be building a comprehensive suite of voice products for enterprises.
Stock added, "We plan to create an end-to-end platform capable of handling multimodal input streams — audio, text, and image — as well as output. The key advantage is that an end-to-end agentic system supporting audio input and output provides much richer information."
Mistral positions its open-source nature and customization capabilities as key differentiators, allowing enterprises to tune the model to their specific needs, thus favoring it over competitor solutions.










 Spotify unveils AI audiobook creation tool powered by ElevenLabs
As part of its latest announcements, Spotify introduced a new AI tool powered by ElevenLabs that lets authors self-publish audiobooks directly through the Spotify for Authors platform. During its Investor Day event, the company confirmed the feature
Spotify unveils AI audiobook creation tool powered by ElevenLabs
As part of its latest announcements, Spotify introduced a new AI tool powered by ElevenLabs that lets authors self-publish audiobooks directly through the Spotify for Authors platform. During its Investor Day event, the company confirmed the feature
 Top AI Dictation Apps: Expert Reviews and Rankings
AI dictation apps have made remarkable progress in a relatively short period. For a long time, they were sluggish and prone to errors, requiring users to speak with a specific accent and perfect clarity.This has changed with advancements in large lan
Top AI Dictation Apps: Expert Reviews and Rankings
AI dictation apps have made remarkable progress in a relatively short period. For a long time, they were sluggish and prone to errors, requiring users to speak with a specific accent and perfect clarity.This has changed with advancements in large lan
 Wispr Flow Bets on Voice AI's Future in India Despite Challenges
India's digital landscape is deeply engaged with voice technology, from voice notes to multilingual messaging. Transforming these widespread habits into a scalable AI business presents significant challenges, given the country's linguistic diversity,
Wispr Flow Bets on Voice AI's Future in India Despite Challenges
India's digital landscape is deeply engaged with voice technology, from voice notes to multilingual messaging. Transforming these widespread habits into a scalable AI business presents significant challenges, given the country's linguistic diversity,

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai













