
















 首页
首页Mistral 发布开源语音生成模型
法国人工智能公司Mistral于周四发布了一款新的开源文本转语音模型,该模型专为语音AI助手及客户支持等企业应用而设计。该模型使企业能够构建用于销售和客户互动的语音代理,从而使Mistral成为ElevenLabs、Deepgram和OpenAI的直接竞争对手。
该模型名为Voxtral TTS,支持九种语言,包括英语、法语、德语、西班牙语、荷兰语、葡萄牙语、意大利语、印地语和阿拉伯语。
“我们的客户一直都在寻求语音模型。因此,我们开发了一个小型语音模型,可以适配智能手表、智能手机、笔记本电脑或其他边缘设备。其成本仅为市场上其他产品的零头,却能提供最先进的性能,”Mistral AI科学运营副总裁皮埃尔·斯托克(Pierre Stock)在接受TechCrunch电话采访时表示。
图片来源:Mistral
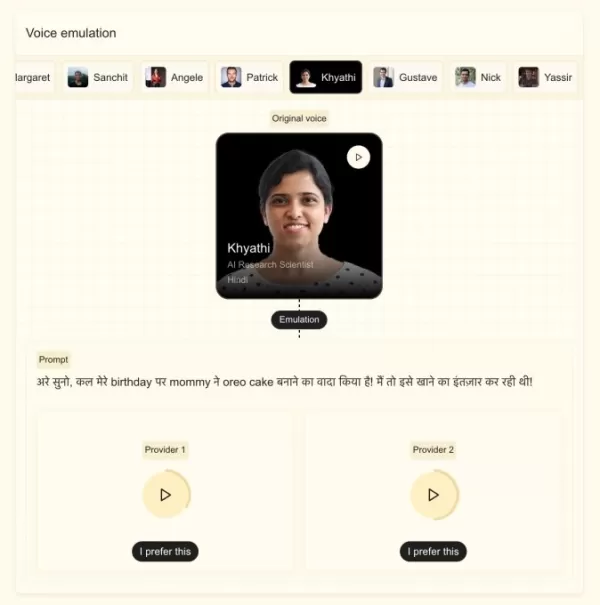
Mistral表示,该新模型仅需不到5秒的语音样本即可适应特定声音,能捕捉细微的口音、语调变化、语调以及语音流中的不规则之处。基于Ministral 3B构建的该模型,可在保持声音特征的同时流畅切换语言,非常适合配音或实时翻译。斯托克指出,公司的目标是让模型听起来像真人,而非机械音。
据该公司介绍,该模型专为实时性能而设计。其“首次发声时间”(TTFA)——即从接收输入到开始“说话”所需的时间——对于一段10秒、500字符的样本而言仅为90毫秒。 该模型还实现了6倍的实时因子(RTF),这意味着它能在约1.6秒内生成一段10秒的音频片段。
图片来源:Mistral AI
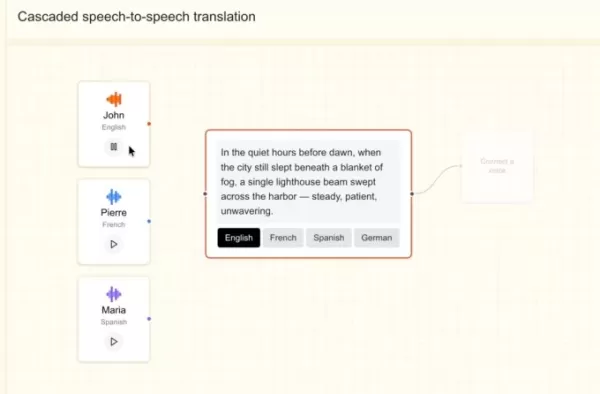
今年早些时候,Mistral 推出了两款转录模型——一款用于大规模批量处理,另一款用于低延迟的实时应用场景。随着这款新语音模型的推出,该公司似乎正在为企业构建一套全面的语音产品套件。
Stock补充道:“我们计划打造一个端到端的平台,能够处理多模态输入流——包括音频、文本和图像——以及输出。其关键优势在于,支持音频输入和输出的端到端代理系统能提供更为丰富的信息。”
Mistral将其开源特性和定制能力作为核心差异化优势,允许企业根据具体需求对模型进行调整,从而使其在竞争中更具优势。
相关文章
 Spotify 推出由 ElevenLabs 提供技术支持的 AI 有声书创作工具
作为最新公告的一部分,Spotify 推出了一款由 ElevenLabs 提供技术支持的新 AI 工具,该工具允许作者通过“Spotify for Authors”平台直接自主发布有声书。在“投资者日”活动上,该公司确认该功能将于 6 月进入测试阶段,仅限受邀用户使用,且初期仅支持英语。使用这款AI驱动的有声书创作工具的作者无需签订独家协议,因此他们可以将生成的有声书分发到任何平台。此次公告是基于
最佳AI语音输入应用:专家评测与排行榜
AI语音输入应用在相对较短的时间内取得了显著进步。长期以来,这类应用反应迟缓且容易出错,要求用户必须使用特定的口音并清晰地表达。随着大型语言模型(LLMs)和语音转文本技术的进步,这一状况已然改变。如今的系统不仅能更准确地识别语音,还能利用上下文正确排版文本。开发者已集成自动去除口头语、修正语无伦次以及管理标点符号等功能,生成的文本几乎无需编辑。鉴于目前可选方案众多,我们整理了一份当前最佳且最实用
尽管面临挑战,Wispr Flow 仍押注印度语音人工智能的未来
印度的数字生态系统与语音技术紧密相连,从语音备忘录到多语言消息传递皆是如此。鉴于该国语言多样性、语言切换的惯例以及各异的变现潜力,将这些普遍存在的习惯转化为可扩展的AI业务面临着巨大挑战。Wispr Flow正致力于把握这一复杂但前景广阔的机遇。这家总部位于旧金山湾区的初创公司专注于开发人工智能驱动的语音输入软件,其报告显示印度目前已成为其增长最快的市场。尽管该地区基于语音的人工智能产品仍处于早期
相关专题推荐
商业
Spotify 推出由 ElevenLabs 提供技术支持的 AI 有声书创作工具
作为最新公告的一部分,Spotify 推出了一款由 ElevenLabs 提供技术支持的新 AI 工具,该工具允许作者通过“Spotify for Authors”平台直接自主发布有声书。在“投资者日”活动上,该公司确认该功能将于 6 月进入测试阶段,仅限受邀用户使用,且初期仅支持英语。使用这款AI驱动的有声书创作工具的作者无需签订独家协议,因此他们可以将生成的有声书分发到任何平台。此次公告是基于
最佳AI语音输入应用:专家评测与排行榜
AI语音输入应用在相对较短的时间内取得了显著进步。长期以来,这类应用反应迟缓且容易出错,要求用户必须使用特定的口音并清晰地表达。随着大型语言模型(LLMs)和语音转文本技术的进步,这一状况已然改变。如今的系统不仅能更准确地识别语音,还能利用上下文正确排版文本。开发者已集成自动去除口头语、修正语无伦次以及管理标点符号等功能,生成的文本几乎无需编辑。鉴于目前可选方案众多,我们整理了一份当前最佳且最实用
尽管面临挑战,Wispr Flow 仍押注印度语音人工智能的未来
印度的数字生态系统与语音技术紧密相连,从语音备忘录到多语言消息传递皆是如此。鉴于该国语言多样性、语言切换的惯例以及各异的变现潜力,将这些普遍存在的习惯转化为可扩展的AI业务面临着巨大挑战。Wispr Flow正致力于把握这一复杂但前景广阔的机遇。这家总部位于旧金山湾区的初创公司专注于开发人工智能驱动的语音输入软件,其报告显示印度目前已成为其增长最快的市场。尽管该地区基于语音的人工智能产品仍处于早期
相关专题推荐
商业
 最佳人工智能招聘工具:筛选简历并自动安排候选人面试
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
 10 个工具
10 个工具
 xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai
代码
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

 评论 (0)
0/500
评论 (0)
0/500
法国人工智能公司Mistral于周四发布了一款新的开源文本转语音模型,该模型专为语音AI助手及客户支持等企业应用而设计。该模型使企业能够构建用于销售和客户互动的语音代理,从而使Mistral成为ElevenLabs、Deepgram和OpenAI的直接竞争对手。
该模型名为Voxtral TTS,支持九种语言,包括英语、法语、德语、西班牙语、荷兰语、葡萄牙语、意大利语、印地语和阿拉伯语。
“我们的客户一直都在寻求语音模型。因此,我们开发了一个小型语音模型,可以适配智能手表、智能手机、笔记本电脑或其他边缘设备。其成本仅为市场上其他产品的零头,却能提供最先进的性能,”Mistral AI科学运营副总裁皮埃尔·斯托克(Pierre Stock)在接受TechCrunch电话采访时表示。
图片来源:Mistral
Mistral表示,该新模型仅需不到5秒的语音样本即可适应特定声音,能捕捉细微的口音、语调变化、语调以及语音流中的不规则之处。基于Ministral 3B构建的该模型,可在保持声音特征的同时流畅切换语言,非常适合配音或实时翻译。斯托克指出,公司的目标是让模型听起来像真人,而非机械音。
据该公司介绍,该模型专为实时性能而设计。其“首次发声时间”(TTFA)——即从接收输入到开始“说话”所需的时间——对于一段10秒、500字符的样本而言仅为90毫秒。 该模型还实现了6倍的实时因子(RTF),这意味着它能在约1.6秒内生成一段10秒的音频片段。
图片来源:Mistral AI
今年早些时候,Mistral 推出了两款转录模型——一款用于大规模批量处理,另一款用于低延迟的实时应用场景。随着这款新语音模型的推出,该公司似乎正在为企业构建一套全面的语音产品套件。
Stock补充道:“我们计划打造一个端到端的平台,能够处理多模态输入流——包括音频、文本和图像——以及输出。其关键优势在于,支持音频输入和输出的端到端代理系统能提供更为丰富的信息。”
Mistral将其开源特性和定制能力作为核心差异化优势,允许企业根据具体需求对模型进行调整,从而使其在竞争中更具优势。










 Spotify 推出由 ElevenLabs 提供技术支持的 AI 有声书创作工具
作为最新公告的一部分,Spotify 推出了一款由 ElevenLabs 提供技术支持的新 AI 工具,该工具允许作者通过“Spotify for Authors”平台直接自主发布有声书。在“投资者日”活动上,该公司确认该功能将于 6 月进入测试阶段,仅限受邀用户使用,且初期仅支持英语。使用这款AI驱动的有声书创作工具的作者无需签订独家协议,因此他们可以将生成的有声书分发到任何平台。此次公告是基于
Spotify 推出由 ElevenLabs 提供技术支持的 AI 有声书创作工具
作为最新公告的一部分,Spotify 推出了一款由 ElevenLabs 提供技术支持的新 AI 工具,该工具允许作者通过“Spotify for Authors”平台直接自主发布有声书。在“投资者日”活动上,该公司确认该功能将于 6 月进入测试阶段,仅限受邀用户使用,且初期仅支持英语。使用这款AI驱动的有声书创作工具的作者无需签订独家协议,因此他们可以将生成的有声书分发到任何平台。此次公告是基于
 最佳AI语音输入应用:专家评测与排行榜
AI语音输入应用在相对较短的时间内取得了显著进步。长期以来,这类应用反应迟缓且容易出错,要求用户必须使用特定的口音并清晰地表达。随着大型语言模型(LLMs)和语音转文本技术的进步,这一状况已然改变。如今的系统不仅能更准确地识别语音,还能利用上下文正确排版文本。开发者已集成自动去除口头语、修正语无伦次以及管理标点符号等功能,生成的文本几乎无需编辑。鉴于目前可选方案众多,我们整理了一份当前最佳且最实用
最佳AI语音输入应用:专家评测与排行榜
AI语音输入应用在相对较短的时间内取得了显著进步。长期以来,这类应用反应迟缓且容易出错,要求用户必须使用特定的口音并清晰地表达。随着大型语言模型(LLMs)和语音转文本技术的进步,这一状况已然改变。如今的系统不仅能更准确地识别语音,还能利用上下文正确排版文本。开发者已集成自动去除口头语、修正语无伦次以及管理标点符号等功能,生成的文本几乎无需编辑。鉴于目前可选方案众多,我们整理了一份当前最佳且最实用
 尽管面临挑战,Wispr Flow 仍押注印度语音人工智能的未来
印度的数字生态系统与语音技术紧密相连,从语音备忘录到多语言消息传递皆是如此。鉴于该国语言多样性、语言切换的惯例以及各异的变现潜力,将这些普遍存在的习惯转化为可扩展的AI业务面临着巨大挑战。Wispr Flow正致力于把握这一复杂但前景广阔的机遇。这家总部位于旧金山湾区的初创公司专注于开发人工智能驱动的语音输入软件,其报告显示印度目前已成为其增长最快的市场。尽管该地区基于语音的人工智能产品仍处于早期
尽管面临挑战,Wispr Flow 仍押注印度语音人工智能的未来
印度的数字生态系统与语音技术紧密相连,从语音备忘录到多语言消息传递皆是如此。鉴于该国语言多样性、语言切换的惯例以及各异的变现潜力,将这些普遍存在的习惯转化为可扩展的AI业务面临着巨大挑战。Wispr Flow正致力于把握这一复杂但前景广阔的机遇。这家总部位于旧金山湾区的初创公司专注于开发人工智能驱动的语音输入软件,其报告显示印度目前已成为其增长最快的市场。尽管该地区基于语音的人工智能产品仍处于早期

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai













