
















 首頁
首頁Mistral 推出開源語音生成模型
法國人工智慧公司 Mistral 於週四推出一款全新的開源文字轉語音模型,專為語音 AI 助理及客戶支援等企業應用而設計。該模型使企業能夠開發用於銷售和客戶互動的語音代理,使 Mistral 成為 ElevenLabs、Deepgram 和 OpenAI 的直接競爭對手。
這款名為 Voxtral TTS 的模型支援九種語言,包括英語、法語、德語、西班牙語、荷蘭語、葡萄牙語、義大利語、印地語和阿拉伯語。
「我們的客戶一直都在尋求語音模型。因此,我們開發了一款體積小巧的語音模型,能夠運行於智慧手錶、智慧型手機、筆記型電腦或其他邊緣裝置上。其成本僅為市場上其他產品的零頭,卻能提供最先進的性能,」Mistral AI 科學運營副總裁 Pierre Stock 在接受 TechCrunch 電話採訪時表示。
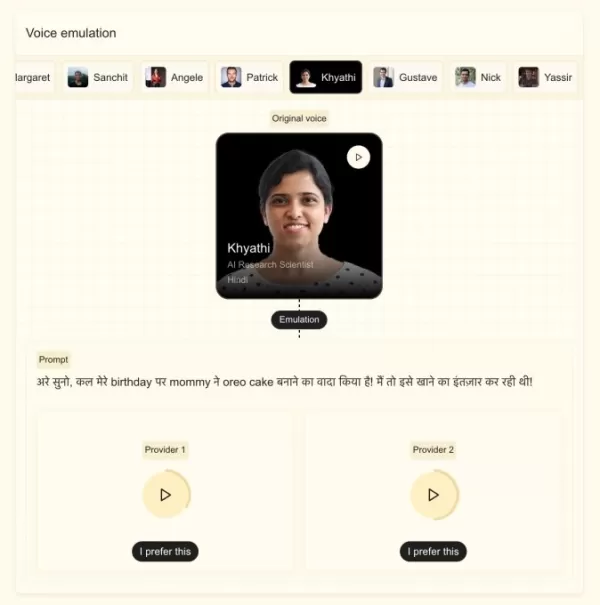
圖片來源:Mistral
Mistral 表示,這款新模型只需不到五秒的語音樣本,就能適應特定使用者的聲音,並能捕捉細微的口音、語調變化、語氣以及語流中的不規則性。該模型基於 Mistral 3B 建構,能在保持語音特徵的同時流暢地切換語言,使其非常適合用於配音或即時翻譯。Stock 指出,公司的目標是讓模型聽起來像真人,而非機器人。
據該公司表示,此模型專為即時表現而設計。其「首次發聲時間」(TTFA)——即從接收輸入到開始「說話」所需的時間——針對 10 秒、500 字元的樣本,僅需 90 毫秒。 該模型還達到了 6 倍的即時係數(RTF),這意味著它大約只需 1.6 秒即可生成 10 秒的音頻片段。
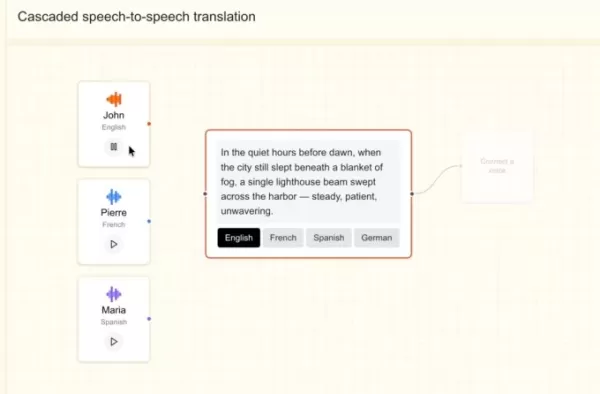
圖片來源:Mistral AI
今年稍早,Mistral 推出了兩款轉錄模型——一款用於大規模批次處理,另一款則針對低延遲的即時應用場景。隨著這款新語音模型的推出,該公司似乎正致力於為企業打造一套全面的語音產品組合。
Stock 補充道:「我們計劃打造一個端到端的平台,能夠處理多模態輸入流——包括音訊、文字和圖像——以及輸出。其關鍵優勢在於,支援音訊輸入與輸出的端到端代理系統能提供更豐富的信息。」
Mistral 將其開源特性與客製化能力視為關鍵差異化優勢,讓企業能根據自身特定需求調整模型,因此相較於競爭對手的解決方案更具吸引力。
相關文章
 Spotify 推出由 ElevenLabs 技術驅動的人工智慧有聲書創作工具
作為最新公告的一部分,Spotify 推出了一款由 ElevenLabs 提供技術支援的新 AI 工具,讓作者能直接透過「Spotify for Authors」平台自行發行有聲書。在「投資者日」活動中,該公司確認這項功能將於六月進入測試階段,初期僅限受邀者使用,且僅支援英文。使用這項 AI 驅動的有聲書創作工具的作者無需簽署獨家協議,因此他們可以將生成的有聲書發行至任何平台。此項公告是基於 Sp
頂尖 AI 語音輸入應用程式:專家評測與排行榜
AI 語音輸入應用程式在相對短的時間內取得了顯著進展。長期以來,這些應用程式反應遲緩且容易出錯,要求使用者必須以特定口音清晰地發音。隨著大型語言模型(LLMs)與語音轉文字技術的進步,這種情況已然改變,如今的系統不僅能更精準地理解語音,還能運用語境來正確格式化文字。開發者已整合多項功能,可自動刪除口頭語、修正口誤並管理標點符號,產出的文字幾乎無需編輯。鑑於現今選擇眾多,我們整理了一份您現在即可使用
儘管面臨挑戰,Wispr Flow 仍看好語音 AI 在印度的未來
印度的數位生態系與語音技術緊密交織,從語音備忘錄到多語言訊息傳遞皆然。鑑於該國語言的多樣性、切換語言的慣例,以及各異的變現潛力,要將這些普遍的習慣轉化為可擴展的 AI 業務,面臨著巨大的挑戰。Wispr Flow 正積極定位自身,以把握這個複雜卻充滿前景的商機。這家總部位於灣區、專注開發 AI 驅動語音輸入軟體的新創公司表示,印度現已成為其成長最快的市場。即使該地區的語音 AI 產品仍處於早期階段
相關專題推薦
商業
Spotify 推出由 ElevenLabs 技術驅動的人工智慧有聲書創作工具
作為最新公告的一部分,Spotify 推出了一款由 ElevenLabs 提供技術支援的新 AI 工具,讓作者能直接透過「Spotify for Authors」平台自行發行有聲書。在「投資者日」活動中,該公司確認這項功能將於六月進入測試階段,初期僅限受邀者使用,且僅支援英文。使用這項 AI 驅動的有聲書創作工具的作者無需簽署獨家協議,因此他們可以將生成的有聲書發行至任何平台。此項公告是基於 Sp
頂尖 AI 語音輸入應用程式:專家評測與排行榜
AI 語音輸入應用程式在相對短的時間內取得了顯著進展。長期以來,這些應用程式反應遲緩且容易出錯,要求使用者必須以特定口音清晰地發音。隨著大型語言模型(LLMs)與語音轉文字技術的進步,這種情況已然改變,如今的系統不僅能更精準地理解語音,還能運用語境來正確格式化文字。開發者已整合多項功能,可自動刪除口頭語、修正口誤並管理標點符號,產出的文字幾乎無需編輯。鑑於現今選擇眾多,我們整理了一份您現在即可使用
儘管面臨挑戰,Wispr Flow 仍看好語音 AI 在印度的未來
印度的數位生態系與語音技術緊密交織,從語音備忘錄到多語言訊息傳遞皆然。鑑於該國語言的多樣性、切換語言的慣例,以及各異的變現潛力,要將這些普遍的習慣轉化為可擴展的 AI 業務,面臨著巨大的挑戰。Wispr Flow 正積極定位自身,以把握這個複雜卻充滿前景的商機。這家總部位於灣區、專注開發 AI 驅動語音輸入軟體的新創公司表示,印度現已成為其成長最快的市場。即使該地區的語音 AI 產品仍處於早期階段
相關專題推薦
商業
 最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
法國人工智慧公司 Mistral 於週四推出一款全新的開源文字轉語音模型,專為語音 AI 助理及客戶支援等企業應用而設計。該模型使企業能夠開發用於銷售和客戶互動的語音代理,使 Mistral 成為 ElevenLabs、Deepgram 和 OpenAI 的直接競爭對手。
這款名為 Voxtral TTS 的模型支援九種語言,包括英語、法語、德語、西班牙語、荷蘭語、葡萄牙語、義大利語、印地語和阿拉伯語。
「我們的客戶一直都在尋求語音模型。因此,我們開發了一款體積小巧的語音模型,能夠運行於智慧手錶、智慧型手機、筆記型電腦或其他邊緣裝置上。其成本僅為市場上其他產品的零頭,卻能提供最先進的性能,」Mistral AI 科學運營副總裁 Pierre Stock 在接受 TechCrunch 電話採訪時表示。
圖片來源:Mistral
Mistral 表示,這款新模型只需不到五秒的語音樣本,就能適應特定使用者的聲音,並能捕捉細微的口音、語調變化、語氣以及語流中的不規則性。該模型基於 Mistral 3B 建構,能在保持語音特徵的同時流暢地切換語言,使其非常適合用於配音或即時翻譯。Stock 指出,公司的目標是讓模型聽起來像真人,而非機器人。
據該公司表示,此模型專為即時表現而設計。其「首次發聲時間」(TTFA)——即從接收輸入到開始「說話」所需的時間——針對 10 秒、500 字元的樣本,僅需 90 毫秒。 該模型還達到了 6 倍的即時係數(RTF),這意味著它大約只需 1.6 秒即可生成 10 秒的音頻片段。
圖片來源:Mistral AI
今年稍早,Mistral 推出了兩款轉錄模型——一款用於大規模批次處理,另一款則針對低延遲的即時應用場景。隨著這款新語音模型的推出,該公司似乎正致力於為企業打造一套全面的語音產品組合。
Stock 補充道:「我們計劃打造一個端到端的平台,能夠處理多模態輸入流——包括音訊、文字和圖像——以及輸出。其關鍵優勢在於,支援音訊輸入與輸出的端到端代理系統能提供更豐富的信息。」
Mistral 將其開源特性與客製化能力視為關鍵差異化優勢,讓企業能根據自身特定需求調整模型,因此相較於競爭對手的解決方案更具吸引力。










 Spotify 推出由 ElevenLabs 技術驅動的人工智慧有聲書創作工具
作為最新公告的一部分,Spotify 推出了一款由 ElevenLabs 提供技術支援的新 AI 工具,讓作者能直接透過「Spotify for Authors」平台自行發行有聲書。在「投資者日」活動中,該公司確認這項功能將於六月進入測試階段,初期僅限受邀者使用,且僅支援英文。使用這項 AI 驅動的有聲書創作工具的作者無需簽署獨家協議,因此他們可以將生成的有聲書發行至任何平台。此項公告是基於 Sp
Spotify 推出由 ElevenLabs 技術驅動的人工智慧有聲書創作工具
作為最新公告的一部分,Spotify 推出了一款由 ElevenLabs 提供技術支援的新 AI 工具,讓作者能直接透過「Spotify for Authors」平台自行發行有聲書。在「投資者日」活動中,該公司確認這項功能將於六月進入測試階段,初期僅限受邀者使用,且僅支援英文。使用這項 AI 驅動的有聲書創作工具的作者無需簽署獨家協議,因此他們可以將生成的有聲書發行至任何平台。此項公告是基於 Sp
 頂尖 AI 語音輸入應用程式:專家評測與排行榜
AI 語音輸入應用程式在相對短的時間內取得了顯著進展。長期以來,這些應用程式反應遲緩且容易出錯,要求使用者必須以特定口音清晰地發音。隨著大型語言模型(LLMs)與語音轉文字技術的進步,這種情況已然改變,如今的系統不僅能更精準地理解語音,還能運用語境來正確格式化文字。開發者已整合多項功能,可自動刪除口頭語、修正口誤並管理標點符號,產出的文字幾乎無需編輯。鑑於現今選擇眾多,我們整理了一份您現在即可使用
頂尖 AI 語音輸入應用程式:專家評測與排行榜
AI 語音輸入應用程式在相對短的時間內取得了顯著進展。長期以來,這些應用程式反應遲緩且容易出錯,要求使用者必須以特定口音清晰地發音。隨著大型語言模型(LLMs)與語音轉文字技術的進步,這種情況已然改變,如今的系統不僅能更精準地理解語音,還能運用語境來正確格式化文字。開發者已整合多項功能,可自動刪除口頭語、修正口誤並管理標點符號,產出的文字幾乎無需編輯。鑑於現今選擇眾多,我們整理了一份您現在即可使用
 儘管面臨挑戰,Wispr Flow 仍看好語音 AI 在印度的未來
印度的數位生態系與語音技術緊密交織,從語音備忘錄到多語言訊息傳遞皆然。鑑於該國語言的多樣性、切換語言的慣例,以及各異的變現潛力,要將這些普遍的習慣轉化為可擴展的 AI 業務,面臨著巨大的挑戰。Wispr Flow 正積極定位自身,以把握這個複雜卻充滿前景的商機。這家總部位於灣區、專注開發 AI 驅動語音輸入軟體的新創公司表示,印度現已成為其成長最快的市場。即使該地區的語音 AI 產品仍處於早期階段
儘管面臨挑戰,Wispr Flow 仍看好語音 AI 在印度的未來
印度的數位生態系與語音技術緊密交織,從語音備忘錄到多語言訊息傳遞皆然。鑑於該國語言的多樣性、切換語言的慣例,以及各異的變現潛力,要將這些普遍的習慣轉化為可擴展的 AI 業務,面臨著巨大的挑戰。Wispr Flow 正積極定位自身,以把握這個複雜卻充滿前景的商機。這家總部位於灣區、專注開發 AI 驅動語音輸入軟體的新創公司表示,印度現已成為其成長最快的市場。即使該地區的語音 AI 產品仍處於早期階段

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai













