
















 家
家ミストラル、オープンソースの音声生成モデルを発表
フランスのAI企業Mistralは木曜日、音声AIアシスタントやカスタマーサポートなどの企業向けアプリケーション向けに設計された、新しいオープンソースのテキスト読み上げ(TTS)モデルを発表した。このモデルにより、企業は営業や顧客エンゲージメントのための音声エージェントを構築できるようになり、MistralはElevenLabs、Deepgram、OpenAIの直接的な競合相手としての地位を確立した。
「Voxtral TTS」と名付けられたこのモデルは、英語、フランス語、ドイツ語、スペイン語、オランダ語、ポルトガル語、イタリア語、ヒンディー語、アラビア語の9言語に対応している。
「顧客から音声モデルの要望が寄せられていました。そこで、スマートウォッチ、スマートフォン、ノートPC、その他のエッジデバイスに搭載可能な小型の音声モデルを開発しました。コストは市場の他製品に比べてごくわずかですが、最先端の性能を発揮します」と、Mistral AIのサイエンスオペレーション担当副社長であるピエール・ストック氏は、TechCrunchとの電話インタビューで語った。
画像提供:Mistral
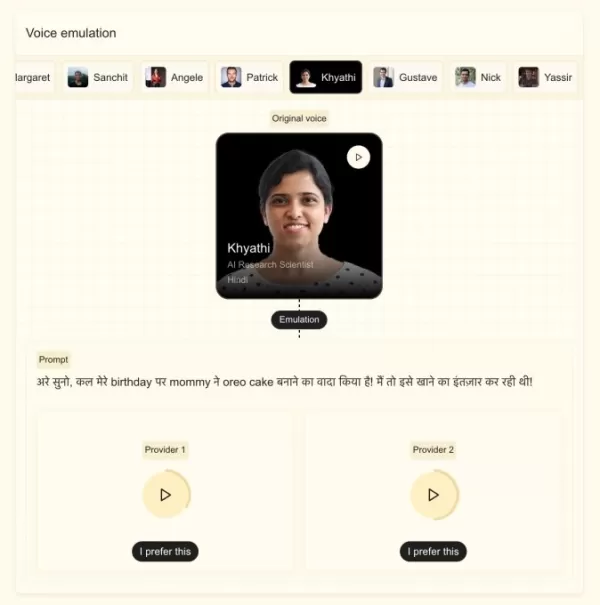
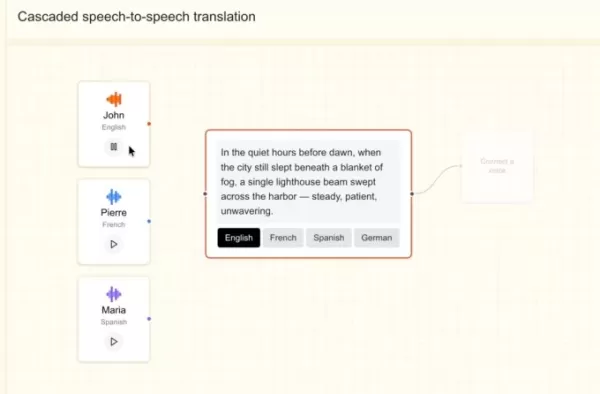
Mistral社によると、この新モデルは5秒未満の音声サンプルを用いて特定の声に順応でき、微妙なアクセント、抑揚、イントネーション、そして話し方の不規則性まで捉えることができるという。Ministral 3Bを基盤として構築されており、声の特性を維持したまま言語を切り替えることができるため、吹き替えやリアルタイム翻訳に最適だ。ストック氏は、同社がロボットのような音声ではなく、人間らしい音声を実現することを目指したと述べた。
同社によると、このモデルはリアルタイム性能を重視して設計されている。入力を受け取ってから「話し始める」までの時間である「Time-to-First-Audio(TTFA)」は、500文字の10秒間のサンプルに対して90ミリ秒である。 また、このモデルはリアルタイムファクター(RTF)6倍を達成しており、10秒間のクリップを約1.6秒で生成できることを意味する。
画像提供:Mistral AI
今年初め、Mistralは2つの文字起こしモデルをリリースしました。1つは大規模なバッチ処理用、もう1つは低遅延のリアルタイムユースケース向けです。この新しい音声モデルにより、同社は企業向けの包括的な音声製品スイートを構築しているようです。
ストック氏は次のように付け加えた。「音声、テキスト、画像といったマルチモーダルな入力ストリームと出力を処理できるエンドツーエンドのプラットフォームを構築する計画だ。最大の利点は、音声の入出力に対応したエンドツーエンドのエージェンティックシステムが、はるかに豊富な情報を提供できる点にある。」
Mistralは、そのオープンソースという性質とカスタマイズ機能を主要な差別化要因として位置付けており、企業が特定のニーズに合わせてモデルを調整できるため、競合他社のソリューションよりも優位性があるとしています。
関連記事
 Spotify、ElevenLabsの技術を活用したAIオーディオブック作成ツールを発表
Spotifyは最新の発表の一環として、ElevenLabsの技術を活用した新しいAIツールを導入しました。これにより、著者は「Spotify for Authors」プラットフォームを通じて、オーディオブックを直接セルフパブリッシングできるようになります。同社は「Investor Day」イベントにおいて、この機能が6月にベータ版として提供開始されることを明らかにしました。利用は招待制となり、当
おすすめのAI音声入力アプリ:専門家のレビューとランキング
AI音声入力アプリは、比較的短期間で目覚ましい進歩を遂げました。長い間、これらのアプリは動作が重く、誤認識も多いため、ユーザーは特定のアクセントで、かつ非常に明瞭に話す必要がありました。しかし、大規模言語モデル(LLM)や音声認識技術の進歩により、状況は一変しました。現在では、音声をより正確に理解するだけでなく、文脈を把握して適切な形式でテキストを生成できるシステムが実現しています。開発者たちは、
Wispr Flow、課題はあるもののインドにおける音声AIの将来性に賭ける
インドのデジタル環境は、音声メモから多言語メッセージングに至るまで、音声技術と深く結びついています。しかし、同国の言語的多様性、コードスイッチングの慣習、そして収益化の可能性のばらつきを考慮すると、こうした広く浸透した習慣をスケーラブルなAIビジネスへと転換するには、大きな課題が伴います。Wispr Flowは、この複雑ながらも有望な機会に取り組むべく、その地位を確立しつつあります。AIを活用した
関連特集おすすめ
生産性
Spotify、ElevenLabsの技術を活用したAIオーディオブック作成ツールを発表
Spotifyは最新の発表の一環として、ElevenLabsの技術を活用した新しいAIツールを導入しました。これにより、著者は「Spotify for Authors」プラットフォームを通じて、オーディオブックを直接セルフパブリッシングできるようになります。同社は「Investor Day」イベントにおいて、この機能が6月にベータ版として提供開始されることを明らかにしました。利用は招待制となり、当
おすすめのAI音声入力アプリ:専門家のレビューとランキング
AI音声入力アプリは、比較的短期間で目覚ましい進歩を遂げました。長い間、これらのアプリは動作が重く、誤認識も多いため、ユーザーは特定のアクセントで、かつ非常に明瞭に話す必要がありました。しかし、大規模言語モデル(LLM)や音声認識技術の進歩により、状況は一変しました。現在では、音声をより正確に理解するだけでなく、文脈を把握して適切な形式でテキストを生成できるシステムが実現しています。開発者たちは、
Wispr Flow、課題はあるもののインドにおける音声AIの将来性に賭ける
インドのデジタル環境は、音声メモから多言語メッセージングに至るまで、音声技術と深く結びついています。しかし、同国の言語的多様性、コードスイッチングの慣習、そして収益化の可能性のばらつきを考慮すると、こうした広く浸透した習慣をスケーラブルなAIビジネスへと転換するには、大きな課題が伴います。Wispr Flowは、この複雑ながらも有望な機会に取り組むべく、その地位を確立しつつあります。AIを活用した
関連特集おすすめ
生産性
 AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
 10 ツール
10 ツール
 xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
フランスのAI企業Mistralは木曜日、音声AIアシスタントやカスタマーサポートなどの企業向けアプリケーション向けに設計された、新しいオープンソースのテキスト読み上げ(TTS)モデルを発表した。このモデルにより、企業は営業や顧客エンゲージメントのための音声エージェントを構築できるようになり、MistralはElevenLabs、Deepgram、OpenAIの直接的な競合相手としての地位を確立した。
「Voxtral TTS」と名付けられたこのモデルは、英語、フランス語、ドイツ語、スペイン語、オランダ語、ポルトガル語、イタリア語、ヒンディー語、アラビア語の9言語に対応している。
「顧客から音声モデルの要望が寄せられていました。そこで、スマートウォッチ、スマートフォン、ノートPC、その他のエッジデバイスに搭載可能な小型の音声モデルを開発しました。コストは市場の他製品に比べてごくわずかですが、最先端の性能を発揮します」と、Mistral AIのサイエンスオペレーション担当副社長であるピエール・ストック氏は、TechCrunchとの電話インタビューで語った。
画像提供:Mistral
Mistral社によると、この新モデルは5秒未満の音声サンプルを用いて特定の声に順応でき、微妙なアクセント、抑揚、イントネーション、そして話し方の不規則性まで捉えることができるという。Ministral 3Bを基盤として構築されており、声の特性を維持したまま言語を切り替えることができるため、吹き替えやリアルタイム翻訳に最適だ。ストック氏は、同社がロボットのような音声ではなく、人間らしい音声を実現することを目指したと述べた。
同社によると、このモデルはリアルタイム性能を重視して設計されている。入力を受け取ってから「話し始める」までの時間である「Time-to-First-Audio(TTFA)」は、500文字の10秒間のサンプルに対して90ミリ秒である。 また、このモデルはリアルタイムファクター(RTF)6倍を達成しており、10秒間のクリップを約1.6秒で生成できることを意味する。
画像提供:Mistral AI
今年初め、Mistralは2つの文字起こしモデルをリリースしました。1つは大規模なバッチ処理用、もう1つは低遅延のリアルタイムユースケース向けです。この新しい音声モデルにより、同社は企業向けの包括的な音声製品スイートを構築しているようです。
ストック氏は次のように付け加えた。「音声、テキスト、画像といったマルチモーダルな入力ストリームと出力を処理できるエンドツーエンドのプラットフォームを構築する計画だ。最大の利点は、音声の入出力に対応したエンドツーエンドのエージェンティックシステムが、はるかに豊富な情報を提供できる点にある。」
Mistralは、そのオープンソースという性質とカスタマイズ機能を主要な差別化要因として位置付けており、企業が特定のニーズに合わせてモデルを調整できるため、競合他社のソリューションよりも優位性があるとしています。










 Spotify、ElevenLabsの技術を活用したAIオーディオブック作成ツールを発表
Spotifyは最新の発表の一環として、ElevenLabsの技術を活用した新しいAIツールを導入しました。これにより、著者は「Spotify for Authors」プラットフォームを通じて、オーディオブックを直接セルフパブリッシングできるようになります。同社は「Investor Day」イベントにおいて、この機能が6月にベータ版として提供開始されることを明らかにしました。利用は招待制となり、当
Spotify、ElevenLabsの技術を活用したAIオーディオブック作成ツールを発表
Spotifyは最新の発表の一環として、ElevenLabsの技術を活用した新しいAIツールを導入しました。これにより、著者は「Spotify for Authors」プラットフォームを通じて、オーディオブックを直接セルフパブリッシングできるようになります。同社は「Investor Day」イベントにおいて、この機能が6月にベータ版として提供開始されることを明らかにしました。利用は招待制となり、当
 おすすめのAI音声入力アプリ:専門家のレビューとランキング
AI音声入力アプリは、比較的短期間で目覚ましい進歩を遂げました。長い間、これらのアプリは動作が重く、誤認識も多いため、ユーザーは特定のアクセントで、かつ非常に明瞭に話す必要がありました。しかし、大規模言語モデル(LLM)や音声認識技術の進歩により、状況は一変しました。現在では、音声をより正確に理解するだけでなく、文脈を把握して適切な形式でテキストを生成できるシステムが実現しています。開発者たちは、
おすすめのAI音声入力アプリ:専門家のレビューとランキング
AI音声入力アプリは、比較的短期間で目覚ましい進歩を遂げました。長い間、これらのアプリは動作が重く、誤認識も多いため、ユーザーは特定のアクセントで、かつ非常に明瞭に話す必要がありました。しかし、大規模言語モデル(LLM)や音声認識技術の進歩により、状況は一変しました。現在では、音声をより正確に理解するだけでなく、文脈を把握して適切な形式でテキストを生成できるシステムが実現しています。開発者たちは、
 Wispr Flow、課題はあるもののインドにおける音声AIの将来性に賭ける
インドのデジタル環境は、音声メモから多言語メッセージングに至るまで、音声技術と深く結びついています。しかし、同国の言語的多様性、コードスイッチングの慣習、そして収益化の可能性のばらつきを考慮すると、こうした広く浸透した習慣をスケーラブルなAIビジネスへと転換するには、大きな課題が伴います。Wispr Flowは、この複雑ながらも有望な機会に取り組むべく、その地位を確立しつつあります。AIを活用した
Wispr Flow、課題はあるもののインドにおける音声AIの将来性に賭ける
インドのデジタル環境は、音声メモから多言語メッセージングに至るまで、音声技術と深く結びついています。しかし、同国の言語的多様性、コードスイッチングの慣習、そして収益化の可能性のばらつきを考慮すると、こうした広く浸透した習慣をスケーラブルなAIビジネスへと転換するには、大きな課題が伴います。Wispr Flowは、この複雑ながらも有望な機会に取り組むべく、その地位を確立しつつあります。AIを活用した

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai













