
















 Heim
HeimMistral stellt ein Open-Source-Modell zur Sprachgenerierung vor
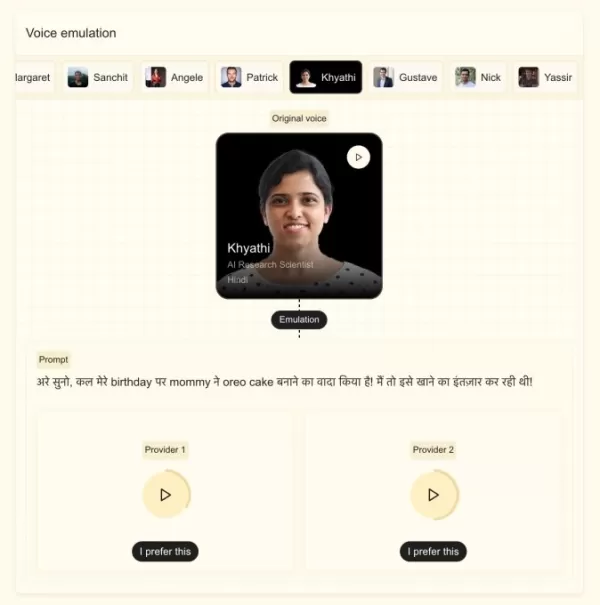
Das französische KI-Unternehmen Mistral hat am Donnerstag ein neues Open-Source-Text-to-Speech-Modell vorgestellt, das für Sprach-KI-Assistenten und Unternehmensanwendungen wie den Kundensupport konzipiert ist. Das Modell ermöglicht es Unternehmen, Sprachassistenten für den Vertrieb und die Kundenbindung zu entwickeln, wodurch sich Mistral als direkter Konkurrent von ElevenLabs, Deepgram und OpenAI positioniert.
Das Modell namens Voxtral TTS unterstützt neun Sprachen, darunter Englisch, Französisch, Deutsch, Spanisch, Niederländisch, Portugiesisch, Italienisch, Hindi und Arabisch.
„Unsere Kunden haben nach einem Sprachmodell gefragt. Deshalb haben wir ein kompaktes Sprachmodell entwickelt, das auf eine Smartwatch, ein Smartphone, einen Laptop oder andere Edge-Geräte passt. Die Kosten betragen nur einen Bruchteil dessen, was sonst auf dem Markt erhältlich ist, dennoch bietet es Leistung auf dem neuesten Stand der Technik“, sagte Pierre Stock, VP of Science Operations bei Mistral AI, in einem Telefoninterview mit TechCrunch.
Bildnachweis: Mistral
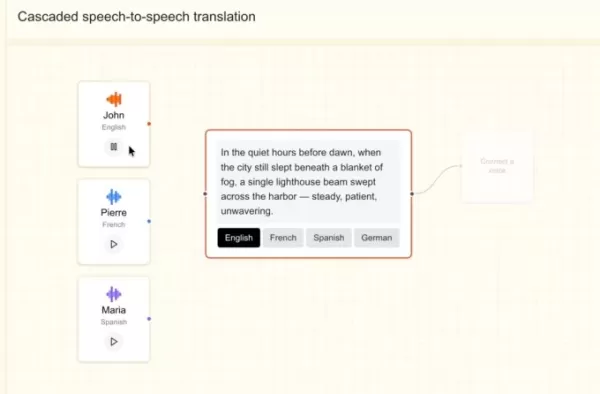
Mistral gibt an, dass sich das neue Modell anhand einer weniger als fünf Sekunden langen Sprachprobe an eine individuelle Stimme anpassen kann und dabei subtile Akzente, Betonungen, Intonationen und Unregelmäßigkeiten im Sprachfluss erfasst. Es basiert auf Mistral 3B und kann nahtlos zwischen Sprachen wechseln, während die Stimmcharakteristika erhalten bleiben, was es ideal für Synchronisation oder Echtzeitübersetzung macht. Stock merkte an, dass das Unternehmen darauf abzielte, das Modell menschlich klingen zu lassen, nicht roboterhaft.
Nach Angaben des Unternehmens ist das Modell für Echtzeitleistung ausgelegt. Seine „Time-to-First-Audio“ (TTFA) – die Zeit zwischen dem Empfang der Eingabe und dem Beginn des „Sprechens“ – beträgt 90 ms für ein 10-Sekunden-Beispiel mit 500 Zeichen. Das Modell erreicht zudem einen Echtzeitfaktor (RTF) von 6x, was bedeutet, dass es einen 10-Sekunden-Clip in etwa 1,6 Sekunden generieren kann.
Bildnachweis: Mistral AI
Anfang dieses Jahres brachte Mistral zwei Transkriptionsmodelle auf den Markt – eines für die groß angelegte Stapelverarbeitung, das andere für Echtzeit-Anwendungsfälle mit geringer Latenz. Mit dem neuen Sprachmodell scheint das Unternehmen eine umfassende Suite von Sprachprodukten für Unternehmen aufzubauen.
Stock fügte hinzu: „Wir planen die Entwicklung einer End-to-End-Plattform, die multimodale Eingabeströme – Audio, Text und Bild – sowie die Ausgabe verarbeiten kann. Der entscheidende Vorteil besteht darin, dass ein End-to-End-Agentensystem, das Audioeingabe und -ausgabe unterstützt, wesentlich reichhaltigere Informationen liefert.“
Mistral positioniert seinen Open-Source-Charakter und seine Anpassungsmöglichkeiten als wesentliche Alleinstellungsmerkmale, die es Unternehmen ermöglichen, das Modell an ihre spezifischen Bedürfnisse anzupassen, und hebt sich damit von Lösungen der Konkurrenz ab.
Verwandter Artikel
 Spotify stellt ein KI-basiertes Tool zur Erstellung von Hörbüchern vor, das auf der Technologie von ElevenLabs basiert
Im Rahmen seiner jüngsten Ankündigungen stellte Spotify ein neues KI-Tool vor, das auf der Technologie von ElevenLabs basiert und es Autoren ermöglicht, Hörbücher direkt über die Plattform „Spotify fo
Die besten KI-Diktat-Apps: Expertenbewertungen und Rankings
KI-Diktier-Apps haben in relativ kurzer Zeit bemerkenswerte Fortschritte gemacht. Lange Zeit waren sie träge und fehleranfällig, sodass die Nutzer mit einem bestimmten Akzent und vollkommen deutlich s
Wispr Flow setzt trotz Herausforderungen auf die Zukunft der Sprach-KI in Indien
Indiens digitale Landschaft ist stark von Sprachtechnologie geprägt, von Sprachnotizen bis hin zu mehrsprachigem Messaging. Die Umwandlung dieser weit verbreiteten Gewohnheiten in ein skalierbares KI-
Empfehlungen zu verwandten Spezialthemen
Produktivität
Spotify stellt ein KI-basiertes Tool zur Erstellung von Hörbüchern vor, das auf der Technologie von ElevenLabs basiert
Im Rahmen seiner jüngsten Ankündigungen stellte Spotify ein neues KI-Tool vor, das auf der Technologie von ElevenLabs basiert und es Autoren ermöglicht, Hörbücher direkt über die Plattform „Spotify fo
Die besten KI-Diktat-Apps: Expertenbewertungen und Rankings
KI-Diktier-Apps haben in relativ kurzer Zeit bemerkenswerte Fortschritte gemacht. Lange Zeit waren sie träge und fehleranfällig, sodass die Nutzer mit einem bestimmten Akzent und vollkommen deutlich s
Wispr Flow setzt trotz Herausforderungen auf die Zukunft der Sprach-KI in Indien
Indiens digitale Landschaft ist stark von Sprachtechnologie geprägt, von Sprachnotizen bis hin zu mehrsprachigem Messaging. Die Umwandlung dieser weit verbreiteten Gewohnheiten in ein skalierbares KI-
Empfehlungen zu verwandten Spezialthemen
Produktivität
 KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
 10 Tools
10 Tools
 xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai
Datenanalyse
Die besten KI-Tools zur Datenvisualisierung: Interaktive BI-Dashboards automatisch aus Rohdaten generieren
Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Das französische KI-Unternehmen Mistral hat am Donnerstag ein neues Open-Source-Text-to-Speech-Modell vorgestellt, das für Sprach-KI-Assistenten und Unternehmensanwendungen wie den Kundensupport konzipiert ist. Das Modell ermöglicht es Unternehmen, Sprachassistenten für den Vertrieb und die Kundenbindung zu entwickeln, wodurch sich Mistral als direkter Konkurrent von ElevenLabs, Deepgram und OpenAI positioniert.
Das Modell namens Voxtral TTS unterstützt neun Sprachen, darunter Englisch, Französisch, Deutsch, Spanisch, Niederländisch, Portugiesisch, Italienisch, Hindi und Arabisch.
„Unsere Kunden haben nach einem Sprachmodell gefragt. Deshalb haben wir ein kompaktes Sprachmodell entwickelt, das auf eine Smartwatch, ein Smartphone, einen Laptop oder andere Edge-Geräte passt. Die Kosten betragen nur einen Bruchteil dessen, was sonst auf dem Markt erhältlich ist, dennoch bietet es Leistung auf dem neuesten Stand der Technik“, sagte Pierre Stock, VP of Science Operations bei Mistral AI, in einem Telefoninterview mit TechCrunch.
Bildnachweis: Mistral
Mistral gibt an, dass sich das neue Modell anhand einer weniger als fünf Sekunden langen Sprachprobe an eine individuelle Stimme anpassen kann und dabei subtile Akzente, Betonungen, Intonationen und Unregelmäßigkeiten im Sprachfluss erfasst. Es basiert auf Mistral 3B und kann nahtlos zwischen Sprachen wechseln, während die Stimmcharakteristika erhalten bleiben, was es ideal für Synchronisation oder Echtzeitübersetzung macht. Stock merkte an, dass das Unternehmen darauf abzielte, das Modell menschlich klingen zu lassen, nicht roboterhaft.
Nach Angaben des Unternehmens ist das Modell für Echtzeitleistung ausgelegt. Seine „Time-to-First-Audio“ (TTFA) – die Zeit zwischen dem Empfang der Eingabe und dem Beginn des „Sprechens“ – beträgt 90 ms für ein 10-Sekunden-Beispiel mit 500 Zeichen. Das Modell erreicht zudem einen Echtzeitfaktor (RTF) von 6x, was bedeutet, dass es einen 10-Sekunden-Clip in etwa 1,6 Sekunden generieren kann.
Bildnachweis: Mistral AI
Anfang dieses Jahres brachte Mistral zwei Transkriptionsmodelle auf den Markt – eines für die groß angelegte Stapelverarbeitung, das andere für Echtzeit-Anwendungsfälle mit geringer Latenz. Mit dem neuen Sprachmodell scheint das Unternehmen eine umfassende Suite von Sprachprodukten für Unternehmen aufzubauen.
Stock fügte hinzu: „Wir planen die Entwicklung einer End-to-End-Plattform, die multimodale Eingabeströme – Audio, Text und Bild – sowie die Ausgabe verarbeiten kann. Der entscheidende Vorteil besteht darin, dass ein End-to-End-Agentensystem, das Audioeingabe und -ausgabe unterstützt, wesentlich reichhaltigere Informationen liefert.“
Mistral positioniert seinen Open-Source-Charakter und seine Anpassungsmöglichkeiten als wesentliche Alleinstellungsmerkmale, die es Unternehmen ermöglichen, das Modell an ihre spezifischen Bedürfnisse anzupassen, und hebt sich damit von Lösungen der Konkurrenz ab.










 Spotify stellt ein KI-basiertes Tool zur Erstellung von Hörbüchern vor, das auf der Technologie von ElevenLabs basiert
Im Rahmen seiner jüngsten Ankündigungen stellte Spotify ein neues KI-Tool vor, das auf der Technologie von ElevenLabs basiert und es Autoren ermöglicht, Hörbücher direkt über die Plattform „Spotify fo
Spotify stellt ein KI-basiertes Tool zur Erstellung von Hörbüchern vor, das auf der Technologie von ElevenLabs basiert
Im Rahmen seiner jüngsten Ankündigungen stellte Spotify ein neues KI-Tool vor, das auf der Technologie von ElevenLabs basiert und es Autoren ermöglicht, Hörbücher direkt über die Plattform „Spotify fo
 Die besten KI-Diktat-Apps: Expertenbewertungen und Rankings
KI-Diktier-Apps haben in relativ kurzer Zeit bemerkenswerte Fortschritte gemacht. Lange Zeit waren sie träge und fehleranfällig, sodass die Nutzer mit einem bestimmten Akzent und vollkommen deutlich s
Die besten KI-Diktat-Apps: Expertenbewertungen und Rankings
KI-Diktier-Apps haben in relativ kurzer Zeit bemerkenswerte Fortschritte gemacht. Lange Zeit waren sie träge und fehleranfällig, sodass die Nutzer mit einem bestimmten Akzent und vollkommen deutlich s
 Wispr Flow setzt trotz Herausforderungen auf die Zukunft der Sprach-KI in Indien
Indiens digitale Landschaft ist stark von Sprachtechnologie geprägt, von Sprachnotizen bis hin zu mehrsprachigem Messaging. Die Umwandlung dieser weit verbreiteten Gewohnheiten in ein skalierbares KI-
Wispr Flow setzt trotz Herausforderungen auf die Zukunft der Sprach-KI in Indien
Indiens digitale Landschaft ist stark von Sprachtechnologie geprägt, von Sprachnotizen bis hin zu mehrsprachigem Messaging. Die Umwandlung dieser weit verbreiteten Gewohnheiten in ein skalierbares KI-

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai













