
















 Maison
MaisonMistral dévoile un modèle open source de synthèse vocale
La société française d'IA Mistral a dévoilé jeudi un nouveau modèle open source de synthèse vocale, conçu pour les assistants vocaux IA et les applications d'entreprise telles que le service client. Ce modèle permet aux entreprises de développer des agents vocaux destinés à la vente et à l'engagement client, positionnant ainsi Mistral comme un concurrent direct d'ElevenLabs, de Deepgram et d'OpenAI.
Baptisé Voxtral TTS, ce modèle prend en charge neuf langues, dont l'anglais, le français, l'allemand, l'espagnol, le néerlandais, le portugais, l'italien, l'hindi et l'arabe.
« Nos clients nous demandaient un modèle de synthèse vocale. Nous avons donc développé un modèle de petite taille pouvant s’intégrer à une montre connectée, un smartphone, un ordinateur portable ou d’autres appareils périphériques. Son coût est bien inférieur à celui de tout autre produit sur le marché, tout en offrant des performances de pointe », a déclaré Pierre Stock, vice-président des opérations scientifiques chez Mistral AI, lors d’un entretien téléphonique avec TechCrunch.
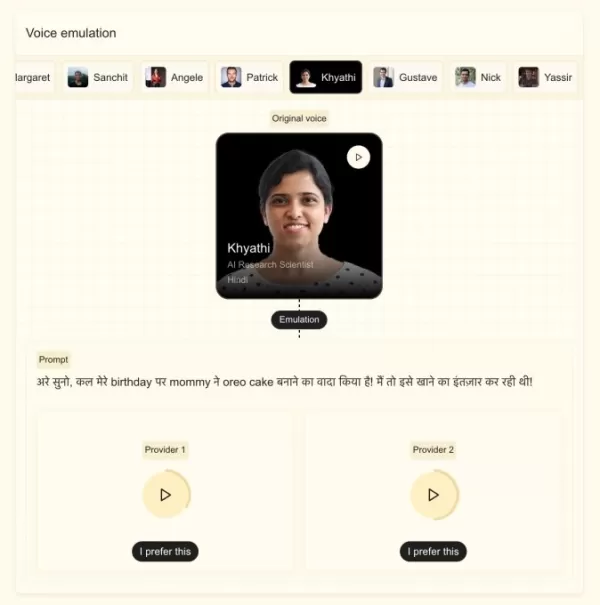
Crédit image : Mistral
Mistral affirme que ce nouveau modèle peut s’adapter à une voix personnalisée à partir d’un échantillon de moins de cinq secondes, en capturant les accents subtils, les inflexions, les intonations et les irrégularités du flux vocal. Basé sur Mistral 3B, il peut passer d’une langue à l’autre en douceur tout en conservant les caractéristiques vocales, ce qui le rend idéal pour le doublage ou la traduction en temps réel. M. Stock a souligné que l’entreprise avait pour objectif de donner au modèle une voix humaine, et non robotique.
Selon l'entreprise, le modèle est conçu pour fonctionner en temps réel. Son temps de réponse audio (TTFA) — le délai entre la réception de l'entrée et le début de la « parole » — est de 90 ms pour un échantillon de 10 secondes comprenant 500 caractères. Le modèle atteint également un facteur temps réel (RTF) de 6x, ce qui signifie qu’il peut générer un clip de 10 secondes en environ 1,6 seconde.
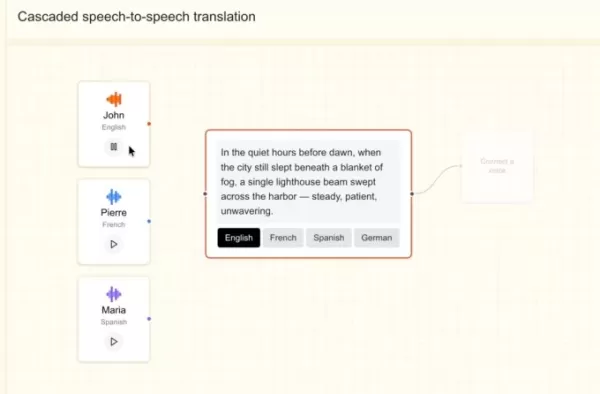
Crédit image : Mistral AI
Plus tôt cette année, Mistral a lancé deux modèles de transcription : l’un pour le traitement par lots à grande échelle, l’autre pour des cas d’utilisation en temps réel à faible latence. Avec ce nouveau modèle vocal, l’entreprise semble en train de développer une suite complète de produits vocaux destinés aux entreprises.
M. Stock a ajouté : « Nous prévoyons de créer une plateforme de bout en bout capable de gérer des flux d'entrée multimodaux — audio, texte et image — ainsi que des sorties. L'avantage principal est qu'un système agentique de bout en bout prenant en charge l'entrée et la sortie audio fournit des informations bien plus riches. »
Mistral met en avant son caractère open source et ses capacités de personnalisation comme principaux facteurs de différenciation, permettant aux entreprises d'adapter le modèle à leurs besoins spécifiques, ce qui le rend plus attractif que les solutions concurrentes.
Article connexe
 Spotify dévoile un outil de création d'audiobooks basé sur l'IA et développé par ElevenLabs
Dans le cadre de ses dernières annonces, Spotify a présenté un nouvel outil d'IA développé par ElevenLabs qui permet aux auteurs d'auto-publier des livres audio directement via la plateforme Spotify f
Les meilleures applications de dictée par IA : avis d'experts et classements
Les applications de dictée par IA ont fait des progrès remarquables en un laps de temps relativement court. Pendant longtemps, elles étaient lentes et sujettes à des erreurs, obligeant les utilisateur
Wispr Flow mise sur l'avenir de l'IA vocale en Inde malgré les défis
Le paysage numérique indien est fortement imprégné des technologies vocales, des notes vocales à la messagerie multilingue. Transformer ces habitudes largement répandues en une activité d'IA évolutive
Recommandations de sujets spéciaux liés
Productivité
Spotify dévoile un outil de création d'audiobooks basé sur l'IA et développé par ElevenLabs
Dans le cadre de ses dernières annonces, Spotify a présenté un nouvel outil d'IA développé par ElevenLabs qui permet aux auteurs d'auto-publier des livres audio directement via la plateforme Spotify f
Les meilleures applications de dictée par IA : avis d'experts et classements
Les applications de dictée par IA ont fait des progrès remarquables en un laps de temps relativement court. Pendant longtemps, elles étaient lentes et sujettes à des erreurs, obligeant les utilisateur
Wispr Flow mise sur l'avenir de l'IA vocale en Inde malgré les défis
Le paysage numérique indien est fortement imprégné des technologies vocales, des notes vocales à la messagerie multilingue. Transformer ces habitudes largement répandues en une activité d'IA évolutive
Recommandations de sujets spéciaux liés
Productivité
 Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
 10 outils
10 outils
 xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai
Analyse des données
Les meilleurs outils de visualisation de données basés sur l'IA : générez automatiquement des tableaux de bord BI interactifs à partir de fichiers bruts
Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
La société française d'IA Mistral a dévoilé jeudi un nouveau modèle open source de synthèse vocale, conçu pour les assistants vocaux IA et les applications d'entreprise telles que le service client. Ce modèle permet aux entreprises de développer des agents vocaux destinés à la vente et à l'engagement client, positionnant ainsi Mistral comme un concurrent direct d'ElevenLabs, de Deepgram et d'OpenAI.
Baptisé Voxtral TTS, ce modèle prend en charge neuf langues, dont l'anglais, le français, l'allemand, l'espagnol, le néerlandais, le portugais, l'italien, l'hindi et l'arabe.
« Nos clients nous demandaient un modèle de synthèse vocale. Nous avons donc développé un modèle de petite taille pouvant s’intégrer à une montre connectée, un smartphone, un ordinateur portable ou d’autres appareils périphériques. Son coût est bien inférieur à celui de tout autre produit sur le marché, tout en offrant des performances de pointe », a déclaré Pierre Stock, vice-président des opérations scientifiques chez Mistral AI, lors d’un entretien téléphonique avec TechCrunch.
Crédit image : Mistral
Mistral affirme que ce nouveau modèle peut s’adapter à une voix personnalisée à partir d’un échantillon de moins de cinq secondes, en capturant les accents subtils, les inflexions, les intonations et les irrégularités du flux vocal. Basé sur Mistral 3B, il peut passer d’une langue à l’autre en douceur tout en conservant les caractéristiques vocales, ce qui le rend idéal pour le doublage ou la traduction en temps réel. M. Stock a souligné que l’entreprise avait pour objectif de donner au modèle une voix humaine, et non robotique.
Selon l'entreprise, le modèle est conçu pour fonctionner en temps réel. Son temps de réponse audio (TTFA) — le délai entre la réception de l'entrée et le début de la « parole » — est de 90 ms pour un échantillon de 10 secondes comprenant 500 caractères. Le modèle atteint également un facteur temps réel (RTF) de 6x, ce qui signifie qu’il peut générer un clip de 10 secondes en environ 1,6 seconde.
Crédit image : Mistral AI
Plus tôt cette année, Mistral a lancé deux modèles de transcription : l’un pour le traitement par lots à grande échelle, l’autre pour des cas d’utilisation en temps réel à faible latence. Avec ce nouveau modèle vocal, l’entreprise semble en train de développer une suite complète de produits vocaux destinés aux entreprises.
M. Stock a ajouté : « Nous prévoyons de créer une plateforme de bout en bout capable de gérer des flux d'entrée multimodaux — audio, texte et image — ainsi que des sorties. L'avantage principal est qu'un système agentique de bout en bout prenant en charge l'entrée et la sortie audio fournit des informations bien plus riches. »
Mistral met en avant son caractère open source et ses capacités de personnalisation comme principaux facteurs de différenciation, permettant aux entreprises d'adapter le modèle à leurs besoins spécifiques, ce qui le rend plus attractif que les solutions concurrentes.










 Spotify dévoile un outil de création d'audiobooks basé sur l'IA et développé par ElevenLabs
Dans le cadre de ses dernières annonces, Spotify a présenté un nouvel outil d'IA développé par ElevenLabs qui permet aux auteurs d'auto-publier des livres audio directement via la plateforme Spotify f
Spotify dévoile un outil de création d'audiobooks basé sur l'IA et développé par ElevenLabs
Dans le cadre de ses dernières annonces, Spotify a présenté un nouvel outil d'IA développé par ElevenLabs qui permet aux auteurs d'auto-publier des livres audio directement via la plateforme Spotify f
 Les meilleures applications de dictée par IA : avis d'experts et classements
Les applications de dictée par IA ont fait des progrès remarquables en un laps de temps relativement court. Pendant longtemps, elles étaient lentes et sujettes à des erreurs, obligeant les utilisateur
Les meilleures applications de dictée par IA : avis d'experts et classements
Les applications de dictée par IA ont fait des progrès remarquables en un laps de temps relativement court. Pendant longtemps, elles étaient lentes et sujettes à des erreurs, obligeant les utilisateur
 Wispr Flow mise sur l'avenir de l'IA vocale en Inde malgré les défis
Le paysage numérique indien est fortement imprégné des technologies vocales, des notes vocales à la messagerie multilingue. Transformer ces habitudes largement répandues en une activité d'IA évolutive
Wispr Flow mise sur l'avenir de l'IA vocale en Inde malgré les défis
Le paysage numérique indien est fortement imprégné des technologies vocales, des notes vocales à la messagerie multilingue. Transformer ces habitudes largement répandues en une activité d'IA évolutive

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai













