
















 Home
HomeEnterprise AI Costs: Claude Models Priced 20-30% Higher Than GPT in Deployment
It's widely known that different model families may employ different tokenizers. However, there has been limited research into how the actual tokenization process varies between these systems. Do all tokenizers produce the same number of tokens for identical input text? If not, how substantial are these differences? What practical implications do they carry?
This article investigates these questions by examining the real-world consequences of tokenization variability. We present a comparative analysis of two leading model families: OpenAI's ChatGPT versus Anthropic's Claude. While their advertised "cost-per-token" rates appear highly competitive, our testing reveals that Anthropic models can actually be 20-30% more expensive than GPT models in practice.
API Pricing — Claude 3.5 Sonnet vs GPT-4o
As of June 2024, the pricing structures for these two advanced frontier models are closely matched. Both Anthropic's Claude 3.5 Sonnet and OpenAI's GPT-4o maintain identical costs for output tokens, while Claude 3.5 Sonnet provides a 40% discount on input tokens.
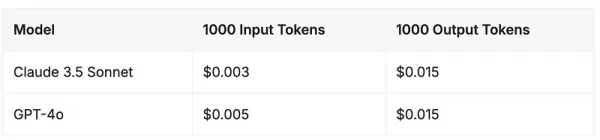
Source: Vantage
The Hidden Tokenization Inefficiency
Despite Anthropic's lower input token rates, our experiments with fixed prompt sets demonstrate that GPT-4o consistently delivers more economical overall costs than Claude Sonnet-3.5.
What explains this discrepancy?
Anthropic's tokenizer typically segments identical input text into more tokens compared to OpenAI's approach. This means that for the same prompts, Anthropic models generate significantly higher token counts than their OpenAI equivalents. Consequently, while Claude 3.5 Sonnet's per-token input cost appears lower, the increased tokenization volume often negates these savings, resulting in higher total expenses for practical implementations.
This hidden cost arises from Anthropic's token encoding methodology, which frequently requires more tokens to represent equivalent content. The inflation in token counts substantially impacts both operational costs and context window efficiency.
Domain-Specific Tokenization Variations
Anthropic's tokenizer processes different content domains with varying efficiency, producing inconsistent token count increases relative to OpenAI's models. The AI research community has documented similar tokenization disparities. We validated our findings across three prominent domains: English articles, Python code, and mathematical content.
Domain Model Input GPT Tokens Claude Tokens % Token Overhead English articles  Additional Practical Implications of Tokenization Differences
Additional Practical Implications of Tokenization DifferencesBeyond direct cost considerations, tokenizer inefficiency indirectly affects context window utilization. While Anthropic models advertise a 200K token context window compared to OpenAI's 128K, the tokenization verbosity may actually reduce the effective usable space in Anthropic models. This creates a potential discrepancy between advertised context window sizes and their practical, effective capacity.
Tokenization Implementation Details
GPT models utilize Byte Pair Encoding (BPE), which combines frequently occurring character pairs to form tokens. The latest GPT models specifically employ the open-source o200k_base tokenizer. The actual tokens used by GPT-4o within the tiktoken tokenizer are publicly accessible.
JSON {#reasoning"o1-xxx": "o200k_base","o3-xxx": "o200k_base",# chat"chatgpt-4o-": "o200k_base","gpt-4o-xxx": "o200k_base",# e.g., gpt-4o-2024-05-13"gpt-4-xxx": "cl100k_base",# e.g., gpt-4-0314, etc., plus gpt-4-32k"gpt-3.5-turbo-xxx": "cl100k_base",# e.g, gpt-3.5-turbo-0301, -0401, etc.}
Unfortunately, Anthropic's tokenization approach remains less transparent, as their tokenizer isn't as readily available as GPT's. Anthropic introduced a Token Counting API in December 2024, but this feature was discontinued in later 2025 versions.
According to Latenode, "Anthropic employs a unique tokenizer with only 65,000 token variations, compared to OpenAI's 100,261 variations for GPT-4." A publicly available Colab notebook contains Python code for analyzing tokenization differences between GPT and Claude models. Another tool that interfaces with common, publicly available tokenizers corroborates our findings.
For AI enterprises, the ability to accurately estimate token counts without invoking actual model APIs is essential for cost forecasting and budgeting.
Essential Insights
- Anthropic's competitive pricing contains hidden expenses:
While Claude 3.5 Sonnet offers 40% lower input token costs than GPT-4o, this apparent advantage can be deceptive due to fundamental differences in text tokenization. - The hidden tokenization inefficiency:
Anthropic models inherently produce more tokens. For organizations processing substantial text volumes, understanding this variation is critical for accurately assessing deployment costs. - Domain-specific tokenization performance:
When selecting between OpenAI and Anthropic models, carefully evaluate your typical input content. While natural language tasks may show minimal cost differences, technical or structured domains could experience significantly higher expenses with Anthropic models. - Effective context window capacity:
Due to Anthropic's tokenization verbosity, its advertised 200K context window might provide less practical usable space than OpenAI's 128K, potentially creating a gap between claimed and actual context capacity.
Anthropic had not responded to VentureBeat's request for comment by publication time. We will update this article if they provide a response.
Related article
 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Related Special Topic Recommendations
writing
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Related Special Topic Recommendations
writing
 Top AI Fiction Profile Creators: Generate Consistent Character Motivations and Fatal Flaws
Top AI Fiction Profile Creators: Generate Consistent Character Motivations and Fatal Flaws
Discover the 2026 best AI fiction profile creators for crafting deep characters. XIX.AI's curated list features top-rated, game-changing tools that generate consistent motivations and fatal flaws. Compare free vs paid options with real-world tests. Unlock your storytelling potential now.
 10 tools
10 tools
 xix.ai
Business
Top AI Pricing Optimization Software: Track Competitors & Auto-Adjust Store Prices
xix.ai
Business
Top AI Pricing Optimization Software: Track Competitors & Auto-Adjust Store Prices
Discover the 2026 best AI pricing optimization software on XIX.AI. Our curated list features top-rated, game-changing tools that track competitors and auto-adjust your store prices for maximum profit. Compare free vs paid options with real-world tests. Unlock your pricing edge now.
10 tools
xix.ai
code
Best AI Code Reviewers: Automate Clean Code Compliance & Refactor Legacy Repo Files
Discover the 2026 best AI code reviewers on XIX.AI. Our curated list features top-rated, game-changing tools for automating clean code compliance and refactoring legacy repo files. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI edge today.
10 tools
xix.ai
Text-to-speech
Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

 Comments (0)
0/500
Comments (0)
0/500
It's widely known that different model families may employ different tokenizers. However, there has been limited research into how the actual tokenization process varies between these systems. Do all tokenizers produce the same number of tokens for identical input text? If not, how substantial are these differences? What practical implications do they carry?
This article investigates these questions by examining the real-world consequences of tokenization variability. We present a comparative analysis of two leading model families: OpenAI's ChatGPT versus Anthropic's Claude. While their advertised "cost-per-token" rates appear highly competitive, our testing reveals that Anthropic models can actually be 20-30% more expensive than GPT models in practice.
API Pricing — Claude 3.5 Sonnet vs GPT-4o
As of June 2024, the pricing structures for these two advanced frontier models are closely matched. Both Anthropic's Claude 3.5 Sonnet and OpenAI's GPT-4o maintain identical costs for output tokens, while Claude 3.5 Sonnet provides a 40% discount on input tokens.
Source: Vantage
The Hidden Tokenization Inefficiency
Despite Anthropic's lower input token rates, our experiments with fixed prompt sets demonstrate that GPT-4o consistently delivers more economical overall costs than Claude Sonnet-3.5.
What explains this discrepancy?
Anthropic's tokenizer typically segments identical input text into more tokens compared to OpenAI's approach. This means that for the same prompts, Anthropic models generate significantly higher token counts than their OpenAI equivalents. Consequently, while Claude 3.5 Sonnet's per-token input cost appears lower, the increased tokenization volume often negates these savings, resulting in higher total expenses for practical implementations.
This hidden cost arises from Anthropic's token encoding methodology, which frequently requires more tokens to represent equivalent content. The inflation in token counts substantially impacts both operational costs and context window efficiency.
Domain-Specific Tokenization Variations
Anthropic's tokenizer processes different content domains with varying efficiency, producing inconsistent token count increases relative to OpenAI's models. The AI research community has documented similar tokenization disparities. We validated our findings across three prominent domains: English articles, Python code, and mathematical content.
| Domain | Model Input | GPT Tokens | Claude Tokens | % Token Overhead |
| English articles | Additional Practical Implications of Tokenization Differences Beyond direct cost considerations, tokenizer inefficiency indirectly affects context window utilization. While Anthropic models advertise a 200K token context window compared to OpenAI's 128K, the tokenization verbosity may actually reduce the effective usable space in Anthropic models. This creates a potential discrepancy between advertised context window sizes and their practical, effective capacity. Tokenization Implementation DetailsGPT models utilize Byte Pair Encoding (BPE), which combines frequently occurring character pairs to form tokens. The latest GPT models specifically employ the open-source o200k_base tokenizer. The actual tokens used by GPT-4o within the tiktoken tokenizer are publicly accessible. Unfortunately, Anthropic's tokenization approach remains less transparent, as their tokenizer isn't as readily available as GPT's. Anthropic introduced a Token Counting API in December 2024, but this feature was discontinued in later 2025 versions. According to Latenode, "Anthropic employs a unique tokenizer with only 65,000 token variations, compared to OpenAI's 100,261 variations for GPT-4." A publicly available Colab notebook contains Python code for analyzing tokenization differences between GPT and Claude models. Another tool that interfaces with common, publicly available tokenizers corroborates our findings. Essential Insights
Anthropic had not responded to VentureBeat's request for comment by publication time. We will update this article if they provide a response. |










 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
 Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont

Discover the 2026 best AI fiction profile creators for crafting deep characters. XIX.AI's curated list features top-rated, game-changing tools that generate consistent motivations and fatal flaws. Compare free vs paid options with real-world tests. Unlock your storytelling potential now.
10 tools
xix.ai

Discover the 2026 best AI pricing optimization software on XIX.AI. Our curated list features top-rated, game-changing tools that track competitors and auto-adjust your store prices for maximum profit. Compare free vs paid options with real-world tests. Unlock your pricing edge now.
10 tools
xix.ai

Discover the 2026 best AI code reviewers on XIX.AI. Our curated list features top-rated, game-changing tools for automating clean code compliance and refactoring legacy repo files. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai













