
















 Lar
Lar
Custos de IA corporativa: Modelos de Claude com preços 20-30% mais altos do que a GPT na implantação
É amplamente conhecido que diferentes famílias de modelos podem empregar diferentes tokenizadores. No entanto, há poucas pesquisas sobre como o processo de tokenização real varia entre esses sistemas. Todos os tokenizadores produzem o mesmo número de tokens para um texto de entrada idêntico? Se não, qual é a importância dessas diferenças? Que implicações práticas elas têm?
Este artigo investiga essas questões examinando as consequências da variabilidade da tokenização no mundo real. Apresentamos uma análise comparativa de duas famílias de modelos líderes: ChatGPT da OpenAI e Claude da Anthropic. Embora as taxas de "custo por token" anunciadas pareçam altamente competitivas, nossos testes revelam que, na prática, os modelos Anthropic podem ser de 20 a 30% mais caros do que os modelos GPT.
Preços de API - Claude 3.5 Sonnet vs GPT-4o
A partir de junho de 2024, as estruturas de preços desses dois modelos avançados de fronteira estão muito próximas. Tanto o Claude 3.5 Sonnet da Anthropic quanto o GPT-4o da OpenAI mantêm custos idênticos para tokens de saída, enquanto o Claude 3.5 Sonnet oferece um desconto de 40% nos tokens de entrada.
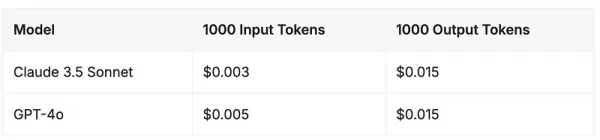
Fonte: Vantage
A ineficiência oculta da tokenização
Apesar das taxas mais baixas de tokens de entrada do Anthropic, nossos experimentos com conjuntos de solicitações fixas demonstram que o GPT-4o fornece consistentemente custos gerais mais econômicos do que o Claude Sonnet-3.5.
O que explica essa discrepância?
O tokenizador da Anthropic normalmente segmenta o texto de entrada idêntico em mais tokens em comparação com a abordagem da OpenAI. Isso significa que, para os mesmos prompts, os modelos Anthropic geram contagens de tokens significativamente mais altas do que seus equivalentes da OpenAI. Consequentemente, embora o custo de entrada por token do Claude 3.5 Sonnet pareça menor, o aumento do volume de tokenização geralmente anula essa economia, resultando em despesas totais mais altas para implementações práticas.
Esse custo oculto decorre da metodologia de codificação de tokens do Anthropic, que frequentemente exige mais tokens para representar conteúdo equivalente. A inflação nas contagens de tokens afeta substancialmente os custos operacionais e a eficiência da janela de contexto.
Variações de tokenização específicas do domínio
O tokenizador da Anthropic processa diferentes domínios de conteúdo com eficiência variável, produzindo aumentos inconsistentes na contagem de tokens em relação aos modelos da OpenAI. A comunidade de pesquisa de IA documentou disparidades de tokenização semelhantes. Validamos nossas descobertas em três domínios importantes: Artigos em inglês, código Python e conteúdo matemático.
Domínio Modelo de entrada Tokens GPT Tokens Claude % Sobrecarga de token Artigos em inglês  Implicações práticas adicionais das diferenças de tokenização
Implicações práticas adicionais das diferenças de tokenizaçãoAlém das considerações de custo direto, a ineficiência do tokenizador afeta indiretamente a utilização da janela de contexto. Embora os modelos Anthropic anunciem uma janela de contexto de 200 mil tokens em comparação com os 128 mil da OpenAI, a verbosidade da tokenização pode, na verdade, reduzir o espaço utilizável efetivo nos modelos Anthropic. Isso cria uma possível discrepância entre os tamanhos de janela de contexto anunciados e sua capacidade prática e efetiva.
Detalhes da implementação da tokenização
Os modelos GPT utilizam Byte Pair Encoding (BPE), que combina pares de caracteres que ocorrem com frequência para formar tokens. Os modelos GPT mais recentes empregam especificamente o tokenizador de código aberto o200k_base. Os tokens reais usados pelo GPT-4o no tokenizador tiktoken podem ser acessados publicamente.
JSON {#reasoning "o1-xxx": "o200k_base","o3-xxx": "o200k_base",# chat"chatgpt-4o-": "o200k_base","gpt-4o-xxx": "o200k_base",# por exemplo, gpt-4o-2024-05-13 "gpt-4-xxx": "cl100k_base",# por exemplo, gpt-4-0314, etc., além de gpt-4-32k "gpt-3.5-turbo-xxx": "cl100k_base",# por exemplo, gpt-3.5-turbo-0301, -0401, etc.}
Infelizmente, a abordagem de tokenização do Anthropic permanece menos transparente, pois seu tokenizador não está tão prontamente disponível quanto o do GPT. O Anthropic introduziu uma API de contagem de tokens em dezembro de 2024, mas esse recurso foi descontinuado em versões posteriores de 2025.
De acordo com a Latenode, "o Anthropic emprega um tokenizador exclusivo com apenas 65.000 variações de token, em comparação com as 100.261 variações do OpenAI para GPT-4". Um notebook Colab disponível publicamente contém código Python para analisar as diferenças de tokenização entre os modelos GPT e Claude. Outra ferramenta que faz interface com tokenizadores comuns e publicamente disponíveis corrobora nossas descobertas.
Para as empresas de IA, a capacidade de estimar com precisão as contagens de tokens sem invocar APIs de modelos reais é essencial para a previsão de custos e o orçamento.
Insights essenciais
- O preço competitivo do Anthropic contém despesas ocultas:
Embora o Claude 3.5 Sonnet ofereça custos de token de entrada 40% menores do que o GPT-4o, essa vantagem aparente pode ser enganosa devido a diferenças fundamentais na tokenização de texto. - A ineficiência oculta da tokenização:
Os modelos antrópicos produzem inerentemente mais tokens. Para as organizações que processam volumes substanciais de texto, compreender essa variação é fundamental para avaliar com precisão os custos de implementação. - Desempenho de tokenização específico do domínio:
Ao escolher entre os modelos OpenAI e Anthropic, avalie cuidadosamente seu conteúdo de entrada típico. Embora as tarefas de linguagem natural possam apresentar diferenças mínimas de custo, os domínios técnicos ou estruturados podem ter despesas significativamente maiores com os modelos Anthropic. - Capacidade efetiva da janela de contexto:
Devido à verbosidade de tokenização do Anthropic, sua janela de contexto de 200K anunciada pode fornecer menos espaço prático utilizável do que os 128K do OpenAI, criando potencialmente uma lacuna entre a capacidade de contexto reivindicada e a real.
A Anthropic não havia respondido ao pedido de comentário da VentureBeat até o momento da publicação. Atualizaremos este artigo se eles fornecerem uma resposta.
Artigo relacionado
 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Recomendações de tópicos especiais relacionados
Negócios
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Recomendações de tópicos especiais relacionados
Negócios
 O melhor software de revisão de contratos com IA: identifique lacunas jurídicas e riscos de conformidade instantaneamente
O melhor software de revisão de contratos com IA: identifique lacunas jurídicas e riscos de conformidade instantaneamente
Descubra os melhores softwares de análise de contratos com IA de 2026 no XIX.AI. Nossa lista, cuidadosamente selecionada e com as melhores avaliações, apresenta ferramentas poderosas que identificam instantaneamente lacunas jurídicas e riscos de conformidade. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre a solução revolucionária para uma análise segura e eficiente de contratos. Explore agora o guia definitivo.
 10 ferramentas
10 ferramentas
 xix.ai
Criação de Animação
Gerador de Animações AI para Donghua: Crie Personagens para Romances Online e Avatares para Quadrinhos
xix.ai
Criação de Animação
Gerador de Animações AI para Donghua: Crie Personagens para Romances Online e Avatares para Quadrinhos
Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Criação de quadrinhos
As melhores ferramentas de colorização automática com IA para mangás: aplique cores planas sem erros de consistência
Descubra as melhores ferramentas de colorização automática por IA para mangás de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções de ponta e revolucionárias que aplicam cores planas sem nenhum erro de consistência, aumentando sua produtividade. Explore comparações entre versões gratuitas e pagas, testes práticos e rankings atualizados semanalmente para encontrar a opção ideal para você. Aproveite hoje mesmo as vantagens da IA.
10 ferramentas
xix.ai
escrita
Os melhores criadores de perfis de ficção com IA: gerar motivações consistentes para personagens e falhas fatais
Descubra os melhores criadores de perfis de ficção com IA de 2026 para criar personagens complexos. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias que geram motivações consistentes e falhas fatais. Compare as opções gratuitas com as pagas por meio de testes práticos. Liberte agora o seu potencial narrativo.
10 ferramentas
xix.ai
Negócios
Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai
código
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai

 Comentários (0)
Comentários (0)
É amplamente conhecido que diferentes famílias de modelos podem empregar diferentes tokenizadores. No entanto, há poucas pesquisas sobre como o processo de tokenização real varia entre esses sistemas. Todos os tokenizadores produzem o mesmo número de tokens para um texto de entrada idêntico? Se não, qual é a importância dessas diferenças? Que implicações práticas elas têm?
Este artigo investiga essas questões examinando as consequências da variabilidade da tokenização no mundo real. Apresentamos uma análise comparativa de duas famílias de modelos líderes: ChatGPT da OpenAI e Claude da Anthropic. Embora as taxas de "custo por token" anunciadas pareçam altamente competitivas, nossos testes revelam que, na prática, os modelos Anthropic podem ser de 20 a 30% mais caros do que os modelos GPT.
Preços de API - Claude 3.5 Sonnet vs GPT-4o
A partir de junho de 2024, as estruturas de preços desses dois modelos avançados de fronteira estão muito próximas. Tanto o Claude 3.5 Sonnet da Anthropic quanto o GPT-4o da OpenAI mantêm custos idênticos para tokens de saída, enquanto o Claude 3.5 Sonnet oferece um desconto de 40% nos tokens de entrada.
Fonte: Vantage
A ineficiência oculta da tokenização
Apesar das taxas mais baixas de tokens de entrada do Anthropic, nossos experimentos com conjuntos de solicitações fixas demonstram que o GPT-4o fornece consistentemente custos gerais mais econômicos do que o Claude Sonnet-3.5.
O que explica essa discrepância?
O tokenizador da Anthropic normalmente segmenta o texto de entrada idêntico em mais tokens em comparação com a abordagem da OpenAI. Isso significa que, para os mesmos prompts, os modelos Anthropic geram contagens de tokens significativamente mais altas do que seus equivalentes da OpenAI. Consequentemente, embora o custo de entrada por token do Claude 3.5 Sonnet pareça menor, o aumento do volume de tokenização geralmente anula essa economia, resultando em despesas totais mais altas para implementações práticas.
Esse custo oculto decorre da metodologia de codificação de tokens do Anthropic, que frequentemente exige mais tokens para representar conteúdo equivalente. A inflação nas contagens de tokens afeta substancialmente os custos operacionais e a eficiência da janela de contexto.
Variações de tokenização específicas do domínio
O tokenizador da Anthropic processa diferentes domínios de conteúdo com eficiência variável, produzindo aumentos inconsistentes na contagem de tokens em relação aos modelos da OpenAI. A comunidade de pesquisa de IA documentou disparidades de tokenização semelhantes. Validamos nossas descobertas em três domínios importantes: Artigos em inglês, código Python e conteúdo matemático.
| Domínio | Modelo de entrada | Tokens GPT | Tokens Claude | % Sobrecarga de token |
| Artigos em inglês | Implicações práticas adicionais das diferenças de tokenização Além das considerações de custo direto, a ineficiência do tokenizador afeta indiretamente a utilização da janela de contexto. Embora os modelos Anthropic anunciem uma janela de contexto de 200 mil tokens em comparação com os 128 mil da OpenAI, a verbosidade da tokenização pode, na verdade, reduzir o espaço utilizável efetivo nos modelos Anthropic. Isso cria uma possível discrepância entre os tamanhos de janela de contexto anunciados e sua capacidade prática e efetiva. Detalhes da implementação da tokenizaçãoOs modelos GPT utilizam Byte Pair Encoding (BPE), que combina pares de caracteres que ocorrem com frequência para formar tokens. Os modelos GPT mais recentes empregam especificamente o tokenizador de código aberto o200k_base. Os tokens reais usados pelo GPT-4o no tokenizador tiktoken podem ser acessados publicamente. Infelizmente, a abordagem de tokenização do Anthropic permanece menos transparente, pois seu tokenizador não está tão prontamente disponível quanto o do GPT. O Anthropic introduziu uma API de contagem de tokens em dezembro de 2024, mas esse recurso foi descontinuado em versões posteriores de 2025. De acordo com a Latenode, "o Anthropic emprega um tokenizador exclusivo com apenas 65.000 variações de token, em comparação com as 100.261 variações do OpenAI para GPT-4". Um notebook Colab disponível publicamente contém código Python para analisar as diferenças de tokenização entre os modelos GPT e Claude. Outra ferramenta que faz interface com tokenizadores comuns e publicamente disponíveis corrobora nossas descobertas. Insights essenciais
A Anthropic não havia respondido ao pedido de comentário da VentureBeat até o momento da publicação. Atualizaremos este artigo se eles fornecerem uma resposta. |










 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
 A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
 Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c

Descubra os melhores softwares de análise de contratos com IA de 2026 no XIX.AI. Nossa lista, cuidadosamente selecionada e com as melhores avaliações, apresenta ferramentas poderosas que identificam instantaneamente lacunas jurídicas e riscos de conformidade. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre a solução revolucionária para uma análise segura e eficiente de contratos. Explore agora o guia definitivo.
10 ferramentas
xix.ai

Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de colorização automática por IA para mangás de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções de ponta e revolucionárias que aplicam cores planas sem nenhum erro de consistência, aumentando sua produtividade. Explore comparações entre versões gratuitas e pagas, testes práticos e rankings atualizados semanalmente para encontrar a opção ideal para você. Aproveite hoje mesmo as vantagens da IA.
10 ferramentas
xix.ai

Descubra os melhores criadores de perfis de ficção com IA de 2026 para criar personagens complexos. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias que geram motivações consistentes e falhas fatais. Compare as opções gratuitas com as pagas por meio de testes práticos. Liberte agora o seu potencial narrativo.
10 ferramentas
xix.ai

Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai

Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai













