
















 Heim
Heim
KI-Kosten für Unternehmen: Claude-Modelle kosten 20-30% mehr als GPT bei der Bereitstellung
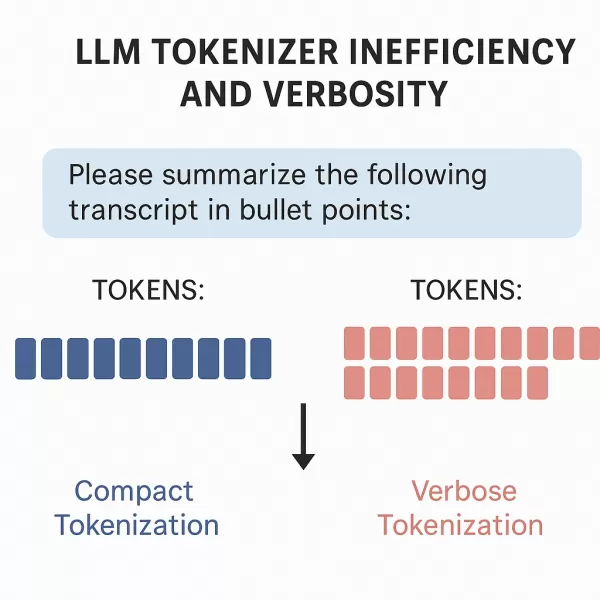
Es ist allgemein bekannt, dass verschiedene Modellfamilien unterschiedliche Tokenizer verwenden können. Es gibt jedoch nur wenige Untersuchungen darüber, wie sich der eigentliche Tokenisierungsprozess zwischen diesen Systemen unterscheidet. Erzeugen alle Tokenizer die gleiche Anzahl von Token für identischen Eingabetext? Wenn nicht, wie groß sind diese Unterschiede? Welche praktischen Auswirkungen haben sie?
Dieser Artikel geht diesen Fragen nach, indem er die Auswirkungen der Tokenisierungsvariabilität in der Praxis untersucht. Wir präsentieren eine vergleichende Analyse von zwei führenden Modellfamilien: ChatGPT von OpenAI und Claude von Anthropic. Während ihre beworbenen "Kosten pro Token"-Raten sehr wettbewerbsfähig erscheinen, zeigen unsere Tests, dass Anthropic-Modelle in der Praxis 20-30% teurer sein können als GPT-Modelle.
API-Preise - Claude 3.5 Sonnet gegenüber GPT-4o
Ab Juni 2024 sind die Preisstrukturen für diese beiden fortschrittlichen Grenzmodelle eng miteinander verbunden. Sowohl Claude 3.5 Sonnet von Anthropic als auch GPT-4o von OpenAI haben identische Kosten für Output-Tokens, während Claude 3.5 Sonnet einen Rabatt von 40 % auf Input-Tokens bietet.
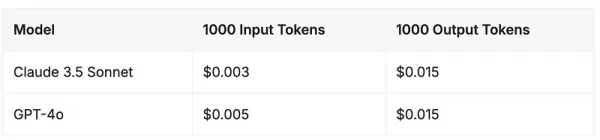
Quelle: Vantage
Die versteckte Tokenisierungsineffizienz
Trotz der niedrigeren Eingabe-Token-Raten von Anthropic zeigen unsere Experimente mit festen Prompt-Sets, dass GPT-4o durchweg wirtschaftlichere Gesamtkosten als Claude Sonnet-3.5 liefert.
Was erklärt diese Diskrepanz?
Der Tokenizer von Anthropic segmentiert identischen Eingabetext typischerweise in mehr Token als der Ansatz von OpenAI. Das bedeutet, dass die Anthropic-Modelle für dieselben Prompts deutlich mehr Token generieren als ihre OpenAI-Entsprechungen. Obwohl die Kosten pro Token in Claude 3.5 Sonnet geringer erscheinen, werden diese Einsparungen durch das höhere Tokenisierungsvolumen oft wieder aufgehoben, was zu höheren Gesamtkosten für praktische Implementierungen führt.
Diese versteckten Kosten ergeben sich aus der Token-Kodierungsmethode von Anthropic, die häufig mehr Token erfordert, um gleichwertige Inhalte darzustellen. Die Inflation der Tokenanzahl wirkt sich sowohl auf die Betriebskosten als auch auf die Effizienz des Kontextfensters aus.
Domänenspezifische Tokenisierungsvariationen
Der Tokenizer von Anthropic verarbeitet verschiedene Inhaltsdomänen mit unterschiedlicher Effizienz, was zu einer uneinheitlichen Erhöhung der Tokenzahl im Vergleich zu den Modellen von OpenAI führt. Die KI-Forschungsgemeinschaft hat ähnliche Ungleichheiten bei der Tokenisierung dokumentiert. Wir haben unsere Ergebnisse in drei prominenten Domänen validiert: Englische Artikel, Python-Code und mathematische Inhalte.
Bereich Modell Eingabe GPT-Tokens Claude Token % Token-Overhead Englische Artikel  Zusätzliche praktische Auswirkungen der Tokenisierungsunterschiede
Zusätzliche praktische Auswirkungen der TokenisierungsunterschiedeAbgesehen von direkten Kostenüberlegungen wirkt sich die Ineffizienz des Tokenizers indirekt auf die Nutzung des Kontextfensters aus. Während Anthropic-Modelle mit einem Kontextfenster von 200K Token im Vergleich zu OpenAIs 128K werben, kann die Ausführlichkeit der Tokenisierung den effektiv nutzbaren Platz in Anthropic-Modellen tatsächlich reduzieren. Dies führt zu einer potenziellen Diskrepanz zwischen den angekündigten Kontextfenstergrößen und ihrer praktischen, effektiven Kapazität.
Details der Tokenisierung-Implementierung
GPT-Modelle verwenden Byte Pair Encoding (BPE), das häufig vorkommende Zeichenpaare zu Token kombiniert. Die neuesten GPT-Modelle verwenden insbesondere den Open-Source-Tokenizer o200k_base. Die eigentlichen Token, die von GPT-4o innerhalb des tiktoken Tokenizers verwendet werden, sind öffentlich zugänglich.
JSON {#reasoning "o1-xxx": "o200k_base","o3-xxx": "o200k_base",# chat"chatgpt-4o-": "o200k_base","gpt-4o-xxx": "o200k_base",# z.B., gpt-4o-2024-05-13 "gpt-4-xxx": "cl100k_base",# z. B. gpt-4-0314, usw., plus gpt-4-32k "gpt-3.5-turbo-xxx": "cl100k_base",# z.B. gpt-3.5-turbo-0301, -0401, usw.}
Leider ist der Tokenisierungsansatz von Anthropic weniger transparent, da ihr Tokenizer nicht so leicht verfügbar ist wie der von GPT. Anthropic führte im Dezember 2024 eine Token-Counting-API ein, aber diese Funktion wurde in späteren Versionen 2025 wieder eingestellt.
Laut Latenode "verwendet Anthropic einen einzigartigen Tokenizer mit nur 65.000 Token-Variationen, verglichen mit den 100.261 Variationen von OpenAI für GPT-4". Ein öffentlich zugängliches Colab-Notebook enthält Python-Code zur Analyse der Tokenisierungsunterschiede zwischen GPT und Claude-Modellen. Ein weiteres Tool, das Schnittstellen zu gängigen, öffentlich verfügbaren Tokenizern bietet, bestätigt unsere Ergebnisse.
Für KI-Unternehmen ist die Möglichkeit, die Anzahl der Token genau zu schätzen, ohne die eigentlichen Modell-APIs aufzurufen, für die Kostenprognose und Budgetierung von entscheidender Bedeutung.
Wesentliche Einblicke
- Die wettbewerbsfähige Preisgestaltung von Anthropic enthält versteckte Kosten:
Während Claude 3.5 Sonnet 40 % niedrigere Input-Token-Kosten als GPT-4o bietet, kann dieser scheinbare Vorteil aufgrund grundlegender Unterschiede bei der Text-Tokenisierung trügerisch sein. - Die versteckte Ineffizienz der Tokenisierung:
Anthropische Modelle erzeugen von Natur aus mehr Token. Für Unternehmen, die große Textmengen verarbeiten, ist es entscheidend, diese Unterschiede zu verstehen, um die Kosten für die Bereitstellung richtig einschätzen zu können. - Domänenspezifische Tokenisierungsleistung:
Bei der Auswahl zwischen OpenAI- und Anthropic-Modellen sollten Sie Ihre typischen Eingabeinhalte sorgfältig bewerten. Während bei natürlichsprachlichen Aufgaben nur minimale Kostenunterschiede auftreten können, könnten bei technischen oder strukturierten Domänen die Kosten für Anthropic-Modelle deutlich höher sein. - Kapazität des effektiven Kontextfensters:
Aufgrund der ausführlichen Tokenisierung von Anthropic könnte das beworbene Kontextfenster von 200K weniger praktisch nutzbaren Platz bieten als das von OpenAI mit 128K, wodurch eine Lücke zwischen der behaupteten und der tatsächlichen Kontextkapazität entstehen könnte.
Anthropic hatte bis zum Redaktionsschluss nicht auf die Anfrage von VentureBeat reagiert. Wir werden diesen Artikel aktualisieren, wenn sie eine Antwort geben.
Verwandter Artikel
 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
 Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
 10 Tools
10 Tools
 xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai
Geschäft
Die beste Software zur Preisoptimierung mittels KI: Beobachten Sie die Konkurrenz und passen Sie Ihre Shop-Preise automatisch an
Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai
Code
Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai
Text-zu-Sprache
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Es ist allgemein bekannt, dass verschiedene Modellfamilien unterschiedliche Tokenizer verwenden können. Es gibt jedoch nur wenige Untersuchungen darüber, wie sich der eigentliche Tokenisierungsprozess zwischen diesen Systemen unterscheidet. Erzeugen alle Tokenizer die gleiche Anzahl von Token für identischen Eingabetext? Wenn nicht, wie groß sind diese Unterschiede? Welche praktischen Auswirkungen haben sie?
Dieser Artikel geht diesen Fragen nach, indem er die Auswirkungen der Tokenisierungsvariabilität in der Praxis untersucht. Wir präsentieren eine vergleichende Analyse von zwei führenden Modellfamilien: ChatGPT von OpenAI und Claude von Anthropic. Während ihre beworbenen "Kosten pro Token"-Raten sehr wettbewerbsfähig erscheinen, zeigen unsere Tests, dass Anthropic-Modelle in der Praxis 20-30% teurer sein können als GPT-Modelle.
API-Preise - Claude 3.5 Sonnet gegenüber GPT-4o
Ab Juni 2024 sind die Preisstrukturen für diese beiden fortschrittlichen Grenzmodelle eng miteinander verbunden. Sowohl Claude 3.5 Sonnet von Anthropic als auch GPT-4o von OpenAI haben identische Kosten für Output-Tokens, während Claude 3.5 Sonnet einen Rabatt von 40 % auf Input-Tokens bietet.
Quelle: Vantage
Die versteckte Tokenisierungsineffizienz
Trotz der niedrigeren Eingabe-Token-Raten von Anthropic zeigen unsere Experimente mit festen Prompt-Sets, dass GPT-4o durchweg wirtschaftlichere Gesamtkosten als Claude Sonnet-3.5 liefert.
Was erklärt diese Diskrepanz?
Der Tokenizer von Anthropic segmentiert identischen Eingabetext typischerweise in mehr Token als der Ansatz von OpenAI. Das bedeutet, dass die Anthropic-Modelle für dieselben Prompts deutlich mehr Token generieren als ihre OpenAI-Entsprechungen. Obwohl die Kosten pro Token in Claude 3.5 Sonnet geringer erscheinen, werden diese Einsparungen durch das höhere Tokenisierungsvolumen oft wieder aufgehoben, was zu höheren Gesamtkosten für praktische Implementierungen führt.
Diese versteckten Kosten ergeben sich aus der Token-Kodierungsmethode von Anthropic, die häufig mehr Token erfordert, um gleichwertige Inhalte darzustellen. Die Inflation der Tokenanzahl wirkt sich sowohl auf die Betriebskosten als auch auf die Effizienz des Kontextfensters aus.
Domänenspezifische Tokenisierungsvariationen
Der Tokenizer von Anthropic verarbeitet verschiedene Inhaltsdomänen mit unterschiedlicher Effizienz, was zu einer uneinheitlichen Erhöhung der Tokenzahl im Vergleich zu den Modellen von OpenAI führt. Die KI-Forschungsgemeinschaft hat ähnliche Ungleichheiten bei der Tokenisierung dokumentiert. Wir haben unsere Ergebnisse in drei prominenten Domänen validiert: Englische Artikel, Python-Code und mathematische Inhalte.
| Bereich | Modell Eingabe | GPT-Tokens | Claude Token | % Token-Overhead |
| Englische Artikel | Zusätzliche praktische Auswirkungen der Tokenisierungsunterschiede Abgesehen von direkten Kostenüberlegungen wirkt sich die Ineffizienz des Tokenizers indirekt auf die Nutzung des Kontextfensters aus. Während Anthropic-Modelle mit einem Kontextfenster von 200K Token im Vergleich zu OpenAIs 128K werben, kann die Ausführlichkeit der Tokenisierung den effektiv nutzbaren Platz in Anthropic-Modellen tatsächlich reduzieren. Dies führt zu einer potenziellen Diskrepanz zwischen den angekündigten Kontextfenstergrößen und ihrer praktischen, effektiven Kapazität. Details der Tokenisierung-ImplementierungGPT-Modelle verwenden Byte Pair Encoding (BPE), das häufig vorkommende Zeichenpaare zu Token kombiniert. Die neuesten GPT-Modelle verwenden insbesondere den Open-Source-Tokenizer o200k_base. Die eigentlichen Token, die von GPT-4o innerhalb des tiktoken Tokenizers verwendet werden, sind öffentlich zugänglich. Leider ist der Tokenisierungsansatz von Anthropic weniger transparent, da ihr Tokenizer nicht so leicht verfügbar ist wie der von GPT. Anthropic führte im Dezember 2024 eine Token-Counting-API ein, aber diese Funktion wurde in späteren Versionen 2025 wieder eingestellt. Laut Latenode "verwendet Anthropic einen einzigartigen Tokenizer mit nur 65.000 Token-Variationen, verglichen mit den 100.261 Variationen von OpenAI für GPT-4". Ein öffentlich zugängliches Colab-Notebook enthält Python-Code zur Analyse der Tokenisierungsunterschiede zwischen GPT und Claude-Modellen. Ein weiteres Tool, das Schnittstellen zu gängigen, öffentlich verfügbaren Tokenizern bietet, bestätigt unsere Ergebnisse. Wesentliche Einblicke
Anthropic hatte bis zum Redaktionsschluss nicht auf die Anfrage von VentureBeat reagiert. Wir werden diesen Artikel aktualisieren, wenn sie eine Antwort geben. |










 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
 Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um

Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai













