
















 Maison
Maison
Coûts de l'IA pour les entreprises : Le prix des modèles Claude est de 20 à 30 % plus élevé que celui des modèles GPT en termes de déploiement
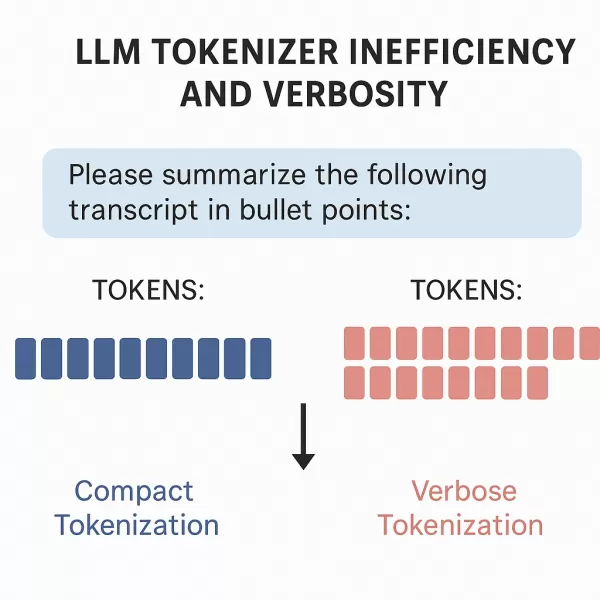
Il est bien connu que les différentes familles de modèles peuvent utiliser différents outils de symbolisation. Cependant, peu de recherches ont été menées sur la manière dont le processus de tokénisation varie entre ces systèmes. Tous les tokenizers produisent-ils le même nombre de tokens pour un texte d'entrée identique ? Si ce n'est pas le cas, quelle est l'importance de ces différences ? Quelles sont les implications pratiques de ces différences ?
Cet article répond à ces questions en examinant les conséquences réelles de la variabilité de la tokenisation. Nous présentons une analyse comparative de deux grandes familles de modèles : ChatGPT d'OpenAI et Claude d'Anthropic. Alors que leurs taux de "coût par jeton" annoncés semblent très compétitifs, nos tests révèlent que les modèles d'Anthropic peuvent en fait être 20 à 30 % plus chers que les modèles GPT dans la pratique.
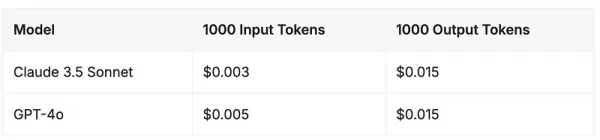
Prix de l'API - Claude 3.5 Sonnet vs GPT-4o
À partir de juin 2024, les structures de prix de ces deux modèles de frontière avancée sont très proches l'une de l'autre. Le Claude 3.5 Sonnet d'Anthropic et le GPT-4o d'OpenAI maintiennent des coûts identiques pour les jetons de sortie, tandis que le Claude 3.5 Sonnet offre une réduction de 40 % sur les jetons d'entrée.
Source : Vantage
L'inefficacité cachée de la tokenisation
Malgré les taux de jetons d'entrée inférieurs d'Anthropic, nos expériences avec des ensembles d'invites fixes démontrent que GPT-4o fournit systématiquement des coûts globaux plus économiques que Claude Sonnet-3.5.
Comment expliquer cet écart ?
Le tokenizer d'Anthropic segmente typiquement un texte d'entrée identique en plus de tokens que l'approche d'OpenAI. Cela signifie que pour les mêmes invites, les modèles Anthropic génèrent des nombres de jetons significativement plus élevés que leurs équivalents OpenAI. Par conséquent, bien que le coût d'entrée par jeton de Claude 3.5 Sonnet semble inférieur, l'augmentation du volume de tokénisation annule souvent ces économies, ce qui se traduit par des dépenses totales plus élevées pour les implémentations pratiques.
Ce coût caché provient de la méthodologie d'encodage des jetons d'Anthropic, qui nécessite souvent plus de jetons pour représenter un contenu équivalent. L'inflation du nombre de jetons a un impact considérable sur les coûts opérationnels et sur l'efficacité des fenêtres contextuelles.
Variations de tokenisation spécifiques à un domaine
Le tokenizer d'Anthropic traite différents domaines de contenu avec une efficacité variable, produisant des augmentations incohérentes du nombre de jetons par rapport aux modèles d'OpenAI. La communauté des chercheurs en IA a documenté des disparités de tokenisation similaires. Nous avons validé nos résultats dans trois domaines importants : Articles en anglais, code Python et contenu mathématique.
Domaine Modèle Entrée Jetons GPT Tokens Claude % de surcharge de tokens Articles en anglais  Autres implications pratiques des différences de tokenisation
Autres implications pratiques des différences de tokenisationAu-delà des considérations de coût direct, l'inefficacité du tokenizer affecte indirectement l'utilisation de la fenêtre de contexte. Alors que les modèles Anthropic annoncent une fenêtre de contexte de 200K tokens contre 128K pour OpenAI, la verbosité de la tokenisation peut en fait réduire l'espace utilisable effectif dans les modèles Anthropic. Cela crée un écart potentiel entre les tailles de fenêtre de contexte annoncées et leur capacité pratique et effective.
Détails de la mise en œuvre de la tokenisation
Les modèles GPT utilisent le codage par paires d'octets (BPE), qui combine des paires de caractères fréquentes pour former des jetons. Les derniers modèles GPT utilisent spécifiquement le tokenizer open-source o200k_base. Les jetons utilisés par GPT-4o dans le tokenizer tiktoken sont accessibles au public.
JSON {#reasoning "o1-xxx" : "o200k_base","o3-xxx": "o200k_base",# chat"chatgpt-4o-": "o200k_base","gpt-4o-xxx": "o200k_base",# par exemple, gpt-4o-2024-05-13 "gpt-4-xxx" : "cl100k_base",# par exemple, gpt-4-0314, etc., plus gpt-4-32k "gpt-3.5-turbo-xxx" : "cl100k_base",# par exemple gpt-3.5-turbo-0301, -0401, etc.}
Malheureusement, l'approche de tokenisation d'Anthropic reste moins transparente, car son tokenizer n'est pas aussi facilement disponible que celui de GPT. Anthropic a introduit une API de comptage de jetons en décembre 2024, mais cette fonctionnalité a été abandonnée dans les versions 2025 ultérieures.
Selon Latenode, "Anthropic utilise un tokenizer unique avec seulement 65 000 variations de token, comparé aux 100 261 variations d'OpenAI pour GPT-4." Un cahier Colab accessible au public contient un code Python permettant d'analyser les différences de symbolisation entre les modèles GPT et Claude. Un autre outil qui s'interface avec des tokenizers communs et accessibles au public corrobore nos résultats.
Pour les entreprises d'IA, la possibilité d'estimer avec précision le nombre de jetons sans invoquer les API des modèles réels est essentielle pour la prévision des coûts et l'établissement du budget.
Des informations essentielles
- Les prix compétitifs d'Anthropic contiennent des dépenses cachées :
Alors que Claude 3.5 Sonnet offre des coûts de jetons d'entrée inférieurs de 40 % à ceux de GPT-4o, cet avantage apparent peut être trompeur en raison de différences fondamentales dans la tokenisation du texte. - L'inefficacité cachée de la tokenisation :
Les modèles anthropiques produisent intrinsèquement plus de jetons. Pour les organisations qui traitent des volumes de texte importants, il est essentiel de comprendre cette variation pour évaluer avec précision les coûts de déploiement. - La performance de la tokenisation spécifique à un domaine :
Lorsque vous choisissez entre les modèles OpenAI et Anthropic, évaluez soigneusement votre contenu d'entrée typique. Alors que les tâches en langage naturel peuvent présenter des différences de coûts minimes, les domaines techniques ou structurés pourraient connaître des dépenses significativement plus élevées avec les modèles Anthropic. - Capacité effective de la fenêtre contextuelle :
En raison de la verbosité de la tokenisation d'Anthropic, sa fenêtre de contexte annoncée de 200K pourrait fournir moins d'espace pratique utilisable que les 128K d'OpenAI, créant potentiellement un écart entre la capacité de contexte annoncée et la capacité réelle.
Anthropic n'avait pas répondu à la demande de commentaire de VentureBeat à l'heure de la publication. Nous mettrons à jour cet article en cas de réponse.
Article connexe
 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Recommandations de sujets spéciaux liés
Entreprise
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Recommandations de sujets spéciaux liés
Entreprise
 Le meilleur logiciel d'analyse de contrats basé sur l'IA : identifiez instantanément les failles juridiques et les risques de non-conformité
Le meilleur logiciel d'analyse de contrats basé sur l'IA : identifiez instantanément les failles juridiques et les risques de non-conformité
Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
 10 outils
10 outils
 xix.ai
Création d'animations
Generateur d'animation AI pour Donghua : Créer des personnages de romans web et des avatars de bandes dessinées
xix.ai
Création d'animations
Generateur d'animation AI pour Donghua : Créer des personnages de romans web et des avatars de bandes dessinées
Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Il est bien connu que les différentes familles de modèles peuvent utiliser différents outils de symbolisation. Cependant, peu de recherches ont été menées sur la manière dont le processus de tokénisation varie entre ces systèmes. Tous les tokenizers produisent-ils le même nombre de tokens pour un texte d'entrée identique ? Si ce n'est pas le cas, quelle est l'importance de ces différences ? Quelles sont les implications pratiques de ces différences ?
Cet article répond à ces questions en examinant les conséquences réelles de la variabilité de la tokenisation. Nous présentons une analyse comparative de deux grandes familles de modèles : ChatGPT d'OpenAI et Claude d'Anthropic. Alors que leurs taux de "coût par jeton" annoncés semblent très compétitifs, nos tests révèlent que les modèles d'Anthropic peuvent en fait être 20 à 30 % plus chers que les modèles GPT dans la pratique.
Prix de l'API - Claude 3.5 Sonnet vs GPT-4o
À partir de juin 2024, les structures de prix de ces deux modèles de frontière avancée sont très proches l'une de l'autre. Le Claude 3.5 Sonnet d'Anthropic et le GPT-4o d'OpenAI maintiennent des coûts identiques pour les jetons de sortie, tandis que le Claude 3.5 Sonnet offre une réduction de 40 % sur les jetons d'entrée.
Source : Vantage
L'inefficacité cachée de la tokenisation
Malgré les taux de jetons d'entrée inférieurs d'Anthropic, nos expériences avec des ensembles d'invites fixes démontrent que GPT-4o fournit systématiquement des coûts globaux plus économiques que Claude Sonnet-3.5.
Comment expliquer cet écart ?
Le tokenizer d'Anthropic segmente typiquement un texte d'entrée identique en plus de tokens que l'approche d'OpenAI. Cela signifie que pour les mêmes invites, les modèles Anthropic génèrent des nombres de jetons significativement plus élevés que leurs équivalents OpenAI. Par conséquent, bien que le coût d'entrée par jeton de Claude 3.5 Sonnet semble inférieur, l'augmentation du volume de tokénisation annule souvent ces économies, ce qui se traduit par des dépenses totales plus élevées pour les implémentations pratiques.
Ce coût caché provient de la méthodologie d'encodage des jetons d'Anthropic, qui nécessite souvent plus de jetons pour représenter un contenu équivalent. L'inflation du nombre de jetons a un impact considérable sur les coûts opérationnels et sur l'efficacité des fenêtres contextuelles.
Variations de tokenisation spécifiques à un domaine
Le tokenizer d'Anthropic traite différents domaines de contenu avec une efficacité variable, produisant des augmentations incohérentes du nombre de jetons par rapport aux modèles d'OpenAI. La communauté des chercheurs en IA a documenté des disparités de tokenisation similaires. Nous avons validé nos résultats dans trois domaines importants : Articles en anglais, code Python et contenu mathématique.
| Domaine | Modèle Entrée | Jetons GPT | Tokens Claude | % de surcharge de tokens |
| Articles en anglais | Autres implications pratiques des différences de tokenisation Au-delà des considérations de coût direct, l'inefficacité du tokenizer affecte indirectement l'utilisation de la fenêtre de contexte. Alors que les modèles Anthropic annoncent une fenêtre de contexte de 200K tokens contre 128K pour OpenAI, la verbosité de la tokenisation peut en fait réduire l'espace utilisable effectif dans les modèles Anthropic. Cela crée un écart potentiel entre les tailles de fenêtre de contexte annoncées et leur capacité pratique et effective. Détails de la mise en œuvre de la tokenisationLes modèles GPT utilisent le codage par paires d'octets (BPE), qui combine des paires de caractères fréquentes pour former des jetons. Les derniers modèles GPT utilisent spécifiquement le tokenizer open-source o200k_base. Les jetons utilisés par GPT-4o dans le tokenizer tiktoken sont accessibles au public. Malheureusement, l'approche de tokenisation d'Anthropic reste moins transparente, car son tokenizer n'est pas aussi facilement disponible que celui de GPT. Anthropic a introduit une API de comptage de jetons en décembre 2024, mais cette fonctionnalité a été abandonnée dans les versions 2025 ultérieures. Selon Latenode, "Anthropic utilise un tokenizer unique avec seulement 65 000 variations de token, comparé aux 100 261 variations d'OpenAI pour GPT-4." Un cahier Colab accessible au public contient un code Python permettant d'analyser les différences de symbolisation entre les modèles GPT et Claude. Un autre outil qui s'interface avec des tokenizers communs et accessibles au public corrobore nos résultats. Des informations essentielles
Anthropic n'avait pas répondu à la demande de commentaire de VentureBeat à l'heure de la publication. Nous mettrons à jour cet article en cas de réponse. |










 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
 OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
 Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc

Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai

Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai













