
















 Hogar
Hogar
Costes de la IA empresarial: Los modelos de Claude tienen un precio de implantación entre un 20 y un 30% superior al de GPT
Es bien sabido que las distintas familias de modelos pueden emplear diferentes tokenizadores. Sin embargo, se ha investigado poco cómo varía el proceso de tokenización entre estos sistemas. ¿Producen todos los tokenizadores el mismo número de tokens para un texto de entrada idéntico? Si no es así, ¿hasta qué punto son sustanciales estas diferencias? ¿Qué implicaciones prácticas tienen?
Este artículo investiga estas cuestiones examinando las consecuencias en el mundo real de la variabilidad de la tokenización. Presentamos un análisis comparativo de dos de las principales familias de modelos: ChatGPT de OpenAI frente a Claude de Anthropic. Aunque sus tarifas anunciadas de "coste por token" parecen muy competitivas, nuestras pruebas revelan que los modelos de Anthropic pueden ser en realidad un 20-30% más caros que los modelos GPT en la práctica.
Precios de API - Claude 3.5 Sonnet frente a GPT-4o
A partir de junio de 2024, las estructuras de precios de estos dos modelos de frontera avanzada están muy igualadas. Tanto Claude 3.5 Sonnet de Anthropic como GPT-4o de OpenAI mantienen costes idénticos para los tokens de salida, mientras que Claude 3.5 Sonnet ofrece un descuento del 40% en los tokens de entrada.
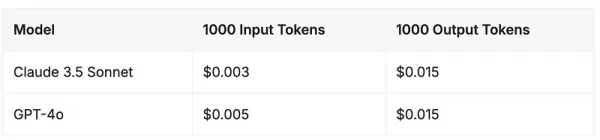
Fuente: Vantage
La ineficiencia oculta de la tokenización
A pesar de que las tasas de tokens de entrada de Anthropic son más bajas, nuestros experimentos con conjuntos de prompt fijos demuestran que GPT-4o ofrece sistemáticamente costes globales más económicos que Claude Sonnet-3.5.
¿Qué explica esta discrepancia?
El tokenizador de Anthropic suele segmentar un texto de entrada idéntico en más tokens que el método de OpenAI. Esto significa que, para las mismas instrucciones, los modelos de Anthropic generan un número de tokens significativamente mayor que sus equivalentes de OpenAI. En consecuencia, aunque el coste de entrada por token de Claude 3.5 Sonnet parece menor, el mayor volumen de tokenización a menudo anula este ahorro, lo que se traduce en mayores gastos totales para las implementaciones prácticas.
Este coste oculto se debe a la metodología de codificación de tokens de Anthropic, que a menudo requiere más tokens para representar un contenido equivalente. La inflación en el recuento de tokens afecta sustancialmente tanto a los costes operativos como a la eficiencia de la ventana de contexto.
Variaciones en la tokenización de dominios específicos
El tokenizador de Anthropic procesa diferentes dominios de contenido con distinta eficiencia, produciendo aumentos inconsistentes en el recuento de tokens en relación con los modelos de OpenAI. La comunidad investigadora en IA ha documentado disparidades similares en la tokenización. Hemos validado nuestros resultados en tres dominios destacados: Artículos en inglés, código Python y contenido matemático.
Dominio Modelo de entrada Tokens GPT Tokens Claude Sobrecarga de tokens Artículos en inglés  Implicaciones prácticas adicionales de las diferencias de tokenización
Implicaciones prácticas adicionales de las diferencias de tokenizaciónMás allá de los costes directos, la ineficacia del tokenizador afecta indirectamente a la utilización de la ventana de contexto. Aunque los modelos de Anthropic anuncian una ventana de contexto de 200.000 tokens frente a los 128.000 de OpenAI, la verbosidad de la tokenización puede reducir el espacio útil efectivo en los modelos de Anthropic. Esto crea una discrepancia potencial entre los tamaños de ventana de contexto anunciados y su capacidad práctica y efectiva.
Detalles de la implementación de la tokenización
Los modelos GPT utilizan la codificación por pares de bytes (BPE), que combina los pares de caracteres más frecuentes para formar tokens. Los últimos modelos de GPT emplean específicamente el tokenizador de código abierto o200k_base. Los tokens reales utilizados por GPT-4o dentro del tokenizador tiktoken son de acceso público.
JSON {#razonamiento "o1-xxx": "o200k_base","o3-xxx": "o200k_base",# chat"chatgpt-4o-": "o200k_base","gpt-4o-xxx": "o200k_base",# p.ej., gpt-4o-2024-05-13 "gpt-4-xxx": "cl100k_base",# p. ej., gpt-4-0314, etc., más gpt-4-32k "gpt-3.5-turbo-xxx": "cl100k_base",# p.ej., gpt-3.5-turbo-0301, -0401, etc.}
Por desgracia, el método de tokenización de Anthropic sigue siendo menos transparente, ya que su tokenizador no está tan disponible como el de GPT. Anthropic introdujo una API de recuento de tokens en diciembre de 2024, pero esta función se interrumpió en versiones posteriores de 2025.
Según Latenode, "Anthropic emplea un tokenizador único con sólo 65.000 variaciones de token, comparado con las 100.261 variaciones de OpenAI para GPT-4". Un cuaderno Colab de acceso público contiene código Python para analizar las diferencias de tokenización entre los modelos GPT y Claude. Otra herramienta que interactúa con tokenizadores comunes disponibles públicamente corrobora nuestros hallazgos.
Para las empresas de IA, la capacidad de estimar con precisión los recuentos de tokens sin invocar APIs de modelos reales es esencial para la previsión de costes y la elaboración de presupuestos.
Información esencial
- Los precios competitivos de Anthropic contienen gastos ocultos:
Aunque Claude 3.5 Sonnet ofrece unos costes de token de entrada un 40% más bajos que GPT-4o, esta aparente ventaja puede ser engañosa debido a diferencias fundamentales en la tokenización de texto. - La ineficacia oculta de la tokenización:
Los modelos antrópicos producen intrínsecamente más tokens. Para las organizaciones que procesan grandes volúmenes de texto, comprender esta variación es fundamental para evaluar con precisión los costes de implantación. - Rendimiento específico de la tokenización:
A la hora de elegir entre los modelos OpenAI y Anthropic, evalúe cuidadosamente su contenido de entrada típico. Mientras que las tareas de lenguaje natural pueden mostrar diferencias de coste mínimas, los dominios técnicos o estructurados podrían experimentar gastos significativamente mayores con los modelos de Anthropic. - Capacidad efectiva de ventana de contexto:
Debido a la verbosidad de la tokenización de Anthropic, su ventana de contexto anunciada de 200K podría proporcionar menos espacio útil práctico que los 128K de OpenAI, creando potencialmente una brecha entre la capacidad de contexto declarada y la real.
Anthropic no había respondido a la solicitud de comentarios de VentureBeat al cierre de esta edición. Actualizaremos este artículo si responden.
Artículo relacionado
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Recomendaciones de temas especiales relacionados
Negocio
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Recomendaciones de temas especiales relacionados
Negocio
 El mejor software de revisión de contratos con IA: detecta al instante las lagunas legales y los riesgos de cumplimiento normativo
El mejor software de revisión de contratos con IA: detecta al instante las lagunas legales y los riesgos de cumplimiento normativo
Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
 10 herramientas
10 herramientas
 xix.ai
Creación de animación
Generador de anime AI para Donghua: Crea personajes para novelas web y avatares para cómics
xix.ai
Creación de animación
Generador de anime AI para Donghua: Crea personajes para novelas web y avatares para cómics
Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai
Negocio
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
Es bien sabido que las distintas familias de modelos pueden emplear diferentes tokenizadores. Sin embargo, se ha investigado poco cómo varía el proceso de tokenización entre estos sistemas. ¿Producen todos los tokenizadores el mismo número de tokens para un texto de entrada idéntico? Si no es así, ¿hasta qué punto son sustanciales estas diferencias? ¿Qué implicaciones prácticas tienen?
Este artículo investiga estas cuestiones examinando las consecuencias en el mundo real de la variabilidad de la tokenización. Presentamos un análisis comparativo de dos de las principales familias de modelos: ChatGPT de OpenAI frente a Claude de Anthropic. Aunque sus tarifas anunciadas de "coste por token" parecen muy competitivas, nuestras pruebas revelan que los modelos de Anthropic pueden ser en realidad un 20-30% más caros que los modelos GPT en la práctica.
Precios de API - Claude 3.5 Sonnet frente a GPT-4o
A partir de junio de 2024, las estructuras de precios de estos dos modelos de frontera avanzada están muy igualadas. Tanto Claude 3.5 Sonnet de Anthropic como GPT-4o de OpenAI mantienen costes idénticos para los tokens de salida, mientras que Claude 3.5 Sonnet ofrece un descuento del 40% en los tokens de entrada.
Fuente: Vantage
La ineficiencia oculta de la tokenización
A pesar de que las tasas de tokens de entrada de Anthropic son más bajas, nuestros experimentos con conjuntos de prompt fijos demuestran que GPT-4o ofrece sistemáticamente costes globales más económicos que Claude Sonnet-3.5.
¿Qué explica esta discrepancia?
El tokenizador de Anthropic suele segmentar un texto de entrada idéntico en más tokens que el método de OpenAI. Esto significa que, para las mismas instrucciones, los modelos de Anthropic generan un número de tokens significativamente mayor que sus equivalentes de OpenAI. En consecuencia, aunque el coste de entrada por token de Claude 3.5 Sonnet parece menor, el mayor volumen de tokenización a menudo anula este ahorro, lo que se traduce en mayores gastos totales para las implementaciones prácticas.
Este coste oculto se debe a la metodología de codificación de tokens de Anthropic, que a menudo requiere más tokens para representar un contenido equivalente. La inflación en el recuento de tokens afecta sustancialmente tanto a los costes operativos como a la eficiencia de la ventana de contexto.
Variaciones en la tokenización de dominios específicos
El tokenizador de Anthropic procesa diferentes dominios de contenido con distinta eficiencia, produciendo aumentos inconsistentes en el recuento de tokens en relación con los modelos de OpenAI. La comunidad investigadora en IA ha documentado disparidades similares en la tokenización. Hemos validado nuestros resultados en tres dominios destacados: Artículos en inglés, código Python y contenido matemático.
| Dominio | Modelo de entrada | Tokens GPT | Tokens Claude | Sobrecarga de tokens |
| Artículos en inglés | Implicaciones prácticas adicionales de las diferencias de tokenización Más allá de los costes directos, la ineficacia del tokenizador afecta indirectamente a la utilización de la ventana de contexto. Aunque los modelos de Anthropic anuncian una ventana de contexto de 200.000 tokens frente a los 128.000 de OpenAI, la verbosidad de la tokenización puede reducir el espacio útil efectivo en los modelos de Anthropic. Esto crea una discrepancia potencial entre los tamaños de ventana de contexto anunciados y su capacidad práctica y efectiva. Detalles de la implementación de la tokenizaciónLos modelos GPT utilizan la codificación por pares de bytes (BPE), que combina los pares de caracteres más frecuentes para formar tokens. Los últimos modelos de GPT emplean específicamente el tokenizador de código abierto o200k_base. Los tokens reales utilizados por GPT-4o dentro del tokenizador tiktoken son de acceso público. Por desgracia, el método de tokenización de Anthropic sigue siendo menos transparente, ya que su tokenizador no está tan disponible como el de GPT. Anthropic introdujo una API de recuento de tokens en diciembre de 2024, pero esta función se interrumpió en versiones posteriores de 2025. Según Latenode, "Anthropic emplea un tokenizador único con sólo 65.000 variaciones de token, comparado con las 100.261 variaciones de OpenAI para GPT-4". Un cuaderno Colab de acceso público contiene código Python para analizar las diferencias de tokenización entre los modelos GPT y Claude. Otra herramienta que interactúa con tokenizadores comunes disponibles públicamente corrobora nuestros hallazgos. Información esencial
Anthropic no había respondido a la solicitud de comentarios de VentureBeat al cierre de esta edición. Actualizaremos este artículo si responden. |










 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
 OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
 Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati

Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
10 herramientas
xix.ai

Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai

Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai













