




"Ít hơn là nhiều hơn: Làm thế nào việc truy xuất ít tài liệu hơn giúp tăng cường phản hồi của AI"
Tạo Sinh Tăng Cường Tìm Kiếm (RAG) là một cách tiếp cận sáng tạo để xây dựng các hệ thống AI, kết hợp mô hình ngôn ngữ với nguồn tri thức bên ngoài để tăng cường độ chính xác và giảm lỗi thực tế. Về bản chất, AI tìm kiếm các tài liệu liên quan đến câu hỏi của người dùng và sử dụng thông tin này để tạo ra câu trả lời chính xác hơn. Phương pháp này đã được công nhận vì khả năng giữ cho các mô hình ngôn ngữ lớn (LLMs) bám sát dữ liệu thực, giảm thiểu nguy cơ ảo giác.
Bạn có thể cho rằng cung cấp cho AI nhiều tài liệu hơn sẽ dẫn đến câu trả lời được thông tin tốt hơn. Tuy nhiên, một nghiên cứu gần đây từ Đại học Hebrew ở Jerusalem lại cho thấy điều ngược lại: khi cung cấp thông tin cho AI, ít hơn đôi khi lại tốt hơn.
Ít Tài Liệu Hơn, Câu Trả Lời Tốt Hơn
Nghiên cứu đã đi sâu vào cách số lượng tài liệu cung cấp cho hệ thống RAG ảnh hưởng đến hiệu suất của nó. Các nhà nghiên cứu giữ tổng độ dài văn bản không đổi, điều chỉnh số lượng tài liệu từ 20 xuống còn 2-4 tài liệu liên quan và mở rộng những tài liệu này để khớp với khối lượng văn bản ban đầu. Điều này cho phép họ cô lập tác động của số lượng tài liệu đối với hiệu suất.
Sử dụng tập dữ liệu MuSiQue, bao gồm các câu hỏi đố vui kết hợp với các đoạn văn từ Wikipedia, họ nhận thấy các mô hình AI thường hoạt động tốt hơn với ít tài liệu hơn. Độ chính xác tăng lên đến 10% (đo bằng điểm F1) khi hệ thống tập trung vào chỉ một vài tài liệu quan trọng thay vì một bộ sưu tập rộng lớn. Xu hướng này được giữ vững trên nhiều mô hình ngôn ngữ mã nguồn mở khác nhau, như Llama của Meta, với Qwen-2 là ngoại lệ đáng chú ý, duy trì hiệu suất với nhiều tài liệu.
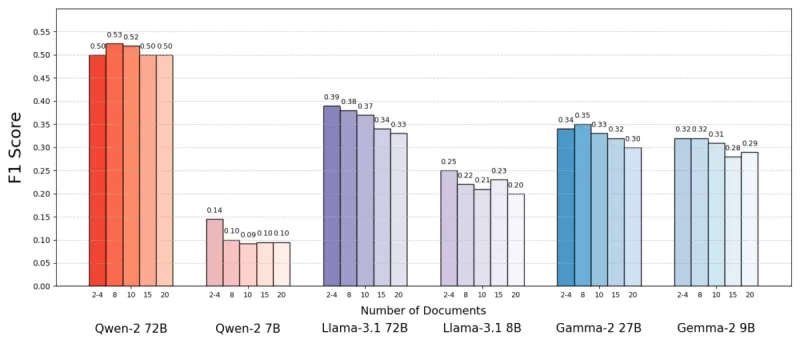 Nguồn: Levy và cộng sự.
Nguồn: Levy và cộng sự.
Kết quả đáng ngạc nhiên này thách thức niềm tin phổ biến rằng nhiều thông tin hơn luôn hữu ích. Ngay cả khi có cùng khối lượng văn bản, sự hiện diện của nhiều tài liệu dường như làm phức tạp nhiệm vụ của AI, gây ra nhiều nhiễu hơn là tín hiệu.
Tại Sao Ít Hơn Lại Có Thể Tốt Hơn Trong RAG
Nguyên tắc "ít hơn là nhiều hơn" trở nên hợp lý khi chúng ta xem xét cách các mô hình AI xử lý thông tin. Với ít tài liệu hơn, nhưng có liên quan cao, AI có thể tập trung vào ngữ cảnh cốt lõi mà không bị phân tâm, giống như một học sinh học tài liệu quan trọng nhất.
Trong nghiên cứu, các mô hình hoạt động tốt hơn khi chỉ được cung cấp các tài liệu trực tiếp liên quan đến câu trả lời, vì ngữ cảnh rõ ràng và tập trung này giúp dễ dàng trích xuất thông tin đúng. Ngược lại, khi AI phải sàng lọc qua nhiều tài liệu, nó thường gặp khó khăn với sự pha trộn giữa nội dung liên quan và không liên quan. Các tài liệu tương tự nhưng không liên quan có thể khiến mô hình bị đánh lạc hướng, làm tăng nguy cơ ảo giác.
Thú vị là, nghiên cứu phát hiện rằng AI có thể dễ dàng bỏ qua các tài liệu rõ ràng không liên quan hơn là những tài liệu lệch chủ đề một cách tinh vi. Điều này cho thấy các yếu tố gây nhiễu thực tế gây khó khăn hơn so với những yếu tố ngẫu nhiên. Bằng cách giới hạn tài liệu chỉ ở những tài liệu cần thiết, chúng ta giảm khả năng tạo ra những cái bẫy như vậy.
Ngoài ra, việc sử dụng ít tài liệu hơn làm giảm chi phí tính toán, giúp hệ thống hiệu quả và tiết kiệm chi phí hơn. Cách tiếp cận này không chỉ cải thiện độ chính xác mà còn nâng cao hiệu suất tổng thể của hệ thống RAG.
 Nguồn: Levy và cộng sự.
Nguồn: Levy và cộng sự.
Tái Tư Duy Về RAG: Hướng Đi Tương Lai
Những phát hiện này có ý nghĩa quan trọng đối với việc thiết kế các hệ thống AI tương lai dựa trên tri thức bên ngoài. Nó cho thấy việc tập trung vào chất lượng và mức độ liên quan của các tài liệu được truy xuất, thay vì số lượng, có thể nâng cao hiệu suất. Các tác giả nghiên cứu ủng hộ các phương pháp truy xuất cân bằng giữa mức độ liên quan và sự đa dạng, đảm bảo bao quát toàn diện mà không làm quá tải mô hình với văn bản không cần thiết.
Nghiên cứu trong tương lai có thể khám phá các hệ thống truy xuất hoặc tái xếp hạng tốt hơn để xác định các tài liệu thực sự giá trị và cải thiện cách các mô hình ngôn ngữ xử lý nhiều nguồn. Việc cải tiến chính các mô hình, như được thấy với Qwen-2, cũng có thể cung cấp cái nhìn sâu sắc về việc làm cho chúng mạnh mẽ hơn với các đầu vào đa dạng.
Khi các hệ thống AI phát triển cửa sổ ngữ cảnh lớn hơn, khả năng xử lý nhiều văn bản cùng lúc trở nên ít quan trọng hơn so với việc đảm bảo văn bản đó liên quan và được chọn lọc cẩn thận. Nghiên cứu, có tiêu đề "Nhiều Tài Liệu Hơn, Cùng Độ Dài," nhấn mạnh tầm quan trọng của việc tập trung vào thông tin liên quan nhất để cải thiện độ chính xác và hiệu quả của AI.
Kết luận, nghiên cứu này thách thức các giả định của chúng ta về dữ liệu đầu vào trong các hệ thống AI. Bằng cách lựa chọn cẩn thận ít tài liệu hơn, tốt hơn, chúng ta có thể tạo ra các hệ thống RAG thông minh hơn, gọn gàng hơn, mang lại câu trả lời chính xác và đáng tin cậy hơn.
Bài viết liên quan
 Amazon’s Danielle Perszyk Phát biểu tại TechCrunch Sessions: AI
Chúng tôi rất hào hứng thông báo rằng Danielle Perszyk, trưởng nhóm tương tác người-máy của Amazon AGI SF Lab, sẽ phát biểu tại TechCrunch Sessions: AI vào ngày 5 tháng 6 tại Zellerbach Hall của UC Be
Tối ưu hóa đặt lịch tiệm cắt tóc với công cụ AI miễn phí
Trong thế giới chuyển động nhanh ngày nay, tự động hóa là chìa khóa cho hiệu quả. Hãy tưởng tượng sử dụng AI để quản lý lịch hẹn tiệm cắt tóc một cách dễ dàng. Hướng dẫn này khám phá cách các tác nhân
Audible Tăng Cường Các Sách Nói Được AI Đọc Với Quan Hệ Đối Tác Nhà Xuất Bản Mới
Audible, nền tảng sách nói của Amazon, vào thứ Ba đã công bố một sự hợp tác với một số nhà xuất bản được chọn để chuyển đổi sách in và sách điện tử thành sách nói do AI đọc. Động thái này nhằm mở rộng
Nhận xét (46)
0/200
Amazon’s Danielle Perszyk Phát biểu tại TechCrunch Sessions: AI
Chúng tôi rất hào hứng thông báo rằng Danielle Perszyk, trưởng nhóm tương tác người-máy của Amazon AGI SF Lab, sẽ phát biểu tại TechCrunch Sessions: AI vào ngày 5 tháng 6 tại Zellerbach Hall của UC Be
Tối ưu hóa đặt lịch tiệm cắt tóc với công cụ AI miễn phí
Trong thế giới chuyển động nhanh ngày nay, tự động hóa là chìa khóa cho hiệu quả. Hãy tưởng tượng sử dụng AI để quản lý lịch hẹn tiệm cắt tóc một cách dễ dàng. Hướng dẫn này khám phá cách các tác nhân
Audible Tăng Cường Các Sách Nói Được AI Đọc Với Quan Hệ Đối Tác Nhà Xuất Bản Mới
Audible, nền tảng sách nói của Amazon, vào thứ Ba đã công bố một sự hợp tác với một số nhà xuất bản được chọn để chuyển đổi sách in và sách điện tử thành sách nói do AI đọc. Động thái này nhằm mở rộng
Nhận xét (46)
0/200
![BruceBrown]() BruceBrown
BruceBrown
 19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?


 0
0
![JasonMartin]() JasonMartin
13:04:32 GMT+07:00 Ngày 26 tháng 4 năm 2025
JasonMartin
13:04:32 GMT+07:00 Ngày 26 tháng 4 năm 2025
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
![JuanMoore]() JuanMoore
05:29:07 GMT+07:00 Ngày 24 tháng 4 năm 2025
JuanMoore
05:29:07 GMT+07:00 Ngày 24 tháng 4 năm 2025
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
![GregoryJones]() GregoryJones
23:50:26 GMT+07:00 Ngày 22 tháng 4 năm 2025
GregoryJones
23:50:26 GMT+07:00 Ngày 22 tháng 4 năm 2025
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
![BrianMartinez]() BrianMartinez
18:14:10 GMT+07:00 Ngày 21 tháng 4 năm 2025
BrianMartinez
18:14:10 GMT+07:00 Ngày 21 tháng 4 năm 2025
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0
![GaryWilson]() GaryWilson
15:39:06 GMT+07:00 Ngày 21 tháng 4 năm 2025
GaryWilson
15:39:06 GMT+07:00 Ngày 21 tháng 4 năm 2025
AI 응답에서 '적을수록 좋다'는 접근 방식이 꽤 멋지네요! 적은 문서로도 정확한 답변을 얻다니, 가입하고 싶어요! 마법 같지만, 좀 더 빨리 작동했으면 좋겠어요. 그래도 AI 기술의 발전 단계로는 훌륭해요! 🚀
0
Tạo Sinh Tăng Cường Tìm Kiếm (RAG) là một cách tiếp cận sáng tạo để xây dựng các hệ thống AI, kết hợp mô hình ngôn ngữ với nguồn tri thức bên ngoài để tăng cường độ chính xác và giảm lỗi thực tế. Về bản chất, AI tìm kiếm các tài liệu liên quan đến câu hỏi của người dùng và sử dụng thông tin này để tạo ra câu trả lời chính xác hơn. Phương pháp này đã được công nhận vì khả năng giữ cho các mô hình ngôn ngữ lớn (LLMs) bám sát dữ liệu thực, giảm thiểu nguy cơ ảo giác.
Bạn có thể cho rằng cung cấp cho AI nhiều tài liệu hơn sẽ dẫn đến câu trả lời được thông tin tốt hơn. Tuy nhiên, một nghiên cứu gần đây từ Đại học Hebrew ở Jerusalem lại cho thấy điều ngược lại: khi cung cấp thông tin cho AI, ít hơn đôi khi lại tốt hơn.
Ít Tài Liệu Hơn, Câu Trả Lời Tốt Hơn
Nghiên cứu đã đi sâu vào cách số lượng tài liệu cung cấp cho hệ thống RAG ảnh hưởng đến hiệu suất của nó. Các nhà nghiên cứu giữ tổng độ dài văn bản không đổi, điều chỉnh số lượng tài liệu từ 20 xuống còn 2-4 tài liệu liên quan và mở rộng những tài liệu này để khớp với khối lượng văn bản ban đầu. Điều này cho phép họ cô lập tác động của số lượng tài liệu đối với hiệu suất.
Sử dụng tập dữ liệu MuSiQue, bao gồm các câu hỏi đố vui kết hợp với các đoạn văn từ Wikipedia, họ nhận thấy các mô hình AI thường hoạt động tốt hơn với ít tài liệu hơn. Độ chính xác tăng lên đến 10% (đo bằng điểm F1) khi hệ thống tập trung vào chỉ một vài tài liệu quan trọng thay vì một bộ sưu tập rộng lớn. Xu hướng này được giữ vững trên nhiều mô hình ngôn ngữ mã nguồn mở khác nhau, như Llama của Meta, với Qwen-2 là ngoại lệ đáng chú ý, duy trì hiệu suất với nhiều tài liệu.
Nguồn: Levy và cộng sự.
Kết quả đáng ngạc nhiên này thách thức niềm tin phổ biến rằng nhiều thông tin hơn luôn hữu ích. Ngay cả khi có cùng khối lượng văn bản, sự hiện diện của nhiều tài liệu dường như làm phức tạp nhiệm vụ của AI, gây ra nhiều nhiễu hơn là tín hiệu.
Tại Sao Ít Hơn Lại Có Thể Tốt Hơn Trong RAG
Nguyên tắc "ít hơn là nhiều hơn" trở nên hợp lý khi chúng ta xem xét cách các mô hình AI xử lý thông tin. Với ít tài liệu hơn, nhưng có liên quan cao, AI có thể tập trung vào ngữ cảnh cốt lõi mà không bị phân tâm, giống như một học sinh học tài liệu quan trọng nhất.
Trong nghiên cứu, các mô hình hoạt động tốt hơn khi chỉ được cung cấp các tài liệu trực tiếp liên quan đến câu trả lời, vì ngữ cảnh rõ ràng và tập trung này giúp dễ dàng trích xuất thông tin đúng. Ngược lại, khi AI phải sàng lọc qua nhiều tài liệu, nó thường gặp khó khăn với sự pha trộn giữa nội dung liên quan và không liên quan. Các tài liệu tương tự nhưng không liên quan có thể khiến mô hình bị đánh lạc hướng, làm tăng nguy cơ ảo giác.
Thú vị là, nghiên cứu phát hiện rằng AI có thể dễ dàng bỏ qua các tài liệu rõ ràng không liên quan hơn là những tài liệu lệch chủ đề một cách tinh vi. Điều này cho thấy các yếu tố gây nhiễu thực tế gây khó khăn hơn so với những yếu tố ngẫu nhiên. Bằng cách giới hạn tài liệu chỉ ở những tài liệu cần thiết, chúng ta giảm khả năng tạo ra những cái bẫy như vậy.
Ngoài ra, việc sử dụng ít tài liệu hơn làm giảm chi phí tính toán, giúp hệ thống hiệu quả và tiết kiệm chi phí hơn. Cách tiếp cận này không chỉ cải thiện độ chính xác mà còn nâng cao hiệu suất tổng thể của hệ thống RAG.
Nguồn: Levy và cộng sự.
Tái Tư Duy Về RAG: Hướng Đi Tương Lai
Những phát hiện này có ý nghĩa quan trọng đối với việc thiết kế các hệ thống AI tương lai dựa trên tri thức bên ngoài. Nó cho thấy việc tập trung vào chất lượng và mức độ liên quan của các tài liệu được truy xuất, thay vì số lượng, có thể nâng cao hiệu suất. Các tác giả nghiên cứu ủng hộ các phương pháp truy xuất cân bằng giữa mức độ liên quan và sự đa dạng, đảm bảo bao quát toàn diện mà không làm quá tải mô hình với văn bản không cần thiết.
Nghiên cứu trong tương lai có thể khám phá các hệ thống truy xuất hoặc tái xếp hạng tốt hơn để xác định các tài liệu thực sự giá trị và cải thiện cách các mô hình ngôn ngữ xử lý nhiều nguồn. Việc cải tiến chính các mô hình, như được thấy với Qwen-2, cũng có thể cung cấp cái nhìn sâu sắc về việc làm cho chúng mạnh mẽ hơn với các đầu vào đa dạng.
Khi các hệ thống AI phát triển cửa sổ ngữ cảnh lớn hơn, khả năng xử lý nhiều văn bản cùng lúc trở nên ít quan trọng hơn so với việc đảm bảo văn bản đó liên quan và được chọn lọc cẩn thận. Nghiên cứu, có tiêu đề "Nhiều Tài Liệu Hơn, Cùng Độ Dài," nhấn mạnh tầm quan trọng của việc tập trung vào thông tin liên quan nhất để cải thiện độ chính xác và hiệu quả của AI.
Kết luận, nghiên cứu này thách thức các giả định của chúng ta về dữ liệu đầu vào trong các hệ thống AI. Bằng cách lựa chọn cẩn thận ít tài liệu hơn, tốt hơn, chúng ta có thể tạo ra các hệ thống RAG thông minh hơn, gọn gàng hơn, mang lại câu trả lời chính xác và đáng tin cậy hơn.










 Amazon’s Danielle Perszyk Phát biểu tại TechCrunch Sessions: AI
Chúng tôi rất hào hứng thông báo rằng Danielle Perszyk, trưởng nhóm tương tác người-máy của Amazon AGI SF Lab, sẽ phát biểu tại TechCrunch Sessions: AI vào ngày 5 tháng 6 tại Zellerbach Hall của UC Be
Amazon’s Danielle Perszyk Phát biểu tại TechCrunch Sessions: AI
Chúng tôi rất hào hứng thông báo rằng Danielle Perszyk, trưởng nhóm tương tác người-máy của Amazon AGI SF Lab, sẽ phát biểu tại TechCrunch Sessions: AI vào ngày 5 tháng 6 tại Zellerbach Hall của UC Be
 Tối ưu hóa đặt lịch tiệm cắt tóc với công cụ AI miễn phí
Trong thế giới chuyển động nhanh ngày nay, tự động hóa là chìa khóa cho hiệu quả. Hãy tưởng tượng sử dụng AI để quản lý lịch hẹn tiệm cắt tóc một cách dễ dàng. Hướng dẫn này khám phá cách các tác nhân
Tối ưu hóa đặt lịch tiệm cắt tóc với công cụ AI miễn phí
Trong thế giới chuyển động nhanh ngày nay, tự động hóa là chìa khóa cho hiệu quả. Hãy tưởng tượng sử dụng AI để quản lý lịch hẹn tiệm cắt tóc một cách dễ dàng. Hướng dẫn này khám phá cách các tác nhân
 Audible Tăng Cường Các Sách Nói Được AI Đọc Với Quan Hệ Đối Tác Nhà Xuất Bản Mới
Audible, nền tảng sách nói của Amazon, vào thứ Ba đã công bố một sự hợp tác với một số nhà xuất bản được chọn để chuyển đổi sách in và sách điện tử thành sách nói do AI đọc. Động thái này nhằm mở rộng
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
Audible Tăng Cường Các Sách Nói Được AI Đọc Với Quan Hệ Đối Tác Nhà Xuất Bản Mới
Audible, nền tảng sách nói của Amazon, vào thứ Ba đã công bố một sự hợp tác với một số nhà xuất bản được chọn để chuyển đổi sách in và sách điện tử thành sách nói do AI đọc. Động thái này nhằm mở rộng
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
13:04:32 GMT+07:00 Ngày 26 tháng 4 năm 2025
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
05:29:07 GMT+07:00 Ngày 24 tháng 4 năm 2025
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
23:50:26 GMT+07:00 Ngày 22 tháng 4 năm 2025
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
18:14:10 GMT+07:00 Ngày 21 tháng 4 năm 2025
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0
15:39:06 GMT+07:00 Ngày 21 tháng 4 năm 2025
AI 응답에서 '적을수록 좋다'는 접근 방식이 꽤 멋지네요! 적은 문서로도 정확한 답변을 얻다니, 가입하고 싶어요! 마법 같지만, 좀 더 빨리 작동했으면 좋겠어요. 그래도 AI 기술의 발전 단계로는 훌륭해요! 🚀
0













