
















 Lar
Lar
QwenLong-L1 resolve tarefas complexas de raciocínio além das capacidades dos LLMs atuais
O Alibaba Group revelou o QwenLong-L1, uma nova estrutura projetada para capacitar modelos de linguagem de grande porte (LLMs) a raciocinar sobre documentos excepcionalmente longos. Essa inovação tem o potencial de impulsionar uma nova geração de aplicativos empresariais que exigem compreensão profunda e análise perspicaz de materiais extensos, incluindo relatórios corporativos abrangentes, demonstrações financeiras detalhadas e contratos jurídicos complexos.
O obstáculo do raciocínio de IA em formatos longos
Os recentes avanços em modelos de raciocínio de grande porte (LRMs), especialmente por meio do aprendizado por reforço (RL), aumentaram drasticamente suas habilidades de resolução de problemas. Estudos indicam que o ajuste fino do RL dota os LRMs de uma forma de “pensamento lento” semelhante à cognição humana, permitindo-lhes elaborar estratégias sofisticadas para lidar com tarefas complexas.
No entanto, esses ganhos estão amplamente restritos ao trabalho com trechos de texto relativamente curtos, geralmente em torno de 4.000 tokens. Um obstáculo significativo permanece na ampliação dessa capacidade de raciocínio para contextos muito mais longos, como 120.000 tokens. O raciocínio eficaz em textos longos exige uma compreensão sólida de todo o documento e a capacidade de análise em várias etapas. “Essa restrição dificulta significativamente os usos práticos que envolvem conhecimento externo, como pesquisas aprofundadas em que os LRMs precisam coletar e processar informações de fontes ricas em dados”, observam os desenvolvedores do QwenLong-L1 em seu artigo de pesquisa.
A equipe enquadra esses obstáculos sob o conceito de “raciocínio RL de contexto longo”. Ao contrário do raciocínio de contexto curto, que muitas vezes aproveita o conhecimento interno do modelo, essa abordagem exige que os modelos encontrem e fixem com precisão fatos relevantes em entradas longas. Só então eles podem construir cadeias de raciocínio lógico com base nessas informações recuperadas.
Treinar modelos para isso por meio de RL é desafiador, frequentemente levando a um aprendizado ineficiente e otimização instável. Os modelos muitas vezes não conseguem convergir para soluções eficazes ou perdem sua capacidade de explorar caminhos de raciocínio variados.
QwenLong-L1: uma estrutura estruturada em várias etapas
O QwenLong-L1 é uma estrutura de aprendizagem por reforço criada para ajudar os LRM a evoluir do tratamento de textos curtos para a generalização robusta em contextos longos. Ele aprimora os LRM de contexto curto existentes por meio de um processo deliberado e em fases:
Aqueecimento com ajuste fino supervisionado (SFT): o modelo primeiro passa por SFT usando exemplos de raciocínio em contextos longos. Essa fase constrói uma base sólida, ensinando o modelo a ancorar com precisão as informações de documentos longos e desenvolver habilidades essenciais na compreensão do contexto, geração de cadeias lógicas e extração de respostas.
RL em fases guiado por currículo: aqui, o modelo é treinado por meio de várias fases em que o comprimento do documento alvo aumenta progressivamente. Esse método passo a passo, baseado em currículo, ajuda o modelo a adaptar de forma constante suas estratégias de raciocínio de textos mais curtos para textos cada vez mais longos, evitando a instabilidade da exposição abrupta a documentos extensos.
Amostragem retrospectiva com reconhecimento de dificuldade: A etapa final incorpora os exemplos mais desafiadores das fases de treinamento anteriores. Ao priorizar instâncias difíceis, ela garante que o modelo continue aprendendo com problemas complexos e seja incentivado a explorar rotas de raciocínio mais diversificadas e complexas.
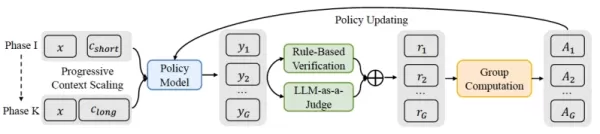
Processo QwenLong-L1 Fonte: arXiv Além desse treinamento estruturado, o QwenLong-L1 emprega um sistema de recompensa especializado. Enquanto o treinamento para tarefas de contexto curto geralmente usa recompensas baseadas em regras rígidas (por exemplo, para uma resposta matemática correta), o QwenLong-L1 usa um mecanismo híbrido. Ele combina a verificação baseada em regras para precisão com um “LLM como juiz” que compara o significado semântico da resposta gerada com a referência. Isso permite maior flexibilidade na avaliação das diversas maneiras pelas quais as respostas corretas podem ser formuladas em documentos longos e cheios de nuances.
Avaliação do desempenho do QwenLong-L1
A equipe da Alibaba testou o QwenLong-L1 principalmente usando perguntas e respostas de documentos (DocQA), uma tarefa altamente pertinente às necessidades empresariais, em que a IA deve decifrar documentos densos para responder a consultas complexas.
Os resultados em sete benchmarks DocQA de contexto longo demonstraram a força do QwenLong-L1. O modelo QWENLONG-L1-32B (baseado no DeepSeek-R1-Distill-Qwen-32B) alcançou desempenho equivalente ao Claude-3.7 Sonnet Thinking da Anthropic e superou modelos como o o3-mini da OpenAI e o Qwen3-235B-A22B. O modelo QWENLONG-L1-14B, menor, também superou o Gemini 2.0 Flash Thinking, do Google, e o Qwen3-32B.
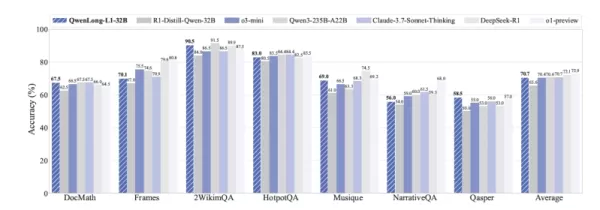
Fonte: arXiv Uma descoberta importante para o uso no mundo real é como o treinamento RL cultiva comportamentos especializados de raciocínio de contexto longo. O artigo destaca que os modelos treinados com QwenLong-L1 melhoram em “fundamentação” (vinculando respostas a seções específicas de documentos), “definição de submetas” (decompondo perguntas complexas), “retrocesso” (identificando e corrigindo erros no meio do raciocínio) e “verificação” (reverificando suas respostas).
Por exemplo, enquanto um modelo básico pode ser prejudicado por detalhes irrelevantes em um relatório financeiro ou ficar preso em análises tangenciais, um modelo treinado com QwenLong-L1 mostrou uma autorreflexão eficaz. Ele conseguiu filtrar informações que distraíam, refazer o caminho a partir de abordagens incorretas e chegar à conclusão correta.
Estruturas como o QwenLong-L1 podem ampliar substancialmente a utilidade da IA nas empresas. As aplicações potenciais abrangem tecnologia jurídica (análise de documentos jurídicos volumosos), finanças (realização de due diligence aprofundada em relatórios anuais e registros financeiros para obter insights sobre riscos ou investimentos) e atendimento ao cliente (revisão de longos históricos de interação para fornecer suporte mais contextual). Os pesquisadores disponibilizaram publicamente o código da estrutura QwenLong-L1 e os pesos dos modelos treinados.
Artigo relacionado
 A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
Recomendações de tópicos especiais relacionados
Negócios
A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
Recomendações de tópicos especiais relacionados
Negócios
 As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
 10 ferramentas
10 ferramentas
 xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

 Comentários (0)
Comentários (0)
O Alibaba Group revelou o QwenLong-L1, uma nova estrutura projetada para capacitar modelos de linguagem de grande porte (LLMs) a raciocinar sobre documentos excepcionalmente longos. Essa inovação tem o potencial de impulsionar uma nova geração de aplicativos empresariais que exigem compreensão profunda e análise perspicaz de materiais extensos, incluindo relatórios corporativos abrangentes, demonstrações financeiras detalhadas e contratos jurídicos complexos.
O obstáculo do raciocínio de IA em formatos longos
Os recentes avanços em modelos de raciocínio de grande porte (LRMs), especialmente por meio do aprendizado por reforço (RL), aumentaram drasticamente suas habilidades de resolução de problemas. Estudos indicam que o ajuste fino do RL dota os LRMs de uma forma de “pensamento lento” semelhante à cognição humana, permitindo-lhes elaborar estratégias sofisticadas para lidar com tarefas complexas.
No entanto, esses ganhos estão amplamente restritos ao trabalho com trechos de texto relativamente curtos, geralmente em torno de 4.000 tokens. Um obstáculo significativo permanece na ampliação dessa capacidade de raciocínio para contextos muito mais longos, como 120.000 tokens. O raciocínio eficaz em textos longos exige uma compreensão sólida de todo o documento e a capacidade de análise em várias etapas. “Essa restrição dificulta significativamente os usos práticos que envolvem conhecimento externo, como pesquisas aprofundadas em que os LRMs precisam coletar e processar informações de fontes ricas em dados”, observam os desenvolvedores do QwenLong-L1 em seu artigo de pesquisa.
A equipe enquadra esses obstáculos sob o conceito de “raciocínio RL de contexto longo”. Ao contrário do raciocínio de contexto curto, que muitas vezes aproveita o conhecimento interno do modelo, essa abordagem exige que os modelos encontrem e fixem com precisão fatos relevantes em entradas longas. Só então eles podem construir cadeias de raciocínio lógico com base nessas informações recuperadas.
Treinar modelos para isso por meio de RL é desafiador, frequentemente levando a um aprendizado ineficiente e otimização instável. Os modelos muitas vezes não conseguem convergir para soluções eficazes ou perdem sua capacidade de explorar caminhos de raciocínio variados.
QwenLong-L1: uma estrutura estruturada em várias etapas
O QwenLong-L1 é uma estrutura de aprendizagem por reforço criada para ajudar os LRM a evoluir do tratamento de textos curtos para a generalização robusta em contextos longos. Ele aprimora os LRM de contexto curto existentes por meio de um processo deliberado e em fases:
Aqueecimento com ajuste fino supervisionado (SFT): o modelo primeiro passa por SFT usando exemplos de raciocínio em contextos longos. Essa fase constrói uma base sólida, ensinando o modelo a ancorar com precisão as informações de documentos longos e desenvolver habilidades essenciais na compreensão do contexto, geração de cadeias lógicas e extração de respostas.
RL em fases guiado por currículo: aqui, o modelo é treinado por meio de várias fases em que o comprimento do documento alvo aumenta progressivamente. Esse método passo a passo, baseado em currículo, ajuda o modelo a adaptar de forma constante suas estratégias de raciocínio de textos mais curtos para textos cada vez mais longos, evitando a instabilidade da exposição abrupta a documentos extensos.
Amostragem retrospectiva com reconhecimento de dificuldade: A etapa final incorpora os exemplos mais desafiadores das fases de treinamento anteriores. Ao priorizar instâncias difíceis, ela garante que o modelo continue aprendendo com problemas complexos e seja incentivado a explorar rotas de raciocínio mais diversificadas e complexas.
Além desse treinamento estruturado, o QwenLong-L1 emprega um sistema de recompensa especializado. Enquanto o treinamento para tarefas de contexto curto geralmente usa recompensas baseadas em regras rígidas (por exemplo, para uma resposta matemática correta), o QwenLong-L1 usa um mecanismo híbrido. Ele combina a verificação baseada em regras para precisão com um “LLM como juiz” que compara o significado semântico da resposta gerada com a referência. Isso permite maior flexibilidade na avaliação das diversas maneiras pelas quais as respostas corretas podem ser formuladas em documentos longos e cheios de nuances.
Avaliação do desempenho do QwenLong-L1
A equipe da Alibaba testou o QwenLong-L1 principalmente usando perguntas e respostas de documentos (DocQA), uma tarefa altamente pertinente às necessidades empresariais, em que a IA deve decifrar documentos densos para responder a consultas complexas.
Os resultados em sete benchmarks DocQA de contexto longo demonstraram a força do QwenLong-L1. O modelo QWENLONG-L1-32B (baseado no DeepSeek-R1-Distill-Qwen-32B) alcançou desempenho equivalente ao Claude-3.7 Sonnet Thinking da Anthropic e superou modelos como o o3-mini da OpenAI e o Qwen3-235B-A22B. O modelo QWENLONG-L1-14B, menor, também superou o Gemini 2.0 Flash Thinking, do Google, e o Qwen3-32B.
Uma descoberta importante para o uso no mundo real é como o treinamento RL cultiva comportamentos especializados de raciocínio de contexto longo. O artigo destaca que os modelos treinados com QwenLong-L1 melhoram em “fundamentação” (vinculando respostas a seções específicas de documentos), “definição de submetas” (decompondo perguntas complexas), “retrocesso” (identificando e corrigindo erros no meio do raciocínio) e “verificação” (reverificando suas respostas).
Por exemplo, enquanto um modelo básico pode ser prejudicado por detalhes irrelevantes em um relatório financeiro ou ficar preso em análises tangenciais, um modelo treinado com QwenLong-L1 mostrou uma autorreflexão eficaz. Ele conseguiu filtrar informações que distraíam, refazer o caminho a partir de abordagens incorretas e chegar à conclusão correta.
Estruturas como o QwenLong-L1 podem ampliar substancialmente a utilidade da IA nas empresas. As aplicações potenciais abrangem tecnologia jurídica (análise de documentos jurídicos volumosos), finanças (realização de due diligence aprofundada em relatórios anuais e registros financeiros para obter insights sobre riscos ou investimentos) e atendimento ao cliente (revisão de longos históricos de interação para fornecer suporte mais contextual). Os pesquisadores disponibilizaram publicamente o código da estrutura QwenLong-L1 e os pesos dos modelos treinados.










 A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
 DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
 O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai













