
















 Heim
Heim
QwenLong-L1 löst komplexe Denkaufgaben, die über die Fähigkeiten aktueller LLMs hinausgehen
Die Alibaba Group hat QwenLong-L1 vorgestellt, ein neues Framework, das große Sprachmodelle (LLMs) in die Lage versetzt, außergewöhnlich lange Dokumente zu analysieren. Dieser Durchbruch hat das Potenzial, eine neue Generation von Unternehmensanwendungen voranzutreiben, die ein tiefes Verständnis und eine aufschlussreiche Analyse umfangreicher Materialien erfordern, darunter umfassende Unternehmensberichte, detaillierte Finanzberichte und komplexe rechtliche Vereinbarungen.
Das Hindernis der KI-Argumentation in Langform
Die jüngsten Fortschritte bei großen Schlussfolgerungsmodellen (LRMs), insbesondere durch verstärktes Lernen (RL), haben deren Problemlösungsfähigkeiten erheblich verbessert. Studien zeigen, dass RL-Feinabstimmung LRMs mit einer Form des „langsamen Denkens” ausstattet, die der menschlichen Kognition ähnelt und es ihnen ermöglicht, ausgefeilte Strategien für die Bewältigung komplexer Aufgaben zu entwickeln.
Diese Fortschritte beschränken sich jedoch weitgehend auf die Arbeit mit relativ kurzen Textpassagen, in der Regel etwa 4.000 Token. Eine erhebliche Hürde bleibt die Skalierung dieser Schlussfolgerungsfähigkeit auf weitaus längere Kontexte, beispielsweise 120.000 Token. Effektives Langzeit-Schlussfolgern erfordert ein solides Verständnis des gesamten Dokuments und die Fähigkeit zur mehrstufigen Analyse. „Diese Einschränkung behindert erheblich praktische Anwendungen, die externes Wissen erfordern, wie z. B. eingehende Recherchen, bei denen LRM Informationen aus datenreichen Quellen sammeln und verarbeiten müssen”, stellen die Entwickler von QwenLong-L1 in ihrer Forschungsarbeit fest.
Das Team fasst diese Hindernisse unter dem Begriff „Long-Context Reasoning RL“ zusammen. Im Gegensatz zum Kurzkontext-Schlussfolgern, das häufig das interne Wissen des Modells nutzt, erfordert dieser Ansatz, dass Modelle relevante Fakten in langen Eingaben genau finden und verankern. Nur dann können sie auf der Grundlage dieser abgerufenen Informationen logische Schlussfolgerungsketten aufbauen.
Das Training von Modellen für diesen Zweck mittels RL ist eine Herausforderung, die häufig zu ineffizientem Lernen und instabiler Optimierung führt. Modelle scheitern oft daran, zu effektiven Lösungen zu konvergieren, oder verlieren ihre Fähigkeit, verschiedene Argumentationswege zu erkunden.
QwenLong-L1: Ein strukturiertes, mehrstufiges Framework
QwenLong-L1 ist ein Framework für verstärktes Lernen, das entwickelt wurde, um LRMs dabei zu helfen, sich von der Verarbeitung kurzer Texte zu einer robusten Verallgemeinerung über lange Kontexte hinweg weiterzuentwickeln. Es verbessert bestehende LRMs für kurze Kontexte durch einen bewussten, schrittweisen Prozess:
Warm-up Supervised Fine-Tuning (SFT): Das Modell durchläuft zunächst ein SFT unter Verwendung von Beispielen für das Schlussfolgern in langen Kontexten. Diese Phase schafft eine solide Grundlage und lehrt das Modell, Informationen aus langen Dokumenten genau zu verankern und Kernkompetenzen im Kontextverständnis, in der Generierung logischer Ketten und in der Extraktion von Antworten zu entwickeln.
Curriculum-Guided Phased RL: Hier wird das Modell in mehreren Phasen trainiert, in denen die Länge der Zieldokumente schrittweise erhöht wird. Diese schrittweise, lehrplanbasierte Methode hilft dem Modell, seine Argumentationsstrategien stetig von kürzeren zu immer längeren Texten anzupassen, wodurch die Instabilität einer abrupten Konfrontation mit umfangreichen Dokumenten vermieden wird.
Schwierigkeitsbewusstes retrospektives Sampling: Die letzte Phase umfasst die anspruchsvollsten Beispiele aus früheren Trainingsphasen. Durch die Priorisierung schwieriger Fälle wird sichergestellt, dass das Modell weiterhin aus schwierigen Problemen lernt und dazu angeregt wird, vielfältigere und komplexere Schlussfolgerungswege zu erkunden.
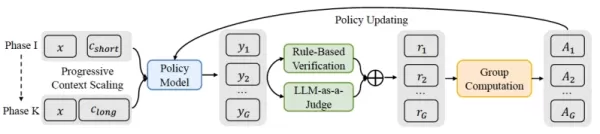
QwenLong-L1-Prozess Quelle: arXiv Über dieses strukturierte Training hinaus verwendet QwenLong-L1 ein spezielles Belohnungssystem. Während beim Training für Aufgaben mit kurzem Kontext oft strenge regelbasierte Belohnungen verwendet werden (z. B. für eine richtige mathematische Antwort), verwendet QwenLong-L1 einen hybriden Mechanismus. Er kombiniert die regelbasierte Überprüfung der Genauigkeit mit einem „LLM-as-a-judge”, das die semantische Bedeutung der generierten Antwort mit der Referenz vergleicht. Dies ermöglicht eine größere Flexibilität bei der Bewertung der vielfältigen Möglichkeiten, wie richtige Antworten in langen, nuancierten Dokumenten formuliert werden können.
Bewertung der Leistung von QwenLong-L1
Das Alibaba-Team testete QwenLong-L1 in erster Linie anhand von Dokumenten-Frage-Antworten (DocQA), einer Aufgabe, die für Unternehmensanforderungen von großer Relevanz ist, bei der KI dichte Dokumente entschlüsseln muss, um komplexe Fragen zu beantworten.
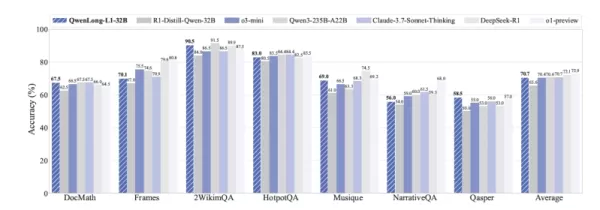
Die Ergebnisse aus sieben DocQA-Benchmarks mit langem Kontext zeigten die Stärke von QwenLong-L1. Das Modell QWENLONG-L1-32B (basierend auf DeepSeek-R1-Distill-Qwen-32B) erreichte eine Leistung, die mit Anthropics Claude-3.7 Sonnet Thinking vergleichbar ist, und übertraf Modelle wie OpenAIs o3-mini und Qwen3-235B-A22B. Das kleinere Modell QWENLONG-L1-14B übertraf ebenfalls Gemini 2.0 Flash Thinking von Google und Qwen3-32B.
Quelle: arXiv Eine wichtige Erkenntnis für den Einsatz in der Praxis ist, wie RL-Training spezialisierte Verhaltensweisen für das Denken in langen Kontexten fördert. Die Studie hebt hervor, dass mit QwenLong-L1 trainierte Modelle sich in den Bereichen „Grounding” (Verknüpfung von Antworten mit bestimmten Dokumentabschnitten), „Subgoal Setting” (Aufschlüsselung komplexer Fragen), „Backtracking” (Identifizierung und Korrektur von Fehlern während des Denkprozesses) und „Verification” (Überprüfung der Antworten) verbessern.
Während ein Basismodell beispielsweise durch irrelevante Details in einem Finanzbericht aus der Bahn geworfen werden oder sich endlos in tangentialen Analysen verlieren könnte, zeigte ein mit QwenLong-L1 trainiertes Modell eine effektive Selbstreflexion. Es konnte ablenkende Informationen herausfiltern, falsche Ansätze zurückverfolgen und erfolgreich zur richtigen Schlussfolgerung gelangen.
Frameworks wie QwenLong-L1 könnten den Nutzen von KI für Unternehmen erheblich erweitern. Mögliche Anwendungsbereiche reichen von der Rechtstechnologie (Analyse umfangreicher Rechtsdokumente) über den Finanzbereich (Durchführung einer gründlichen Due Diligence von Jahresberichten und Finanzunterlagen für Risiko- oder Investitionsanalysen) bis hin zum Kundenservice (Überprüfung langer Interaktionshistorien, um kontextbezogenere Unterstützung zu bieten). Die Forscher haben den Code für das QwenLong-L1-Framework und die Gewichte für die trainierten Modelle öffentlich zugänglich gemacht.
Verwandter Artikel
 Snowflake investiert über 600 Millionen Dollar in maßgeschneiderte AWS-Chips für den Ausbau der KI im Unternehmensbereich
Snowflake, der Cloud-Datenriese, hat Pläne bekannt gegeben, in den nächsten sechs Jahren über 600 Millionen US-Dollar in den Erwerb von CPUs und KI-Beschleunigern der Graviton-Serie zu investieren, di
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Empfehlungen zu verwandten Spezialthemen
Schreiben
Snowflake investiert über 600 Millionen Dollar in maßgeschneiderte AWS-Chips für den Ausbau der KI im Unternehmensbereich
Snowflake, der Cloud-Datenriese, hat Pläne bekannt gegeben, in den nächsten sechs Jahren über 600 Millionen US-Dollar in den Erwerb von CPUs und KI-Beschleunigern der Graviton-Serie zu investieren, di
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Empfehlungen zu verwandten Spezialthemen
Schreiben
 Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
 10 Tools
10 Tools
 xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai
Code
Die besten KI-Generatoren für Chrome-Erweiterungen: Erstellen Sie individuelle Browser-Erweiterungen ganz ohne Programmierkenntnisse
Entdecken Sie die besten KI-Generatoren für Chrome-Erweiterungen des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, unverzichtbare Tools, mit denen Sie ganz ohne Programmierkenntnisse individuelle Browser-Erweiterungen erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich Praxistests an und steigern Sie Ihre Produktivität. Entdecken Sie die aktuellen Rankings und finden Sie noch heute das perfekte Tool für sich!
10 Tools
xix.ai
Text-zu-Sprache
Die beste künstliche Intelligenz für mehrsprachige TTS-Technologie: Erzeugung authentischer Sprache mit Muttersprachakzent in über 50 Sprachen
Entdecken Sie die besten KI-basierten, mehrsprachigen TTS-Tools von 2026 – sie ermöglichen eine authentische Aussprache in natürlicher Muttersprachentonart in über 50 Sprachen. Erfahren Sie mehr über unsere hochrangig bewerteten und sorgfältig ausgewählten Tools, inklusive Vergleichen zwischen kostenlosen und kostenpflichtigen Varianten sowie Ergebnissen aus realen Tests. Finden Sie das perfekte Tool für Ihre Bedürfnisse auf XIX.AI und öffnen Sie so neue Möglichkeiten für die globale Kommunikation – noch heute!
10 Tools
xix.ai
Besprechungsassistent
Die besten AI-Tools für die Automatisierung von Besprechungen – für eine schlauere und schnellere Zusammenarbeit
Entdecken Sie die besten und am meisten bewerteten AI-Tools für die Automatisierung von Besprechungen im Jahr 2026 – sie ermöglichen eine intelligente und schnellere Zusammenarbeit. Unsere sorgfältig ausgewählte Liste bietet leistungsstarke Lösungen, mit denen Sie Notizen, Zusammenfassungen und Aufgaben automatisch erstellen können. Vergleichen Sie kostenlose und bezahlte Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings – so steigern Sie die Produktivität Ihres Teams. Entdecken Sie die besten Tools jetzt bei XIX.AI.
10 Tools
xix.ai
Prompt
KI-Vorgaben für Infrastructure-as-Code: Terraform- und Docker-Konfigurationen sicher bereitstellen
Entdecken Sie die aktuellsten und am besten bewerteten KI-Prompts für Infrastructure-as-Code aus dem Jahr 2026. Die von XIX.AI zusammengestellte Auswahl hilft Ihnen dabei, Terraform- und Docker-Konfigurationen sicher bereitzustellen, Cloud-Setups zu automatisieren und die DevOps-Produktivität zu steigern. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entdecken Sie die Möglichkeiten jetzt und sichern Sie sich Ihren KI-Vorteil.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Die Alibaba Group hat QwenLong-L1 vorgestellt, ein neues Framework, das große Sprachmodelle (LLMs) in die Lage versetzt, außergewöhnlich lange Dokumente zu analysieren. Dieser Durchbruch hat das Potenzial, eine neue Generation von Unternehmensanwendungen voranzutreiben, die ein tiefes Verständnis und eine aufschlussreiche Analyse umfangreicher Materialien erfordern, darunter umfassende Unternehmensberichte, detaillierte Finanzberichte und komplexe rechtliche Vereinbarungen.
Das Hindernis der KI-Argumentation in Langform
Die jüngsten Fortschritte bei großen Schlussfolgerungsmodellen (LRMs), insbesondere durch verstärktes Lernen (RL), haben deren Problemlösungsfähigkeiten erheblich verbessert. Studien zeigen, dass RL-Feinabstimmung LRMs mit einer Form des „langsamen Denkens” ausstattet, die der menschlichen Kognition ähnelt und es ihnen ermöglicht, ausgefeilte Strategien für die Bewältigung komplexer Aufgaben zu entwickeln.
Diese Fortschritte beschränken sich jedoch weitgehend auf die Arbeit mit relativ kurzen Textpassagen, in der Regel etwa 4.000 Token. Eine erhebliche Hürde bleibt die Skalierung dieser Schlussfolgerungsfähigkeit auf weitaus längere Kontexte, beispielsweise 120.000 Token. Effektives Langzeit-Schlussfolgern erfordert ein solides Verständnis des gesamten Dokuments und die Fähigkeit zur mehrstufigen Analyse. „Diese Einschränkung behindert erheblich praktische Anwendungen, die externes Wissen erfordern, wie z. B. eingehende Recherchen, bei denen LRM Informationen aus datenreichen Quellen sammeln und verarbeiten müssen”, stellen die Entwickler von QwenLong-L1 in ihrer Forschungsarbeit fest.
Das Team fasst diese Hindernisse unter dem Begriff „Long-Context Reasoning RL“ zusammen. Im Gegensatz zum Kurzkontext-Schlussfolgern, das häufig das interne Wissen des Modells nutzt, erfordert dieser Ansatz, dass Modelle relevante Fakten in langen Eingaben genau finden und verankern. Nur dann können sie auf der Grundlage dieser abgerufenen Informationen logische Schlussfolgerungsketten aufbauen.
Das Training von Modellen für diesen Zweck mittels RL ist eine Herausforderung, die häufig zu ineffizientem Lernen und instabiler Optimierung führt. Modelle scheitern oft daran, zu effektiven Lösungen zu konvergieren, oder verlieren ihre Fähigkeit, verschiedene Argumentationswege zu erkunden.
QwenLong-L1: Ein strukturiertes, mehrstufiges Framework
QwenLong-L1 ist ein Framework für verstärktes Lernen, das entwickelt wurde, um LRMs dabei zu helfen, sich von der Verarbeitung kurzer Texte zu einer robusten Verallgemeinerung über lange Kontexte hinweg weiterzuentwickeln. Es verbessert bestehende LRMs für kurze Kontexte durch einen bewussten, schrittweisen Prozess:
Warm-up Supervised Fine-Tuning (SFT): Das Modell durchläuft zunächst ein SFT unter Verwendung von Beispielen für das Schlussfolgern in langen Kontexten. Diese Phase schafft eine solide Grundlage und lehrt das Modell, Informationen aus langen Dokumenten genau zu verankern und Kernkompetenzen im Kontextverständnis, in der Generierung logischer Ketten und in der Extraktion von Antworten zu entwickeln.
Curriculum-Guided Phased RL: Hier wird das Modell in mehreren Phasen trainiert, in denen die Länge der Zieldokumente schrittweise erhöht wird. Diese schrittweise, lehrplanbasierte Methode hilft dem Modell, seine Argumentationsstrategien stetig von kürzeren zu immer längeren Texten anzupassen, wodurch die Instabilität einer abrupten Konfrontation mit umfangreichen Dokumenten vermieden wird.
Schwierigkeitsbewusstes retrospektives Sampling: Die letzte Phase umfasst die anspruchsvollsten Beispiele aus früheren Trainingsphasen. Durch die Priorisierung schwieriger Fälle wird sichergestellt, dass das Modell weiterhin aus schwierigen Problemen lernt und dazu angeregt wird, vielfältigere und komplexere Schlussfolgerungswege zu erkunden.
Über dieses strukturierte Training hinaus verwendet QwenLong-L1 ein spezielles Belohnungssystem. Während beim Training für Aufgaben mit kurzem Kontext oft strenge regelbasierte Belohnungen verwendet werden (z. B. für eine richtige mathematische Antwort), verwendet QwenLong-L1 einen hybriden Mechanismus. Er kombiniert die regelbasierte Überprüfung der Genauigkeit mit einem „LLM-as-a-judge”, das die semantische Bedeutung der generierten Antwort mit der Referenz vergleicht. Dies ermöglicht eine größere Flexibilität bei der Bewertung der vielfältigen Möglichkeiten, wie richtige Antworten in langen, nuancierten Dokumenten formuliert werden können.
Bewertung der Leistung von QwenLong-L1
Das Alibaba-Team testete QwenLong-L1 in erster Linie anhand von Dokumenten-Frage-Antworten (DocQA), einer Aufgabe, die für Unternehmensanforderungen von großer Relevanz ist, bei der KI dichte Dokumente entschlüsseln muss, um komplexe Fragen zu beantworten.
Die Ergebnisse aus sieben DocQA-Benchmarks mit langem Kontext zeigten die Stärke von QwenLong-L1. Das Modell QWENLONG-L1-32B (basierend auf DeepSeek-R1-Distill-Qwen-32B) erreichte eine Leistung, die mit Anthropics Claude-3.7 Sonnet Thinking vergleichbar ist, und übertraf Modelle wie OpenAIs o3-mini und Qwen3-235B-A22B. Das kleinere Modell QWENLONG-L1-14B übertraf ebenfalls Gemini 2.0 Flash Thinking von Google und Qwen3-32B.
Eine wichtige Erkenntnis für den Einsatz in der Praxis ist, wie RL-Training spezialisierte Verhaltensweisen für das Denken in langen Kontexten fördert. Die Studie hebt hervor, dass mit QwenLong-L1 trainierte Modelle sich in den Bereichen „Grounding” (Verknüpfung von Antworten mit bestimmten Dokumentabschnitten), „Subgoal Setting” (Aufschlüsselung komplexer Fragen), „Backtracking” (Identifizierung und Korrektur von Fehlern während des Denkprozesses) und „Verification” (Überprüfung der Antworten) verbessern.
Während ein Basismodell beispielsweise durch irrelevante Details in einem Finanzbericht aus der Bahn geworfen werden oder sich endlos in tangentialen Analysen verlieren könnte, zeigte ein mit QwenLong-L1 trainiertes Modell eine effektive Selbstreflexion. Es konnte ablenkende Informationen herausfiltern, falsche Ansätze zurückverfolgen und erfolgreich zur richtigen Schlussfolgerung gelangen.
Frameworks wie QwenLong-L1 könnten den Nutzen von KI für Unternehmen erheblich erweitern. Mögliche Anwendungsbereiche reichen von der Rechtstechnologie (Analyse umfangreicher Rechtsdokumente) über den Finanzbereich (Durchführung einer gründlichen Due Diligence von Jahresberichten und Finanzunterlagen für Risiko- oder Investitionsanalysen) bis hin zum Kundenservice (Überprüfung langer Interaktionshistorien, um kontextbezogenere Unterstützung zu bieten). Die Forscher haben den Code für das QwenLong-L1-Framework und die Gewichte für die trainierten Modelle öffentlich zugänglich gemacht.










 Snowflake investiert über 600 Millionen Dollar in maßgeschneiderte AWS-Chips für den Ausbau der KI im Unternehmensbereich
Snowflake, der Cloud-Datenriese, hat Pläne bekannt gegeben, in den nächsten sechs Jahren über 600 Millionen US-Dollar in den Erwerb von CPUs und KI-Beschleunigern der Graviton-Serie zu investieren, di
Snowflake investiert über 600 Millionen Dollar in maßgeschneiderte AWS-Chips für den Ausbau der KI im Unternehmensbereich
Snowflake, der Cloud-Datenriese, hat Pläne bekannt gegeben, in den nächsten sechs Jahren über 600 Millionen US-Dollar in den Erwerb von CPUs und KI-Beschleunigern der Graviton-Serie zu investieren, di
 China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
 Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen

Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
10 Tools
xix.ai

Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai

Entdecken Sie die besten KI-Generatoren für Chrome-Erweiterungen des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, unverzichtbare Tools, mit denen Sie ganz ohne Programmierkenntnisse individuelle Browser-Erweiterungen erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich Praxistests an und steigern Sie Ihre Produktivität. Entdecken Sie die aktuellen Rankings und finden Sie noch heute das perfekte Tool für sich!
10 Tools
xix.ai

Entdecken Sie die besten KI-basierten, mehrsprachigen TTS-Tools von 2026 – sie ermöglichen eine authentische Aussprache in natürlicher Muttersprachentonart in über 50 Sprachen. Erfahren Sie mehr über unsere hochrangig bewerteten und sorgfältig ausgewählten Tools, inklusive Vergleichen zwischen kostenlosen und kostenpflichtigen Varianten sowie Ergebnissen aus realen Tests. Finden Sie das perfekte Tool für Ihre Bedürfnisse auf XIX.AI und öffnen Sie so neue Möglichkeiten für die globale Kommunikation – noch heute!
10 Tools
xix.ai

Entdecken Sie die besten und am meisten bewerteten AI-Tools für die Automatisierung von Besprechungen im Jahr 2026 – sie ermöglichen eine intelligente und schnellere Zusammenarbeit. Unsere sorgfältig ausgewählte Liste bietet leistungsstarke Lösungen, mit denen Sie Notizen, Zusammenfassungen und Aufgaben automatisch erstellen können. Vergleichen Sie kostenlose und bezahlte Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings – so steigern Sie die Produktivität Ihres Teams. Entdecken Sie die besten Tools jetzt bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie die aktuellsten und am besten bewerteten KI-Prompts für Infrastructure-as-Code aus dem Jahr 2026. Die von XIX.AI zusammengestellte Auswahl hilft Ihnen dabei, Terraform- und Docker-Konfigurationen sicher bereitzustellen, Cloud-Setups zu automatisieren und die DevOps-Produktivität zu steigern. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entdecken Sie die Möglichkeiten jetzt und sichern Sie sich Ihren KI-Vorteil.
10 Tools
xix.ai













