
















 Lar
Lar
Nvidia revela modelo de IA de código aberto Nemotron-Nano-9B-v2 com raciocínio alternável
Os modelos de linguagem pequenos estão causando impacto. Após o lançamento do modelo de visão do tamanho de um smartwatch da Liquid AI, uma spin-off do MIT, e da oferta pronta para smartphones do Google, a Nvidia agora entra em cena com seu próprio concorrente simplificado: o Nemotron-Nano-9B-V2. Esse novo modelo lidera sua classe em benchmarks importantes e apresenta um recurso exclusivo que permite aos usuários ativar ou desativar o “raciocínio” da IA — essencialmente um processo de autoverificação antes de fornecer uma resposta final.
Embora 9 bilhões de parâmetros excedam a escala dos micromodelos com milhões de parâmetros sobre os quais relatamos recentemente, a Nvidia destaca isso como uma otimização significativa em relação aos seus 12 bilhões de parâmetros originais. O tamanho revisado foi projetado especificamente para rodar em uma única GPU Nvidia A10 amplamente disponível.
Como Oleksii Kuchiaev, diretor de pós-treinamento de modelos de IA da Nvidia, explicou em resposta a uma pergunta no X: “Reduzimos o modelo de 12 bilhões para 9 bilhões para se encaixar perfeitamente na A10, uma GPU de implantação popular. É também uma arquitetura híbrida, o que permite lidar com tamanhos de lote maiores e atingir velocidades até seis vezes mais rápidas do que os modelos transformadores tradicionais de tamanho semelhante.”
Para se ter uma perspectiva, muitos modelos de linguagem grandes líderes operam na faixa de mais de 70 bilhões de parâmetros. Os parâmetros são as configurações internas que definem o comportamento de um modelo, onde contagens mais altas normalmente indicam maior capacidade, mas também exigem significativamente mais poder computacional.
O modelo suporta vários idiomas, incluindo inglês, alemão, espanhol, francês, italiano e japonês. Recursos estendidos também abrangem coreano, português, russo e chinês. É adequado para tarefas que vão desde seguir instruções até gerar código.
O Nemotron-Nano-9B-V2 e seus conjuntos de dados de pré-treinamento estão disponíveis atualmente no Hugging Face e no catálogo de modelos da Nvidia.
Uma fusão das arquiteturas Transformer e Mamba
O modelo é baseado no Nemotron-H, uma família de modelos híbridos Mamba-Transformer que servem de base para as mais recentes ofertas de IA da Nvidia.
Embora os LLMs dominantes normalmente dependam exclusivamente da arquitetura Transformer e seus mecanismos de atenção, eles podem se tornar proibitivamente caros em termos de memória e computação à medida que o comprimento das sequências de entrada aumenta.
Os modelos Nemotron-H e outros que utilizam a arquitetura Mamba — pioneira dos pesquisadores da Carnegie Mellon University e Princeton — incorporam modelos de espaço de estado seletivo (SSMs). Esses SSMs gerenciam com eficiência sequências extremamente longas, mantendo um estado interno.
Essas camadas são dimensionadas linearmente com o comprimento da sequência, permitindo que processem contextos muito mais longos do que a autoatenção padrão, sem a mesma sobrecarga computacional.
Um design híbrido Mamba-Transformer reduz os custos ao substituir a maioria das camadas de atenção por camadas de espaço de estado de tempo linear. Isso pode render um rendimento até 2 a 3 vezes maior em tarefas de contexto longo, mantendo uma precisão comparável.
A Nvidia não está sozinha nessa abordagem; outros laboratórios de pesquisa em IA, como o AI2, também lançaram modelos baseados na arquitetura Mamba.
Ative ou desative o raciocínio com comandos simples
O Nemotron-Nano-9B-v2 foi projetado como um modelo unificado, somente de texto, capaz de interação conversacional e raciocínio complexo, treinado inteiramente do zero.
Por padrão, o sistema gera um rastreamento detalhado do raciocínio antes de produzir sua resposta final. Os usuários podem controlar esse comportamento usando tokens de comando simples, como /think ou /no_think.
O modelo também introduz o gerenciamento de “orçamento de raciocínio” em tempo de execução. Isso permite que os desenvolvedores definam um limite máximo para o número de tokens que o modelo pode usar para raciocínio interno antes de ter que entregar uma resposta.
Esse mecanismo tem como objetivo equilibrar a precisão com a latência da resposta, o que é crucial para aplicativos como chatbots de suporte ao cliente ou agentes autônomos.
Benchmarks mostram forte desempenho
Os resultados da avaliação demonstram precisão competitiva em relação a outros modelos abertos de pequena escala líderes. Quando testado com raciocínio habilitado usando o pacote NeMo-Skills, o Nemotron-Nano-9B-v2 alcançou pontuações de 72,1% no AIME25, 97,8% no MATH500, 64,0% no GPQA e 71,1% no LiveCodeBench.
As pontuações nos benchmarks de seguimento de instruções e contexto longo também são fortes: 90,3% no IFEval e 78,9% no teste RULER 128K, com ganhos mensuráveis adicionais no BFCL v3 e no benchmark HLE.
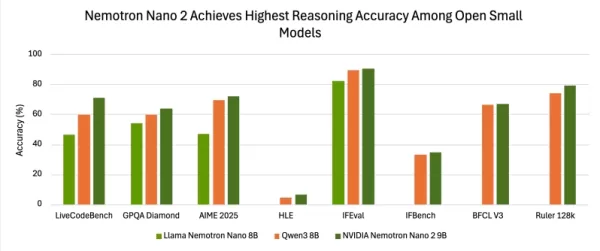
Em várias avaliações, o Nano-9B-v2 mostra consistentemente uma precisão maior do que um ponto de comparação comum, o modelo Qwen3-8B.
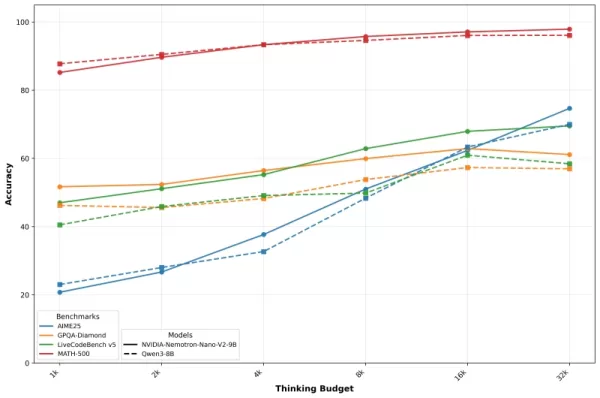
A Nvidia apresenta esses resultados com curvas de precisão versus orçamento que ilustram como o desempenho melhora à medida que a permissão de tokens para raciocínio aumenta. A empresa observa que o controle cuidadoso do orçamento permite que os desenvolvedores otimizem a qualidade e a velocidade em ambientes de produção.
Treinado em conjuntos de dados sintéticos
Tanto o modelo Nano quanto a família Nemotron-H mais ampla são treinados em uma mistura de dados da web cuidadosamente selecionados, fontes proprietárias e dados de treinamento sintéticos.
O corpus de treinamento inclui textos gerais, códigos, matemática, literatura científica, documentos jurídicos e financeiros, bem como conjuntos de dados de perguntas e respostas com foco no alinhamento.
A Nvidia confirma o uso de traços de raciocínio sintéticos gerados por outros modelos grandes para melhorar o desempenho em tarefas de benchmark complexas.
Licenciamento e uso comercial
O modelo Nano-9B-v2 é lançado sob o Contrato de Licença de Modelo Aberto da Nvidia, que foi atualizado pela última vez em junho de 2025.
Esta licença foi concebida para ser permissiva e favorável às empresas. A Nvidia afirma explicitamente que os modelos são comercialmente utilizáveis imediatamente e que os desenvolvedores são livres para criar e distribuir trabalhos derivados.
Fundamentalmente, a Nvidia não reivindica a propriedade de quaisquer resultados gerados pelo modelo, deixando todos os direitos e responsabilidades com o desenvolvedor ou organização que o utiliza.
Para desenvolvedores empresariais, isso significa que o modelo pode ser implantado em produção imediatamente, sem a necessidade de negociar uma licença comercial separada ou pagar taxas com base no volume de uso, receita ou número de usuários. Ao contrário de algumas licenças abertas em camadas de outros fornecedores, não há cláusulas que exijam o pagamento de uma licença quando uma empresa atinge um determinado tamanho.
Dito isso, o contrato inclui várias condições importantes que as empresas devem seguir:
- Barreiras de proteção: os usuários não podem contornar ou desativar os mecanismos de segurança integrados (conhecidos como “barreiras de proteção”) sem implementar substitutos adequados e equivalentes para sua implantação específica.
- Redistribuição: qualquer redistribuição do modelo ou de seus derivados deve incluir o texto completo da Licença de Modelo Aberto da Nvidia e a atribuição adequada (“Licenciado pela Nvidia Corporation sob a Licença de Modelo Aberto da Nvidia”).
- Conformidade: os usuários devem cumprir todas as regulamentações e restrições comerciais aplicáveis, como as leis de controle de exportação dos EUA.
- Termos de IA confiável: o uso deve estar alinhado com as diretrizes de IA confiável da Nvidia, que abrangem princípios para implantação responsável e considerações éticas.
- Cláusula de litígio: a licença é automaticamente rescindida se um usuário iniciar um litígio de direitos autorais ou patentes contra outra parte, alegando violação relacionada ao modelo.
Essas condições se concentram em garantir a conformidade legal e o uso responsável, em vez de restringir a escala comercial. As empresas não precisam solicitar permissão adicional ou pagar royalties à Nvidia para criar produtos, monetizar serviços ou ampliar sua base de usuários. Em vez disso, elas devem garantir que suas práticas de implantação respeitem a segurança, forneçam a atribuição adequada e cumpram todas as obrigações de conformidade.
Posicionamento no mercado
Com o Nemotron-Nano-9B-v2, a Nvidia tem como alvo desenvolvedores que precisam equilibrar a capacidade de raciocínio com a eficiência de implantação em menor escala.
Os recursos de controle de orçamento de tempo de execução e alternância de raciocínio foram projetados para dar aos criadores de sistemas maior flexibilidade no gerenciamento do equilíbrio entre precisão e velocidade de resposta.
Sua disponibilidade no Hugging Face e no catálogo de modelos da Nvidia sinaliza uma intenção de ampla acessibilidade, incentivando a experimentação e a integração.
O lançamento do Nemotron-Nano-9B-v2 pela Nvidia ressalta o foco contínuo da empresa em eficiência e raciocínio controlável em modelos de linguagem.
Ao combinar arquiteturas híbridas com técnicas avançadas de compressão e treinamento, a Nvidia visa fornecer aos desenvolvedores ferramentas que mantêm alta precisão e, ao mesmo tempo, reduzem os custos operacionais e a latência.
Artigo relacionado
 A variante OpenClaw da Nvidia pode resolver seu maior desafio: a segurança
O CEO da Nvidia, Jensen Huang, acredita que toda empresa precisa de uma estratégia OpenClaw — e a Nvidia está pronta para fornecê-la.Durante sua palestra na GTC na segunda-feira, Huang anunciou que a
O Pentágono assinou acordos com a Nvidia, a Microsoft e a AWS para implementar inteligência artificial em redes confidenciais.
Após alcançar acordos anteriores com a Google, a SpaceX e a OpenAI, o Departamento de Defesa dos EUA anunciou na sexta-feira que assinou contratos com a Nvidia, a Microsoft, a Amazon Web Services e a Reflection AI para utilizar suas tecnologias e mod
A Nvidia GTC apresenta o NemoClaw, o robô Olaf e uma aposta de US$ 1 trilhão
Carregando o player…O CEO Jensen Huang subiu ao palco na conferência GTC da Nvidia nesta semana, vestindo sua jaqueta de couro característica, para proferir uma palestra de duas horas e meia, projetan
Recomendações de tópicos especiais relacionados
Criação de quadrinhos
A variante OpenClaw da Nvidia pode resolver seu maior desafio: a segurança
O CEO da Nvidia, Jensen Huang, acredita que toda empresa precisa de uma estratégia OpenClaw — e a Nvidia está pronta para fornecê-la.Durante sua palestra na GTC na segunda-feira, Huang anunciou que a
O Pentágono assinou acordos com a Nvidia, a Microsoft e a AWS para implementar inteligência artificial em redes confidenciais.
Após alcançar acordos anteriores com a Google, a SpaceX e a OpenAI, o Departamento de Defesa dos EUA anunciou na sexta-feira que assinou contratos com a Nvidia, a Microsoft, a Amazon Web Services e a Reflection AI para utilizar suas tecnologias e mod
A Nvidia GTC apresenta o NemoClaw, o robô Olaf e uma aposta de US$ 1 trilhão
Carregando o player…O CEO Jensen Huang subiu ao palco na conferência GTC da Nvidia nesta semana, vestindo sua jaqueta de couro característica, para proferir uma palestra de duas horas e meia, projetan
Recomendações de tópicos especiais relacionados
Criação de quadrinhos
 Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
 15 ferramentas
15 ferramentas
 xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

 Comentários (1)
Comentários (1)
![DanielThomas]()
이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.
Os modelos de linguagem pequenos estão causando impacto. Após o lançamento do modelo de visão do tamanho de um smartwatch da Liquid AI, uma spin-off do MIT, e da oferta pronta para smartphones do Google, a Nvidia agora entra em cena com seu próprio concorrente simplificado: o Nemotron-Nano-9B-V2. Esse novo modelo lidera sua classe em benchmarks importantes e apresenta um recurso exclusivo que permite aos usuários ativar ou desativar o “raciocínio” da IA — essencialmente um processo de autoverificação antes de fornecer uma resposta final.
Embora 9 bilhões de parâmetros excedam a escala dos micromodelos com milhões de parâmetros sobre os quais relatamos recentemente, a Nvidia destaca isso como uma otimização significativa em relação aos seus 12 bilhões de parâmetros originais. O tamanho revisado foi projetado especificamente para rodar em uma única GPU Nvidia A10 amplamente disponível.
Como Oleksii Kuchiaev, diretor de pós-treinamento de modelos de IA da Nvidia, explicou em resposta a uma pergunta no X: “Reduzimos o modelo de 12 bilhões para 9 bilhões para se encaixar perfeitamente na A10, uma GPU de implantação popular. É também uma arquitetura híbrida, o que permite lidar com tamanhos de lote maiores e atingir velocidades até seis vezes mais rápidas do que os modelos transformadores tradicionais de tamanho semelhante.”
Para se ter uma perspectiva, muitos modelos de linguagem grandes líderes operam na faixa de mais de 70 bilhões de parâmetros. Os parâmetros são as configurações internas que definem o comportamento de um modelo, onde contagens mais altas normalmente indicam maior capacidade, mas também exigem significativamente mais poder computacional.
O modelo suporta vários idiomas, incluindo inglês, alemão, espanhol, francês, italiano e japonês. Recursos estendidos também abrangem coreano, português, russo e chinês. É adequado para tarefas que vão desde seguir instruções até gerar código.
O Nemotron-Nano-9B-V2 e seus conjuntos de dados de pré-treinamento estão disponíveis atualmente no Hugging Face e no catálogo de modelos da Nvidia.
Uma fusão das arquiteturas Transformer e Mamba
O modelo é baseado no Nemotron-H, uma família de modelos híbridos Mamba-Transformer que servem de base para as mais recentes ofertas de IA da Nvidia.
Embora os LLMs dominantes normalmente dependam exclusivamente da arquitetura Transformer e seus mecanismos de atenção, eles podem se tornar proibitivamente caros em termos de memória e computação à medida que o comprimento das sequências de entrada aumenta.
Os modelos Nemotron-H e outros que utilizam a arquitetura Mamba — pioneira dos pesquisadores da Carnegie Mellon University e Princeton — incorporam modelos de espaço de estado seletivo (SSMs). Esses SSMs gerenciam com eficiência sequências extremamente longas, mantendo um estado interno.
Essas camadas são dimensionadas linearmente com o comprimento da sequência, permitindo que processem contextos muito mais longos do que a autoatenção padrão, sem a mesma sobrecarga computacional.
Um design híbrido Mamba-Transformer reduz os custos ao substituir a maioria das camadas de atenção por camadas de espaço de estado de tempo linear. Isso pode render um rendimento até 2 a 3 vezes maior em tarefas de contexto longo, mantendo uma precisão comparável.
A Nvidia não está sozinha nessa abordagem; outros laboratórios de pesquisa em IA, como o AI2, também lançaram modelos baseados na arquitetura Mamba.
Ative ou desative o raciocínio com comandos simples
O Nemotron-Nano-9B-v2 foi projetado como um modelo unificado, somente de texto, capaz de interação conversacional e raciocínio complexo, treinado inteiramente do zero.
Por padrão, o sistema gera um rastreamento detalhado do raciocínio antes de produzir sua resposta final. Os usuários podem controlar esse comportamento usando tokens de comando simples, como /think ou /no_think.
O modelo também introduz o gerenciamento de “orçamento de raciocínio” em tempo de execução. Isso permite que os desenvolvedores definam um limite máximo para o número de tokens que o modelo pode usar para raciocínio interno antes de ter que entregar uma resposta.
Esse mecanismo tem como objetivo equilibrar a precisão com a latência da resposta, o que é crucial para aplicativos como chatbots de suporte ao cliente ou agentes autônomos.
Benchmarks mostram forte desempenho
Os resultados da avaliação demonstram precisão competitiva em relação a outros modelos abertos de pequena escala líderes. Quando testado com raciocínio habilitado usando o pacote NeMo-Skills, o Nemotron-Nano-9B-v2 alcançou pontuações de 72,1% no AIME25, 97,8% no MATH500, 64,0% no GPQA e 71,1% no LiveCodeBench.
As pontuações nos benchmarks de seguimento de instruções e contexto longo também são fortes: 90,3% no IFEval e 78,9% no teste RULER 128K, com ganhos mensuráveis adicionais no BFCL v3 e no benchmark HLE.
Em várias avaliações, o Nano-9B-v2 mostra consistentemente uma precisão maior do que um ponto de comparação comum, o modelo Qwen3-8B.
A Nvidia apresenta esses resultados com curvas de precisão versus orçamento que ilustram como o desempenho melhora à medida que a permissão de tokens para raciocínio aumenta. A empresa observa que o controle cuidadoso do orçamento permite que os desenvolvedores otimizem a qualidade e a velocidade em ambientes de produção.
Treinado em conjuntos de dados sintéticos
Tanto o modelo Nano quanto a família Nemotron-H mais ampla são treinados em uma mistura de dados da web cuidadosamente selecionados, fontes proprietárias e dados de treinamento sintéticos.
O corpus de treinamento inclui textos gerais, códigos, matemática, literatura científica, documentos jurídicos e financeiros, bem como conjuntos de dados de perguntas e respostas com foco no alinhamento.
A Nvidia confirma o uso de traços de raciocínio sintéticos gerados por outros modelos grandes para melhorar o desempenho em tarefas de benchmark complexas.
Licenciamento e uso comercial
O modelo Nano-9B-v2 é lançado sob o Contrato de Licença de Modelo Aberto da Nvidia, que foi atualizado pela última vez em junho de 2025.
Esta licença foi concebida para ser permissiva e favorável às empresas. A Nvidia afirma explicitamente que os modelos são comercialmente utilizáveis imediatamente e que os desenvolvedores são livres para criar e distribuir trabalhos derivados.
Fundamentalmente, a Nvidia não reivindica a propriedade de quaisquer resultados gerados pelo modelo, deixando todos os direitos e responsabilidades com o desenvolvedor ou organização que o utiliza.
Para desenvolvedores empresariais, isso significa que o modelo pode ser implantado em produção imediatamente, sem a necessidade de negociar uma licença comercial separada ou pagar taxas com base no volume de uso, receita ou número de usuários. Ao contrário de algumas licenças abertas em camadas de outros fornecedores, não há cláusulas que exijam o pagamento de uma licença quando uma empresa atinge um determinado tamanho.
Dito isso, o contrato inclui várias condições importantes que as empresas devem seguir:
- Barreiras de proteção: os usuários não podem contornar ou desativar os mecanismos de segurança integrados (conhecidos como “barreiras de proteção”) sem implementar substitutos adequados e equivalentes para sua implantação específica.
- Redistribuição: qualquer redistribuição do modelo ou de seus derivados deve incluir o texto completo da Licença de Modelo Aberto da Nvidia e a atribuição adequada (“Licenciado pela Nvidia Corporation sob a Licença de Modelo Aberto da Nvidia”).
- Conformidade: os usuários devem cumprir todas as regulamentações e restrições comerciais aplicáveis, como as leis de controle de exportação dos EUA.
- Termos de IA confiável: o uso deve estar alinhado com as diretrizes de IA confiável da Nvidia, que abrangem princípios para implantação responsável e considerações éticas.
- Cláusula de litígio: a licença é automaticamente rescindida se um usuário iniciar um litígio de direitos autorais ou patentes contra outra parte, alegando violação relacionada ao modelo.
Essas condições se concentram em garantir a conformidade legal e o uso responsável, em vez de restringir a escala comercial. As empresas não precisam solicitar permissão adicional ou pagar royalties à Nvidia para criar produtos, monetizar serviços ou ampliar sua base de usuários. Em vez disso, elas devem garantir que suas práticas de implantação respeitem a segurança, forneçam a atribuição adequada e cumpram todas as obrigações de conformidade.
Posicionamento no mercado
Com o Nemotron-Nano-9B-v2, a Nvidia tem como alvo desenvolvedores que precisam equilibrar a capacidade de raciocínio com a eficiência de implantação em menor escala.
Os recursos de controle de orçamento de tempo de execução e alternância de raciocínio foram projetados para dar aos criadores de sistemas maior flexibilidade no gerenciamento do equilíbrio entre precisão e velocidade de resposta.
Sua disponibilidade no Hugging Face e no catálogo de modelos da Nvidia sinaliza uma intenção de ampla acessibilidade, incentivando a experimentação e a integração.
O lançamento do Nemotron-Nano-9B-v2 pela Nvidia ressalta o foco contínuo da empresa em eficiência e raciocínio controlável em modelos de linguagem.
Ao combinar arquiteturas híbridas com técnicas avançadas de compressão e treinamento, a Nvidia visa fornecer aos desenvolvedores ferramentas que mantêm alta precisão e, ao mesmo tempo, reduzem os custos operacionais e a latência.










 A variante OpenClaw da Nvidia pode resolver seu maior desafio: a segurança
O CEO da Nvidia, Jensen Huang, acredita que toda empresa precisa de uma estratégia OpenClaw — e a Nvidia está pronta para fornecê-la.Durante sua palestra na GTC na segunda-feira, Huang anunciou que a
A variante OpenClaw da Nvidia pode resolver seu maior desafio: a segurança
O CEO da Nvidia, Jensen Huang, acredita que toda empresa precisa de uma estratégia OpenClaw — e a Nvidia está pronta para fornecê-la.Durante sua palestra na GTC na segunda-feira, Huang anunciou que a
 O Pentágono assinou acordos com a Nvidia, a Microsoft e a AWS para implementar inteligência artificial em redes confidenciais.
Após alcançar acordos anteriores com a Google, a SpaceX e a OpenAI, o Departamento de Defesa dos EUA anunciou na sexta-feira que assinou contratos com a Nvidia, a Microsoft, a Amazon Web Services e a Reflection AI para utilizar suas tecnologias e mod
O Pentágono assinou acordos com a Nvidia, a Microsoft e a AWS para implementar inteligência artificial em redes confidenciais.
Após alcançar acordos anteriores com a Google, a SpaceX e a OpenAI, o Departamento de Defesa dos EUA anunciou na sexta-feira que assinou contratos com a Nvidia, a Microsoft, a Amazon Web Services e a Reflection AI para utilizar suas tecnologias e mod
 A Nvidia GTC apresenta o NemoClaw, o robô Olaf e uma aposta de US$ 1 trilhão
Carregando o player…O CEO Jensen Huang subiu ao palco na conferência GTC da Nvidia nesta semana, vestindo sua jaqueta de couro característica, para proferir uma palestra de duas horas e meia, projetan
A Nvidia GTC apresenta o NemoClaw, o robô Olaf e uma aposta de US$ 1 trilhão
Carregando o player…O CEO Jensen Huang subiu ao palco na conferência GTC da Nvidia nesta semana, vestindo sua jaqueta de couro característica, para proferir uma palestra de duas horas e meia, projetan

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.













