




"कम अधिक है: कम दस्तावेजों को कैसे पुनर्प्राप्त करना एआई प्रतिक्रियाओं को बढ़ाता है"
पुनर्प्राप्ति-संवर्धित जनन (RAG) एक नवोन्मेषी दृष्टिकोण है जो AI सिस्टम बनाने के लिए उपयोग किया जाता है, जिसमें एक भाषा मॉडल को बाहरी ज्ञान स्रोत के साथ जोड़ा जाता है ताकि सटीकता बढ़ाई जा सके और तथ्यात्मक त्रुटियों को कम किया जा सके। संक्षेप में, AI उपयोगकर्ता के प्रश्न से संबंधित प्रासंगिक दस्तावेजों की खोज करता है और इस जानकारी का उपयोग करके अधिक सटीक प्रतिक्रिया उत्पन्न करता है। इस विधि को बड़े भाषा मॉडल्स (LLMs) को वास्तविक डेटा में आधारित रखने और भ्रम (hallucinations) के जोखिम को कम करने की क्षमता के लिए मान्यता प्राप्त हुई है।
आप यह मान सकते हैं कि AI को अधिक दस्तावेज प्रदान करने से बेहतर सूचित उत्तर प्राप्त होंगे। हालांकि, येरुशलम के हिब्रू विश्वविद्यालय के एक हालिया अध्ययन से पता चलता है कि ऐसा नहीं है: AI को जानकारी प्रदान करने के मामले में, कम वास्तव में अधिक हो सकता है।
कम दस्तावेज, बेहतर उत्तर
अध्ययन में यह जांच की गई कि RAG सिस्टम को प्रदान किए गए दस्तावेजों की संख्या इसके प्रदर्शन को कैसे प्रभावित करती है। शोधकर्ताओं ने कुल पाठ की लंबाई को स्थिर रखा, दस्तावेजों की संख्या को 20 से घटाकर 2-4 प्रासंगिक दस्तावेजों तक समायोजित किया और इनका विस्तार करके मूल पाठ की मात्रा से मेल खाया। इससे उन्हें दस्तावेजों की मात्रा के प्रभाव को अलग करने में मदद मिली।
म्यूसिक डेटासेट (MuSiQue) का उपयोग करके, जिसमें ट्रिविया प्रश्नों के साथ विकिपीडिया पैराग्राफ जोड़े गए हैं, उन्होंने पाया कि AI मॉडल अक्सर कम दस्तावेजों के साथ बेहतर प्रदर्शन करते हैं। सटीकता में 10% तक सुधार (F1 स्कोर द्वारा मापा गया) हुआ जब सिस्टम ने केवल कुछ प्रमुख दस्तावेजों पर ध्यान केंद्रित किया, न कि व्यापक संग्रह पर। यह प्रवृत्ति विभिन्न ओपन-सोर्स भाषा मॉडलों, जैसे मेटा के लामा (Llama), में देखी गई, जिसमें Qwen-2 एक उल्लेखनीय अपवाद था, जो कई दस्तावेजों के साथ अपना प्रदर्शन बनाए रखता था।
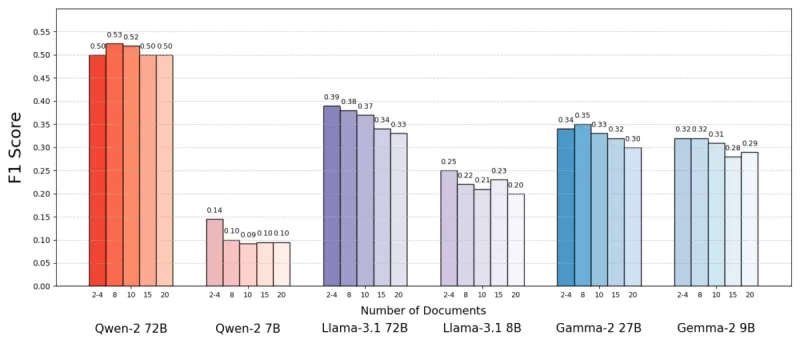 स्रोत: लेवी एट अल।
स्रोत: लेवी एट अल।
यह आश्चर्यजनक परिणाम इस सामान्य धारणा को चुनौती देता है कि अधिक जानकारी हमेशा मदद करती है। समान पाठ की मात्रा के बावजूद, कई दस्तावेजों की उपस्थिति ने AI के कार्य को जटिल बना दिया, जिससे सिग्नल की तुलना में अधिक शोर उत्पन्न हुआ।
RAG में कम क्यों हो सकता है अधिक
"कम है अधिक" सिद्धांत तब समझ में आता है जब हम विचार करते हैं कि AI मॉडल जानकारी को कैसे संसाधित करते हैं। कम, अधिक प्रासंगिक दस्तावेजों के साथ, AI बिना किसी विचलन के आवश्यक संदर्भ पर ध्यान केंद्रित कर सकता है, ठीक वैसे ही जैसे एक छात्र सबसे प्रासंगिक सामग्री का अध्ययन करता है।
अध्ययन में, मॉडल तब बेहतर प्रदर्शन करते थे जब उन्हें केवल उत्तर से सीधे संबंधित दस्तावेज दिए गए, क्योंकि यह स्वच्छ, केंद्रित संदर्भ सही जानकारी निकालना आसान बनाता था। इसके विपरीत, जब AI को कई दस्तावेजों के माध्यम से छानबीन करनी पड़ी, तो यह अक्सर प्रासंगिक और अप्रासंगिक सामग्री के मिश्रण से जूझता था। समान लेकिन असंबंधित दस्तावेज मॉडल को गुमराह कर सकते थे, जिससे भ्रम का जोखिम बढ़ गया।
दिलचस्प बात यह है कि अध्ययन में पाया गया कि AI स्पष्ट रूप से अप्रासंगिक दस्तावेजों को अनदेखा करना आसान पाता है, जबकि सूक्ष्म रूप से ऑफ-टॉपिक दस्तावेज अधिक भ्रमित करने वाले थे। यह सुझाव देता है कि यथार्थवादी विचलन (distractors) बेतरतीब वाले से अधिक भ्रामक हैं। केवल आवश्यक दस्तावेजों तक सीमित करके, हम ऐसे जाल सेट करने की संभावना को कम करते हैं।
इसके अतिरिक्त, कम दस्तावेजों का उपयोग करने से कम्प्यूटेशनल ओवरहेड कम होता है, जिससे सिस्टम अधिक कुशल और लागत-प्रभावी बनता है। यह दृष्टिकोण न केवल सटीकता में सुधार करता है बल्कि RAG सिस्टम के समग्र प्रदर्शन को भी बढ़ाता है।
 स्रोत: लेवी एट अल।
स्रोत: लेवी एट अल।
RAG पर पुनर्विचार: भविष्य की दिशाएँ
ये निष्कर्ष भविष्य के AI सिस्टमों के डिज़ाइन के लिए महत्वपूर्ण निहितार्थ रखते हैं जो बाहरी ज्ञान पर निर्भर करते हैं। यह सुझाव देता है कि पुनर्प्राप्त दस्तावेजों की गुणवत्ता और प्रासंगिकता पर ध्यान देना, उनकी मात्रा के बजाय, प्रदर्शन को बढ़ा सकता है। अध्ययन के लेखक पुनर्प्राप्ति विधियों की वकालत करते हैं जो प्रासंगिकता और विविधता को संतुलित करती हैं, ताकि मॉडल को अनावश्यक पाठ से अभिभूत किए बिना व्यापक कवरेज सुनिश्चित हो।
भविष्य के शोध में बेहतर पुनर्प्राप्ति सिस्टम या री-रैंकर्स की खोज हो सकती है ताकि वास्तव में मूल्यवान दस्तावेजों की पहचान की जा सके और भाषा मॉडल्स कई स्रोतों को संभालने में सुधार कर सकें। मॉडल्स को स्वयं बेहतर बनाना, जैसा कि Qwen-2 के साथ देखा गया, विविध इनपुट्स के प्रति उन्हें अधिक मजबूत बनाने में अंतर्दृष्टि प्रदान कर सकता है।
जैसे-जैसे AI सिस्टम बड़े संदर्भ खिड़कियों (context windows) को विकसित करते हैं, अधिक पाठ को एक साथ संसाधित करने की क्षमता कम महत्वपूर्ण हो जाती है, बनिस्पत यह सुनिश्चित करने के कि पाठ प्रासंगिक और चयनित हो। "अधिक दस्तावेज, समान लंबाई" शीर्षक वाला यह अध्ययन AI की सटीकता और दक्षता में सुधार के लिए सबसे प्रासंगिक जानकारी पर ध्यान केंद्रित करने के महत्व को रेखांकित करता है।
निष्कर्ष में, यह शोध AI सिस्टमों में डेटा इनपुट के बारे में हमारी धारणाओं को चुनौती देता है। कम, बेहतर दस्तावेजों का सावधानीपूर्वक चयन करके, हम अधिक स्मार्ट, हल्के RAG सिस्टम बना सकते हैं जो अधिक सटीक और भरोसेमंद उत्तर प्रदान करते हैं।
संबंधित लेख
 अमेज़न की डैनियल पर्सज़िक टेकक्रंच सेशंस: AI में बोलेंगी
हमें यह साझा करते हुए खुशी हो रही है कि डैनियल पर्सज़िक, अमेज़न AGI SF लैब की मानव-कंप्यूटर इंटरैक्शन टीम की प्रमुख, 5 जून को UC बर्कले के ज़ेलरबैक हॉल में टेकक्रंच सेशंस: AI में बोलेंगी। AGI SF लैब व
नाई की दुकान की बुकिंग को मुफ्त AI उपकरणों के साथ सरल बनाएं
आज की तेजी से बदलती दुनिया में, स्वचालन दक्षता की कुंजी है। कल्पना करें कि AI का उपयोग करके अपनी नाई की दुकान की नियुक्तियों को आसानी से प्रबंधित किया जाए। यह मार्गदर्शिका बताती है कि AI एजेंट और वेब
Audible Boosts AI-Narrated Audiobook Offerings with New Publisher Partnerships
Audible, Amazon का ऑडियोबुक मंच, ने मंगलवार को चुनिंदा प्रकाशकों के साथ सहयोग की घोषणा की ताकि प्रिंट और ई-बुक्स को AI-नैरेटेड ऑडियोबुक्स में बदला जा सके। यह कदम Apple, Spotify और ऑडियोबुक उद्योग में
सूचना (46)
0/200
अमेज़न की डैनियल पर्सज़िक टेकक्रंच सेशंस: AI में बोलेंगी
हमें यह साझा करते हुए खुशी हो रही है कि डैनियल पर्सज़िक, अमेज़न AGI SF लैब की मानव-कंप्यूटर इंटरैक्शन टीम की प्रमुख, 5 जून को UC बर्कले के ज़ेलरबैक हॉल में टेकक्रंच सेशंस: AI में बोलेंगी। AGI SF लैब व
नाई की दुकान की बुकिंग को मुफ्त AI उपकरणों के साथ सरल बनाएं
आज की तेजी से बदलती दुनिया में, स्वचालन दक्षता की कुंजी है। कल्पना करें कि AI का उपयोग करके अपनी नाई की दुकान की नियुक्तियों को आसानी से प्रबंधित किया जाए। यह मार्गदर्शिका बताती है कि AI एजेंट और वेब
Audible Boosts AI-Narrated Audiobook Offerings with New Publisher Partnerships
Audible, Amazon का ऑडियोबुक मंच, ने मंगलवार को चुनिंदा प्रकाशकों के साथ सहयोग की घोषणा की ताकि प्रिंट और ई-बुक्स को AI-नैरेटेड ऑडियोबुक्स में बदला जा सके। यह कदम Apple, Spotify और ऑडियोबुक उद्योग में
सूचना (46)
0/200
![BruceBrown]() BruceBrown
BruceBrown
 29 जुलाई 2025 5:55:16 अपराह्न IST
29 जुलाई 2025 5:55:16 अपराह्न IST
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?


 0
0
![JasonMartin]() JasonMartin
26 अप्रैल 2025 11:34:32 पूर्वाह्न IST
JasonMartin
26 अप्रैल 2025 11:34:32 पूर्वाह्न IST
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
![JuanMoore]() JuanMoore
24 अप्रैल 2025 3:59:07 पूर्वाह्न IST
JuanMoore
24 अप्रैल 2025 3:59:07 पूर्वाह्न IST
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
![GregoryJones]() GregoryJones
22 अप्रैल 2025 10:20:26 अपराह्न IST
GregoryJones
22 अप्रैल 2025 10:20:26 अपराह्न IST
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
![BrianMartinez]() BrianMartinez
21 अप्रैल 2025 4:44:10 अपराह्न IST
BrianMartinez
21 अप्रैल 2025 4:44:10 अपराह्न IST
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0
![GaryWilson]() GaryWilson
21 अप्रैल 2025 2:09:06 अपराह्न IST
GaryWilson
21 अप्रैल 2025 2:09:06 अपराह्न IST
AI 응답에서 '적을수록 좋다'는 접근 방식이 꽤 멋지네요! 적은 문서로도 정확한 답변을 얻다니, 가입하고 싶어요! 마법 같지만, 좀 더 빨리 작동했으면 좋겠어요. 그래도 AI 기술의 발전 단계로는 훌륭해요! 🚀
0
पुनर्प्राप्ति-संवर्धित जनन (RAG) एक नवोन्मेषी दृष्टिकोण है जो AI सिस्टम बनाने के लिए उपयोग किया जाता है, जिसमें एक भाषा मॉडल को बाहरी ज्ञान स्रोत के साथ जोड़ा जाता है ताकि सटीकता बढ़ाई जा सके और तथ्यात्मक त्रुटियों को कम किया जा सके। संक्षेप में, AI उपयोगकर्ता के प्रश्न से संबंधित प्रासंगिक दस्तावेजों की खोज करता है और इस जानकारी का उपयोग करके अधिक सटीक प्रतिक्रिया उत्पन्न करता है। इस विधि को बड़े भाषा मॉडल्स (LLMs) को वास्तविक डेटा में आधारित रखने और भ्रम (hallucinations) के जोखिम को कम करने की क्षमता के लिए मान्यता प्राप्त हुई है।
आप यह मान सकते हैं कि AI को अधिक दस्तावेज प्रदान करने से बेहतर सूचित उत्तर प्राप्त होंगे। हालांकि, येरुशलम के हिब्रू विश्वविद्यालय के एक हालिया अध्ययन से पता चलता है कि ऐसा नहीं है: AI को जानकारी प्रदान करने के मामले में, कम वास्तव में अधिक हो सकता है।
कम दस्तावेज, बेहतर उत्तर
अध्ययन में यह जांच की गई कि RAG सिस्टम को प्रदान किए गए दस्तावेजों की संख्या इसके प्रदर्शन को कैसे प्रभावित करती है। शोधकर्ताओं ने कुल पाठ की लंबाई को स्थिर रखा, दस्तावेजों की संख्या को 20 से घटाकर 2-4 प्रासंगिक दस्तावेजों तक समायोजित किया और इनका विस्तार करके मूल पाठ की मात्रा से मेल खाया। इससे उन्हें दस्तावेजों की मात्रा के प्रभाव को अलग करने में मदद मिली।
म्यूसिक डेटासेट (MuSiQue) का उपयोग करके, जिसमें ट्रिविया प्रश्नों के साथ विकिपीडिया पैराग्राफ जोड़े गए हैं, उन्होंने पाया कि AI मॉडल अक्सर कम दस्तावेजों के साथ बेहतर प्रदर्शन करते हैं। सटीकता में 10% तक सुधार (F1 स्कोर द्वारा मापा गया) हुआ जब सिस्टम ने केवल कुछ प्रमुख दस्तावेजों पर ध्यान केंद्रित किया, न कि व्यापक संग्रह पर। यह प्रवृत्ति विभिन्न ओपन-सोर्स भाषा मॉडलों, जैसे मेटा के लामा (Llama), में देखी गई, जिसमें Qwen-2 एक उल्लेखनीय अपवाद था, जो कई दस्तावेजों के साथ अपना प्रदर्शन बनाए रखता था।
स्रोत: लेवी एट अल।
यह आश्चर्यजनक परिणाम इस सामान्य धारणा को चुनौती देता है कि अधिक जानकारी हमेशा मदद करती है। समान पाठ की मात्रा के बावजूद, कई दस्तावेजों की उपस्थिति ने AI के कार्य को जटिल बना दिया, जिससे सिग्नल की तुलना में अधिक शोर उत्पन्न हुआ।
RAG में कम क्यों हो सकता है अधिक
"कम है अधिक" सिद्धांत तब समझ में आता है जब हम विचार करते हैं कि AI मॉडल जानकारी को कैसे संसाधित करते हैं। कम, अधिक प्रासंगिक दस्तावेजों के साथ, AI बिना किसी विचलन के आवश्यक संदर्भ पर ध्यान केंद्रित कर सकता है, ठीक वैसे ही जैसे एक छात्र सबसे प्रासंगिक सामग्री का अध्ययन करता है।
अध्ययन में, मॉडल तब बेहतर प्रदर्शन करते थे जब उन्हें केवल उत्तर से सीधे संबंधित दस्तावेज दिए गए, क्योंकि यह स्वच्छ, केंद्रित संदर्भ सही जानकारी निकालना आसान बनाता था। इसके विपरीत, जब AI को कई दस्तावेजों के माध्यम से छानबीन करनी पड़ी, तो यह अक्सर प्रासंगिक और अप्रासंगिक सामग्री के मिश्रण से जूझता था। समान लेकिन असंबंधित दस्तावेज मॉडल को गुमराह कर सकते थे, जिससे भ्रम का जोखिम बढ़ गया।
दिलचस्प बात यह है कि अध्ययन में पाया गया कि AI स्पष्ट रूप से अप्रासंगिक दस्तावेजों को अनदेखा करना आसान पाता है, जबकि सूक्ष्म रूप से ऑफ-टॉपिक दस्तावेज अधिक भ्रमित करने वाले थे। यह सुझाव देता है कि यथार्थवादी विचलन (distractors) बेतरतीब वाले से अधिक भ्रामक हैं। केवल आवश्यक दस्तावेजों तक सीमित करके, हम ऐसे जाल सेट करने की संभावना को कम करते हैं।
इसके अतिरिक्त, कम दस्तावेजों का उपयोग करने से कम्प्यूटेशनल ओवरहेड कम होता है, जिससे सिस्टम अधिक कुशल और लागत-प्रभावी बनता है। यह दृष्टिकोण न केवल सटीकता में सुधार करता है बल्कि RAG सिस्टम के समग्र प्रदर्शन को भी बढ़ाता है।
स्रोत: लेवी एट अल।
RAG पर पुनर्विचार: भविष्य की दिशाएँ
ये निष्कर्ष भविष्य के AI सिस्टमों के डिज़ाइन के लिए महत्वपूर्ण निहितार्थ रखते हैं जो बाहरी ज्ञान पर निर्भर करते हैं। यह सुझाव देता है कि पुनर्प्राप्त दस्तावेजों की गुणवत्ता और प्रासंगिकता पर ध्यान देना, उनकी मात्रा के बजाय, प्रदर्शन को बढ़ा सकता है। अध्ययन के लेखक पुनर्प्राप्ति विधियों की वकालत करते हैं जो प्रासंगिकता और विविधता को संतुलित करती हैं, ताकि मॉडल को अनावश्यक पाठ से अभिभूत किए बिना व्यापक कवरेज सुनिश्चित हो।
भविष्य के शोध में बेहतर पुनर्प्राप्ति सिस्टम या री-रैंकर्स की खोज हो सकती है ताकि वास्तव में मूल्यवान दस्तावेजों की पहचान की जा सके और भाषा मॉडल्स कई स्रोतों को संभालने में सुधार कर सकें। मॉडल्स को स्वयं बेहतर बनाना, जैसा कि Qwen-2 के साथ देखा गया, विविध इनपुट्स के प्रति उन्हें अधिक मजबूत बनाने में अंतर्दृष्टि प्रदान कर सकता है।
जैसे-जैसे AI सिस्टम बड़े संदर्भ खिड़कियों (context windows) को विकसित करते हैं, अधिक पाठ को एक साथ संसाधित करने की क्षमता कम महत्वपूर्ण हो जाती है, बनिस्पत यह सुनिश्चित करने के कि पाठ प्रासंगिक और चयनित हो। "अधिक दस्तावेज, समान लंबाई" शीर्षक वाला यह अध्ययन AI की सटीकता और दक्षता में सुधार के लिए सबसे प्रासंगिक जानकारी पर ध्यान केंद्रित करने के महत्व को रेखांकित करता है।
निष्कर्ष में, यह शोध AI सिस्टमों में डेटा इनपुट के बारे में हमारी धारणाओं को चुनौती देता है। कम, बेहतर दस्तावेजों का सावधानीपूर्वक चयन करके, हम अधिक स्मार्ट, हल्के RAG सिस्टम बना सकते हैं जो अधिक सटीक और भरोसेमंद उत्तर प्रदान करते हैं।










 अमेज़न की डैनियल पर्सज़िक टेकक्रंच सेशंस: AI में बोलेंगी
हमें यह साझा करते हुए खुशी हो रही है कि डैनियल पर्सज़िक, अमेज़न AGI SF लैब की मानव-कंप्यूटर इंटरैक्शन टीम की प्रमुख, 5 जून को UC बर्कले के ज़ेलरबैक हॉल में टेकक्रंच सेशंस: AI में बोलेंगी। AGI SF लैब व
अमेज़न की डैनियल पर्सज़िक टेकक्रंच सेशंस: AI में बोलेंगी
हमें यह साझा करते हुए खुशी हो रही है कि डैनियल पर्सज़िक, अमेज़न AGI SF लैब की मानव-कंप्यूटर इंटरैक्शन टीम की प्रमुख, 5 जून को UC बर्कले के ज़ेलरबैक हॉल में टेकक्रंच सेशंस: AI में बोलेंगी। AGI SF लैब व
 नाई की दुकान की बुकिंग को मुफ्त AI उपकरणों के साथ सरल बनाएं
आज की तेजी से बदलती दुनिया में, स्वचालन दक्षता की कुंजी है। कल्पना करें कि AI का उपयोग करके अपनी नाई की दुकान की नियुक्तियों को आसानी से प्रबंधित किया जाए। यह मार्गदर्शिका बताती है कि AI एजेंट और वेब
नाई की दुकान की बुकिंग को मुफ्त AI उपकरणों के साथ सरल बनाएं
आज की तेजी से बदलती दुनिया में, स्वचालन दक्षता की कुंजी है। कल्पना करें कि AI का उपयोग करके अपनी नाई की दुकान की नियुक्तियों को आसानी से प्रबंधित किया जाए। यह मार्गदर्शिका बताती है कि AI एजेंट और वेब
 Audible Boosts AI-Narrated Audiobook Offerings with New Publisher Partnerships
Audible, Amazon का ऑडियोबुक मंच, ने मंगलवार को चुनिंदा प्रकाशकों के साथ सहयोग की घोषणा की ताकि प्रिंट और ई-बुक्स को AI-नैरेटेड ऑडियोबुक्स में बदला जा सके। यह कदम Apple, Spotify और ऑडियोबुक उद्योग में
29 जुलाई 2025 5:55:16 अपराह्न IST
Audible Boosts AI-Narrated Audiobook Offerings with New Publisher Partnerships
Audible, Amazon का ऑडियोबुक मंच, ने मंगलवार को चुनिंदा प्रकाशकों के साथ सहयोग की घोषणा की ताकि प्रिंट और ई-बुक्स को AI-नैरेटेड ऑडियोबुक्स में बदला जा सके। यह कदम Apple, Spotify और ऑडियोबुक उद्योग में
29 जुलाई 2025 5:55:16 अपराह्न IST
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
26 अप्रैल 2025 11:34:32 पूर्वाह्न IST
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
24 अप्रैल 2025 3:59:07 पूर्वाह्न IST
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
22 अप्रैल 2025 10:20:26 अपराह्न IST
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
21 अप्रैल 2025 4:44:10 अपराह्न IST
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0
21 अप्रैल 2025 2:09:06 अपराह्न IST
AI 응답에서 '적을수록 좋다'는 접근 방식이 꽤 멋지네요! 적은 문서로도 정확한 답변을 얻다니, 가입하고 싶어요! 마법 같지만, 좀 더 빨리 작동했으면 좋겠어요. 그래도 AI 기술의 발전 단계로는 훌륭해요! 🚀
0













